






 本文介绍了如何在Stata中进行面板数据的GMM回归分析,包括全样本基本面分析、虚拟变量分组对比以及固定效应与随机效应的选择。针对固定效应模型的缺陷,如自相关问题,提出了面板数据的检验方法。此外,文章还讨论了Hausman检验的局限性和异方差性修正,并提供了LR图绘制及内生性与工具变量处理的命令模板。
本文介绍了如何在Stata中进行面板数据的GMM回归分析,包括全样本基本面分析、虚拟变量分组对比以及固定效应与随机效应的选择。针对固定效应模型的缺陷,如自相关问题,提出了面板数据的检验方法。此外,文章还讨论了Hausman检验的局限性和异方差性修正,并提供了LR图绘制及内生性与工具变量处理的命令模板。
1.全样本基本面分析
reg csr X1 lnsize bcash roa lev les tobinq age i.Ind i.year
est store m1
reg csr X2 lnsize bcash roa lev les tobinq age i.Ind i.year
est store m2
esttab m1 m2 m3 m4 using esttab1.rtf, replace2.虚拟变量分组对比分析
reg csr X1 lnsize bcash roa lev tobinq age i.Ind i.year if zy==1
est store m1
reg csr X1 lnsize bcash roa lev tobinq age i.Ind i.year if zy==0
est store m2
reg csr X2 lnsize bcash roa lev tobinq age i.Ind i.year if zy==1
est store m3
reg csr X2 lnsize bcash roa lev tobinq age i.Ind i.year if zy==0
est store m4
esttab m1 m2 m3,se scalars(N r2 F p) mtitles title(“图1”),using esttab1.rtf,replace3.固定效应还是随机效应
个体效应的两种形态:固定效应&随机效应
step1.分别检验固定效应&随机效应 是否优于混合回归
step2.固定效应&随机效应 通过hausman检验选择
命令:
xtreg csr X1 lnsize bcash roa lev les tobinq age i.Ind i.year , fe
estimates store FE
xtreg csr X1 lnsize bcash roa lev les tobinq age i.Ind i.year , re
estimates store RE
hausman FE RE,constant sigmamore结果
FE 中p值越小越说明 FE回归优于混合回归;
RE 中p值越小越说明 RE回归优于混合回归;
HAUSMAN 检验中 Prob>chi2 越小越说明 FE优于RE;固定效应的缺陷
它只能反映随时间而变的变量信息,不随时间而变的变量(如你现在模型中的Industry)
会自动被omitted(遗漏)掉的。而如果加入时间的虚拟变量,固定效应模型就变为双向固定效应模型了堆积:
你先xtreg, fe,结果底下有个F test that all u_i=0,
这个检验如果不通过,即p值很小,那么混合回归reg就不能用。
接下来,就是fe和re的选择了
对于宽而短(N远大于T)的样本,随机效应模型和固定效应模型的估计结果可能相差很大。
究竟哪一个更好些,不好一概而论,因为各有优缺点。至于在实际应用中具体采用哪一种,
需要通过一定的准则进行判断。
1.根据数据类型判断:宏观数据一般用固定效应(因为大量偶然性波动通过数据汇总抵消了);
微观数据一般用随机效应;
2.根据个体数目判断:如果个体是的全部总体单位,目的在于描述总体(如用全国各省份数据),
一般用固定效应;如果个体是随机抽取的一部分总体单位,目的在于推算总体(如家计调查数据),
一般用随机效应;
3.根据模型参数估计量性质判断:最常用的是Hausman 检验
encode firmcode,gen(firm)
xtset firm year
drop csr firmcode
rename csr1 csr
gen shortr=shortloan/size
强制转换类型
destring gov2 ,replace force
destring var1,gen(var2)
esttab m1 m2 ,se scalars(N r2 F) mtitles title(“图1”),using esttab1.rtf,replace
- 常见问题
Qestion:
reg命令:reg,robust 和 reg,cluster(clustvar) 能得到结果不同的Robust-SE(标准误),
我的理解是前者主要应对异方差,后者主要应对的是自相关?
xtreg命令:,vce(robust) 和,vce(cluster clustvar) 得到的 SE 完全相同?
为什么呢?而且你建议,应对异方差时用前者,应对截面相关时用后者。
这是否意味着,这两个等价的选项能同时应对异方差和截面相关呢?
Answer:
reg, robust 只在考虑有异方差时调整标准误,采用的是 White (1980) 的三明治估计量;
xtset id year后xtreg, robust被设定与xtreg, vce(cluster id) 等价(Stata11后);
若xtreg, vce(cluster industry) 则不相同;(xt便表明系统了解了)
xtreg, vce(cluster industry) 与 reg, vce(cluster industry) 的解释相同:
假设干扰项在不同的行业之间彼此独立,但在同一个行业内部的不同的公司之间存在相关性。
case1:reg, vce(cluster year) 则相当于假设不同年度之间的干扰项彼此独立,
但同一个年度上的所有公司之间的干扰项彼此相关。
case2:reg, vce(cluster id) 相当于假设不同公司的干扰项彼此独立,
但同一家公司不同年度上的干扰项彼此相关。
因此,设定 vce(cluster var) 并不一定意味着序列相关,关键在于 var 是什么变量。自相关
自相关(autocorrelation)/序列相关(serial-correlation)
分类:时间自相关(某变量临近年份相关,多发于时间序列);
(移动平均等运用前后年信息人为调整数据,统计局数据可能调整过)
空间自相关(临近变量相关,多发于截面数据);
扰动项自相关,如遗漏某自相关变量,含在扰动项中便有此;面板数据检验
多重共线性一直不是计量的大问题,相关系数,vif可以基本诊断,过高可以考虑直接剔除
异方差检验一般直接就用robust-se,从来不用一般标准差!
自相关检验这个问题也是没有做过的!
FDI存量数据肯定有很强自相关性,直接动态面板估计,后来比对发现,自相关性对回归结果影响很小。门限回归:要求平衡面板
非平衡面板变成平衡面板
xtbalance ,range(2004 2007)
【代码示例】
use thresholddata,clear
STATA12.0:xtptm pollution,rx(pgdp) thrvar(fdi) regime(1) iters(300)
trim(0.01) grid(100)
STATA14.0:xthreg pollution,rx(pgdp) qx(fdi) thnum(1) bs(300)
trim(0.01) grid(100)
双门槛:xthreg y, rx(x1) qx(x2) thnum(2) bs(300 300) trim(0.05 0.05)
grid(100) vce(robust)
【命令区别】
两个命令里的rx都代表受门限变量影响的核心解释变量;
xthreg命令里的qx代表门限变量,而xtptm命令里的thrvar代表门限变量
(有一些旧版的xtptm也是以qx代表门限变量);
xthreg命令里的thnum代表门限数量,而xtptm命令里的regime代表门限数量
(有一些旧版的xtptm也是以thnum代表门限数量);
xthreg命令里的bs代表自举抽样次数,而xtptm命令里的iters代表自举抽样次数;
两个命令里的trim都代表每个门限分组内异常值去除的比例;
两个命令里的grid代表样本网格计算的网格数
(不设的话该值为0,设置这个option可以减少运算时间,提高运算效率)。
关于整体运算效率:xtptm运算耗时要明显小于xthreg,效率更高。
关于对输出结果的解释:xthreg的回归输出要比xtptm更友好:
xtptm按变量顺序命名然后输出,xthreg直接按变量名称命名然后输出。
【报错原因1】
至于有的同学说使用命令出错,系统提示3200 conformability error之类的错误,
很可能是你把rx里的核心解释变量也写到一般解释变量里面去了,
会导致矩阵结构上的错误,所以系统报错,然后回归无法运行。形如:
STATA14.0:xthreg pollution pgdp, rx(pgdp) qx(fdi)
thnum(1) bs(300) trim(0.01) grid(100)
这样的语句就是错误的。
【报错原因2】
有的同学说运行的时候出错,系统提示thestm(): 3301 subscript invalid之类的错误,
很可能是你每个门限分组内异常值去除的比例太小,也就是trim设得太小(比如0.01),
这时会导致元素引用时下标溢出而导致下标引用无效,遇到这种情况时你不妨将trim调大一点
(比如0.05),形如:
STATA14.0:xthreg pollution pgdp population urbanization_level
industrialization_level, rx(pgdp) qx(fdi) thnum(1) bs(300) trim(0.05) grid(100)描述性统计
1.知道分布状态:左偏or右偏
sum x1,d
return list
其中p(50)代表中位数
2.xtsum x1 含标准差等描述性统计量基本处理数据
直接剔除超标数据
winsor2 x1, replace cuts(1 99) trim
生成时间虚拟变量
tab year, gen(dy)
reg时,dy* 即可代表所有
滞后一期
gen m=l.x
Q:repeated time values within panel
A:
duplicates drop firm year, force
tsset firm yearPSM
gen tmp = runiform()
sort tmp (以上两步对所有观测值进行随机排序)
psmatch2 treat age , out(re78) logit neighbor(1) common caliper(.05) ties
pstest, both
psgraph
命令解读:
以下是帮助菜单中psmatch2语法格式,
psmatch2 depvar [indepvars] [if exp] [in range] [, outcome(varlist)
pscore(varname) neighbor(integer) radius caliper(real) mahalanobis(varlist)
ai(integer) population altvariance kernel llr kerneltype(type) bwidth(real)
spline nknots(integer) common trim(real) noreplacement descending odds index
logit ties quietly w(matrix) ate]
简单说就是:psmatch2 因变量 协变量,[选择项]。重点解读命令语句中选择项的含义。
本例中选择“nearest neighbor matching within caliper”匹配方法。out(re78)指明结局变量。
logit指定使用logit模型进行拟合,默认的是probit模型。neighbor(1)指定按照1:1进行匹配,
如果要按照1:3进行匹配,则设定为neighbor(3),本例中因对照组样本量有限,仅适合1:1进行匹配。
common强制排除试验组中倾向值大于对照组最大倾向值或低于对照组最小倾向值。caliper(.05)试验组
与匹配对照所允许的最大距离为0.05。ties强制当试验组观测有不止一个最优匹配时同时记录。
pstest, both做匹配后均衡性检验,理论上说此处只能对连续变量做均衡性检验,对分类变量的均
衡性检验应该重新整理数据后运用χ2检验或者秩和检验。但此处对于分类变量也有一定的参考价值。
psgraph对匹配的结果进行图示。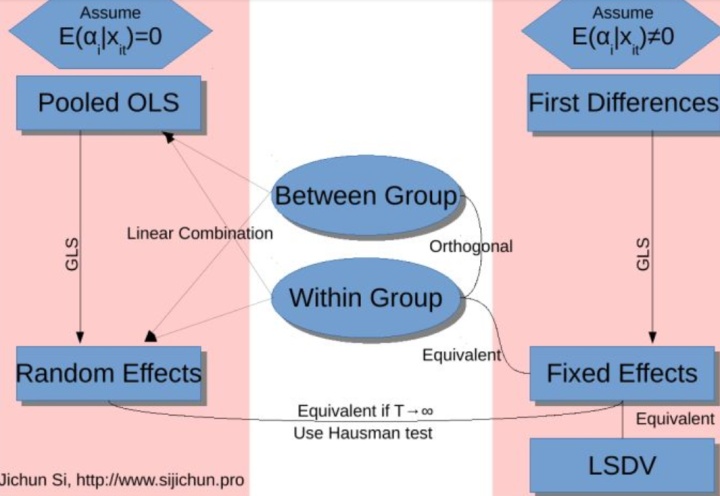
选择什么样的模型应该主要从经济含义出发,而不建议纠结于具体的统计指
标。是否要考虑双向固定效应应当考虑忽视二者所带来的内生性问题有多严重。
个体固定效应只能排除不随时变的个体不可观测因素所可能导致的内生性问题。
你的被解释变量似乎是GDP,解释变量中有FDI?那么我认为应当考虑时间固定效应。
例如,一些制度性的因素可能会同时影响GDP和FDI(如知识产权保护、贸易壁垒等)。
如果从国家层面来看,这种制度性因素存在明显的随时间变化的趋势,那么显然就必须加以排除或控制,
否则FDI将成为内生变量。当然,更严格来说,这些因素很有可能在各省或各行业的变化并不完全一致,
这种情况下,进一步加入省份(或行业)和时间虚拟变量的交互项才能完全排除该类不可观测因素的
影响。fe or re
在做面板数据FE模型时候,解释变量中的虚拟变量被omitted,
但在做RE模型时候,并没有出现此等情况,霍斯曼检验得出是使用FE模型,
但是虚拟变量被omitted,请问该如何改进?
固定效应差分的缘故(陈强)
我们老师说过这种时候把虚拟变量和其他某个变量做交互项
比如x1是dummy ,x2是另外一个随时间随个体改变的量,做一个x1*x2作为解释变量
固定效应模型由于存在N-1个个体效应,其实就是N-1虚拟变量,
如果采用FE模型并多存在一个虚拟变量必然会存在多重共线陷阱,这个时候可以使用RE,
并通过工具变量法等解决内生性,避免参数的非一致性。论坛中大家常用的 Hausman test (RE vs FE),只能在"同方差"之假设下进行。若是"异方差"(而且你若注意顶尖期刊都会修正标准误,意谓著真实之情况极可能是"异方差")之情形即需用这里所谈之方法,而且我深深觉得此方法被低估用途、而大家常用之 (同方差下) Hausman test 则是被高估了!拒绝 null hypothesis (RE),则应该使用 FE (加 robust 选项)
LR图绘制 (命令时每段不换行)
xthreg lncsr lnsize,rx(x1) qx(x1) thnum(2) bs(500 500) trim(0.01 0.01) grid(100)
_matplot e(LR21), columns(1 2) yline(7.35, lpattern(dash)) connect(direct)
msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("First Threshold")
recast(line) name(LR21) nodraw
_matplot e(LR22), columns(1 2) yline(7.35, lpattern(dash)) connect(direct)
msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Second Threshold")
recast(line) name(LR22) nodraw
_matplot e(LR22), columns(1 2) yline(7.35, lpattern(dash)) connect(direct)
msize(small) mlabp(0) mlabs(zero) ytitle("LR Statistics") xtitle("Third Threshold")
recast(line) name(LR23) nodraw
graph combine LR21 LR22 LR23, cols(1) 检验自相关&异方差
横截面数据主要考虑异方差,时间序列主要考虑自相关。
同时存在异方差和自相关,先考虑产生自相关的原因是模型误设还是纯粹的自相关。
如果只是纯粹的自相关,可以用FGLS解决自相关的问题。
而你在解决了自相关后发现,还存在异方差的问题。但是通常情况下方差都是未知的,
我们不方便再做加权最小二乘了。这时要解决异方差的问题,可以采用怀特的“异方差稳健标准误”,
基于这个标准误构造出的统计量可以做出有效的统计推断。
另一种方法:同时存在异方差和自相关时,直接使用HAC,异方差自相关一致标准误,
基于这个标准误构造的统计量可以做出正确的推断。它的前提是你的样本需要足够大。
最后,还需要你根据自己的情况构造出一个合适的模型,上面那些只是理论上的参考
Question:
用stata如何检验panel的自相关和异方差??hettest, szroeter 等只能用在regress之后,
不能用于xtreg.如果stata没有这方面的功能,eviews有的话,那就说说如何在eviews中实现
对panel的自相关和异方差检验吧?
Answer:
A) Test heteroskedasticity. We can use the fact that iterated
GLS=MLE (Refer to most of standard textbooks). Try the following codes.
xtgls y x1 x2 x3 x4 x5, i(country) t(year) igls panels(heteroskedastic)
estimates store hetero
xtgls y x1 x2 x3 x4 x5, i(country) t(year)
estimates store nohetero
local df=e(N_g)-1
lrtest hetero nohetero , df(`df')
B) Test autocorrelation. You can NOT use the fact given above.
Since you can easily see after you write down the likelihood functioin,
GLS does not accout for 1/2*(1+rho), (where rho is the correlation for AR(1) model)
. However, you can use the following code.
tsset county year, yearly (声明时间序列)
findit xtserial
net sj 3-2 st0039
net install st0039
xtserial y x1 x2 x3 x4 x5
XTGLS is a random effects model estimation method, in your case,
you can use xtreg with vce(robust) option to correct for heteoscedasticity
which uses Huber-White (1980) method.
Q:如果检验得知有异方差及自相关,应该如何纠正?
理论上说是要用feasible generalized least squares (FGLS) ,
就是用你提供的命令xtgls和igsl么?
而且在这个命令xtgls y x1 x2 x3 x4 x5, i(country) t(year) igls
panels(heteroskedastic)中的i(country) 和t(year)要提供数据么?
A:Change your country to numbers first. The following is an example.
Your data should look like the following sample.
Once you found the problems of heteroscedasticity and autocorrelation
using the tests provided, then it will be proper to use FGLS using the following
STATA command:
iis country
tis year
xtgls y x1 x2 x3, i(country) t(year) panels(correlated) corr(psar1)
This code corrects for heteroscedasticity across sections (or countries),
it corrects for autocorrelation within countries (serial correlation)
and contemporaneous correlation (spatial correlation) between countries
as well. It is similar (but not exactly same) to Parks’ method in SAS.
Data format
Country year x1 x2 x3
1 1 x x x
1 2 x x x
2 1 x x x
2 2 x x x
3 1 x x x
3 2 x x x
XTGLS is a random effects model estimation method, in your case,
you can use xtreg with vce(robust) option to correct for heteoscedasticity
which uses Huber-White (1980) method.内生性与工具变量
看你用的什么模型,标准的OLS带有IV的2SLS可以采用ivreg命令
ivreg y (x(内生变量)=IV(x的工具变量)control variables) control variables
多内生变量GMM
ivreg2 y x1 x2 (x3 x4 x5 = z1 z2 z3), robust
ivreg 2sls Y X2 X i.country i.year (X1 X1X2=Z1 Z1X2),r 也可
关注一下xtivreg2连玉君
xtgls 的理论解释可以参考Greene(2000,4th,chp15);
个人认为它比较适合“大T小N”或N和T相当的面板数据,而对
于使用最为广泛的“大N小T”型面板该命令并不适用。
可以考虑使用 xtscc 命令得到异方差、序列相关、截面相关稳健型标准误。
fintit xtscc
命令的说明参考 stata journal, 2007, vol3. 在论坛中可以搜索得到该文档。
xtgls 一般用来检验随即效应异方差,而xtscc用来检验固定效应异方差,
建议多看看help xtgls ,help xtscc
from help file,除此对于small T, large N , 还可以用 xtabond and xtabond2
help ivreg2
help xtabond2
(Heteroskedastic and autocorrelation-consistent (HAC) inference in an OLS
regression)
. ivreg2 cinf unem, bw(3) kernel(bartlett) robust small
. newey cinf unem, lag(2)
(AC and HAC in IV and GMM estimation)
. ivreg2 cinf (unem = l(1/3).unem), bw(3)
. ivreg2 cinf (unem = l(1/3).unem), bw(3) gmm2s kernel(thann)
. ivreg2 cinf (unem = l(1/3).unem), bw(3) gmm2s kernel(qs) robust
orthog(l1.unem)
(Examples using Large N, Small T Panel Data)
. use http://fmwww.bc.edu/ec-p/data/macro/abdata.dta
. tsset id year
(Autocorrelation-consistent inference in an IV regression)
. ivreg2 n (w k ys = d.w d.k d.ys d2.w d2.k d2.ys), bw(1) kernel(tru)
(Two-step effic. GMM in the presence of arbitrary heteroskedasticity and
autocorrelation)
. ivreg2 n (w k ys = d.w d.k d.ys d2.w d2.k d2.ys), bw(2) gmm2s
kernel(tru) robust
(Two-step effic. GMM in the presence of arbitrary heterosked. and
intragroup correlation)
. ivreg2 n (w k ys = d.w d.k d.ys d2.w d2.k d2.ys), gmm2s cluster(id)!!!下面按照实证论文的顺序给出一个命令模板
*****************************管理类实证论文模块化命令模板***********************
****************************by 李文 wendell_lee@ruc.edu.cn**********************
*******************************0、数据清理和变量生成****************************
sum x1 x2 x3 //查看异常值
replace x1=. if x1==9999997 //清理异常值
gen age2=age*age //生成年龄平方项
drop if gender<0
rename a2 gender //老变量a2被命名为gender
***************************1、描述性统计:心中明确数据结构**********************
sum y x1 x2 x3
corr y x1 x2 x3//相关系数表
tab y if gender==0 //单变量分数位表
tab y x //联合分布表,最多俩个
***************************2.1、导出Oprobit回归结果*****************************
oprobit y x i.year,r
est store m1
//丰富模型方案:分组且核心变量、控制变量、固定效应逐步放入对比并表
esttab m1 m2 m3 m4 m5 m6,b(%6.3f) se star(* 0.1 ** 0.05 *** 0.01) ///
scalars(N r2 chi2) mtitles title(“图1”),using esttab1.rtf,replace//导出到rtf文件
logout, save(mylogout) excel replace fix(3): /// //注意冒号;导出到Excel文件
esttab m1 m2 m3 m4 m5 m6, ///
b(%6.3f) se(%6.2f) /// //系数、标准误
star(* 0.1 ** 0.05 *** 0.01) /// //显著水平的标注
scalar(r2 r2_a N F) compress nogap
****************************2.2 中介效应:a*b显著即可***************************
//约定,y:因变量 m:中介/调节变量 iv:核心解释变量 cv:协变量
//1.检验系数c(X对Y)
oprobit y x1 x2/*个人层面*/ //c的系数不显著没研究意义
//2.1检验系数a(M对Y)
oprobit y m x2//
//2.2检验系数b(X对M)
oprobit m x1 x2//中介(间接效应)核心在于a*b是否显著,a,b同显著则a*b显著,否则sobel检验
//2.3Sobel检验
sgmediation y if gender==2,mv(m) iv(x1) cv(x2 x3) //sobel中介效应检验
//3.检验系数c‘(中介模型中的下路)
oprobit y x1 x2 m//c‘系数显著,说明直接效应显著
******************************2.3 调节效应:交互项显著即可**********************
generate x1x2=x1*x2 //定义交互项
oprobit y x1 x2 x1x2 x3 x4 //同时进入方程,交互项显著即可,主效应可以不再显著
est store m6
esttab m1 m2 m3 m4 m5 m6,b(%6.3f) se star(* 0.1 ** 0.05 *** 0.01) ///
scalars(N r2 F) mtitles title(“图1”),using esttab1.rtf,replace
//调节效应斜杠图
twoway(lfit y x if m<2) (lfit y x if m>3),xtitle(m) ytitle(m) ///
xscale(range(1 5)) yscale(range(1 5)) xlabel(#5) ylabel(#5)
// m为调节变量,两分段可以不连续,一高一低且能看出两线斜率不一样即可
*******************************3.拓展性研究**************************************
**分位数回归:在y分段内回归(对x分段回归用if限定or门限模型)
qui reg y x1 x2 i.x3,vce(cluster id)//qui表安静回归,quiltly,不报过程
est store OLS
qreg y x1 x2 i.x3,q(0.25) //qreg为分数位回归
est store QR_25
qreg y x1 x2 i.x3,q(0.5)
est store QR_50
qui qreg y x1 x2 i.x3,q(0.75)
est store QR_75
qui qreg y x1 x2 i.x3,q(0.9)
est store QR_90
logout, save(mylogout) excel replace fix(3): ///
esttab QR_25 QR_50 QR_75 QR_90,se mtitles star(* 0.1 ** 0.05 *** 0.01) b(%6.3f)
//分位数回归画图
set seed 10101
bsqreg y x1 x2 i.x3,reps(200) q(0.5)
grqreg, ci ols olsci
**********************************4.稳健性检验**********************************
**(1)PSM克服自选择
psmatch2 belief happiness x1 x2//进入处理组和控制组的概率按协变量匹配
pstest, both
psgraph
//核密度估计图
//- 比较密度函数图
//-匹配前的密度函数图
*-E-version(large)
twoway (kdensity _ps if _treat==1,lp(solid) lw(*2.5)) ///
(kdensity _ps if _treat==0,lp(dash) lw(*2.5)), ///
ytitle("Density", size(*1.1)) ///
ylabel(,angle(0) labsize(*1.1)) ///
xtitle("Propensity Score", size(*1.1)) ///
xscale(titlegap(2)) ///
xlabel(0(0.2)0.8, format(%2.1f) labsize(*1.1)) ///
legend(label(1 "Treatment Group") label(2 "Control Group") row(2) ///
position(10) ring(0) size(*1.1)) ///
scheme(s1mono)
graph export "Figskn01_large.wmf", ///
replace fontface("Times New Roman")
//-匹配后的密度函数图
*-E-version(large)
twoway (kdensity _ps if _treat==1,lp(solid) lw(*2.5)) ///
(kdensity _ps if _wei!=1 & _wei!=.,lp(dash) lw(*2.5)), ///
ytitle("Density", size(*1.1)) ///
ylabel(,angle(0) labsize(*1.1)) ///
xtitle("Propensity Score", size(*1.1)) ///
xscale(titlegap(2)) ///
xlabel(0(0.2)0.8, format(%2.1f) labsize(*1.1)) ///
legend(label(1 "Treatment Group") label(2 "Control Group") row(2) ///
position(10) ring(0) size(*1.1)) ///
scheme(s1mono)
graph export "Figskn02_large.wmf", ///
replace fontface("Times New Roman")
***(2)Heckman两阶段克服自选择偏误
heckman wage edu gender,select(work=family health edu) twostep
//选择变量内至少一一个变量与前不一致,以能生成p_work
heckman wage edu gender,select(work=family health edu) twostep first
probit wage edu gender
predict p_work,xb //生成work概率
gen IMR = normalden(p_belief)/normal(p_belief)
//影响work概率的变量被降维成单变量IMR(逆米尔斯比)
oprobit wage edu gender IMR
















 7497
7497

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









