






Spark Streaming 是构建在Spark Core基础之上的实时计算框架(或流计算框架),它扩展了Spark 处理大规模流式数据的能力。
Sparking Streaming 可以整合多种输入数据源,如Kafka、Flume、HDFS、TCP socket等等,经过处理的数据可以存储到HDFS、数据库和Dashboard等等。

一、Spark Streaming基本原理和执行流程
Spark Streaming的基本原理是将实时输入数据流以时间片(秒级)为单位进行拆分,然后经过Spark Engine以类似批处理的方式处理每个时间片数据,执行流程如下图示。
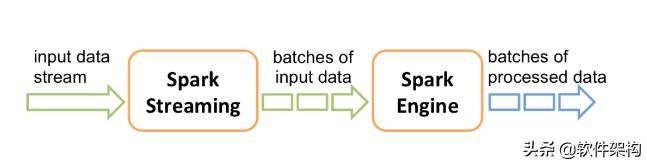
Spark Streaming 最主要的抽象是DStream(Discretized Stream,离散化数据流),表示连续不断的数据流。在内部实现上,Spark Streaming的输入数据按照时间片(如1s),每一段数据转换为Spark 中的RDD,DStream表示为RDD序列(DStream 由连续的序列化 RDD 来表示)。

将连续问题离散化处理:
- 以时间为单位将数据流切分成离散的数据单位;
- 将每批数据看做RDD,使用RDD操作符处理;
- 最终结果以RDD为单位返回;
在 Spark Streaming 中,处理数据的单位是一批而不是单条,而数据采集却是逐条进行的,因此 Spark Streaming 系统需要设置间隔使得数据汇总到一定的量后再一并操作,这个间隔就是批处理间隔。批处理间隔是 Spark Streaming 的核心概念和关键参数,它决定了 Spark Streaming 提交作业的频率和数据处理的延迟,同时也影响着数据处理的吞吐量和性能。
以单词统计为例,每个时间片的数据(行数据的RDD)经过flatMap操作,生成了存储单词的RDD。

二、用Spark Streaming实现实时WordCount
首先需要引入Spark Streaming的依赖jar包。
org.apache.spark
spark-streaming_2.12
2.4.3
编写NetworkWordCount 类,实现单词统计逻辑。
这个程序就是从tcp sockets中读取数据,并做单词统计(WordCount),时间间隔是1秒,结果输出在屏幕上。
package com.rickie.sparkstreaming;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.StorageLevels;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
public class NetworkWordCount {
public static void main(String[] args) throws InterruptedException {
System.out.println("Hello World.");
if(args.length < 2) {
System.err.println("Usage: NetworkWordCount ");
System.exit(1);
}
// Create a local StreamingContext with two working thread and batch interval of 1 second
SparkConf conf = new SparkConf().setMaster("local[2]").setAppName("NetworkWordCount");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
// 设置日志级别
jssc.sparkContext().setLogLevel("WARN");
// 创建了一个DStream,从Socket中接受数据 hostname:port, like localhost:9999
JavaReceiverInputDStream lines = jssc.socketTextStream(args[0],
Integer.parseInt(args[1]), StorageLevels.MEMORY_AND_DISK_SER);
// 以空格把收到的每一行数据分割成单词
JavaDStream words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
// 在本批次内计单词的数目
JavaPairDStream pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairDStream wordCounts = pairs.reduceByKey((i1, i2) -> i1 + i2);
// Print the first ten elements of each RDD generated in this DStream to the console
// 打印每个RDD中的前10个元素到控制台
wordCounts.print();
jssc.start(); // 启动计算
jssc.awaitTermination(); // 等待计算结果
System.out.println("Well done!");
}
}
编译打包,生成 tutorial-1.0.jar包,复制到Spark 运行环境中。
三、单词统计WordCount测试
下面进行具体的应用测试。
(1)为了运行NetworkWordCount,首先我们需要运行一个netcat server(Linux CentOS 7环境)。
nc -lk 9999
(2)然后,另开一个shell窗口,提交NetworkWordCount任务。
/usr/local/spark/bin/spark-submit --class "com.rickie.sparkstreaming.NetworkWordCount" tutorial-1.0.jar localhost 9999
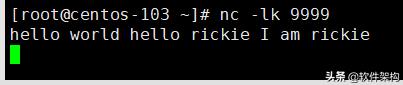
(3)在nc上发送消息,消费端接收消息,然后并进行单词统计计算。
如下图所示,输入一些文字,并回车。
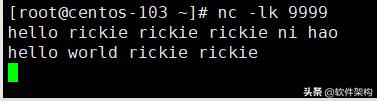
(4)我们就可以在Spark 运行窗口观察到如下的信息。

为了避免Spark 应用输出信息的干扰,可以添加 2>&1 | grep "rickie" 命令行参数,方便捕捉输出的信息。
/usr/local/spark/bin/spark-submit --class "com.rickie.sparkstreaming.NetworkWordCount" tutorial-1.0.jar localhost 9999 2>&1 | grep "rickie"

如下是在 nc窗口输入的信息。
参考链接:
Spark Streaming Programming Guide
http://spark.apache.org/docs/latest/streaming-programming-guide.html
Spark Streaming 新手指南
https://www.ibm.com/developerworks/cn/opensource/os-cn-spark-streaming/index.html















 948
948











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









