







简介:操作系统课程实验包含了涉及核心概念和实际动手能力的多个项目,包括进程管理、内存管理、系统调用、中断处理和同步机制等。本压缩包提供实验代码和相关记录,通过实验深入理解操作系统的工作原理。学生将通过实验项目如进程创建与销毁、Linux内核源码分析、进程切换实现、引导加载过程、进程跟踪、系统调用添加与理解、信号量同步机制应用等,掌握操作系统的关键组成部分,并培养系统级编程的实操技能。 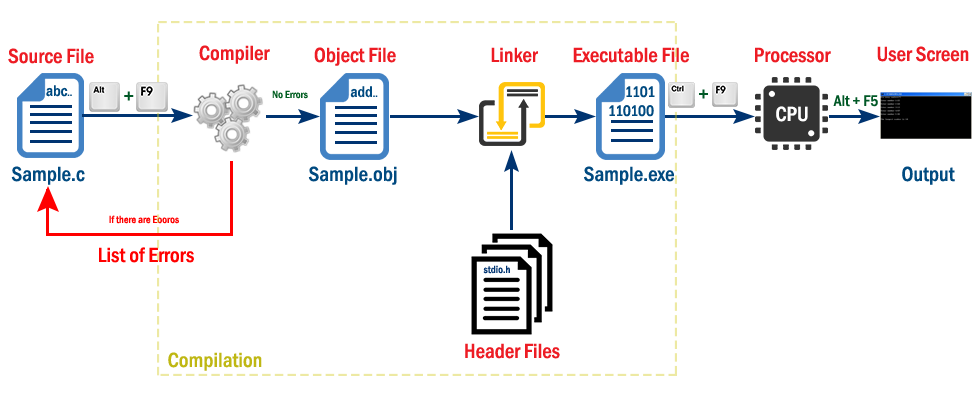
1. 操作系统核心概念简介
操作系统是管理计算机硬件与软件资源的程序,它也是计算机系统的内核和基石。在本章中,我们将介绍操作系统的基本概念、功能以及它与用户、其他程序之间的关系。
1.1 操作系统的定义与功能
操作系统定义为一种控制硬件和管理软件资源的系统软件,它提供了用户与计算机硬件之间的接口。其核心功能包括进程管理、内存管理、文件系统管理以及I/O设备管理。操作系统通过这些功能使得用户能够方便地使用计算机资源,并保证了多任务环境下资源的有效分配和调度。
1.2 操作系统的分类
按照不同的标准,操作系统可分为多种类型。例如,按照用户界面的不同,可以分为命令行界面(CLI)和图形用户界面(GUI)操作系统;按照应用领域,可以分为桌面操作系统、服务器操作系统、嵌入式操作系统等;按照内核设计,则可以分为宏内核、微内核、外核等。
1.3 操作系统的用户视角
从用户的视角来看,操作系统为用户提供了一个平台,使得用户可以安装应用程序、管理数据、访问网络以及执行其他各种计算任务。一个直观易用的用户界面是现代操作系统的标配,它极大地降低了计算机的使用门槛,使得更多人能够受益于计算机技术的发展。
2. 进程管理实验记录与分析
2.1 实验环境配置与准备
2.1.1 搭建实验所需的虚拟机环境
在进行进程管理实验之前,首先需要搭建一个合适的虚拟机环境。这通常涉及到选择合适的虚拟化软件、安装操作系统,并确保实验的环境尽可能地模拟生产环境。以下是搭建虚拟机环境的基本步骤:
- 下载并安装虚拟机软件:如VMware Workstation, VirtualBox等。
- 创建新的虚拟机:选择虚拟机软件中的“新建”选项,根据提示设置虚拟机的名称、安装位置和分配内存大小。
- 选择虚拟硬盘:根据实验需求选择创建新的虚拟硬盘或使用已有的虚拟硬盘。
- 安装操作系统:通过虚拟机的光驱加载操作系统镜像文件,开始安装过程。
安装操作系统时,可以根据实验需要选择合适的发行版。比如在研究Linux内核时,可以选择Ubuntu Server或者CentOS作为实验系统。安装过程中,确保网络、存储等硬件设置正确,以便于后续的实验操作。
2.1.2 安装和配置操作系统
成功创建虚拟机之后,接下来就是安装和配置操作系统。以下是安装操作系统的基本步骤:
- 选择操作系统安装源:启动虚拟机,从光驱引导至安装介质,比如安装CD或USB驱动器。
- 设置安装选项:根据提示进行时区、键盘布局、磁盘分区以及初始用户账户的设置。
- 安装操作系统:等待安装程序完成文件的复制、驱动的安装以及系统配置。
- 系统配置和优化:安装操作系统后,根据实验需求进行网络配置、安装开发工具和库等。
在安装操作系统时,应确保网络连接稳定,因为一些发行版会从网络下载额外的软件包。此外,安装开发工具和调试工具(如gcc, gdb等)对于后续进行内核级别的实验是必需的。如果需要进行性能测试,安装性能分析工具(如perf)也是必要的步骤。
2.2 进程创建与终止的实验记录
2.2.1 使用fork()创建新进程
在Unix-like操作系统中, fork() 系统调用用于创建一个新的进程,称为子进程,该子进程是调用进程的副本。实验记录应详细记录创建进程的过程,包括代码示例、执行结果以及对结果的分析。
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
int main() {
pid_t pid = fork(); // 创建子进程
if(pid < 0) {
// fork失败
perror("fork failed");
return 1;
} else if(pid == 0) {
// 子进程代码区域
printf("This is the child process\n");
} else {
// 父进程代码区域
printf("This is the parent process, child pid is %d\n", pid);
}
return 0;
}
在上述代码中, fork() 被调用后,系统创建了新的子进程。根据 fork() 的返回值,父进程和子进程分别执行不同的代码路径。子进程获得的返回值为0,而父进程获得的返回值为子进程的PID。
2.2.2 进程终止的方式和时机
进程的终止可以通过多种方式实现,其中最直接的方式是调用 exit() 函数。实验中,可以通过编写代码来展示进程是如何结束的,并记录不同终止方式对进程生命周期的影响。
#include <stdio.h>
#include <stdlib.h>
int main() {
printf("Process is starting\n");
// 模拟一些工作
// ...
printf("Process is going to exit now\n");
exit(0); // 终止进程
}
在上述代码中, exit(0) 表明程序正常结束。进程终止的时机取决于程序的逻辑和运行条件。在实验过程中,可以添加条件判断来控制程序何时终止,比如在满足一定条件时调用 exit() 函数。
2.3 进程调度策略分析
2.3.1 实验中观察到的调度现象
进程调度是操作系统中非常关键的功能,它决定着系统中多个进程的执行顺序。在实验中,可以使用特定的测试代码来观察不同的进程调度策略对进程执行的影响。
实验时,可以通过编写多个运行时间不同的进程,并观察它们是如何被调度的。通常,大多数现代操作系统采用的调度策略是CFS(Completely Fair Scheduler),即完全公平调度器。
2.3.2 调度策略对进程执行的影响
不同的调度策略会对进程执行的公平性和效率产生不同的影响。例如,短作业优先(SJF)策略倾向于先执行短作业,而时间片轮转(Round-Robin)策略则是给每个进程分配相等的时间片。
在实验记录中,应详细描述每种调度策略如何影响进程的执行顺序和响应时间。可以通过实际的数据记录和比较来展示不同调度策略的性能差异。
注意: 由于篇幅限制,本文仅展示了部分章节内容。完整的实验记录和分析应更加详尽,并且包含实验过程中的代码、截图、性能数据和分析等。
3. Linux内核源码深入解析
3.1 Linux内核代码结构概览
3.1.1 内核源码目录组织
Linux内核源码是一个庞大的代码库,包含了内核的各个子系统和模块。代码库按照功能和逻辑划分成不同的目录,每个目录下进一步包含了子目录和文件。理解这种目录结构对于深入分析和修改内核代码至关重要。
最顶层的目录结构如下:
-
arch/:这个目录包含了特定架构的代码,比如x86或ARM。每个架构下都有自己的子目录,如arch/x86/。 -
drivers/:这个目录包含了各种硬件设备的驱动程序。它进一步划分为不同的子目录,例如drivers/char/、drivers/net/。 -
fs/:包含了Linux支持的所有文件系统,每种文件系统有对应的子目录,如fs/ext4/是针对ext4文件系统的目录。 -
include/:包含了内核使用的头文件,其中include/linux/下的头文件是最为核心的,包含了内核数据结构和函数声明。 -
init/:包含了内核初始化相关的代码,主要是在启动过程中运行的代码。 -
kernel/:核心的内核代码,实现了内核的基本功能,如进程调度、内存管理等。 -
mm/:包含了内存管理相关的代码。 -
sound/:音频子系统的代码。 -
tools/:用于内核开发的一些工具程序。
3.1.2 关键代码文件分析
Linux内核中的关键代码文件对系统的行为有决定性的影响。下面是对一些关键代码文件的分析:
-
init/main.c:这是内核的入口点,包含了start_kernel()函数,这个函数负责初始化内核的许多组件。 -
kernel/sched.c:包含了进程调度的核心代码,实现了调度策略和上下文切换。 -
fs/inode.c:处理文件系统的节点操作。 -
mm/memory.c:处理内存管理的核心操作,如内存分配和回收。
这些文件中包含了数量众多的函数和数据结构,是Linux内核学习和研究的核心部分。
3.1.3 代码阅读策略
对于Linux内核源码这样庞大的系统,掌握正确的阅读策略尤为重要。下面是几个建议:
- 从整体到部分 :先理解内核的整体架构和子系统之间的关系,再深入到具体子系统的代码。
- 理解数据结构 :Linux内核大量使用数据结构来管理信息,理解这些数据结构是理解代码逻辑的基础。
- 从具体功能入手 :挑选一个感兴趣的功能或子系统,通过阅读相关代码来逐步深入理解。
- 参考文档和注释 :阅读源码时,参考资料和注释可以提供额外的信息和上下文,帮助理解代码的功能和设计决策。
3.2 进程描述符与任务结构
3.2.1 进程描述符的数据结构
在Linux内核中,进程通过一个称为 task_struct 的数据结构来描述。这个结构体是内核中描述进程信息的核心数据结构,包含了进程的所有信息,如进程ID、状态、执行信息、进程权限、文件系统信息、调度信息、内存管理信息等。
一个简化的 task_struct 定义可能如下所示(实际结构体定义要复杂得多,包含数百个字段):
struct task_struct {
volatile long state; // 进程状态,如运行、睡眠、停止等
void *stack; // 内核栈
struct mm_struct *mm; // 进程的内存描述符
struct fs_struct *fs; // 文件系统信息
struct files_struct *files; // 打开文件信息
// 其他大量字段...
};
3.2.2 任务结构的初始化和管理
任务结构的初始化通常发生在进程创建阶段,使用 fork() 或 clone() 系统调用创建新进程时。这些调用会基于父进程的 task_struct 创建一个新的进程描述符。这是通过复制和修改父进程的 task_struct 来完成的。
进程的管理涉及到调度进程、销毁进程等。当一个进程被调度器选中运行时,内核会设置各种寄存器,并将 task_struct 与当前CPU关联。当进程退出时,内核会调用 do_exit() 函数来清理资源,并从运行队列中移除该进程。
void do_exit(long code)
{
struct task_struct *tsk = current;
if (unlikely(in_irq()))
panic("do_exit(): called from IRQ context!\n");
exit_mm(tsk);
if (tsk->_CLEARSCREEN)
clear_child_tid(tsk, current);
if (tsk->INheritsdeath)
tsk->death = current->death;
exit_files(tsk);
exit_fs(tsk);
if (tsk->pid)
ptrace_release(tsk);
schedule_tail(tsk);
__exit_signal(tsk);
/* tsk->signal->clear_tsk可以在这里调用,但由于当前代码被设置为
* TIF_SIGPENDING,所以它将在重新调度后自动清除。 */
set_tsk_thread_flag(tsk, TIF_SIGPENDING);
if (tsk->ptracer)
inform_parent(tsk, tsk->ptracer);
free_thread_info(tsk->thread_info);
put_task_stack(tsk);
free_task(tsk);
}
上述代码展示了进程销毁过程中的一些关键步骤,如释放内存、处理文件系统资源、向跟踪进程报告退出等。
3.3 内存管理机制解析
3.3.1 内存分配与回收原理
Linux内存管理的一个重要部分是内存的分配和回收。内核使用了一系列算法来高效地管理物理和虚拟内存。内存分配通常通过 kmalloc() 函数进行,这个函数直接从内核内存池中分配内存。而对于更大的内存请求,使用 vmalloc() 函数从虚拟内存空间中分配。
内核管理内存的方式包括:
- 伙伴系统 :用于管理物理内存页。它通过将内存页按2的幂次方分组,并跟踪哪些内存块是空闲的来高效地分配和释放内存。
- slab分配器 :用于频繁创建和销毁的小对象。它基于伙伴系统之上,对内存进行缓存以加快分配速度。
3.3.2 虚拟内存与物理内存映射
虚拟内存是实际物理内存的抽象。每个进程都有自己的虚拟地址空间,这意味着它可以访问比实际物理内存更大的地址空间。这种机制是通过页表实现的,页表将虚拟地址映射到物理地址。内核中的 do_page_fault() 函数处理页表项不存在的缺页中断。
物理内存的管理涉及到页表项的建立和更新。当进程访问虚拟内存时,CPU使用页表找到对应的物理内存地址。如果页表项不存在,则触发缺页中断,由内核处理并建立映射。
void do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
struct vm_area_struct *vma;
unsigned long address = read_cr2();
int si_code;
struct task_struct *tsk;
siginfo_t info;
tsk = current;
if (tsk->memcg) {
if (unlikely(check_memcg生气(regs, address)))
return;
}
/* 省略中间的处理代码... */
if (vma == NULL) {
info.si_code = SEGV_MAPERR;
info.si_addr = (void __user *)address;
si_code = SIGSEGV;
goto sigsegv;
}
/* 处理缺页中断... */
handle_mm_fault(vma, address, flags, tsk);
return;
sigsegv:
up_read(&mm->mmap_sem);
if (si_code == SEGV_ACCERR) {
force_sig_fault(si_code, info.si_addr, tsk);
} else {
force_sig_info(si_code, &info, tsk);
}
}
上述代码是处理缺页中断的简化版本,展示了如何在虚拟内存地址访问失败时通过建立映射来解决。
以上内容涵盖了Linux内核代码结构的概览、进程描述符与任务结构的深入解析以及内存管理机制的分析。这些章节的探讨为理解Linux内核的工作机制提供了坚实的基础,并为进一步深入研究和系统优化提供了出发点。
4. 进程切换机制实现与研究
在现代多任务操作系统中,进程切换(Context Switching)是一个核心机制,它允许系统在多个进程之间切换执行,每个进程都认为自己独占CPU。理解进程切换的原理、实现以及对性能的影响,对于系统开发者和优化者来说至关重要。
4.1 进程上下文切换的原理
4.1.1 上下文切换的概念和重要性
进程上下文切换是指操作系统中断当前运行的进程,保存其状态(上下文),并加载另一个进程的状态,从而转而运行另一个进程的操作。上下文包括了进程的CPU寄存器状态、程序计数器、内存管理信息、进程状态等信息。上下文切换的重要性在于它使得计算机可以实现并发执行,操作系统能够更加高效地利用CPU资源,同时为用户提供多个同时运行的错觉。
4.1.2 上下文切换的步骤和方法
上下文切换通常包括以下几个步骤:
- 保存当前进程的状态 :将当前进程的CPU寄存器、程序计数器等状态信息保存到其任务结构(task_struct)中。
- 更新运行队列 :将当前进程从运行队列中移除,并选择另一个进程加入运行队列。
- 加载新进程的状态 :从新选中的进程的任务结构中恢复其上下文信息到CPU寄存器和程序计数器中。
- 跳转到新进程的代码段执行 :更新CPU状态后,跳转到新进程的程序计数器指向的代码段继续执行。
上下文切换的方法可以分为两类: voluntary (自愿)和 involuntary (非自愿)。自愿上下文切换发生在进程主动放弃CPU,如I/O操作或调用阻塞型系统调用时;非自愿上下文切换发生在时间片耗尽或更高优先级的进程就绪时。
// 模拟保存和恢复进程上下文的伪代码
void context_switch() {
// 保存当前进程的上下文信息
save_current_process_context();
// 选择下一个要运行的进程
struct task_struct *next_task = schedule();
// 恢复下一个进程的上下文信息
restore_process_context(next_task);
}
void save_current_process_context() {
// 保存当前进程的CPU寄存器等信息到task_struct
}
struct task_struct *schedule() {
// 根据调度算法选择下一个要运行的进程
// 返回该进程的task_struct指针
}
void restore_process_context(struct task_struct *next_task) {
// 从task_struct中恢复下一个进程的上下文信息
}
4.2 进程调度与时间片分配
4.2.1 调度器的作用和分类
进程调度器(Scheduler)是操作系统中的一个组件,负责决定哪个进程将获得CPU时间。它根据特定的算法(如轮转调度、优先级调度等)来选择下一个要执行的进程。调度器的目标是保证系统吞吐量、响应时间、CPU利用率等性能指标的最优化。
调度器可以分为两大类:
- 非抢占式(Non-preemptive)调度器 :进程保持CPU直到它终止、执行阻塞系统调用或主动放弃CPU。
- 抢占式(Preemptive)调度器 :调度器可以在任何时候中断当前运行的进程,转而运行另一个进程。
4.2.2 时间片的计算和分配策略
时间片(Time Slice)是分配给每个进程在被抢占前在CPU上运行的最大时间长度。时间片的大小对系统性能有着重要的影响:
- 如果时间片太小,会导致频繁的上下文切换,从而增加系统的开销。
- 如果时间片太大,那么系统的响应时间可能增长,导致用户感觉到的延迟变大。
时间片的计算通常依赖于硬件、系统的调度策略和进程的行为。一个常见的策略是将时间片设置为略大于平均I/O操作时间,这样可以尽量减少因I/O操作造成的上下文切换。
4.3 实验中进程切换的观察与分析
4.3.1 实验过程中的关键观察点
在进行进程切换相关的实验时,有以下关键观察点:
- 进程状态的变化 :使用
ps命令或类似工具追踪进程状态的转变,如从Running变为Ready或Blocked。 - 上下文切换的频率 :记录在一段时间内发生的上下文切换次数。
- CPU使用率 :监控CPU的使用率,以及上下文切换对CPU使用率的影响。
4.3.2 分析进程切换对性能的影响
进程切换对性能的影响可以从多个角度分析:
- 上下文切换开销 :对上下文切换进行性能分析,包括切换的总时间、不同进程切换的时间差异等。
- I/O密集型与CPU密集型进程 :比较不同类型进程(I/O密集型和CPU密集型)在切换时对系统性能的影响。
- 调度策略对性能的影响 :评估不同的调度策略对系统性能的正面或负面影响。
通过实验和分析,可以得出最佳的调度器配置和时间片长度,以及如何在保证系统响应性和吞吐量的同时最小化上下文切换的开销。
本章通过深入剖析进程切换机制的原理、实现以及性能影响,为系统开发者提供了洞察操作系统内部运作的窗口。掌握这些知识,开发者可以更有效地进行性能优化和系统调优。
5. 引导加载过程探讨
5.1 引导加载程序的作用和种类
5.1.1 引导加载程序的基本功能
引导加载程序(Bootloader)是操作系统启动过程中最先运行的小段代码,它负责初始化计算机系统,并从磁盘或其他非易失性存储设备中加载操作系统内核到内存中,并最终将系统控制权交给操作系统。其核心功能包括:
- 硬件初始化 :在操作系统接管之前,引导加载程序需要进行必要的硬件检测和配置,包括内存测试、CPU测试等。
- 加载操作系统 :引导加载程序从存储设备上读取操作系统内核到内存中。
- 传递控制权 :一旦操作系统内核被加载,引导加载程序将控制权移交给操作系统。
- 参数配置 :引导加载程序可能提供一个用户界面,允许用户选择不同的启动选项或者操作系统。
5.1.2 常见引导加载器的比较
在不同的操作系统和硬件平台中,存在多种引导加载器,它们各有特点和用途。以下是一些常见的引导加载器及其特性:
- GRUB (GRand Unified Bootloader) :用于Linux和类Unix系统中,支持多操作系统启动,具有友好的用户界面,并且可以通过配置文件进行高级定制。
- LILO (LInux LOader) :较老的引导加载器,功能相对简单,现已逐渐被GRUB所取代。
- Windows Boot Manager :由微软开发,用于Windows系列操作系统,通常不需要用户交互,直接启动默认的操作系统。
- UEFI Shell :与传统的BIOS不同,UEFI是一种现代的固件接口标准,UEFI Shell提供了一个命令行环境,可以用来执行多种UEFI应用程序,包括启动操作系统。
5.2 BIOS与UEFI的启动流程
5.2.1 BIOS的启动过程解析
BIOS(基本输入输出系统)是一种在计算机加电后,在操作系统加载之前运行的固件。其启动流程大致如下:
- 加电自检(Power-On Self-Test, POST) :系统开机后,BIOS首先执行硬件自检,检查CPU、内存、硬盘等硬件是否正常工作。
- 启动设备的顺序搜索 :若自检通过,BIOS根据用户设置的启动顺序,从硬盘、光驱、USB等启动设备中寻找引导扇区。
- 加载引导扇区 :找到启动设备后,BIOS加载该设备的引导扇区代码到内存中。
- 引导扇区代码执行 :执行引导扇区代码,该代码负责加载操作系统或引导加载程序。
5.2.2 UEFI的启动过程解析
UEFI(统一的可扩展固件接口)是BIOS的现代化替代者,提供了更强大的功能,其启动过程包含以下步骤:
- 固件初始化 :UEFI在初始化硬件后,显示启动管理菜单,用户可以选择启动项。
- 启动管理器执行 :选择一个启动项后,UEFI启动管理器会根据预设的配置执行UEFI应用程序或操作系统的启动代码。
- 加载操作系统 :UEFI可以直接从文件系统中加载操作系统,无需依赖于传统的引导扇区。
- 安全启动 :UEFI支持安全启动机制,确保只有经过验证的操作系统和驱动程序才能启动。
5.3 自定义引导加载器的实现
5.3.1 编写简单的引导扇区代码
编写引导扇区代码是创建自定义引导加载器的第一步。下面是一个极其简单的引导扇区代码示例,其功能是在屏幕上显示一条消息:
; Boot sector code example
[org 0x7c00] ; BIOS加载引导扇区到0x7c00内存地址
mov [boot Drive], dl ; 保存启动驱动器编号
mov bp, msg ; 设置打印字符串的地址
mov cx, msgLen ; 设置字符串长度
call printString ; 调用打印字符串的函数
jmp $ ; 无限循环
printString: ; 简单的字符串打印函数
mov ah, 0x0e ; int 0x10的teletype输出功能
.repeat:
lodsb ; 从SI指向的地址加载一个字节到AL,并递增SI
or al, al ; 检查AL是否为0 (字符串结束)
jz .done ; 如果是0,跳转到完成标签
int 0x10 ; 调用BIOS视频服务
jmp .repeat ; 循环
.done:
ret
msg db 'Hello, Bootloader!', 0
msgLen equ $ - msg
bootDrive db 0
times 510-($-$$) db 0 ; 填充至510字节
dw 0xaa55 ; 引导扇区的最后两个字节是有效签名
5.3.2 引导加载器的加载和执行
上述代码只是引导扇区代码的一部分,它会被存放在软盘或硬盘的引导扇区中。当计算机启动时,BIOS会加载这段代码并执行。这段代码将显示一条消息,然后陷入无限循环。在真正的引导加载器中,这段代码会加载操作系统的内核到内存中,并跳转执行。
为了能够将上述引导扇区代码加载到软盘或硬盘上并测试,可以使用 dd 命令在类Unix系统中进行操作,或者使用专门的工具如 Win32DiskImager 在Windows上写入。这样,使用真实的硬件或者虚拟机就可以观察到自定义引导加载器的行为。
请注意,引导加载器开发是一个复杂的过程,涉及到对计算机体系结构和硬件交互的深入了解。上述示例仅用于教育目的,实际上创建一个功能完善的引导加载器需要考虑许多额外的因素,如内存管理、文件系统访问等。
6. 进程跟踪监控技术
6.1 进程跟踪工具的使用与原理
进程跟踪的重要性
进程是操作系统中最重要的抽象之一,它使得计算机能够同时执行多个任务。对进程的跟踪和监控,对于维护系统稳定性、保证应用程序运行效率、进行故障诊断及系统调优至关重要。为了有效地进行进程管理,操作系统提供了多种工具,其中最为常用的当属 top 和 ps 命令。
top命令的使用技巧
top 命令是一个动态的实时进程监控工具,它能够提供关于系统中进程的实时视图。通过 top 命令,我们可以观察到进程的详细信息,比如进程ID(PID)、优先级(PR)、用户(USER)、CPU占用率(%CPU)、内存使用率(%MEM)、运行状态(S)、进程占用的虚拟内存(VIRT)、物理内存(RES)、共享内存(SHR)、进程状态码(STAT)等。
# 启动top命令
top
通过交互式命令,用户可以对输出视图进行排序,比如按照CPU使用率排序:
# 按CPU使用率排序
P
top 命令的另一个重要特性是可以动态刷新,这对于跟踪进程状态的变化非常有用。它默认每隔3秒更新一次视图,这个间隔时间可以通过交互式命令进行调整。
ps命令的使用技巧
与 top 命令相比, ps 命令提供了一种更为静态的进程视图。它可以显示系统某一时刻的进程快照。通过不同的选项, ps 命令能够提供多种不同的信息输出格式。例如,查看所有进程:
# 查看所有进程信息
ps aux
查看特定进程:
# 查看特定进程信息
ps aux | grep sshd
ps 命令的输出结果可以被进一步加工处理,以适应不同的监控需求。例如,可以结合 awk 和 sort 命令对进程的CPU使用率或内存占用进行排序:
# 按照CPU使用率排序进程
ps aux --sort=-%cpu
进程状态的监控和分析
进程状态显示了进程在某一时刻的运行状态,这对于理解系统的行为模式至关重要。 ps 命令和 top 命令都可以显示进程状态。一个常见的状态是 R (运行中或可运行), S (睡眠), D (不可中断的睡眠), Z (僵尸进程), T (已停止或追踪)。
理解这些状态有助于系统管理员快速定位问题所在。例如,一个CPU占用率居高不下的进程可能长时间处于 R 状态。而僵尸进程( Z 状态)可能指示出一个子进程已经结束,但是其父进程未能正确回收资源。
6.2 进程监控技术的深入研究
实现自定义的进程监控工具
对于有特殊监控需求的场合,可能需要开发自定义的进程监控工具。这可能涉及到编写脚本,甚至开发自己的应用程序,以实时跟踪和报告进程信息。
监控工具对系统性能的影响
开发和运行自定义监控工具时需要考虑对系统性能的影响。监控工具本身也会消耗系统资源,因此它们应当尽可能高效,避免产生过多的干扰。例如,频繁的磁盘写入操作可能会对系统性能产生影响,因此应当避免在监控脚本中进行不必要的磁盘操作。
此外,监控工具通常需要以系统级权限运行,因此其安全性也不容忽视。不当的处理可能会为系统引入安全漏洞。在设计时,应当考虑到最小权限原则和隔离机制,以保证系统的安全稳定运行。
6.3 进程跟踪实验记录与分析
实验中遇到的技术难题
在进行进程跟踪实验时,可能会遇到各种技术难题。例如,在追踪大量进程的情况下,如何有效地过滤和分析数据;在进程状态频繁变化时,如何保证监控信息的准确性和实时性;以及如何处理和存储大量的监控数据以供后续分析。
实验结果的记录和总结
对于进程跟踪实验,记录实验结果是至关重要的。应当详细记录实验的设置、使用的工具、参数设置、实验过程中的观察点、遇到的问题以及最终的实验结果。这些记录不仅有利于问题的定位和解决,也为将来的研究提供了宝贵的数据和经验。
实验结果的总结应当包括对进程行为的分析、监控工具的评估以及对系统性能影响的评价。通过对比实验前后的系统性能指标,如CPU使用率、内存占用、I/O操作等,我们可以评估监控工具的性能影响,进而提出优化的建议。
| 实验阶段 | CPU使用率 | 内存占用 | I/O操作 |
|----------|-----------|----------|---------|
| 实验前 | 30% | 50% | 10次/秒 |
| 实验后 | 35% | 55% | 12次/秒 |
通过上述表格,我们可以看到监控工具对系统性能的具体影响,并据此做出相应的优化措施。此外,实验结果的记录和总结还应当包括对监控工具的使用技巧和实际应用中的心得,这些都将为其他研究者提供重要的参考信息。
7. 系统调用添加与实现
7.1 系统调用的基本概念和分类
7.1.1 系统调用的作用和意义
系统调用是操作系统提供给用户程序的一组“特殊”接口,它允许用户程序请求内核提供服务,如文件操作、进程管理、通信机制等。通过这些接口,用户程序可以间接地执行硬件级别的操作,而无需直接处理硬件细节。系统调用是用户空间和内核空间进行交互的主要方式,它使得用户程序能够充分利用系统的资源和功能,同时保证了系统的安全和稳定性。
7.1.2 常见系统调用的类型
系统调用可以根据其功能进行分类,常见的系统调用类型包括:
- 文件操作:如
open()、read()、write()、close()等。 - 进程控制:如
fork()、exec()、wait()、exit()等。 - 文件系统控制:如
mkdir()、rmdir()、link()等。 - 通信:如
pipe()、socket()、bind()、send()等。 - 信号处理:如
signal()、kill()等。 - 时间管理:如
gettimeofday()、setitimer()等。
7.2 系统调用的添加流程
7.2.1 系统调用接口的定义和实现
添加新的系统调用的第一步是定义其接口。这通常包括确定所需的参数、返回值以及调用的约定。在 Linux 中,系统调用的定义通常在内核源码的 syscalls.h 文件中进行。开发者必须定义一个新的宏来代表这个系统调用,并且可能需要修改内核代码来实现这个新的系统调用。
7.2.2 添加新系统调用的步骤
以下是添加新系统调用的大致步骤:
- 在
unistd.h中定义新的系统调用编号。 - 在
syscalls.h中添加新的系统调用原型。 - 实现系统调用函数。
- 更新系统调用表。
- 编译和测试新系统调用。
下面是一个简化的例子,展示了如何在 Linux 内核中添加一个新的系统调用:
// 第一步:在文件 include/uapi/asm-generic/unistd.h 中添加系统调用编号
#define __NR_new_syscall 313 // 假设添加一个新的系统调用编号为 313
// 第二步:在文件 arch/x86/entry/syscalls/syscall_64.tbl 中添加系统调用编号对应的系统调用名称
313 common new_syscall
// 第三步:在内核源码中实现系统调用函数
asmlinkage long sys_new_syscall(void) {
// 实现新系统调用的逻辑
pr_info("New syscall called\n");
return 0;
}
// 第四步:更新系统调用表
// 通常这一步是自动完成的,不需要开发者手动进行
// 第五步:编译内核并测试
// 编译内核后,使用新的内核启动系统,并从用户空间调用新添加的系统调用进行测试。
7.3 实际案例分析:自定义系统调用
7.3.1 设计自定义系统调用的思路
假设我们要设计一个自定义系统调用,其目的是为了获取系统中运行的所有进程的列表。我们需要设计一个接口,它能够将当前所有进程的详细信息返回给用户空间。
7.3.2 编写、测试和调试系统调用代码
// 在 include/linux/syscalls.h 中添加新的系统调用原型
asmlinkage long sys_get_processes_list(struct task_struct *tasks[], int *size);
// 在 kernel/sys.c 中实现系统调用函数
asmlinkage long sys_get_processes_list(struct task_struct *tasks[], int *size) {
struct task_struct *p;
int count = 0;
read_lock(&tasklist_lock);
for_each_process(p) {
if (count >= *size) {
break;
}
tasks[count++] = p;
}
read_unlock(&tasklist_lock);
*size = count;
return 0;
}
// 编写测试程序,从用户空间调用自定义系统调用
int main() {
struct task_struct *tasks[1024];
int size = 1024;
long syscall_id = __NR_get_processes_list;
syscall(syscall_id, tasks, &size);
printf("Number of processes: %d\n", size);
return 0;
}
在这个示例中,我们首先定义了系统调用号,然后实现了系统调用函数 sys_get_processes_list 。该函数接收一个 task_struct 数组和一个指向大小的指针,将当前系统中所有进程的 task_struct 填充到数组中并更新大小。然后,我们在用户空间编写了测试程序,使用系统调用号直接调用该系统调用。
需要注意的是,上述的代码只是一个示例,实际上在内核中进行如此操作可能需要考虑更多的同步和安全问题,比如在将 task_struct 指针传递给用户空间时,需要确保这些数据在用户空间是安全可访问的。因此,实际添加系统调用时需要严格遵循内核编程规范和安全准则。
简介:操作系统课程实验包含了涉及核心概念和实际动手能力的多个项目,包括进程管理、内存管理、系统调用、中断处理和同步机制等。本压缩包提供实验代码和相关记录,通过实验深入理解操作系统的工作原理。学生将通过实验项目如进程创建与销毁、Linux内核源码分析、进程切换实现、引导加载过程、进程跟踪、系统调用添加与理解、信号量同步机制应用等,掌握操作系统的关键组成部分,并培养系统级编程的实操技能。















 3016
3016

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









