







无聊是第一生产力,尤其是在吃饱了撑的的情况下;而懒又是另一个促进科技发展的重要因素。众所周知,追星会使人勤奋,尤其体现在做单人剪辑视频这一点上:
单人CUT视频有两大用处:提供给二次创作党做素材,以及供某些只想看一个人的观众观看,当红明星的“求CUT”是一个很高的需求。
为什么不想想怎么把这件事用机器自动实现呢?先告诉你们结论——如果把这个任务交给一个学人工智能的大学生,完成起来并不会很难。
主要是因为制作单人CUT的门槛很简单:
- 纵观全视频
- 找到每一个目标艺人的出场镜头
- 使用剪辑软件剔除多余的内容
而单人CUT又有很多细节视情况而定,比如说是否保留完整的对话上下文,不“断章取义”;是否只剪脸不剪只有声音的部分……这个工作的主要时间都花在看视频跟找子片段的起始点上,可以说技术含量并不高,只是一个搬砖的苦差事。
用一种简单粗暴的思路就行了:通过人脸识别的方法学习艺人的外貌(为了简单起见,只看脸),针对目标视频的帧进行识别,然后根据一定的规则确定剪辑的子片段,最后使用视频处理工具(如ffmpeg)生成成品单人CUT视频。
下面是具体的尝试过程:
一、适用于菜鸟的人脸识别方法
人工智能+人脸识别=一大批赫赫有名的技术、公司、专家、论文,堪称炙手可热的C位,这里我就不多说了。
一个人应当尽量避免班门弄斧,比如随便抄一个CNN/KNN/GAN的模型,用爬虫爬来的数据集跑半天,最后不管效果如何总归水了篇博客。事实上我用的是这个东西:

它有两个用处:
- 找到图片中的人脸,用一个小矩形圈出来(只是识别是不是人脸,是谁的不做判断)。速度很快,精准度比OpenCV强不少,不会把某些奇奇怪怪的树杈、广告牌什么的识别为人脸(我是怎么知道的?无聊的时候试出来的)
- 判断人脸的相似性,它的判断是基于阈值的,就是说严格要求只能有百分之多少的数据不同,才认为是同一张脸。这种方法虽然太莽了,但是速度非常之快。也就是说,我可以用几千个同一人的脸跟样本对比,然后设一个很低的阈值,只要有几个通过,就认为是同一张脸。
它依赖于一个库叫dlib,看了一下,貌似很牛逼:
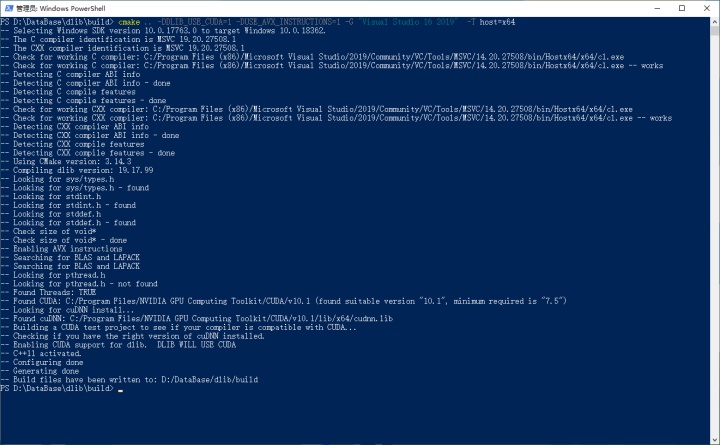
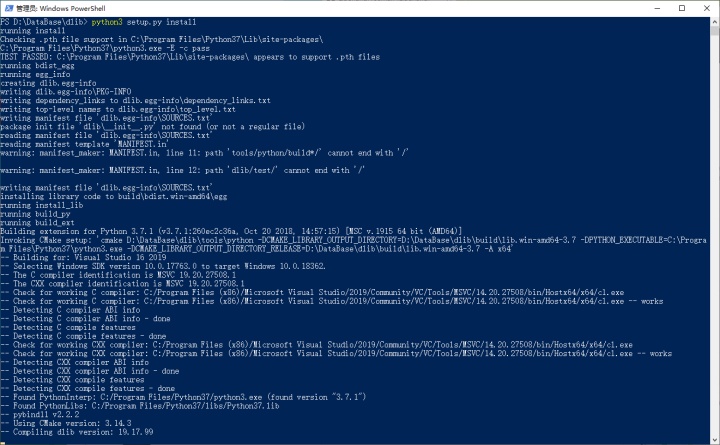
然而,装这个库是非常麻烦的,识别人脸可以显卡加速,但是必须自己编译:
首先要装cmake:
然后装cuda:
下面开始编译:
搞完之后,我们就可以开始,首先截了几千个超超越越的大头贴:
这1700个图的面部信息都会保存到一个表里,留着供比对使用。先来一个测试:
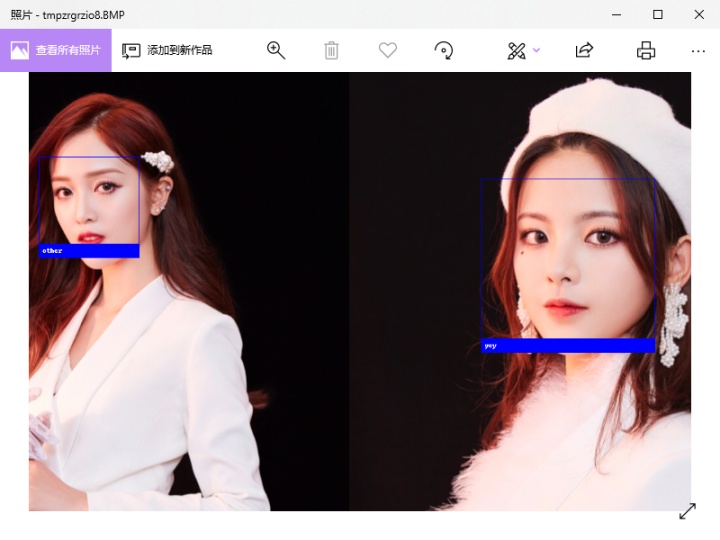
二、对视频进行正确处理的姿势
- 每隔25帧取一帧,每取14张720P(单张图片的识别速度跟分辨率有关,每次可以一块识别的图片数量跟显存有关,这个数值是供6G显存用的)的截图,就进行一次批量识别。
- 每一次识别是将此帧中的每一个面孔都与样本集中1700组数据进行比对,设置识别阈值为0.4(严格程度堪称六亲不认),如果通过的数量超过5个(0,10,1这些我也都试过,这个值越小,CUT得到的子视频越多),就标记这一帧有用,并截一张图保存下来。
- 如果两帧间隔超过10秒(我随便定的,越小则CUT的次数越多),就记录一次子CUT,确定开始时间和截止时间。
- 用ffmpeg把子CUT导出,截图也放到同一个文件夹里
无聊之时,还可以加一个进度条:

这种方式是很落后的:
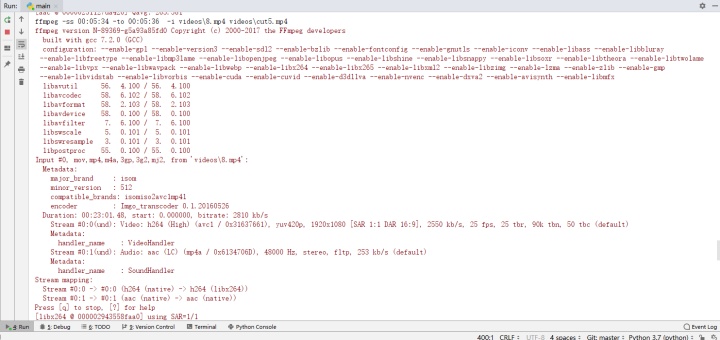
ffmpeg截取视频应当使用这条命令:
ffmpeg -ss {} -to {} -i {} -codec copy -avoid_negative_ts 1 {}
#参数依次为:开始时间、持续时间、输入视频文件名、输出视频文件名不需要重新编码,CPU再也不会满载了:
尤其是avoid_negative_ts,否则截出来的视频会出现奇怪的表现
三、论如何使用人工弥补人工智能的愚蠢
如果降低了识别阈值,那么就会出现认错人的情况,但是认错也比漏认强,前者是可以通过人工来弥补的:
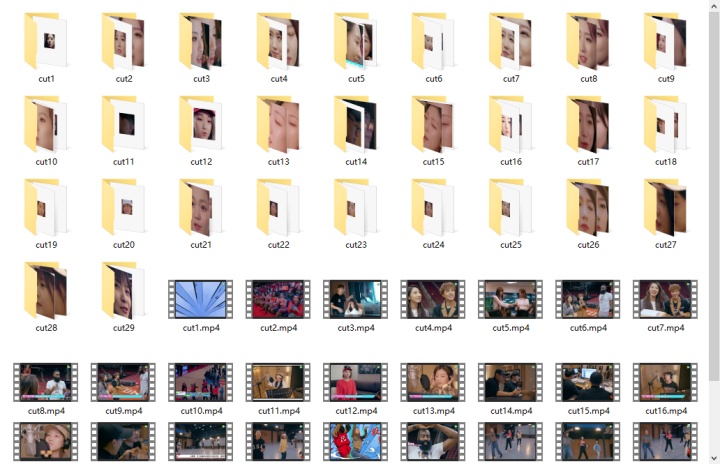
比如说这个视频中好几个别的火箭少女都被认成了超越,但是多余的可以ctrl+d直接删掉
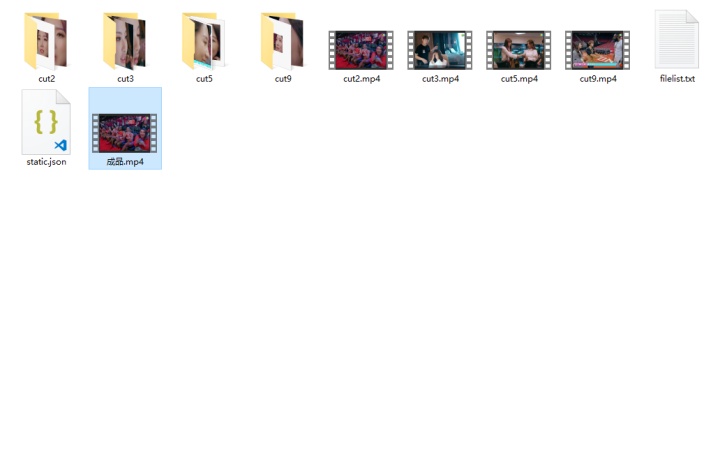
这样就OK了。怎么样,学会了吗?这是某个成品链接
附上github链接;
LiuChangFreeman/smart_personal_cutgithub.com














 1176
1176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









