







 Pandas进行数据清洗1、完整性1.1 缺失值1.2 空行2、全面性列数据的单位不统一3、合理性非ASCII字符4、唯一性4.1 一列有多个参数4.2 重复数据我们有下面的一个数据,利用其做简单的数据分析。这是一家服装店统计的会员数据。最上面的一行是列坐标,最左侧一列是行坐标。列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸。数据清洗规则总结为以下 4 个关键点,统一起来
Pandas进行数据清洗1、完整性1.1 缺失值1.2 空行2、全面性列数据的单位不统一3、合理性非ASCII字符4、唯一性4.1 一列有多个参数4.2 重复数据我们有下面的一个数据,利用其做简单的数据分析。这是一家服装店统计的会员数据。最上面的一行是列坐标,最左侧一列是行坐标。列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸。数据清洗规则总结为以下 4 个关键点,统一起来
我们有下面的一个数据,利用其做简单的数据分析。
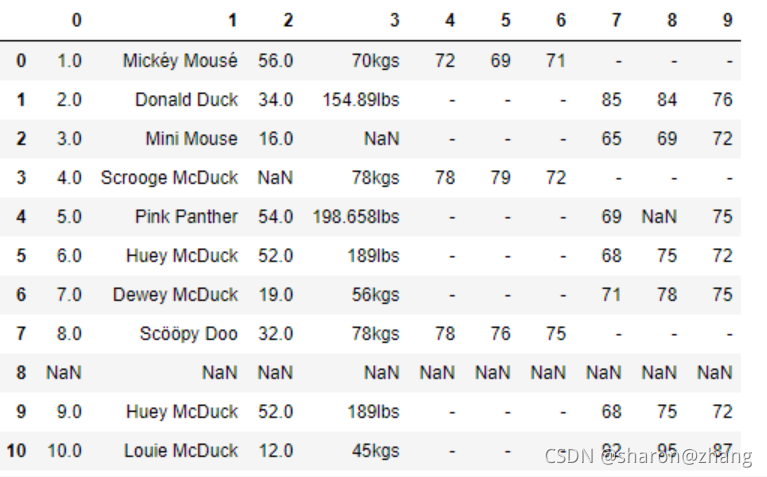
这是一家服装店统计的会员数据。最上面的一行是列坐标,最左侧一列是行坐标。列坐标中,第 0 列代表的是序号,第 1 列代表的会员的姓名,第 2 列代表年龄,第 3 列代表体重,第 4~6 列代表男性会员的三围尺寸,第 7~9 列代表女性会员的三围尺寸。
数据清洗规则总结为以下 4 个关键点,统一起来叫“完全合一”,下面来解释下:
完整性:单条数据是否存在空值,统计的字段是否完善。
全面性:观察某一列的全部数值,比如在 Excel 表中,我们选中一列,可以看到该列的平均值、最大值、最小值。我们可以通过常识来判断该列是否有问题,比如:数据定义、单位标识、数值本身。
合法性:数据的类型、内容、大小的合法性。比如数据中存在非 ASCII 字符,性别存在了未知,年龄超过了 150 岁等。
唯一性:数据是否存在重复记录,因为数据通常来自不同渠道的汇总,重复的情况是常见的。行数据、列数据都需要是唯一的,比如一个人不能重复记录多次,且一个人的体重也不能在列指标中重复记录多次。
1、完整性
1.1 缺失值
一般情况下,由于数据量巨大,在采集数据的过程中,会出现有些数据单元没有被采集到,也就是数据存在缺失。通常面对这种情况,我们可以采用以下三种方法:
删除:删除数据缺失的记录
均值:使用当前列的均值填充
高频:使用当前列出现频率最高的数据
比如我们相对data[‘Age’]中缺失的数值使用平均年龄进行填充,可以写:
df['Age'].fillna(df['Age'].mean(), inplace=True)
如果我们用最高频的数据进行填充,可以先通过 value_counts 获取 Age 字段最高频次 age_maxf,然后再对 Age 字段中缺失的数据用 age_maxf 进行填充:
age_maxf = train_features['Age' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1723
1723











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











