






在爬取百度知道的时候,回答分为“最佳回答”和“其他回答”,分别存在两个id不同,class类似的div标签中,而爬虫是需要把所有回答都抓取的
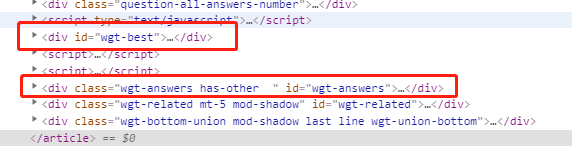
利用
div[id^=wgt-best],div[id^=wgt-answers]即可匹配到上述两个标签


在pyquery中的应用代码如下:
import requests
from pyquery import PyQuery as pq
question_url = 'http://zhidao.baidu.com/question/2144136671097683828.html?fr=iks&word=%E5%9B%BD%E6%B3%B0%E5%85%83%E9%91%AB&ie=gbk'
res2 = requests.get(question_url,headers=headers)
response2 = bytes(res2.text, res2.encoding).decode('gbk', 'ignore') # 转码
answer_list = pq(response2)("div[id^=wgt-best],div[id^=wgt-answers]").items() # 同时抓取两个div标签
print(answer_list) # 回答的数据列表















 4861
4861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









