






最近有一些同学跟我说『TiDB 搞不定分库分表的场景』,实话我当时真的二丈摸不着头脑,TiDB 从最开始设计的时候,就是要去解决分库分表这种解决方案所带来的一些问题的,让 DBA 同学,研发同学更好的去使用数据库。但现在发现还有些同学觉得 TiDB 搞不定分库分表的场景,我觉得有必要研究一下。
首先来看什么是分库分表,我们后面以 MySQL 为例子,毕竟 TiDB 也是 MySQL Protocol Family 一员。假设现在我们要开发一个购物应用,当然这里选择了 MySQL,这个应用当然也会有账户,物品等信息吧,然后整个系统的架构大概如下:
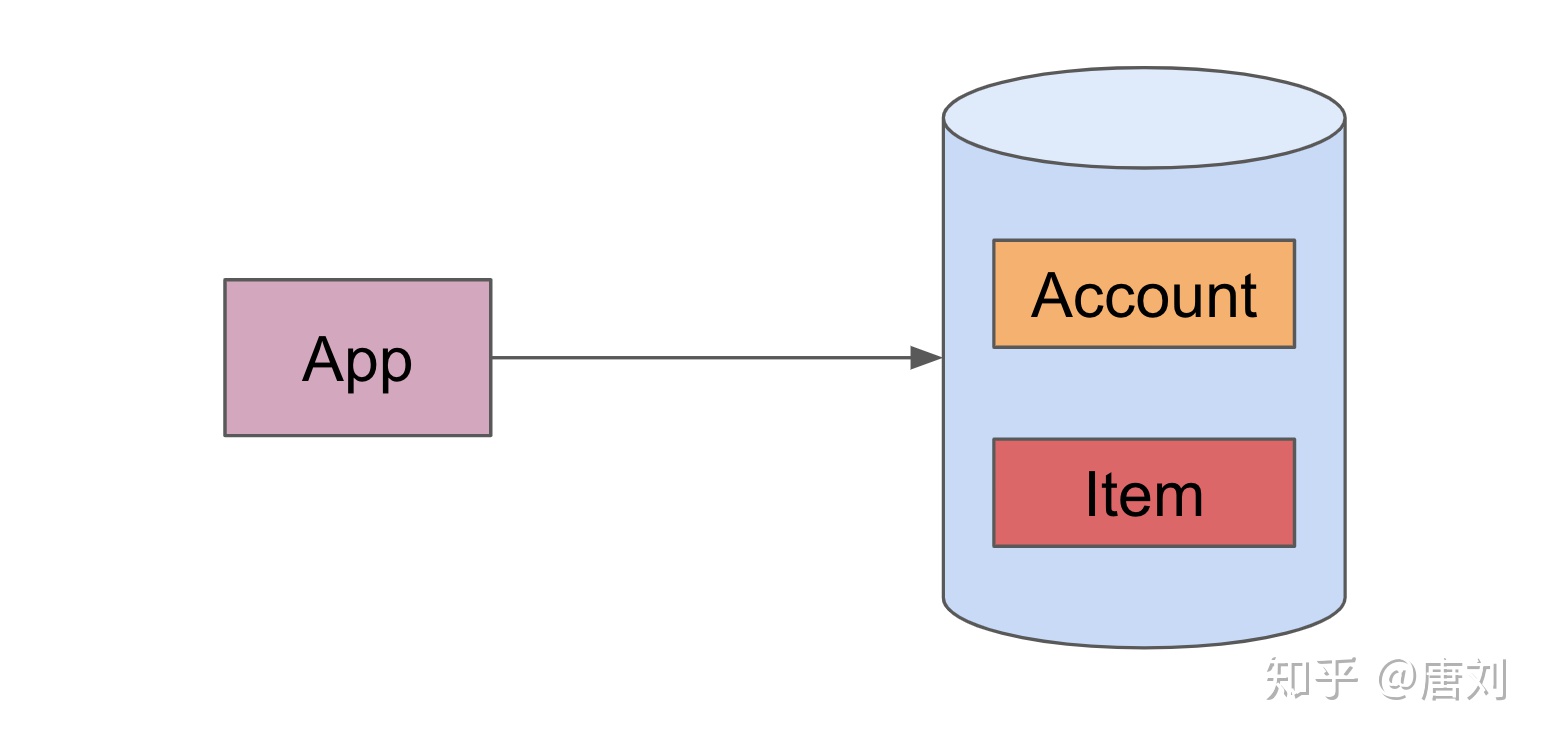
Account 表假设有一个 AccountID 的主键,而 Item 表也是有一个 ItemID 的主键,另外还有一个 AccountID 的 unique ID,也就是一个账户,可能会有多个 Item。
现在这个架构很简单,随着数据量的增大,单个 MySQL 出现了性能瓶颈。一个很简单的方式,就是分库分表,这里我们按照 account ID 来做切分,
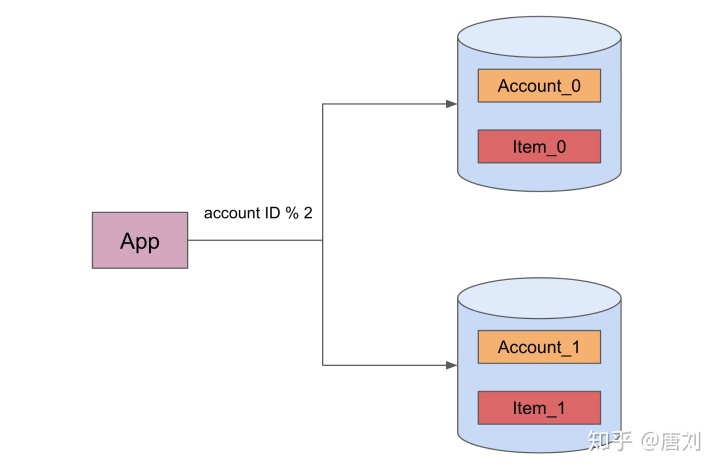
通过切分的方式,我们很容易就分散了压力,这也是传统的分库分表的做法,但这个做法有一些问题:
- 业务的侵入性,现在业务需要显示的知道分片规则,这样才能知道如何将请求发给对应的 MySQL。
- MySQL 的高可用,这个其实算一个老生常谈的问题了,不可否认,MySQL 的 HA 方案现在是越来越好,但有时候还是需要人为的介入。另外,一些看起来很健壮的 HA 方案其实也是有坑的,如果的这个感兴趣,其实可以去看看 GitHub 很多 Post accident 分析。
- 运维的成本,通常为了防止出现因为数据再次膨胀导致的再分片情况,我们最开始就会比较粗暴的分 1024 或者更多的分片,如果每个分片在一台 MySQL 上面,管理 1024 个或者更多的 MySQL 实例真的不是一件轻松容易的事情。另外,如果真的出现了再次需要重新分片的情况,这个运维压力就更大了。折腾完大概率会脱层皮的。
- 分布式事务的缺失,这个其实算分库分表方案的一个硬伤,我们很难去保障跨库事务的强一致。而恰恰一些核心场景是有这样的诉求的。
- 业务的约束,因为现在数据是按照分片键来分布的,所以一些跨库 join,或者复杂的查询,或者不能通过分片主键来进行的查询都不会被支持,因为这会造成严重的性能问题,业务比较受限制。通常的做法就是通过 ETL 来解决,这又增加了运维成本。
上面只是列举了一些问题,虽然业界也有一些解决方案,譬如通过中间件来解决,但我们总觉得这些方案并不是优雅的方案,而且也不能彻底的解决上面的问题,这也是为啥我们要开发 TiDB 来解放运维人员,解放程序员的一个初衷。那么为啥还是有人说 TiDB 搞不定分库分表的一些场景呢?
我仔细思考了一下,可能的一个场景是这样的,在这个场景有如下约束:
- 用户知道自己的业务不会无限制的数据膨胀,也能保证分片的数据不会超过单机 MySQL 的限制。
- 用户的业务请求只会根据分片主键来执行
- 用户没有跨 MySQL 的分布式事务的需求,所有事务都是在分片主键所属的 MySQL 上面完成
- 用户对低延迟要求高
如果有这样的约束,那么现阶段,TiDB 在性能上面相对于传统的分库分表会有劣势,这可能也是一些同学跟我说的 TiDB 现阶段搞不定的分库分表场景。原因主要在于 TiDB 为了支持分布式事务,使用的是 Percolator 事务模型,而这个是典型的 2PC 模式,也就是相比于单机 MySQL,天然在 latency 上面会有劣势。但 TiDB 真的没法解决这个问题吗?我相信,办法总比困难多!!!
在 TiDB 4.0,我们提供了一个 placement rule 的功能,这个功能很强大,但现在只能通过 API 的方式使用,易用性不强,我们也会在 4.0 的后续版本提供 SQL 语法支持,更易于使用,大家可以关注这个 issue。
那么 placement rule 是什么呢?直白的说,就是能给数据设置规则,将其移动到我们指定的地点。所以,对于上面提到的分库分表场景,我们可以非常方便的使用这个功能,将其移动到特定的 TiKV 上面,类似如下:

上面我们仍然沿用了多个分表,但实际我们也可以用一个表,然后使用 parition 的方式来模拟分库分表。使用单个表,会让业务处理更加的简单。
所有的规则都是通过 placement rule 来配置,用户业务只需要跟 TiDB 进行交互,用户业务不需要知道任何的配置信息。通过这种方式,我们能保证分片数据全部在一台 TiKV 上面,但这里仍然没有解决 TiDB 的事务模型造成的延迟问题,我们一个一个来看。
对于读写事务来说,TiDB 在事务开始和提交的时候会从 PD 拿两次时间戳(TS),如果 TiDB 跟 PD 在同一个机房,这个开销其实可以省略,但如果 TiDB 跟 PD 离得很远,这个网络开销就很大了,为了解决这个问题,我们决定在 5.0 的时候支持 Local/Global PD,简单来说,就是对于在同一个机房(譬如单分区内)的事务,可以使用 Local PD 来进行 TS 的分配,而对于跨机房的分布式事务,则会用 Global PD 来进行 TS 的分配,我们也有机制来保证 Local 和 Global PD 分配的 TS 不会打破一致性约束。详细的设计方案,我们后面会放出,大家可以关注这个 issue。更进一步,对于 commit 阶段 TSO,我们可以采用计算的方式来得到,这样就不用额外在从 PD 拿一次 TS。
上面说了我们会如何解决 TS 的获取问题,然后再来说下事务的提交,我们现在不打算做 1 PC,但我们会提供一个 async commit 的优化,使用这个优化,TiDB 在事务提交的事务,只需要等待 Prewrite 完成,而 commit 可以异步完成,这样虽然整体的吞吐没有减少,但对于单个事务来说,latency 减少了很多。其实已经类似于 1 PC 效果了。(但这里,我们需要知道,延迟仍然是可能比单机 MySQL 要高的。不过单机的 MySQL 没有 HA,而如果有让 MySQL 提供 HA ,延迟开销也会上去。)
最后再来说下回表,虽然现在分片的数据都聚集到一个 TiKV 了,但现在我们的读取还是可能会有网络回表操作,具体可以参考 使用 unistore 对 TiDB 快速进行『回表优化』原型验证 这篇文章,里面也提出来了解决办法,这里就不详细说明了。
可以看到,通过上面的这些优化,TiDB 大概率就能搞定分库分表下需要低延迟的场景了,而且还额外提供了非常多的增强功能,包括高可用,分布式事务,更好的可运维性,HTAP 等特性。这妥妥的就是一个解决方案大礼包了。
上面说的那些性能优化,我们都会在 4.0.x 以及 5.0 带上,尽情期待。如果你迫不及待的想体验我上面说的这些功能,也欢迎加入我们,给我们一起做贡献,一起加速这些特性的落地。















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









