







概要
了解数据
分析数据问题
清洗数据
整合代码
了解数据
在处理任何数据之前,我们的第一任务是理解数据以及数据是干什么用的。我们尝试去理解数据的列/行、记录、数据格式、语义错误、缺失的条目以及错误的格式,这样我们就可以大概了解数据分析之前要做哪些“清理”工作。
本次我们需要一个 patient_heart_rate.csv (链接:https://pan.baidu.com/s/1geX8oYf 密码:odj0)的数据文件,这个数据很小,可以让我们一目了然。这个数据是 csv 格式。数据是描述不同个体在不同时间的心跳情况。数据的列信息包括人的年龄、体重、性别和不同时间的心率。
import pandas as pd
df = pd.read_csv('../data/patient_heart_rate.csv')
df.head()
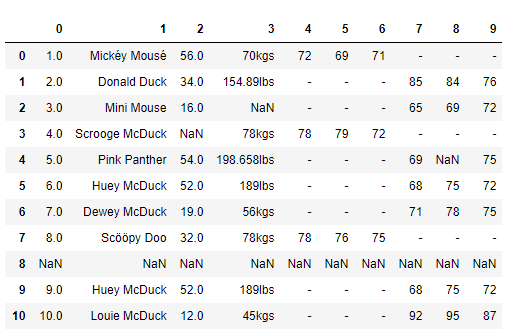
分析数据问题
没有列头
一个列有多个参数
列数据的单位不统一
缺失值
空行
重复数据
非 ASCII 字符
有些列头应该是数据,而不应该是列名参数
清洗数据
下面我们就针对上面的问题一一击破。
1. 没有列头
如果我们拿到的数据像上面的数据一样没有列头,Pandas 在读取 csv 提供了自定义列头的参数。下面我们就通过手动设置列头参数来读取 csv,代码如下:
import pandas as pd
# 增加列头
column_names= ['id', 'name', 'age', 'weight','m0006','m0612','m1218','f0006','f0612','f1218']
df = pd.read_csv('../data/patient_heart_rate.csv', names = column_names)
df.head()
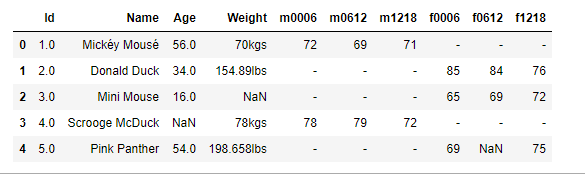
上面的结果展示了我们自定义的列头。我们只是在这次读取 csv 的时候,多了传了一个参数 names = column_names,这个就是告诉 Pandas 使用我们提供的列头。
2. 一个列有多个参数
在数据中不难发现,Name 列包含了两个参数 Firtname 和 L
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1831
1831











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









