







简介:本系统通过Python3编程语言和wxPython图形用户界面库开发而成,旨在简化图书管理流程。系统利用Python3的高级特性和内置库支持,通过wxPython构建跨平台的应用界面,实现图书信息的增删改查功能。系统支持数据库操作,并采用MVC架构模式,结合数据验证、错误处理、事件驱动编程、异常处理、文件操作和版本控制等技术要点,为图书管理人员提供了一个全面且高效的管理工具。 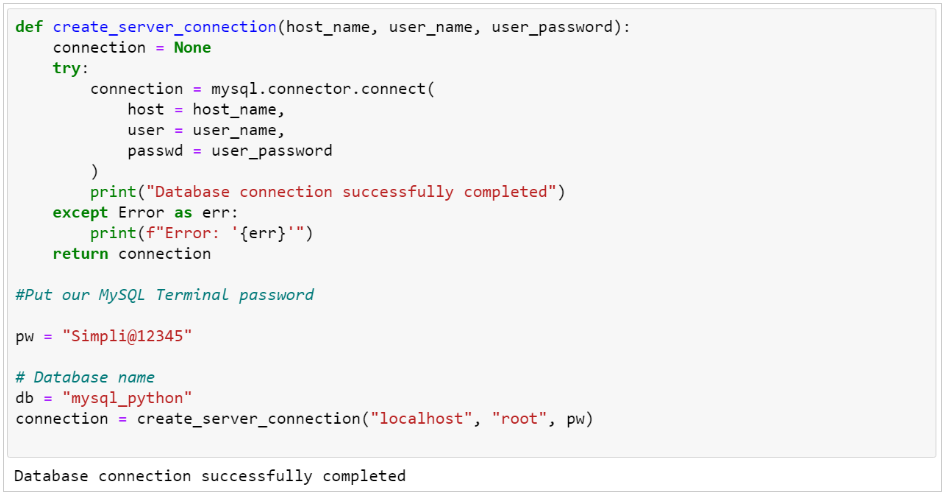
1. Python3编程语言应用
Python3作为当今最流行的编程语言之一,在数据分析、人工智能、网络开发等多个领域都有广泛的应用。学习Python3的基本语法和数据结构是步入编程世界的第一步。
1.1 Python3基础知识
Python3通过简洁明了的语法降低了学习门槛,同时拥有强大的标准库和第三方库,能够满足各种开发需求。例如,数据类型的使用、条件判断、循环控制等是编写程序的基础。
# 示例:基础数据类型和控制流
number = 10
if number > 5:
print("Number is greater than 5.")
else:
print("Number is 5 or less.")
1.2 函数和模块
函数是组织代码的重要方式,而模块则允许我们重用代码并实现代码的模块化。Python标准库中有许多内置函数和模块,如math、os、sys等,支持开发者进行更高级的操作。
# 示例:定义和使用函数、导入模块
import math
def square(number):
return number * number
print(square(4)) # 输出 16
print(math.sqrt(16)) # 输出 4.0
通过本章,我们将掌握Python3的核心概念,为深入学习后续章节打下坚实的基础。随着章节的深入,我们会逐渐接触到Python在更复杂项目中的应用,包括图形用户界面的开发、数据库操作以及系统架构设计等。
2. wxPython图形用户界面库
2.1 wxPython基础组件使用
在本章节中,我们将深入探讨如何使用wxPython库开发图形用户界面(GUI)。wxPython是Python的一个扩展模块,它提供了一套丰富的GUI控件,允许开发者轻松创建跨平台的应用程序。我们将从基础组件开始,逐步介绍如何创建和布局窗口与控件,以及如何将事件绑定到这些组件上,以便实现用户交互。
2.1.1 窗口与控件的创建与布局
在wxPython中,创建一个窗口(wx.Frame)和控件(如按钮、文本框等)通常涉及以下步骤:
import wx
class MyFrame(wx.Frame):
def __init__(self, parent, id, title):
wx.Frame.__init__(self, parent, id, title, size=(300, 200))
panel = wx.Panel(self, -1)
self.button = wx.Button(panel, -1, "Hello World", pos=(100,50))
app = wx.App(False)
frame = MyFrame(None, -1, 'First wxPython App')
frame.Show()
app.MainLoop()
代码解析: - 导入wx模块,这是使用wxPython进行GUI开发的前提。 - 定义一个 MyFrame 类,继承自 wx.Frame ,这是我们创建的主窗口。 - 使用 wx.Button 创建一个按钮,位置定义为距离窗口左边缘100像素,顶部边缘50像素。
在上述代码中,我们创建了一个主窗口 MyFrame ,并在其中添加了一个按钮。布局是在父控件 panel 上使用相对位置和大小进行定义的。
2.1.2 事件绑定与响应处理
用户与GUI组件的交互主要是通过事件的形式来处理的。在wxPython中,事件处理需要使用事件绑定机制:
def OnButton(self, event):
print("Button clicked!")
self.button.Bind(wx.EVT_BUTTON, self.OnButton)
逻辑分析: - OnButton 函数被定义为事件处理器,当按钮被点击时,会打印出相应的消息。 - Bind 方法将 EVT_BUTTON 类型的事件与 OnButton 函数关联起来,实现了对按钮点击事件的响应。
2.2 高级界面元素应用
2.2.1 菜单栏、工具栏和状态栏的设计
为了提供更丰富的用户交互体验,wxPython还支持菜单栏、工具栏和状态栏等高级界面元素。以下是创建这些元素的基本代码示例:
# 创建菜单栏
menuBar = wx.MenuBar()
menuFile = wx.Menu()
menuFile.Append(1, "&Open", "Open a file")
menuFile.AppendSeparator()
menuFile.Append(2, "E&xit", "Exit application")
menuBar.Append(menuFile, "&File")
self.SetMenuBar(menuBar)
# 创建工具栏
toolbar = self.CreateToolBar()
toolbar.AddTool(1, "Open", wx.Bitmap("open.png"), shortHelp="Open file")
# 创建状态栏
statusbar = self.CreateStatusBar()
statusbar.SetStatusText("Ready")
self.Bind(wx.EVT_MENU, self.OnFileOpen, id=1)
self.Bind(wx.EVT_TOOL, self.OnFileOpen, id=1)
代码解析: - 菜单栏通过 wx.MenuBar 创建,并通过 Append 方法添加菜单项和分隔符。 - 工具栏通过 CreateToolBar 方法创建,并使用 AddTool 添加工具按钮。 - 状态栏通过 CreateStatusBar 方法创建,并用 SetStatusText 设置状态信息。 - 事件绑定与按钮点击类似,使用 Bind 方法绑定事件与相应的处理函数。
2.2.2 弹出窗口和对话框的实现
弹出窗口和对话框是GUI应用程序中常见的组件,用于显示信息、接收用户输入或进行功能选择等。在wxPython中,可以使用 wx.Dialog 创建自定义对话框。
class MyDialog(wx.Dialog):
def __init__(self, parent, title):
wx.Dialog.__init__(self, parent, title=title, size=(300,200))
panel = wx.Panel(self)
sizer = wx.BoxSizer(wx.VERTICAL)
# 添加组件到对话框
label = wx.StaticText(panel, -1, "This is a dialog")
textctrl = wx.TextCtrl(panel)
okButton = wx.Button(panel, -1, "OK")
# 添加组件到sizer布局管理器
sizer.Add(label, 0, wx.EXPAND | wx.ALL, 5)
sizer.Add(textctrl, 0, wx.EXPAND | wx.ALL, 5)
sizer.Add(okButton, 0, wx.ALIGN_CENTER | wx.ALL, 5)
panel.SetSizer(sizer)
# 绑定事件
self.Bind(wx.EVT_BUTTON, self.OnOK, id=okButton.GetId())
def OnOK(self, event):
self.EndModal(wx.ID_OK)
# 使用对话框
dialog = MyDialog(None, "Sample Dialog")
dialog.ShowModal()
dialog.Destroy()
逻辑分析: - MyDialog 类继承自 wx.Dialog ,可以自定义窗口中的内容和布局。 - 组件(如标签、文本框、按钮)被添加到 BoxSizer 布局管理器中。 - 点击OK按钮会触发 OnOK 方法,结束模态对话框并返回相应的返回码。
通过以上内容,我们介绍了wxPython图形用户界面库的基础组件使用,以及如何通过事件绑定与响应处理来实现用户交互。在后续的章节中,我们将继续探讨wxPython的高级界面元素应用,以及如何在图书信息管理系统中应用这些GUI元素。
3. 图书信息管理功能实现
3.1 图书信息数据结构设计
3.1.1 图书信息的属性与方法
在设计图书信息管理功能时,首先需要确定图书信息的数据结构。通常情况下,每本图书都具备一系列的属性,例如书名、作者、ISBN编号、出版社、出版年份、分类号、库存数量等。这些属性是管理图书的基础。
class Book:
def __init__(self, title, author, isbn, publisher, year, category, stock):
self.title = title
self.author = author
self.isbn = isbn
self.publisher = publisher
self.year = year
self.category = category
self.stock = stock
def display_info(self):
print(f"Title: {self.title}")
print(f"Author: {self.author}")
print(f"ISBN: {self.isbn}")
print(f"Publisher: {self.publisher}")
print(f"Year: {self.year}")
print(f"Category: {self.category}")
print(f"Stock: {self.stock}")
def update_stock(self, quantity):
if self.stock + quantity >= 0:
self.stock += quantity
else:
print("Insufficient stock to update.")
在上述代码中,我们定义了一个 Book 类,它包含了初始化方法 __init__ 和两个实例方法: display_info 用于打印图书信息, update_stock 用于更新图书的库存数量。这个类为图书信息提供了一个清晰的结构,并提供了操作这些数据的方法。
3.1.2 图书分类与检索算法
分类和检索是图书管理系统中不可或缺的功能。图书可以通过多种属性进行分类,如按作者、分类号、出版年份等。为了有效地检索图书,我们可以采用不同的算法,例如二分查找、哈希表或者全文搜索。
以下是一个简单的分类和检索的示例:
# 假设我们有一个Book对象的列表
books = [
Book("Book1", "Author1", "123456789", "Publisher1", 2001, "CategoryA", 5),
Book("Book2", "Author2", "987654321", "Publisher2", 2002, "CategoryB", 3),
# ... 更多图书
]
# 按照分类号检索图书
def search_by_category(category):
return [book for book in books if book.category == category]
# 调用示例
searched_books = search_by_category("CategoryA")
for book in searched_books:
book.display_info()
在这个例子中, search_by_category 函数通过过滤列表中 Book 对象的 category 属性来检索特定分类的所有图书。这种方式适用于数据量不是非常大的情况,但对于大数据量的搜索,可以考虑使用数据库提供的高级搜索功能或索引机制来提高效率。
3.2 图书管理功能模块
3.2.1 图书的增删改查操作
图书的增删改查(CRUD)是图书管理系统中最核心的功能。每一项操作都直接影响到图书信息数据的完整性与准确性。
增加图书
def add_book(title, author, isbn, publisher, year, category, stock):
new_book = Book(title, author, isbn, publisher, year, category, stock)
books.append(new_book)
通过 add_book 函数,我们可以向 books 列表中添加新的图书对象。
删除图书
def delete_book(isbn):
global books
books = [book for book in books if book.isbn != isbn]
使用 delete_book 函数,我们可以通过图书的 ISBN 号来删除图书信息。
修改图书信息
def update_book(isbn, title=None, author=None, publisher=None, year=None, category=None, stock=None):
for book in books:
if book.isbn == isbn:
if title:
book.title = title
if author:
book.author = author
if publisher:
book.publisher = publisher
if year:
book.year = year
if category:
book.category = category
if stock:
book.update_stock(stock)
return
print("Book not found.")
在 update_book 函数中,我们通过 ISBN 号查找图书并根据传入的参数更新相应的信息。
查询图书
def query_books_by_title(title):
return [book for book in books if title.lower() in book.title.lower()]
通过 query_books_by_title 函数,可以查询所有标题中包含特定文本的图书。
3.2.2 图书借阅与归还处理
图书的借阅与归还是图书管理系统中处理与用户交互的重要环节。每本图书的状态(是否可借)和借阅者信息都需要在管理系统中得到准确的记录。
借阅图书
def borrow_book(isbn, borrower):
for book in books:
if book.isbn == isbn and book.stock > 0:
book.update_stock(-1)
book.borrower = borrower
print(f"Borrower {borrower} has borrowed {book.title}.")
return
print("Book is not available for borrowing.")
在 borrow_book 函数中,我们首先检查是否可以借阅图书(即库存大于 0),然后更新图书的库存数量,并记录借阅者信息。
归还图书
def return_book(isbn, borrower):
for book in books:
if book.isbn == isbn and book.borrower == borrower:
book.update_stock(1)
book.borrower = None
print(f"Borrower {borrower} has returned {book.title}.")
return
print("Book return failed. Invalid book or borrower.")
在 return_book 函数中,我们检查图书是否被指定的借阅者借出,如果是,则更新图书的库存数量,并清空借阅者信息。
以上代码片段展示了如何实现图书管理功能模块中的核心操作。实际开发中,这些功能通常会结合用户界面来实现交互式的操作,并且还需要考虑异常处理和事务管理以保证数据的完整性和一致性。
4. 跨平台系统开发
在现代软件开发中,跨平台能力是衡量一个应用成功与否的关键因素之一。第四章将深入探讨如何构建跨平台的图形用户界面(GUI)应用,并详细说明系统的打包与分发过程。本章节内容将涵盖两大主要部分:跨平台GUI应用的构建以及应用的打包与分发。
4.1 跨平台GUI应用的构建
构建跨平台GUI应用要求开发者选择合适的工具和策略来确保应用能在不同的操作系统中无缝运行。本小节将介绍Linux、Windows、Mac OS X的兼容性分析,并探讨如何构建单一代码库以支持多平台。
4.1.1 Linux、Windows、Mac OS X兼容性分析
当涉及到跨平台GUI应用开发时,需要考虑到不同操作系统的特性,包括用户界面的外观、行为和系统级功能。例如,在Windows上,一个特定的控件可能与Linux和Mac OS X中有所不同。因此,为了确保应用的用户界面在各个平台上具有一致的体验,开发者需要对每个操作系统的特定细节进行深入分析。
跨平台兼容性分析应该包括以下方面: - 界面元素兼容性 :不同平台下的控件和布局可能需要调整以保持一致性。 - 系统功能访问 :访问系统功能,如剪贴板、文件选择器等,在不同平台上可能有不同的API。 - 用户交互一致性 :确保用户与应用的交互在不同平台上是相同的,包括快捷键等。
4.1.2 构建单一代码库的跨平台策略
为了简化跨平台GUI应用的开发,开发者可以采用单一代码库的策略。这样,开发者只需要维护一份代码,即可编译生成能在多个操作系统上运行的应用。流行的跨平台框架如Qt、wxWidgets等,可以用来实现这一目标。
在使用Python语言时,wxPython是一个常用的跨平台GUI框架。它提供了一套基于wxWidgets库的Python接口,允许开发者使用Python来编写可以在Linux、Windows和Mac OS X上运行的应用。构建单一代码库时应考虑以下策略: - 抽象层 :创建抽象层来封装不同平台间的差异。 - 代码兼容性检查 :确保代码在所有目标平台上都能正常工作。 - 模块化设计 :模块化的设计有助于维护和后续的平台特定适配。
4.2 系统的打包与分发
在构建完一个功能完备的跨平台GUI应用后,接下来的任务是将应用打包和分发给用户。本小节将探讨使用PyInstaller和cx_Freeze等工具进行应用打包,以及如何构建安装程序和部署指南。
4.2.1 使用PyInstaller和cx_Freeze打包应用
PyInstaller和cx_Freeze是Python中流行的打包工具,它们能将Python脚本和所有依赖打包成一个独立的可执行文件。这使得应用的部署变得简单,用户无需安装Python环境即可运行应用。
打包应用时,应该注意以下方面: - 依赖管理 :确保所有依赖都被正确识别并包含在内。 - 运行时环境 :对于不同平台,可能需要不同的运行时环境。 - 安全性 :打包后的应用应该安全,不包含任何敏感数据。
PyInstaller的基本使用方法如下:
import PyInstaller
# 构建可执行文件
PyInstaller.build_main(['--onefile', 'your_script.py'])
在这个例子中, --onefile 参数会生成一个单一的可执行文件。
4.2.2 构建安装程序与部署指南
打包后的应用通常需要通过安装程序进行分发。这允许用户通过简单的点击安装步骤来安装应用。此外,提供详细的部署指南可以帮助用户解决在安装过程中可能遇到的问题。
安装程序的构建和部署指南的编写需要考虑以下方面: - 用户界面 :安装程序应有清晰的用户界面,让用户轻松完成安装。 - 安装选项 :提供定制安装选项,例如安装路径选择、快捷方式创建等。 - 部署指南 :详细说明安装步骤,包括错误排查和解决方法。
部署指南示例:
# 安装指南
## 步骤1:下载安装包
前往官方网站下载最新版的安装包。
## 步骤2:运行安装程序
双击下载的安装文件,启动安装向导。
## 步骤3:选择安装选项
按照指示选择安装路径和创建快捷方式。
## 步骤4:完成安装
完成安装向导,启动应用。
在本章节中,我们详细介绍了跨平台GUI应用的构建和打包与分发的关键点。接下来的章节将继续深入探讨数据库操作和MVC架构模式的应用。
5. 数据库操作
在现代的信息管理系统中,数据库操作是必不可少的一部分,它涉及到数据的存储、检索、更新和维护。本章节将详细探讨如何在Python3中连接和配置数据库,以及如何设计和执行SQL语句以满足图书信息管理系统的业务需求。
5.1 数据库连接与配置
数据库连接是应用程序与数据库之间建立交互的桥梁。在Python中,可以使用多种库来实现数据库的连接,例如sqlite3、MySQLdb和psycopg2等。这些库通常提供了用于数据库操作的API,能够执行SQL语句和处理结果集。
5.1.1 SQLite和MySQL数据库的使用选择
SQLite和MySQL是两种常见的数据库系统,它们各有优势和适用场景。SQLite是一种轻量级的数据库,适合小型应用或者原型设计,因为它不需要配置服务器环境。而MySQL是一个成熟的数据库管理系统,适用于需要处理大量数据的复杂应用。
选择合适的数据库系统主要取决于以下几个因素:
- 应用大小:小型应用可以考虑使用SQLite,而大型应用或者并发用户较多时应选择MySQL。
- 开发环境:SQLite操作简单,适合快速开发,而MySQL可能需要更多的配置和管理。
- 性能要求:MySQL在性能上要优于SQLite,特别是在处理大量数据和高并发请求时。
- 扩展性:MySQL支持更多的高级特性,如分布式存储、主从复制等。
以下代码展示了如何在Python中连接SQLite和MySQL数据库:
import sqlite3
import MySQLdb
# SQLite连接示例
conn_sqlite = sqlite3.connect('library.db')
cursor_sqlite = conn_sqlite.cursor()
# MySQL连接示例
conn_mysql = MySQLdb.connect('host', 'user', 'password', 'dbname')
cursor_mysql = conn_mysql.cursor()
# 执行SQL操作...
# ...
# 关闭连接
cursor_mysql.close()
conn_mysql.close()
cursor_sqlite.close()
conn_sqlite.close()
5.1.2 连接池和性能优化
当应用频繁与数据库交互时,建立和销毁数据库连接的成本会变得很高,这时可以使用连接池来优化性能。连接池通过维护一组活跃的数据库连接并重用它们来减少连接的开销。
Python中可以使用 pymysql 库的 ConnectionPool 类来实现连接池。下面是一个简单的连接池使用示例:
from pymysql import pool
# 初始化连接池
pool_size = 5
pool.init_poolsize(pool_size)
pool.start_pools()
# 获取连接池中的连接
connection = pool.get_connection()
# 使用连接进行数据库操作...
# ...
# 释放连接回连接池
pool.put_connection(connection)
5.2 SQL语句的设计与执行
SQL(Structured Query Language)是用于数据库管理和数据操作的标准语言。一个精心设计的SQL语句可以提高数据检索的效率和准确性,减少系统资源的消耗。
5.2.1 高效查询与数据完整性保证
在设计查询语句时,我们应当尽可能地使用索引,避免全表扫描,合理使用 JOIN 操作,并且减少不必要的数据读取。例如,使用 EXPLAIN 语句可以分析SQL执行计划,优化查询性能。
EXPLAIN SELECT * FROM books WHERE author = 'Author Name';
保证数据完整性是数据库设计中的重要方面,这通常通过定义约束来实现。约束可以是主键约束、唯一约束、非空约束和外键约束等。
CREATE TABLE authors (
author_id INT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
bio TEXT
);
CREATE TABLE books (
book_id INT PRIMARY KEY,
title VARCHAR(255) NOT NULL,
author_id INT,
FOREIGN KEY (author_id) REFERENCES authors(author_id)
);
5.2.2 事务管理与数据库安全
事务管理是确保数据库操作原子性、一致性、隔离性和持久性(ACID属性)的重要机制。在Python中,可以使用事务来确保一组操作要么全部成功,要么全部失败。
# 使用with语句自动管理事务
with conn_mysql.cursor() as cursor:
try:
# 开始事务
conn_mysql.begin()
# 执行多个数据库操作
cursor.execute("UPDATE books SET title = 'New Title' WHERE book_id = 1")
cursor.execute("INSERT INTO sales (book_id, quantity) VALUES (1, 5)")
# 提交事务
conn_mysql.commit()
except Exception as e:
# 回滚事务
conn_mysql.rollback()
print(f"Error: {e}")
数据库安全性是数据库管理系统的一个重要方面。它包括数据加密、权限控制和防止SQL注入等。在Python代码中应当使用参数化查询来防止SQL注入攻击。
# 使用参数化查询防止SQL注入
book_id = 1
cursor_mysql.execute("SELECT * FROM books WHERE book_id = %s", (book_id,))
通过在本章节中学习数据库连接与配置以及SQL语句的设计与执行,可以有效地在Python中管理数据库系统,并对图书信息管理系统的数据库进行高效的查询、更新和维护。随着系统复杂度的提升,理解并实践这些知识点将有助于构建稳定、可扩展的数据库解决方案。
6. MVC架构模式应用
6.1 MVC架构模式概述
6.1.1 模型、视图、控制器的角色与职责
MVC(Model-View-Controller)架构模式是一种将应用程序分为三个主要组成部分的设计模式,旨在通过分隔关注点来降低应用程序的复杂性,并提高系统的可维护性、可测试性和可重用性。
-
模型(Model) :模型是应用程序的业务逻辑部分。它处理数据和业务规则,与数据库或外部资源进行交互。在MVC中,模型不依赖于视图和控制器,它只是简单地提供数据,并在数据变化时通知观察者。
-
视图(View) :视图是用户界面部分,负责将数据展示给用户。视图通常只是显示模型的数据,并不包含任何处理逻辑。当模型中的数据发生变化时,视图会更新以反映这些变化。
-
控制器(Controller) :控制器是处理用户输入的部分,负责接收用户的输入并调用模型和视图来完成相应的任务。控制器解释用户的输入,决定执行哪些业务逻辑,并选择将数据呈现给用户的视图。
6.1.2 MVC在图书馆管理系统中的应用实例
在图书馆管理系统中,MVC架构模式可以帮助开发者构建一个清晰、松耦合的系统结构。例如:
-
模型 :图书信息模型包含书籍的各种属性(如书名、作者、ISBN等),以及获取和更新这些属性的方法。此外,模型还负责与数据库进行交互,执行添加、删除、修改和查询图书的操作。
-
视图 :图书目录视图会展示所有可用的图书列表,同时提供搜索框以让用户可以按照不同的条件检索图书。用户点击某本书时,详情视图会被激活,显示该书的详细信息。
-
控制器 :图书控制器处理用户的请求,如添加新书、删除书籍或修改书目信息。它将用户的操作转化为模型层的调用,并更新视图层以反映数据的变化。
6.2 MVC组件的实现与集成
6.2.1 模型的业务逻辑封装
模型组件通常是与数据库交互的逻辑层,它负责维护数据的一致性和完整性。
class Book:
def __init__(self, title, author, isbn):
self.title = title
self.author = author
self.isbn = isbn
# 假设有一个方法来保存数据到数据库
self.save_to_db()
def update_book_info(self, title, author, isbn):
self.title = title
self.author = author
self.isbn = isbn
# 更新数据库中的记录
self.save_to_db()
def delete_book(self):
# 从数据库中删除书籍记录
self.remove_from_db()
# 更多的模型方法...
在上述代码中,我们定义了一个简单的 Book 类,它具有保存、更新和删除书籍的方法。在实际应用中,这些方法将包含数据库操作的具体逻辑。
6.2.2 视图的用户界面渲染
视图负责向用户显示信息,并将用户请求转发给控制器。在Web应用中,视图可能是HTML模板,在桌面应用中可能是wxPython窗口。
import wx
class BookView(wx.Frame):
def __init__(self):
super().__init__(None, title="图书管理系统", size=(400, 300))
self.panel = wx.Panel(self)
self.book_list = wx.ListCtrl(self.panel, style=wx.LC_REPORT)
self.book_list.InsertColumn(0, '书名')
self.book_list.InsertColumn(1, '作者')
self.book_list.InsertColumn(2, 'ISBN')
# 填充书籍列表
self.populate_book_list()
def populate_book_list(self):
# 假设有一个方法可以从数据库获取所有书籍
books = self.get_books_from_db()
for book in books:
self.book_list.Append([book.title, book.author, book.isbn])
# 更多的视图逻辑...
上述代码创建了一个wxPython窗口,其中包含一个列表控件用于展示图书信息。实际应用中,视图层可能会更加复杂,涉及到更多的用户交互和数据绑定逻辑。
6.2.3 控制器的请求处理与流转
控制器是连接模型和视图的中间件,它根据用户的请求调用相应的模型方法,并决定将结果呈现给哪个视图。
class BookController:
def __init__(self):
self.model = Book()
self.view = BookView()
def add_book(self, title, author, isbn):
new_book = self.model.add_book(title, author, isbn)
self.view.book_list.Append([new_book.title, new_book.author, new_book.isbn])
def delete_book(self, isbn):
self.model.delete_book(isbn)
self.view.book_list.Delete(self.view.book_list.GetFirstSelected())
# 更多的控制器逻辑...
在上述控制器类中,我们定义了添加和删除图书的方法,这些方法触发模型层相应的操作,并更新视图层以反映最新的状态。
通过以上代码示例,我们可以看到模型、视图和控制器之间的交互关系。在实际开发中,还需要考虑如何将这些组件结合起来,以及如何处理组件间的依赖关系。使用MVC模式可以帮助开发者构建出结构清晰、易于维护的应用程序。
7. 系统维护与升级策略
系统维护与升级是任何软件项目中不可或缺的部分,尤其是在快速发展的IT行业中。一个健壮的系统需要不断的维护和更新来应对变化的需求、修复已知问题以及增强系统性能。本章节将聚焦于数据验证与错误处理以及版本控制与代码管理两个主要方面。
7.1 数据验证与错误处理
在任何系统中,数据验证和错误处理都是保证数据准确性和系统稳定性的重要手段。
7.1.1 输入验证与数据清洗
输入验证是确保用户输入数据符合预期格式的过程。数据清洗则是检查数据的准确性、完整性和一致性,去除无用数据,纠正错误的过程。
实施步骤:
- 设计一个输入验证机制,可以使用正则表达式、输入长度检查、范围检查等方法。
- 创建数据清洗规则,确保所有输入数据符合业务规则和格式要求。
- 利用日志记录所有验证和清洗过程中的事件,便于后续追踪和调试。
import re
def validate_email(email):
pattern = r"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$"
if not re.match(pattern, email):
raise ValueError("无效的电子邮件格式。")
return email
def clean_data(input_data):
# 假设数据为字典类型
cleaned_data = {}
for key, value in input_data.items():
if key == "email":
value = validate_email(value)
cleaned_data[key] = value
return cleaned_data
7.1.2 异常捕获与系统容错机制
异常捕获是系统处理运行时错误的一种方式,系统容错机制则包括了对错误处理的所有策略,以确保系统能够在出现错误时继续运行或者优雅地恢复。
实施步骤:
- 使用try-except语句块来捕获可能发生的异常。
- 为不同类型的异常提供不同的处理逻辑。
- 确保在异常处理逻辑中尽可能详细地记录错误信息,便于问题追踪。
try:
# 可能触发异常的代码
result = divide(a, b)
except ZeroDivisionError:
# 处理除数为零的异常情况
print("错误:除数不能为零。")
except Exception as e:
# 记录其他未预料的异常信息
logging.error(f"捕获到异常:{str(e)}")
else:
# 异常未发生时的逻辑
print("操作成功执行。")
finally:
# 无论是否发生异常都会执行的代码
print("操作结束。")
7.2 版本控制与代码管理
版本控制系统是软件开发中用于记录和管理源代码变更的工具。它不仅可以帮助开发团队协作开发,还可以提供回溯历史版本和分支管理的能力。
7.2.1 Git版本控制的基本使用
Git是一个流行的分布式版本控制系统。它允许开发者使用分支进行并行开发,每个分支都可以独立提交和更新代码。
基本命令:
-
git init:初始化一个新的Git仓库。 -
git add <file>:将文件添加到暂存区。 -
git commit -m "提交信息":将暂存区的更改提交到本地仓库。 -
git push:将本地仓库的更改推送到远程仓库。
7.2.2 代码的分支管理与合并策略
分支管理允许开发者在不影响主分支(通常是master或main)的情况下进行实验或开发新功能。合理地合并策略是确保代码质量和项目稳定的关键。
分支管理实践:
- 为新功能或错误修复创建独立的分支。
- 在推送分支到远程仓库之前,保持本地分支与主分支同步。
- 使用
git pull --rebase或git fetch && git rebase来保持分支的线性历史。
# 创建并切换到新分支
git checkout -b feature-branch
# 在feature-branch上开发新功能
# 完成开发后同步主分支
git checkout master
git pull
git checkout feature-branch
git rebase master
# 解决冲突,完成变基
# 将feature-branch合并到主分支
git checkout master
git merge feature-branch
在本章节中,我们讨论了系统维护与升级的关键策略,包括数据验证、错误处理、版本控制和代码管理。这些内容对于确保软件的长期成功至关重要,并且对于所有IT专业人员来说都是必须掌握的技能。在接下来的章节中,我们将继续探索其他提升软件质量和可维护性的高级话题。
简介:本系统通过Python3编程语言和wxPython图形用户界面库开发而成,旨在简化图书管理流程。系统利用Python3的高级特性和内置库支持,通过wxPython构建跨平台的应用界面,实现图书信息的增删改查功能。系统支持数据库操作,并采用MVC架构模式,结合数据验证、错误处理、事件驱动编程、异常处理、文件操作和版本控制等技术要点,为图书管理人员提供了一个全面且高效的管理工具。

















 269
269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









