







前言:本篇是TextCNN系列的第二篇,分享TextCNN的代码
前两篇可见:
一、textCNN整体框架
1. 模型架构
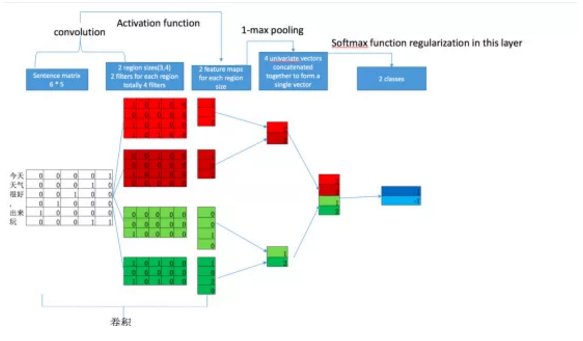
图一:textCNN 模型结构示意
2. 代码架构
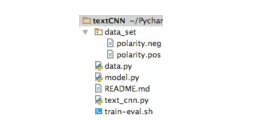 图二: 代码架构说明
图二: 代码架构说明
text_cnn.py 定义了textCNN 模型网络结构
model.py 定义了训练代码
data.py 定义了数据预处理操作
data_set 存放了测试数据集合. polarity.neg 是负面情感文本, polarity.pos 是正面情感文本
train-eval.sh 执行脚本
3.代码地址
部分代码参考了 此处代码
4.训练效果说明:
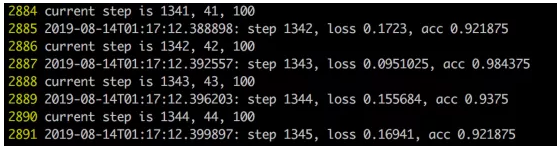
图三:训练效果展示
二、textCNN model 代码介绍
2.1 wordEmbedding

图四:WordEmbedding 例子说明
简要说明:
vocab_size: 词典大小18758
embedding_dim: 词向量大小 为128
seq_length: 句子长度,设定最长为56
embedding_look: 查表操作 根据每个词的位置id 去初始化的w中寻找对应id的向量. 得到一个tensor :[batch_size, seq_length, embedding_size] 既 [?, 56, 128], 此处? 表示batch, 即不知道会有多少输入。
#embedding layer
with tf.name_scope("embedding"):
self.W= tf.Variable(tf.random_uniform([self._config.vocab_size, self._config.embedding_dim], -1.0, 1.0),
name="W")
self.char_emb=tf.nn.embedding_lookup(self.W, self.input_x)
self.char_emb_expanded= tf.expand_dims(self.char_emb, -1)
tf.logging.info("Shape of embedding_chars:{}".format(str(self.char_emb_expanded.shape)))
举例说明:我们有一个词典大小为3的词典,一共对应三个词 “今天”,“天气” “很好“,w =[[0,0,0,1],[0,0,1,0],[0,1,0,0]]。
我们有两个句子,”今天天气“,经过预处理后输入是[0,1]. 经过embedding_lookup 后,根据0 去查找 w 中第一个位置的向量[0,0,0,1], 根据1去查找 w 中第二个位置的向量[0,0,1,0] 得到我们的char_emb [[0,0,0,1],[0,0,1,0]]
同理,“天气很好”,预处理后是[1,2]. 经过经过embedding_lookup 后, 得到 char_emb 为[[0,0,1,0],[0,1,0,0]]
因为, 卷积神经网conv2d是需要接受四维向量的,故将char_embdding 增广一维,从 [?, 56, 128] 增广到[?, 56, 128, 1]
2.2 Convolution 卷积 + Max-Pooling
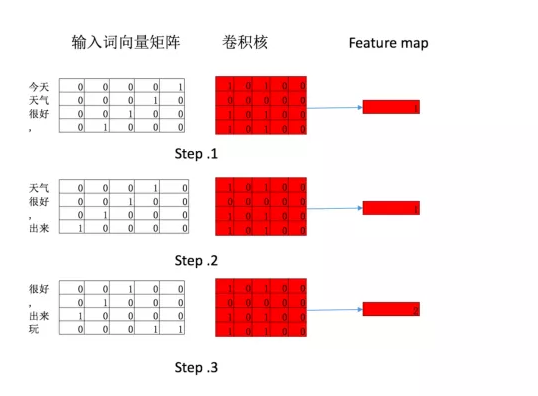 图五:卷积例子说明
图五:卷积例子说明
简要说明:
filter_size= 3,4,5. 每个filter 的宽度与词向量等宽,这样只能进行一维滑动。
每一种filter卷积
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 868
868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









