






目录
PyPi也称为Cheese Shop
一、使用itertools得到排列和组合
在Python的itertools模块中,有两个函数用于处理排列和组合:permutations() 和 combinations()。
1. 全排列
permutations(iterable, r=None):创建所有长度为r的可能排列。如果未指定r,则默认为len(iterable)。
2. 组合
combinations(iterable, r):创建所有长度为r的可能组合(从iterable中选择r个不同的元素)。
注意:itertools.permutations和itertools.combinations返回的是元组的迭代器,如果你需要列表,可以使用list()函数进行转换。
二、产生随机数
1. 随机选择一个值
random.choice(),该函数从指定的序列(列表,元组,字典,字符串)参数中返回一个值:
2. 随机选择多个值
3. 获取随机整数
4. 获取随机浮点数
三、正则表达式
正则表达式的常见元字符
| 模式 | 匹配 |
|---|---|
| \d | 数字 |
| \D | 非数字 |
| \w | 字母数字下划线组成的单词(空白字符分割) |
| \W | 非单词 |
| \s | 空白字符(" “,”\t",“\n”,“\r”) |
| \S | 非空白字符 |
| \b | 单词边界(\w和\W之间) |
| \B | 非单词边界 |
| abc | 字面量 |
| (expr) | 分组 |
| expr1│expr2 | expr1或expr2 |
| · | 除\n之外的任意字符 |
| ^和$ | 源字符串的开始和结束 |
| re? | 0或1个re |
| re* | 0或多个re,尽可能多 |
| re*? | 0或多个re,尽可能少 |
| re+ | 1或多个re,尽可能多 |
| re+? | 1或多个re,尽可能少 |
| re{m} | m个连续的re |
| re{m,n} | m至n个连续re,尽可能多 |
| re{m,n}? | m至n个连续re,尽可能少 |
| [abc] | a或b或c |
| [^abc] | 非a或b或c |
| prev(?=next) | 如果后继是next,则匹配prev |
| prev(?!next) | 如果后继不是next,则匹配prev |
| (?<=prev)next | 如果前驱是prev,则匹配next |
| (?<!prev)next | 如果前驱不是prev,则匹配next |
四、日期的使用
另一种方式
五、文本文件的读写
1. 文本文件的读
使用到的函数:
字符串filename指定了文件名,字符串mode的取值指定了文件类型和操作。
mode第一个字符指定了操作:
- r 表示读取。
- w 表示写入。如果文件不存在,则创建文件;如果文件存在,就覆盖同名文件。
- x 表示仅在指定文件不存在时写入。可以避免文件被覆盖(会抛出FileExistsError异常)。
- a 表示如果文件存在,则在文件末尾追加写入。
mode第二个字符指定了文件类型 - t(或省略) 表示文本文件
- b 表示二进制文件。
注意:mode字符串只能有2个字符组成(或者1个字符),一个指代操作,一个指代文件类型(t可省)。
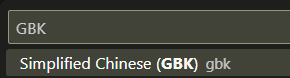
文本文件还要注意统一编码。建议统一使用utf-8编码。在VSCode中可以使用GBK to UTF8 for vscode插件来完成Windows下GBK编码向UTF8编码的统一转换。
VSCode文本文件编码格式转换的其他方式:
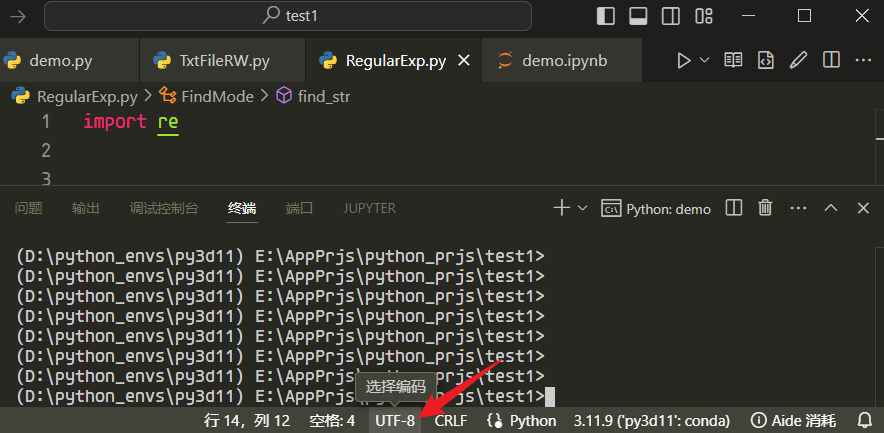
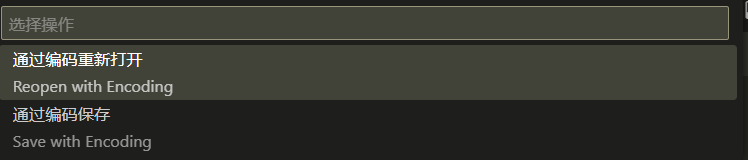
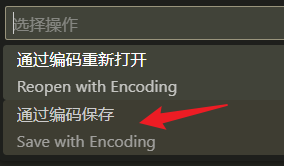
Ctrl + Shift + p,然后在命令窗口中输入Reopen with Encoding
或者点击下图箭头所示位置“选择编码”
通过编码重新打开
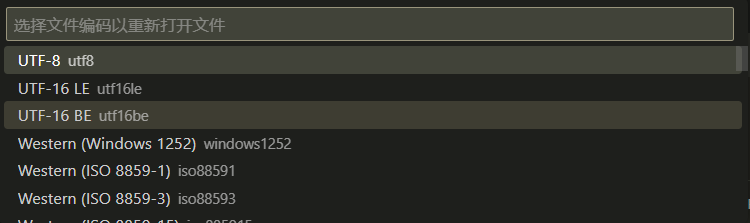
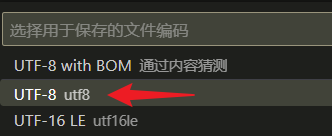
通过尝试找到无乱码的正确编码,或者最初使用VSCode打开文件时状态栏会显示检测到的编码格式。
然后使用通过编码保存。
1.1. 使用内置函数readline()逐行读取文本文件
文本文件中间读到的空行包含一个字节的“\n”——不是“”;而文件结尾处读到的空行才是“”。
1.2. 使用迭代器逐行读取文本文件
1.3. 将文件内容全部读入列表,然后逐行处理。
1.4. 封装成一个文本文件处理类
2. 文本文件的写
默认情况下,print()会自动在每个参数后边添加空格,在结尾添加换行符“\n”,而上边的write()方法不会。如果希望print()和write()一样,可以如下传递参数。















 8877
8877

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









