







入门网络数据爬取,也就是Python爬虫
现实中我们使用浏览器访问网页时,网络是怎么运转的,做了什么呢?
首先,必须了解网络连接基本过程原理,然后,再进入爬虫原理了解就好理解的多了。
1、网络连接原理
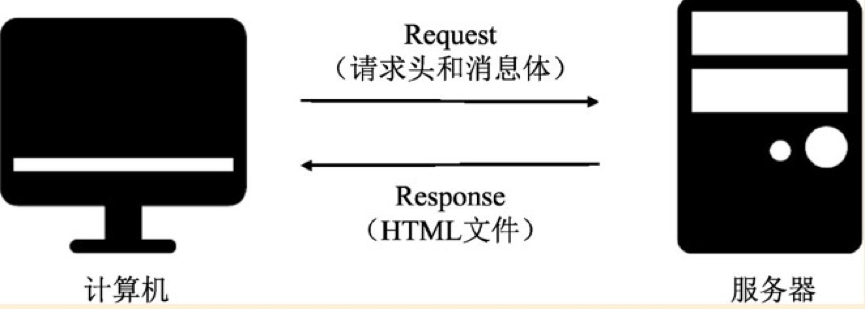
如上图,简单的说,网络连接就是计算机发起请求,服务器返回相应的HTML文件,至于请求头和消息体待爬虫环节在详细解释。
2、爬虫原理
爬虫原理就是模拟计算机对服务器发起Request请求,接收服务器端的Response内容并解析,提取所需要的信息。
往往一次请求不能完全得到所有网页的信息数据,然后就需要合理设计爬取的过程,来实现多页面和跨页面的爬取。
多页面爬取过程是怎样的呢?
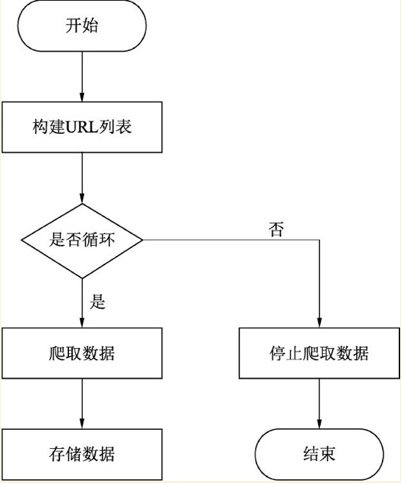
基本思路:
1、由于多页面结构可能相似,可以先手动翻页观察URL
2、得到所有URL
3、根据每页URL定义函数爬取数据
4、循环URL爬取存储
跨页面爬取过程是怎样的呢?
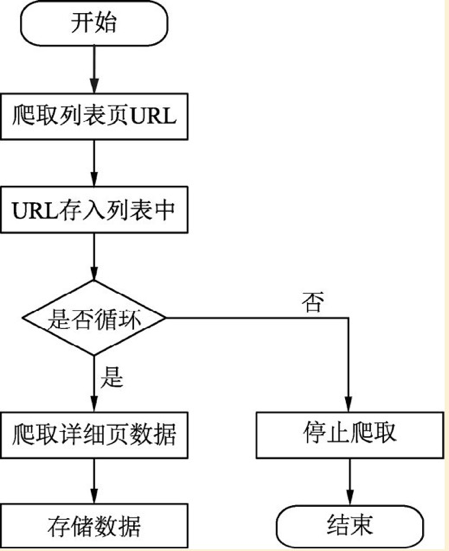
基本思路:
1、找到所有URL
2、定义爬取详细页函数代码
3、进入详细页获取详细数据
4、存储,循环完成,结束
3、网页到底是怎么样的呢?
右键选择“检查”,打开网页源代码,可以看到上面是HTML文件,下面是CSS样式,其中HTML中包含的部分就是JavaScript代码。
我们浏览的网页就是浏览器渲染后的结果,就是把HTML、CSS、JavaScript代码进行翻译得到的页面界面。有一个通俗的比喻就是:加入网页是一个房子,HTML就是房子的框架和格局,CSS就是房子的软装样式,如地板和油漆,javaScript就是电器。
如打开百度搜索,将鼠标移至“百度一下”按钮位置,右键选择“检查”,就可以看到网页源码位置。
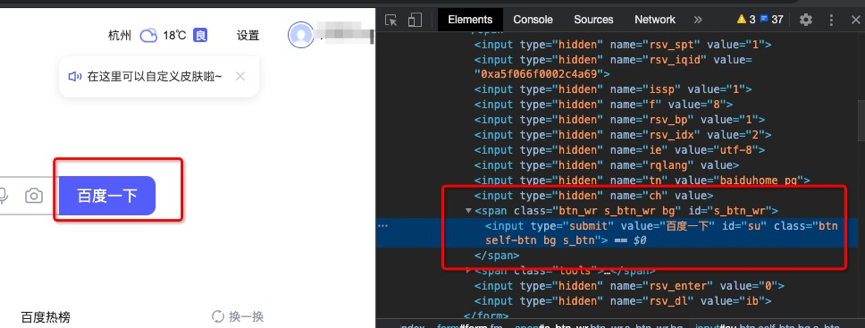
或者直接打开右键源码,通过点击网页源码页面左上角鼠标状图标,然后移动到网页的具体位置,就可以看到。
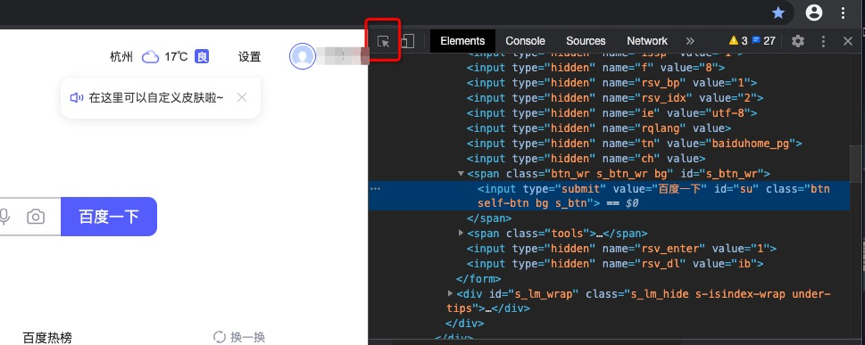
总结一下:爬取数据就是发起请求,得到网页信息,然后找到你要的信息,但是在请求的过程中,很容易被反扒,禁止爬取动作,所以,需要很多技巧绕过反扒机制,这一点后续我们逐一解答。
--每天一小步,未来一大步!














 2385
2385











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









