







Pivot 算子是 spark 1.6 版本开始引入的,在 spark2.4版本中功能做了增强,还是比较强大的,做过数据清洗ETL工作的都知道,行列转换是一个常见的数据整理需求。spark 中的Pivot 可以根据枢轴点(Pivot Point) 把多行的值归并到一行数据的不同列,这个估计不太好理解,我们下面使用例子说明,看看pivot 这个算子在处理复杂数据时候的威力。
使用Pivot 来统计天气走势
下面是西雅图的天气数据表,每行代表一天的天气最高值:
| Date | Temp (°F) |
|---|---|
| 07-22-2018 | 86 |
| 07-23-2018 | 90 |
| 07-24-2018 | 91 |
| 07-25-2018 | 92 |
| 07-26-2018 | 92 |
| 07-27-2018 | 88 |
| 07-28-2018 | 85 |
| 07-29-2018 | 94 |
| 07-30-2018 | 89 |
如果我们想看下最近几年的天气走势,如果这样一天一行数据,是很难看出趋势来的,最直观的方式是 按照年来分行,然后每一列代表一个月的平均天气,这样一行数据,就可以看到这一年12个月的一个天气走势,下面我们使用 pivot 来构造这样一个查询结果:
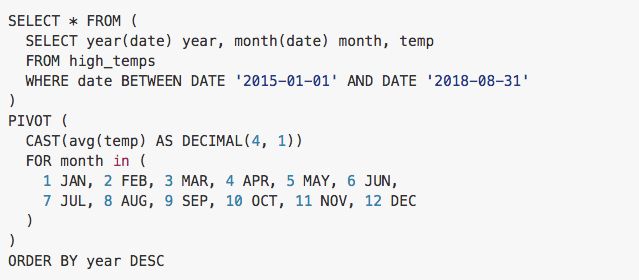
结果如下图:
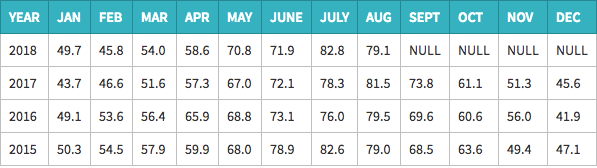 <
<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4430
4430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









