






1. UWB室内定位概述:
UWB室内定位技术与传统通信技术有极大的差异,它不需要使用传统通信体制中的载波,而是通过发送和接收具有纳秒或纳秒级以下的极窄脉冲来传输数据,从而具有GHz量级的带宽。超宽带室内定位可用于各个领域的室内精确定位和导航,包括人和大型物品,例如贵重物品仓储、矿井人员定位、机器人运动跟踪、汽车地库停车等。
UWB室内定位系统与传统的窄带系统相比,具有穿透力强、功耗低、抗多径效果好、安全性高、系统复杂度低、能提供精确定位精度等优点。因此,UWB室内定位技术可以应用于室内静止或者移动物体以及人的定位跟踪与导航,且能提供十分精确的定位精度。例如作为UWB定位专家的EHIGH恒高,其自主研发生产的UWB室内定位系统可以达到优于10cm的定位精度。
2.UWB室内定位原理:
跟蓝牙和WIFI定位方法不同,UWB室内定位技术位置信息并不是基于信号强度(RSSI)进行计算,而是通过精确无线信号的发送时刻、接收时刻,并通过算法计算的。UWB无线定位系统要实现精确定位,首先要获取与位置相关的变量信息,建立相应的数学模型,然后根据这些变量和参数以及数学模型来解算目标的坐标。
UWB室内定位技术具有超高的时间分辨率,保证了UWB可以准确的获得待定位目标的时间和角度信息,信号飞行的速度是光速(固定值),所以只要知道飞行时间就可以计算出两个设备的距离,结合角度信息利用三角定位等几何定位方法求得待定位目标的位置信息。
在UWB室内定位技术中应用最广泛的是飞行时间测距法(TOF)和到达时间差法(TDOA)。从定位方式来看均属于多点定位,即确定标签与多个已知坐标点的相对位置关系定位。
3.UWB室内定位之TOF
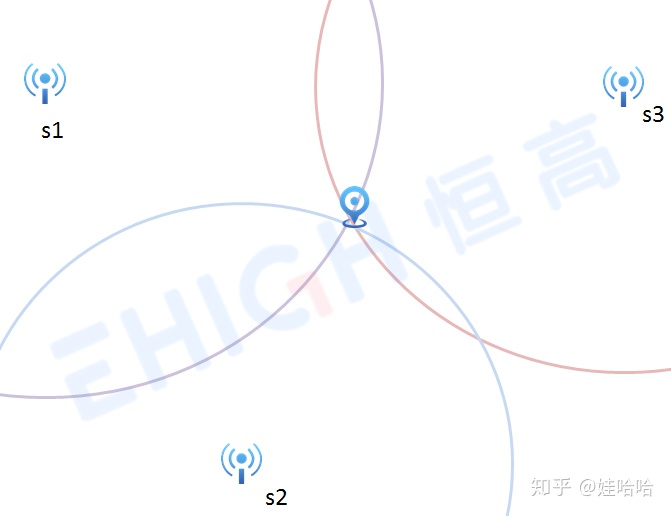
飞行时间法(Time of flight,TOF)是一种双向测距技术,它通过测量UWB信号在基站与标签之间往返的飞行时间来计算距离。根据数学关系,一点到已知点的距离为常数,那么这点一定在以已知点为圆心,以该常数为半径的圆上。有两个已知点,就有两个交点。以三个已知点和距离作三个圆,他们交于同一个点,该点就是标签的位置。
移动标签首先向定位基站发送测距请求,基站收到测距请求进行处理,经过一小段时间处理后向移动标签回复确认信息,分别记录 UWB 信号发送和接收的时间间隔,例如我们将发送端发出信号和接收回应的时间间隔记为TTOT,接收端收到数据包和发出回应的时间间隔记为TTAT。那么信号在空中的单向飞行时间TTOF可以计算为:
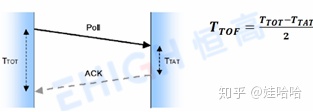
然后根据TTOF与电磁波传播速度的乘积便可算出标签到基站之间的距离。d = c × TTOF
根据到各个基站的测距信息,以各个基站为中心画圆,就可以得到一个交点,交点就是标签的位置。
4.UWB室内定位之上行TDOA
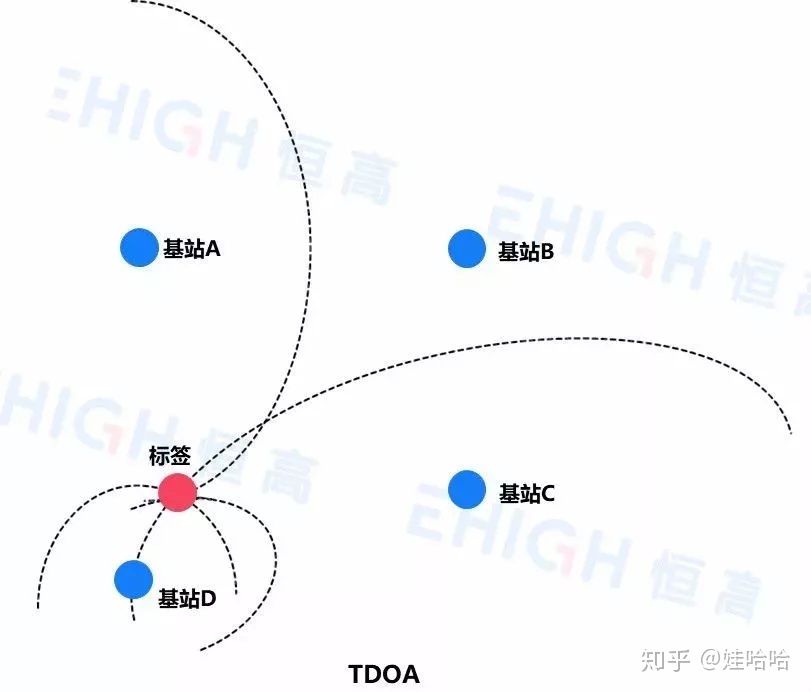
到达时间差(Time Difference of Arrival,TDOA)是一种利用到达时间差进行定位的方法又称为双曲线定位。标签卡对外发送一次UWB信号,在标签定位距离内的所有基站都会收到无线信号,如果有两个已知坐标点的基站收到信号,标签和基站的距离间隔不同,因此这两个收到信号的时间节点是不一样的,根据数学关系,到已知两点为常数的点,一定处于以这两点为焦点的双曲线上。那么有四个已知点(四个定位基站)就会有四条双曲线,四条双曲线交于一点就是标签的位置。
5.UWB室内定位之下行TDOA技术
简单的说就是定位基站发送定位信号,定位标签接收定位信号。这种工作方式和GPS类似,所以又叫室内GPS。下行TDOA是在终端进行位置坐标计算,同时EHIGH恒高的定位系统,可以通过标签上传这些数据到服务器,实时结算标签位置,这一点得归功于恒高室内定位系统自带的一套高实时性的物联传输网络。
下行TDOA的优势是,基站决定信号发送的时间,所以基站的功耗较低,并且跟GPS有着同样的优势,即该系统的容量无限大的,终端获取位置信息的延时也很小,这种模式,适合用于目标的独立导航。
在国内的UWB行业中,能实现UWB下行TDOA定位技术的公司屈指可数,EHIGH恒高正是其中一家,并且早在2016年的福清核电建设工地项目上就已经被成功应用了。














 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









