






基于内存映射的千万级数据处理框架
在计算机的世界里,将大问题切分为多个小问题予以解决是非常优秀的思想。
许多优秀的数据存储框架都采用分布式架构解决海量数据的存储问题,在典型的数据库中间件架构中,
往往抽象出逻辑的数据表概念,一个逻辑表对应多个物理表,写入的数据会根据规则路由到指定的物理表,
这不仅解决了海量数据的存储问题,还附带解决单点故障问题,在之前依靠昂贵服务器的架构中,一旦我
们这个昂贵的家伙罢工,那么网站几乎就会陷入瘫痪,而在分布式架构中,对服务器的要求是比较低的,
而且即使某个节点坏了,往往也只影响部分业务。分布式架构给我们带来了'银弹',但同时也给我们带来
了挑战,我们不得不面对数据切分后的合并问题.在某些场景下,我们不得不从各个节点加载大量数据,从
中筛选出满足业务需求的几条,如执行以下SQL:
select
* from xxx limit 10000000,10
我们不得不去每个节点加载1000w+10条数据,合并后在其中筛选满足条件的10条,这将会对我们架构的
中枢节点造成巨大的压力,简单的解决办法是加大中枢节点的内存和CPU,在内中合并这些数据,但这不现
实,相比于大量的业务数据,现今的内存容量小的太多太多,第二种方案是将这些数据先写到硬盘,再根据
需求加载数据进行处理,相比内存而言,硬盘的容量能支持非常大的数据,但是,如果有时间要求呢?如果
每条与上述SQL类似的语句都需要几小时或数十小时的时间来运行,哪恐怕业务又会不断的抱怨了。我们先
搁置这个问题,看一个比较常见的现象,在我们2G内存的PC中,可以同时打开大型游戏,文本编辑器,浏
览器,图片查看程序。。。,这些程序使用的内存往往远超我们的物理内存,操作系统是如何调度这些程序
的呢,技巧之一就是使用虚拟内存,每个进程都有4G左右的虚拟内存空间(32bit),这些空间并不是真实
的物理内存地址,他和物理内存或文件之间存在映射关系,这个映射关系是在系统加载程序时创建好的,当内
存不足时,OS会将最近使用较少的内存块写到文件,需要时又读回内存,这部分操作虽然涉及I/O,但是与
普通的I/O不同,一方面他总是按块顺序地读写,另一方面他不会有二次读写问题(数据总是读写到系统的缓
冲区中转),所以即使在2G的PC上运行多个程序使用内存大于2G,在局部性原理的作用下,你感觉不到系统
内存调度带来的影响,当然,这种感觉是相对的。既然OS的虚拟内存机制利用文件实现也十分高效,我们为什
么不用来解决上述问题呢,windows和*ux都提供了相应的接口,我们可以用来实现内存映射,幸运的是
java已经支持这种内存映射特性,采用java可以快速实现这样一套模拟OS的虚拟内存管理框架,Moni
就是这样一套框架,初衷是作为我设计的mysql中间件VirtualDB的跨节点数据合并组件,后来在研究
Mycat时发现Mycat也遇到这个问题,于是我把这部份抽出来作为一个独立的框架,并取名Moni。我为
Moni设计了一套自动扩容和地址数据分离的数据结构,Moni的数据存取非常快,本身几乎没有内存消耗。
理论上容量只受限于硬盘大小,目前版本数据量建议在千万级以内。Moni是一个非常轻巧的框架,总共5个类,
Moni源码:https://git.oschina.net/coder-c/Moni.git 类结构如下:
org.virtualdb.mpp
MemMapBytesItor:用于存取byte[]的数据结构只支持顺序添加和遍历,是最高效的
MemMapBytesArray:用于存取byte[]的数据结构,支持随机读写和排序
MemMapLongArray
:用于存取long的数据结构
MemMapSorter :上述数据结构的排序工具,实现了原地归并和堆排序以及位图排序
MemMapUtil :工具类
org.virtualdb.mpp.test
....
通常只需关注 MemMapBytesArray,MemMapLongArray是为实现地址和数据分离而实现的,地址数据
分离是实现快速排序的基础,目前所有的排序算法都需要移动数据本身,这在数据量大时会造成巨大的时间消耗,有
的算法还会产生巨大的空间消耗。有如下数组:
数据: [12,96,8,-1,45]
索引: 0, 1,2, 3, 4
常规的排序需要将-1移到0号索引,将8移到1号索引,依次类推。在数据长度不固定的数组中,每次数据的移动涉
及空间的扩容和压缩,因此难以用常规的排序算法进行排序,即使实现了排序也非常耗时。
我们换个思维进行排序,不移动数据,改为移动索引,如下:
数据: [12,96,8,-1,45]
索引: 0, 1,2, 3, 4
将-1的索引改为0,8的索引改为1,依此类推,实现对数据的排序。常规排序中所使用的索引是数组天然具有的,
但在基于地址移动实现的排序中,我们必须自己维护索引,MemMapBytesArray内部记录每条数据的地址从而在
巨大的‘内存’中区分不同的数据项以便排序,MemMapBytesArray初始化时会映射400M的内存,如果添加数据
大于400M,MemMapBytesArray会自动扩容,这点与JDK的ArrayList十分类似,但不同的是,JDK的
ArrayList在扩容时必须copy数据,这在数据量大时会带来巨大的时间效耗,MemMapBytesArray扩容后无
需copy原数据,而是记录当前的扩容数,获取数据时按page+offset的方式定位数据的具体地址,实现快速的存取
数据。简单说,ArrayList是采用单一数组存储数据,而MemMapBytesArray采用多数组存储数据,他相当于
一本字典,我们需要某条数据时先找到该数据所在的page,再根据offset定位到数据。MemMapBytesArray支
持不定长的数据项,但建议单条数据项尽量小,并且不能超过65535个字节。对于不需要排序的数据而言,MemMapBytesItor
是最佳选择,他不需要记录数据的地址,占用的空间较少,顺序遍历也使得其速度很快。
MemMapSorter中的原地归并排序,在我电脑上测试,与JDK自带的快排相当,对1000w随机数排序,MemMapSorter
原地归并耗时1.3s左右,JDK耗时1.15s左右。当然,对于不重复的数字排序,最快的还是MemMapSorter里的位图排序,
1000w随机数排序耗时仅0.3s,实现也是最简单的,内存消耗也非常少,1000w个5000w以内的数据排序,仅消耗5000w/8
也就是大约6M内存。
PS:
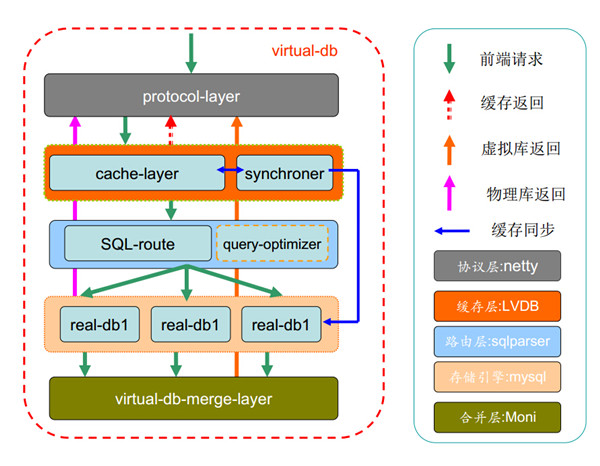
VirtualDB的设计目标是成为高效的Mysql中间件,VirtualDB遵循几个原则:
1.尽可少解析SQL
2.尽可能多实现透传
3.尽可能快的实现合并
4.尽可能多的缓存查询
协议解析/分片/合并等基本功能都已实现,现在缺少一个非常快的SQL解析框架,预计明年年中释放第一个版,以下
是VirtualDB架构图:















 504
504











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









