






运维的时候,经常遇到auto_increment的疑惑:
机器异常crash,重启后id回退的问题
性能考虑,每次获取肯定不会持久化,内存中取值,statement复制如何保证主备一致
id的取值受binlog的保护吗
1. auto_increment相关的参数控制
1.1 innodb_autoinc_lock_mode
0: 每一个statement获取一个排他lock,直到statement结束,保证statement执行过程的id是连续的。
1: 单条确定insert影响的条数的时候,使用mutex。如果是insert select,load data这样的,使用排他lock。
2: 多条statement产生的id会穿插在一起,如果是statement复制,会产生不一致的情况。
1.2
auto_increment_increment
auto_increment_offset
控制自增的起始值和interval
2. auto_increment相关的数据结构
1. 锁模式中LOCK_AUTO_INC,即auto_increment的表锁。
/*Basic lock modes*/
enumlock_mode {
LOCK_IS= 0, /*intention shared*/LOCK_IX,/*intention exclusive*/LOCK_S,/*shared*/LOCK_X,/*exclusive*/LOCK_AUTO_INC, /* locks the auto-inc counter of a table in an exclusive mode */LOCK_NONE,/*this is used elsewhere to note consistent read*/LOCK_NUM= LOCK_NONE/*number of lock modes*/};
2. dict_table_t: innodb表定义
lock_t*autoinc_lock; 表锁
mutex_t autoinc_mutex; mutex锁
ib_uint64_t autoinc; 自增值ulongn_waiting_or_granted_auto_inc_locks; 等待自增表锁的队列数const trx_t* autoinc_trx; hold自增表锁的事务
3. trx_t: 事务结构
ulint n_autoinc_rows; statement插入的行数
ib_vector_t* autoinc_locks; 持有的自增lock
4. handler:table的innodb引擎句柄
ulonglong next_insert_id; 下次插入的id
ulonglong insert_id_for_cur_row; 当前插入的id
Discrete_interval auto_inc_interval_for_cur_row; 缓存,一次申请一个区间,缓存在server层。减少对innodb的调用uint auto_inc_intervals_count; 向innodb申请id的interval。按照[1, 2, 4, 8, 16]递增。 最多1<<16 -1
注意:handler里的这些变量,只在一个语句下有效,语句结束就清理掉了。
3. 测试case
create table pp( id int primary key auto_increment, name varchar(100));
session1 : insert into pp(name) values('xx');
session2 : insert into pp(name) values('xx'),('xx'),('xx'),('xx')
session3 : insert into pp(name) select name from pp;
4. auto_increment的实现原理
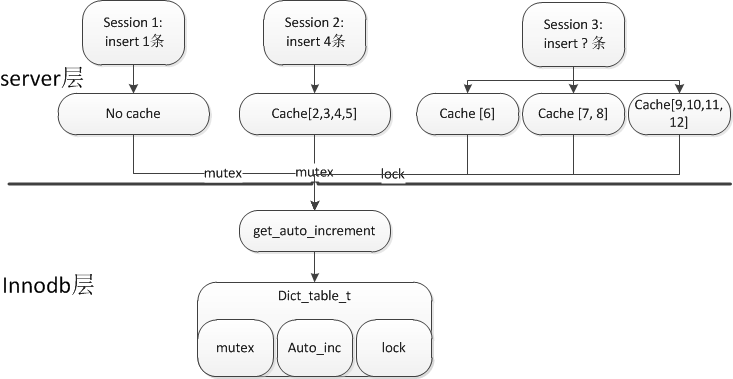
4.2 锁的解释
根据锁持有的时间粒度,分为
1. 内存级别:类似mutex,很快释放
2. 语句级别:statement结束,释放
3. 事务级别:transaction提交或者回滚才释放
4. 会话级别:session级别,连接断开才释放
这里,session1和session2都是确定insert的条数,所以使用mutex分配固定的id。而session3未知,所以为了保证这一个statement的id是连续的,拿到一个lock,维持到statement结束才释放。
所以,为了提高并发量,锁持有的粒度越小越好。
4.3 缓存的解释
针对一个statement,预分配id值,减少对innodb的请求,也相应减少持有锁。
5. 测试细节
5.1 第一次执行
根据select max(id) from pp:获取autoinc的初始值
这样也就解释了文章开头的第一个疑惑,为什么机器crash了,id会回退。
简单函数栈:
ha_innobase::open
innobase_initialize_autoinc
5.2 session 1
1. 首先 持有mutex,获取autoinc
2. 因为insert的条数是1条,计算新的autoinc并更新到dict_table_t中,然后释放mutex结束
简单函数栈
handler::update_auto_increment
ha_innobase::get_auto_increment
ha_innobase::innobase_lock_autoinc
mutex_enter(&table->autoinc_mutex);
dict_table_autoinc_update_if_greater
5.3 session 2
1. 因为insert的条数是4条,所以前面的步骤都类似于session1,但计算完成新的autoinc为5,并更新dict_table_t.
2. 因为cache了[3,4,5],所以后面的三条insert,都在本地缓存中获取,不再请求innodb。
5.4 session 3
1. 因为不确定insert的条数,所以在语句的整个执行期间,持有lock。
2. 语句结束时,statement commit的时候释放
3. 第一次申请1个,第二次申请2个,第三次申请4个,共申请了3次。
简单函数栈:
handler::update_auto_increment
ha_innobase::get_auto_increment
row_lock_table_autoinc_for_mysql
trans_commit_stmt
row_unlock_table_autoinc_for_mysql
语句结束后, 清理语句级的环境
ha_release_auto_increment
insert_id_for_cur_row= 0; 当前语句的insert id设置为0
auto_inc_interval_for_cur_row.replace(0, 0, 0); 预分配的清空
auto_inc_intervals_count= 0; 预分配的迭代数也清0
table->in_use->auto_inc_intervals_forced.empty(); 清理链表
6. 警告:
1. 如果你的表是insert+delete的模式,你会发现重启了后,id被复用了,小心,被坑过的说。
2. 如果表上有自增键,insert select,load file,会对insert产生阻塞。
7. 思考:
1. 分布式的全局唯一递增(不保证连续) 怎么实现。 这是分布式系统都需要解决的问题!















 4217
4217











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









