






程序员天天只顾写生活琐事的文章可就太对不起其他的程序员们了,某大佬给我在线寄了一张刀片的图片,催更技术分享,不得不动手了。从今年刚开始学习python,美妙的语法令人陶醉,好用的第三方库令人爱不释手。
由于能力有限,还在入门阶段,今天就分享一个小白级python爬虫实例。爬取最好大学网的大学高校排名并输出到csv文件中。还是那句话,代码入门级,人也是入门级,命名不规范处可轻喷。废话不多说,开始开始。
术语解释
网络爬虫是一种按照一定的规则,自动地抓取互联网信息的程序或者脚本。
说人话就是,通过运行代码,使机器模拟人访问服务器,快速获得互联网上需要的数据的一种技术。
第三方库
python近些年来发展速度如此之快,也很大程度上得益于其免费开源的特点,所有有技术的开发者,都可以为py社区贡献自己的力量,这就使得py拥有的第三方库数量众多,也为开发带来了极大的方便。
本次体验我们要用的库有:requests,Beautifulsoup。其中request库是爬虫常用的也是很专业的与与服务器交互的库,可用于请求服务器,接收服务器响应等网络操作。 Beautifulsoup库则是针对爬取下来的网站源码,进行解析。由于能力有限,篇幅有限,本次仅体验,库的安装以及其余用法可自行了解。
了解最好大学网
中国最好大学网,使用各项指标来进行综合评价,并列出各大高校以及排名,详情请看下图。
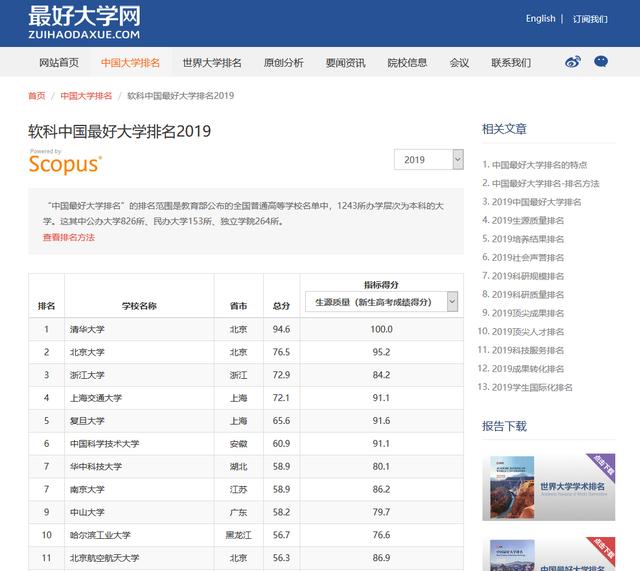
最好大学网
闲话不多聊,来看网站源码。可以看出,上图中显示的学校信息,都保存在表格当中。最顶层标签是<table>,下层依次是<tbody><tr><td>
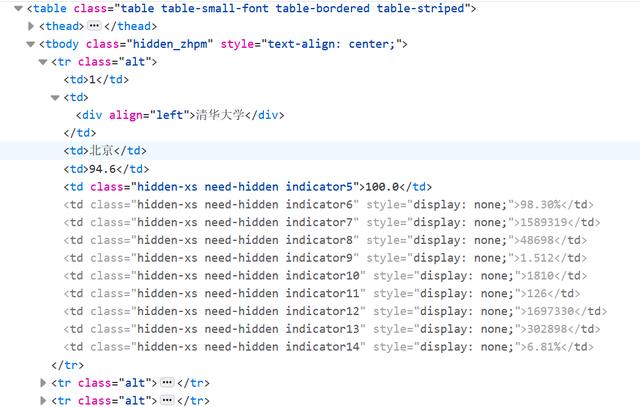
网站关键部分源码
了解这些之后,我们先来初步对本次爬虫进行模块划分,从大方面来说,可以分为三部分。
第一步: 获取网站源码,可定义函数 def getHTMLText(url) 第二步: 根据网站源码,使用Beautifulsoup库进 行解析,将解析结果返回。可定义函数 def fillUnivList(uList, html) 第三步: 将解析结果输出到文件,可定义函数 def printUnivList(uList, num)
代码编写
OK,开始动工: 首先导入需要的库
import bs4import requestsfrom bs4 import BeautifulSoup抓取源码
def getHTMLText(url): try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding return r.text except: print("异常") return ""提取html中关键数据,填充List
def fillUnivList(uList, html): soup = BeautifulSoup(html, "html.parser") for tr in soup.find("tbody").children: if isinstance(tr, bs4.element.Tag): # 去除字符串 只保留标签类型 tds = tr("td") #soup. find_all("tr")的简写 uList.append([tds[0].string, tds[1].string, tds[2].string, tds[3].string])列表输出到csv文件中
def printUnivList(uList, num): with open("D://daxue.csv", "w") as file: # print("{0:^10}{1:{4}^15}{2:^5}{3:^10}".format("排名", "学校名称", "省份", "总分", chr(12288))) for item in uList: file.write(",".join(item)) file.write("") # print("{0:^10}{1:{4}^15}{2:^5}{3:^10}".format(uList[i][0], uList[i][1], uList[i][2], uList[i][3],chr(12288)))定义主函数,依次执行三部分
def main(): unifo = [] url = "http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html" html = getHTMLText(url) fillUnivList(unifo, html) printUnivList(unifo, 20)main()结果如下:
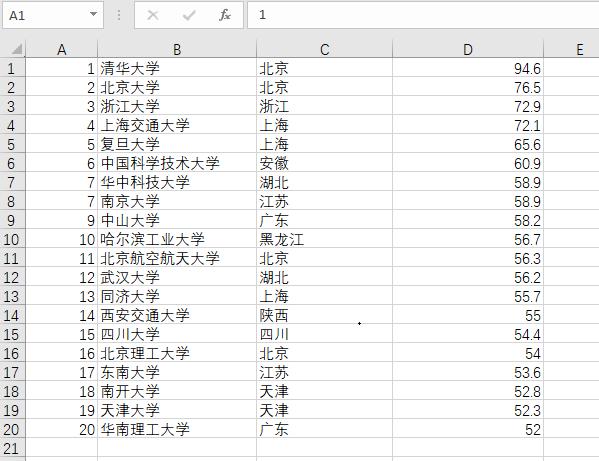
排名前20高校结果图
事后烟
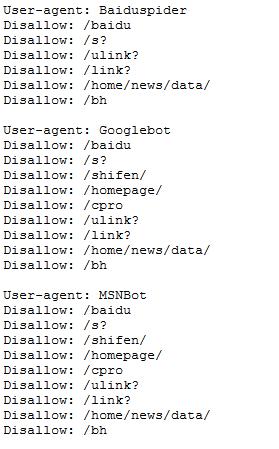
爬虫有风险,做事要谨慎。如今互联网上信息量巨大,各大型网站为防止恶意爬虫增加服务器负担,都做了负面清单,技术爱好者盗亦有道,一定要尽可能的遵循robots协议。可查看如下:"https://www.baidu.com/robots.txt"
需要免费学习资料可私小编或回复"资料 学习 领取免费资料















 1351
1351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









