







d:
进入D盘
scrapy startproject douban
创建豆瓣项目
cd douban
进入项目
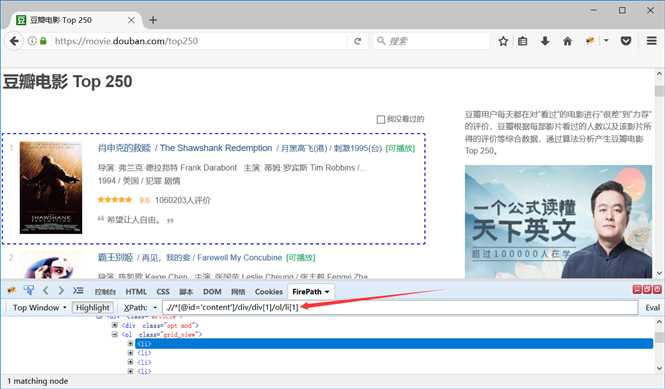
scrapy genspider douban_spider movie.douban.com
创建爬虫
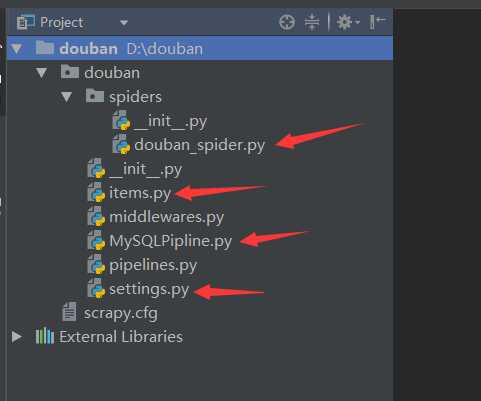
编辑items.py:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
serial_number = scrapy.Field()
# 序号
movie_name = scrapy.Field()
# 电影的名称
introduce = scrapy.Fi
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 814
814











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









