







 本文详细介绍了如何在Stata中进行面板数据的单位根检验(LLC和IPS方法)、协整分析、确定最优滞后阶数、格兰杰因果检验以及GMM估计、脉冲响应和方差分解。通过实例操作,讲解了数据导入、格式调整、描述性分析等步骤,提供了一套完整的PVAR模型构建流程。
本文详细介绍了如何在Stata中进行面板数据的单位根检验(LLC和IPS方法)、协整分析、确定最优滞后阶数、格兰杰因果检验以及GMM估计、脉冲响应和方差分解。通过实例操作,讲解了数据导入、格式调整、描述性分析等步骤,提供了一套完整的PVAR模型构建流程。

作者:alpamber
网址:https://bbs.pinggu.org/thread-6920947-1-1.html
本文仅用于分享交流,不用于任何商业用途,版权归原作者所有,如有侵权敬请后台联系,我们将在第一时间删除。
简单目录:
stata操作界面简介
PVAR的基本操作流程图
第一步输入数据(以导入Excel数据为例)
第二步 调整数据格式
第三步 描述性分析
第四步 面板单位根检验
第五步 协整检验
第六步 确定最优滞后阶数
第七步 格兰杰因果检验
第八步 GMM估计、脉冲响应及方差分解
stata软件操作界面简介:
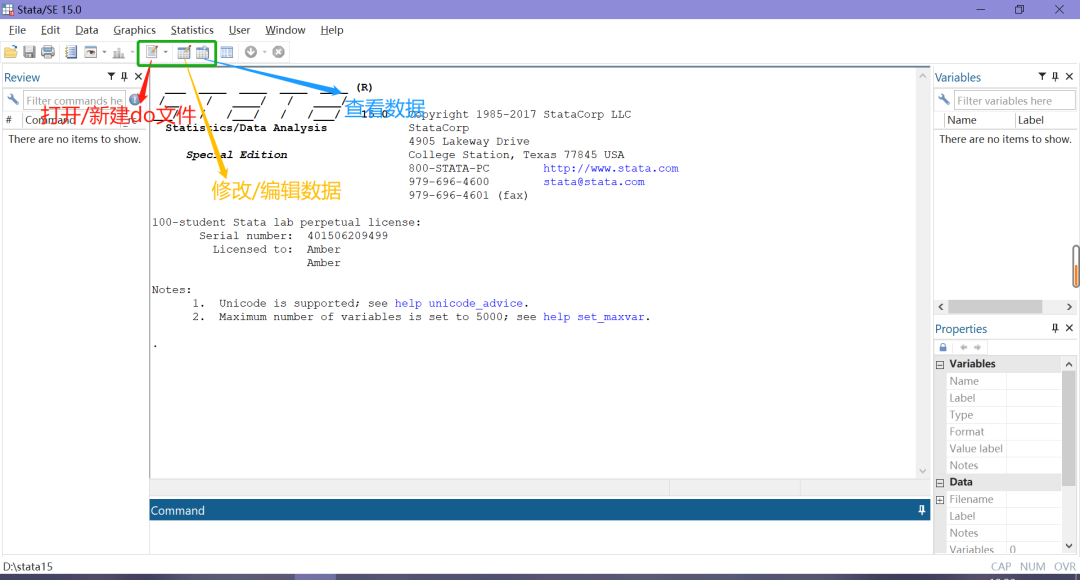
以stata15为例,基本的stata操作界面可以分为六个部分:
最上面两行是菜单,其中比较常用的是第二行中用绿框标出来的三个图标,第一个是新建/打开do文件、第二个是修改/编辑数据、第三个是查看(只读)数据;
整个界面中间的一大块窗口是结果窗口,执行完命令后的结果就显示在这里;
结果窗口左边的是Review窗口,记录刚才执行过的所有命令;结果窗口下边的是Command窗口即命令窗口,我们可以在这里输入命令,但一般仅用于输入一些不需要重复的简单的命令,并不常用;结果窗口右边靠上的窗口是Variables(变量)窗口,显示导入数据中包含的各变量信息;结果窗口右边靠下的窗口是Properties窗口,一般在编辑/修改数据时使用。
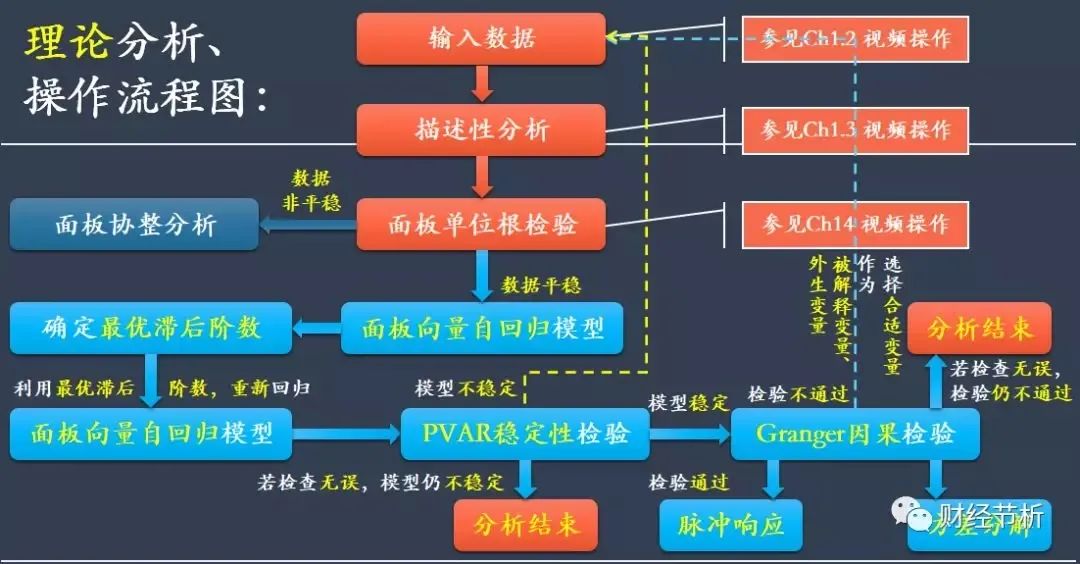
PVAR的基本操作流程图:
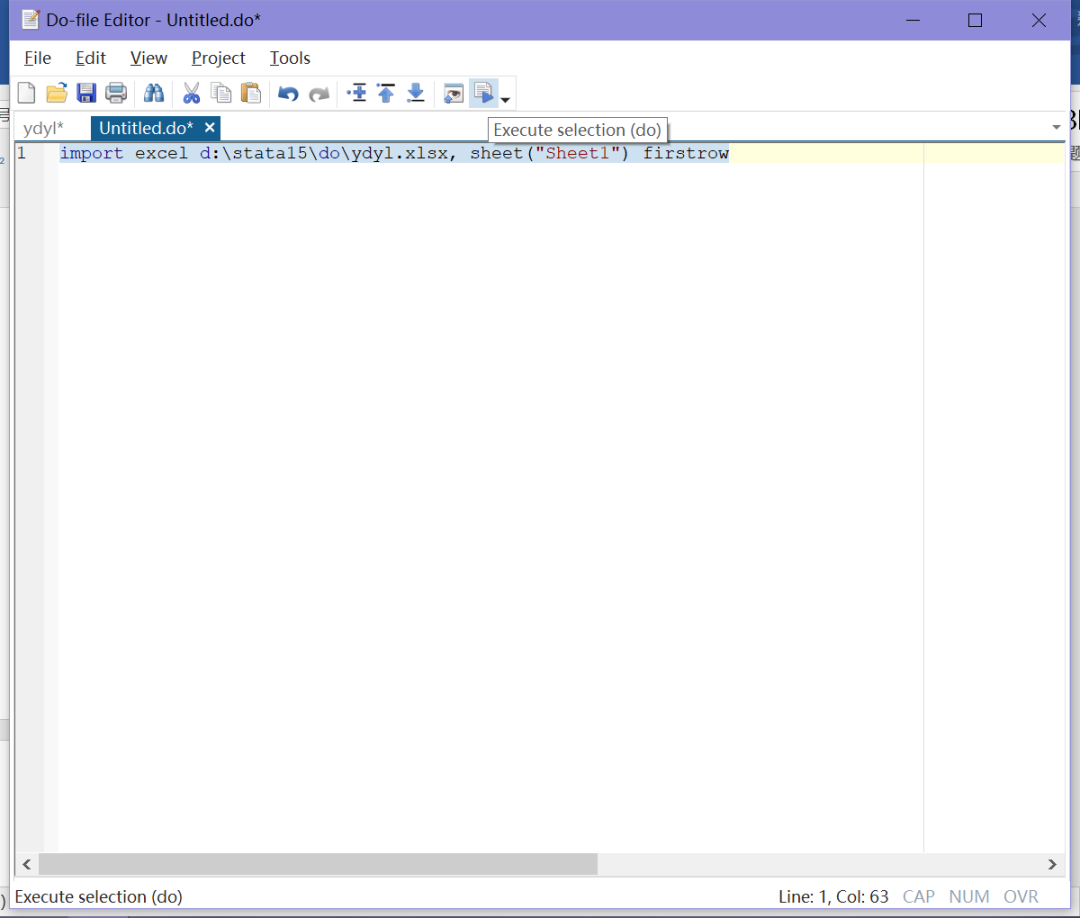
最后,我们在do文件中,输入或复制粘贴命令save d:\stata15\do\ydyl.dta,replace ,就可以将我们刚刚导入的Excel中的数据,保存为stata软件中的dta文件也就是数据文件了。在这一条命令中,save是“保存”命令,d:\stata15\do\ydyl.dta表示要保存在哪个路径及保存的文件名,replace表示替代之前保存的ydyl.dta文件。如果之前没有保存过这个文件,结果窗口中会提示你没有这个文件,所以第一次保存的时候不用觉得奇怪。
第二步 调整数据格式
1. 打开数据
为了简便,我们不在每一次打开stata软件时,都导入和保存一遍数据,而是运用这样的两条命令:
cd d:\stata15\do // 指定默认路径
use ydyl.dta,clear // 打开指定路径下的数据文件
第一条命令为指定默认路径,第二条命令为打开该默认路径下的数据文件,如果我们不指定路径就直接打开文件的话,系统是无法识别的。
2. 调整格式
在PVAR模型中,我们导入的数据前两列要分别是个体变量(如地区、国家)和时间变量(如年度、季度、月度)。但是大多时候,我们直接导入进来的数据中,这两列数据的格式不正确的,在stata中无法识别,之后的统计分析中也会出现诸多问题,所以我们要先调整数据格式。正常情况下,个体变量的数据类型应该是long(如地区一=1、地区二=2…),时间变量的数据类型应该是float,如下图所示,我们可以在查看数据界面右下角的Properties窗口中看到。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









