package cn.kgc.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
//创建WordCount运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//创建Spark上下文环境对象(连接对象)
val sc = new SparkContext(sparkConf)
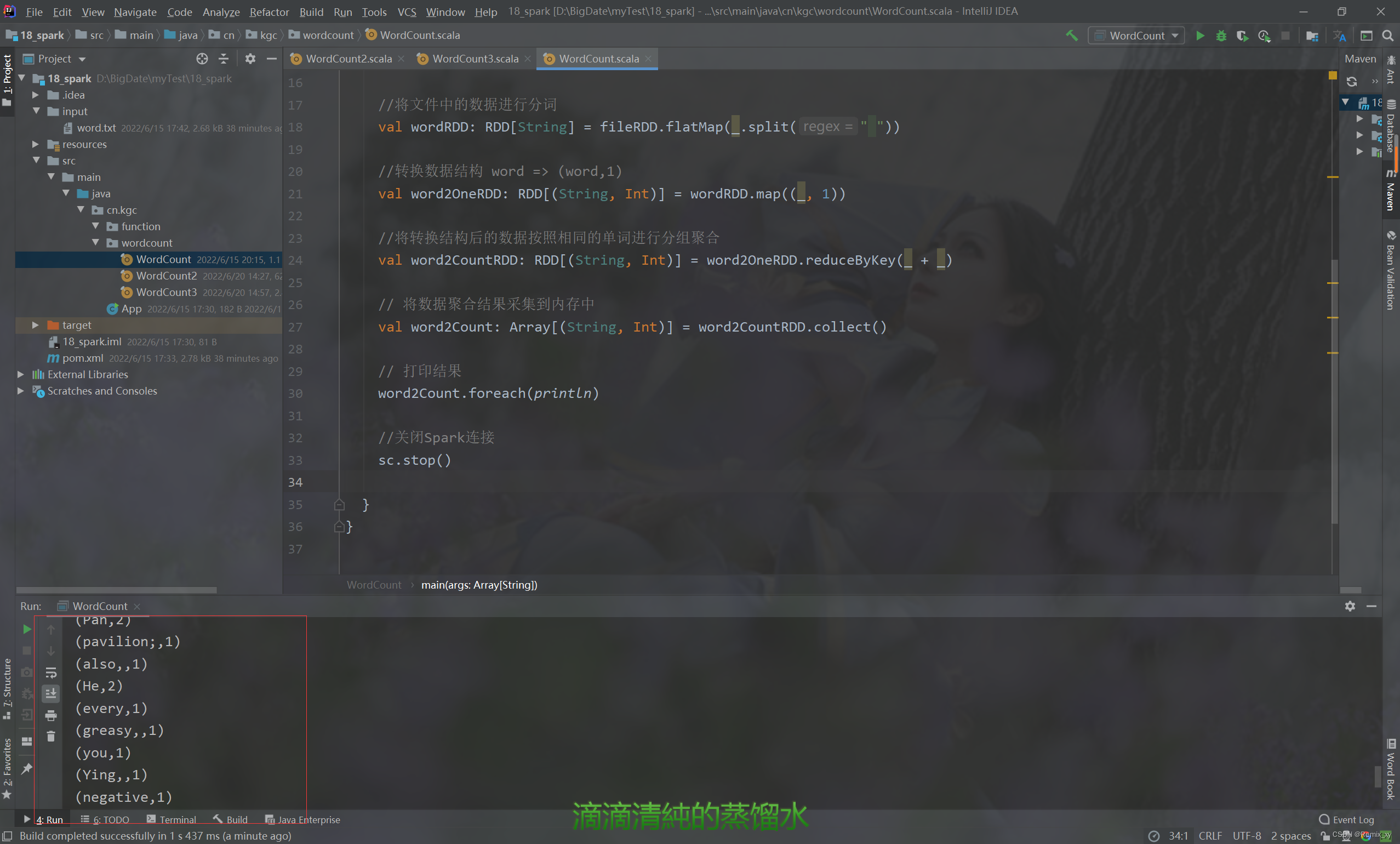
//读取文件中的数据进行分词
val fileRDD: RDD[String] = sc.textFile("input/word.txt")
//将文件中的数据进行分词
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
//转换数据结构 word => (word,1)
val word2OneRDD: RDD[(String, Int)] = wordRDD.map((_, 1))
//将转换结构后的数据按照相同的单词进行分组聚合
val word2CountRDD: RDD[(String, Int)] = word2OneRDD.reduceByKey(_ + _)
// 将数据聚合结果采集到内存中
val word2Count: Array[(String, Int)] = word2CountRDD.collect()
// 打印结果
word2Count.foreach(println)
//关闭Spark连接
sc.stop()
}
}
package cn.kgc.wordcount
/**
*对统计出的每个单词的词频Count,按照降序排序,获取词频次数最多Top3单词
*/
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount3 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordCount3")
val sc = new SparkContext(conf)
//读取文件
val words: RDD[String] = sc.textFile("input/word.txt")
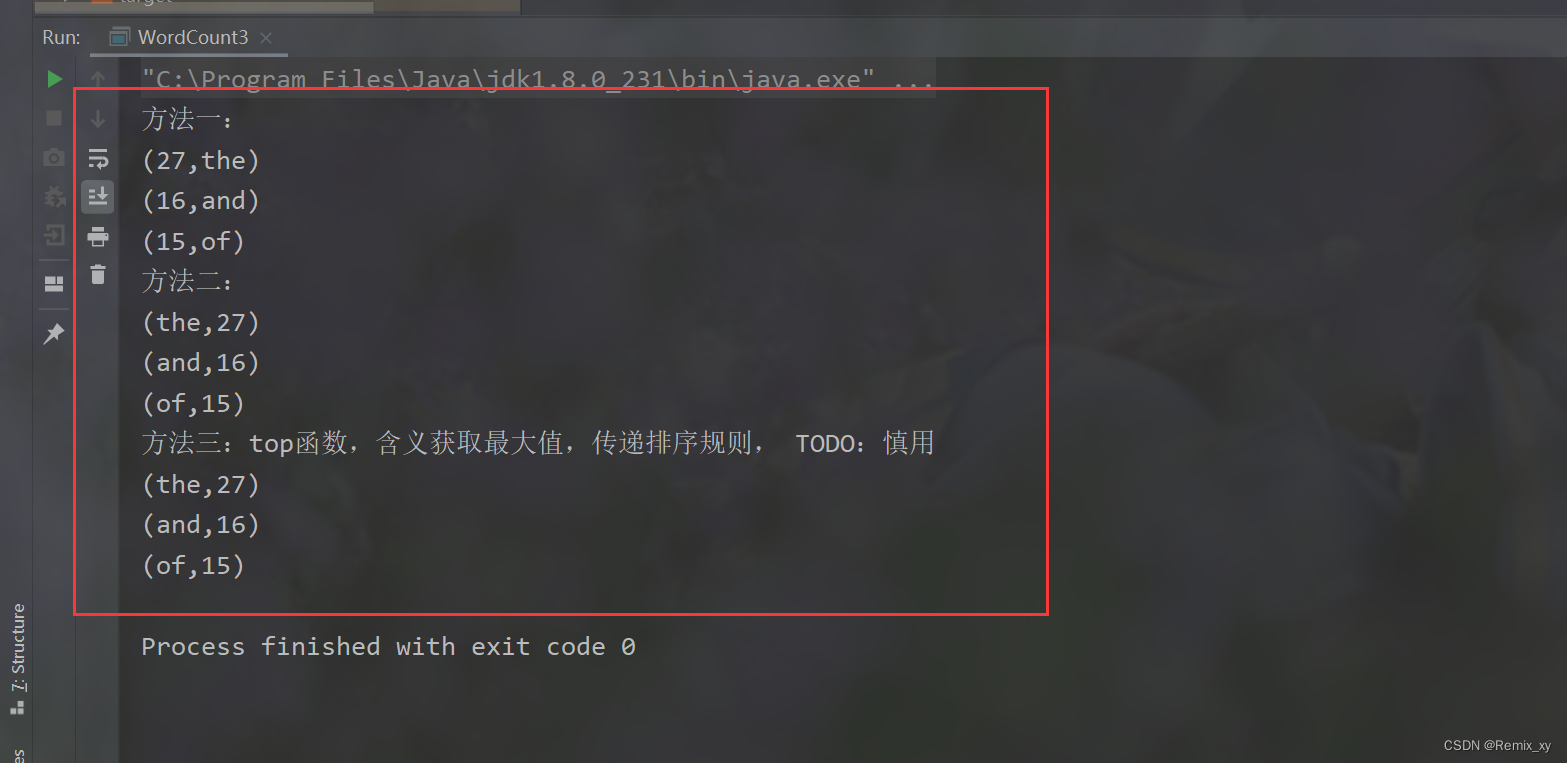
println("方法一:")
val rst1: Unit = words.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item) //所有的单词都被统计成二元组,此时单词已被统计
/* 方式一:按照Key排序sortByKey函数, TODO: 建议使用sortByKey函数
def sortByKey(
ascending: Boolean = true,
numPartitions: Int = self.partitions.length
): RDD[(K, V)]
wordCountsRDD*/
.map(tuple => tuple.swap) //.map(tuple => (tuple._2, tuple._1))
.sortByKey(ascending = false)
.take(3)
.foreach(println)
/* // 方式二:sortBy函数, 底层调用sortByKey函数
/*
def sortBy[K](
f: (T) => K, // T 表示RDD集合中数据类型,此处为二元组
ascending: Boolean = true,
numPartitions: Int = this.partitions.length
)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
*/*/
println("方法二:")
val rst2: Unit = words.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
.sortBy(tuple => tuple._2,ascending = false)
.take(3)
.foreach(println)
println("方法三:top函数,含义获取最大值,传递排序规则, TODO:慎用")
val rst3: Unit = words.flatMap(line => line.split("\\s+"))
.map(word => (word, 1))
.reduceByKey((tmp, item) => tmp + item)
.top(3)(Ordering.by(tuple => tuple._2))
.foreach(println)
sc.stop()
}
}






















 1180
1180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









