







本文来自Andrew Ray博士在Silicon Valley Data Science网站上发表的博客,Andrew Ray博士对大数据有着浓厚的兴趣并且有着丰富的Spark使用经验。Andrew同样也是一名活跃的Apache Spark源码贡献者,其源码贡献主要集中在Spark SQL和GraphX组件上。
透视(pivot)数据功能是Spark 1.6的众多新增特性之一,它通过使用DataFrame(目前支持Scala、Java和Python语言)创建透视表(pivot table)。透视可以视为一个聚合操作,通过该操作可以将一个(实际当中也可能是多个)具有不同值的分组列转置为各个独立的列。透视表在数据分析和报告中占有十分重要的地位,许多流行的数据操纵工具(如pandas、reshape2和Excel)和数据库(如MS SQL和Oracle 11g)都具有透视数据的能力。在以前的博客当中我已经做了简要介绍,但在本文中,我将更深入地给大家讲解具体细节。本博文的代码可以从这里下载。
语法
在为透视操作进行pull请求的过程中,我进行了许多相关研究,其中一项便是对其它优秀工具的语法进行比较,目前透视语法格式多种多样,Spark 透视功能最主要的两个竞争对手是pandas(Python语言)和reshape2(R语言)。
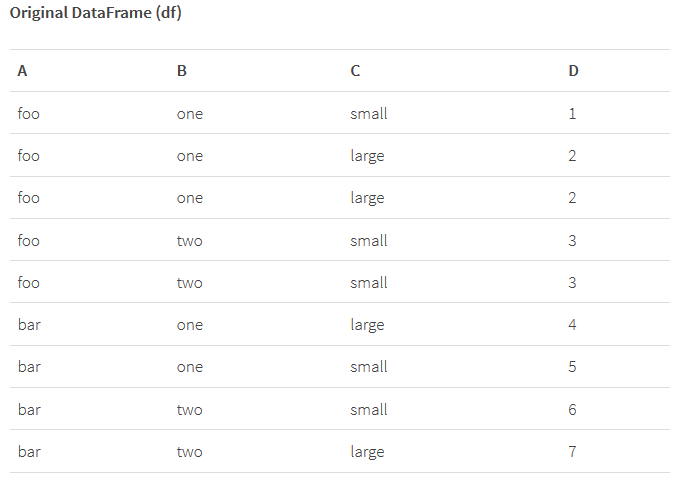
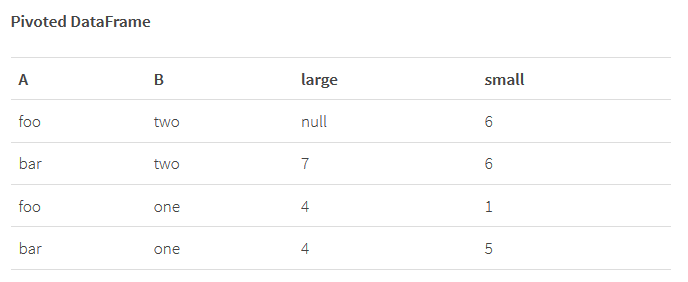
例如,我们想对A列和B列进行分组,然后在C列上进行透视操作并对D列数据进行求和,pandas的语法格式为 pivot_table(df, values=’D’, index=[‘A’, ‘B’], columns=[‘C’], aggfunc=np.sum),这看起来有点冗长但表达还算清晰,如果使用reshape2的话,其语法格式为 dcast(df, A + B ~ C, sum),借助于R语言公式的表达能力,这种语法十分紧凑,需要注意的是reshape2不需要指定求值列,因为它自身具备将剩余DataFrame列作为最终求值列的能力(当然也可能通过其它参数进行显式指定)。
我们提出Spark透视操作自有的语法格式,它能够与DataFrame上现有其它聚合操作完美结合,同样是进行group/pivot/sum操作,在Spark中其语法为:df.groupBy(“A”, “B”).pivot(“C”).sum(“D”),显然这种语法格式非常直观,但这其中也有个值得注意的地方:为取得更好的性能,需要明确指定透视列对应的不同值,例如如果C列有两个不同的值(small 和 large),则性能更优的版本语法为: df.groupBy(“A”, “B”).pivot(“C”, Seq(“small”, “large”)).sum(“D”)。当然,这里给出的是Scala语言实现,使用Java语言和Python语言实现的话方法也是类似的。
报告
让我们来看一些实际应用案例,假设你是一个大型零售商(例如我前任东家),销售数据具有标准交易格式并且你想制作一些汇总数据透视表。当然,你可以选择将数据聚合到可管理的大小,然后使用其它工具
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 542
542











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









