







一直想找个Kernal了解一下贝叶斯调参框架的原理和LighGBM的算法实现,没想到HomeDefaultRisk数据集的大神竟然专门有一篇kernal是讲基于LightGBM的贝叶斯调参框架Hyperpot。赶紧自己实现一遍,收获很多,文中也有很多引申的额外阅读链接。
先放结论:
贝叶斯优化(Bayesian)是一种自动探索模型最优超参数的方法。会基于历史验证结果来决策模型下一次迭代超参数的选择,这样的好处是:
- 自动,省时间。
- 更好的在测试集上的泛化性能
- 远远低于随机搜索的迭代次数
下面开始!
本文主要内容:
1. 贝叶斯超参调参思想
2. 介绍使用贝叶斯调参框架Hyperopt的四步
3. 与RandomSearch的结果对比
自动超参调优框架
- 这张将介绍使用贝叶斯优化思想来自动对模型超参数进行调优的方法。
- 一般来说有四种对模型超参进行调整的方法:
- 手工:靠经验活瞎猜,根据结果调整。
- 网格调参:给一组参数进行测试,比较耗时因为每种参数组合而成的笛卡尔积都要尝试。
- 随机网格调参:与网格调参一样,只不过会随机挑选参数组合,相对来说对时间和计算资源都要更节约,效果也差不多。
- 自动调优(Automated Hyperparameter Tuning):今天的重点,使用梯度下降,贝叶斯优化Bayesian Optimization 或进化算法来有指导的对模型参数进行调整.
初始贝叶斯优化(Bayesian Optimization Primer)
网格搜索也随机搜索的问题在于不是启发式的调参,先验的模型结果对于后续模型调整的方向毫无帮助。在人工调优时,我们的调参吗方法一般是基于目标函数,正向或反向调整超参数值的过程(比如1,2,3效果一般,7,8,9效果不好,我们大概率参数搜索空间就会落在1,2,3附近),但非启发式的参数搜索就做不到这点。贝叶斯优化的精髓就在于它根据先前结果的验证情况来挑选下一次迭代的超参数。这就使得模型能够花更多时间在相对较好的参数中比较精确的找到最好的那一组参数,而不是漫无目的的在参数空间中浪费我们的计算资源。我们拿下图举个例子:
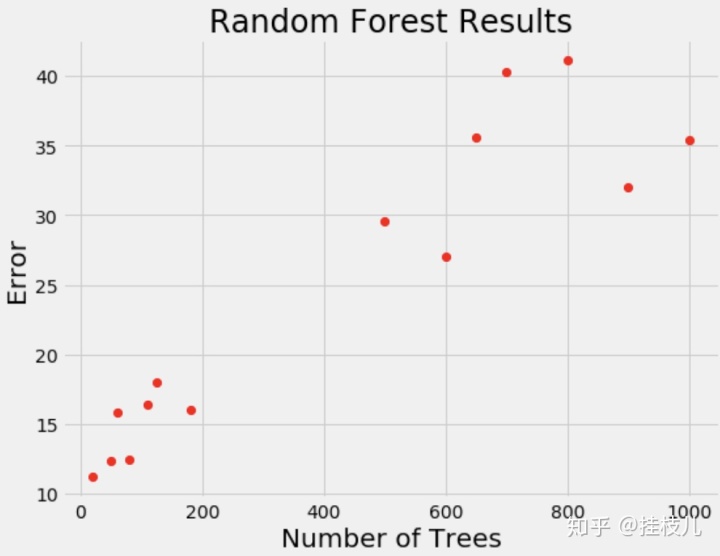
在上图这个验证结果的情况下,如果让你选下一次迭代中树学习期的数量,你大概率会根据错误选择100左右。这就是贝叶斯优化的核心所在,我们等于在脑海中构建了一个概率模型,来根据最大低错误率的概率选择了一个模型参数,其实就是一个P(score | Hyperparameters) 的模型。这个模型是基于我们之前的验证结果的 - 一个个(score, hyperparameter) 对子,并且在每一轮的验证后都会继续得到更新。所以贝叶斯优化的核心思想就是:构建一个初始模型(先验),然后根据后续的结果来对他进行优化。因为随着数据的积累,我们的优化函数会离真正的目标函数越来越接近(因为概率推导的依据更多了)。
贝叶斯优化(Bayesian Optimization)的四个部分:
- 目标函数(Objective Function):以超参数作为输入,返回一个分数(交叉验证分)
- 搜索空间(Domain Space):给定的超参数搜索空间
- 优化算法(Optimization Algorithm):用来构建优化挑选下一次迭代超参数值的方法
- 结果(Results): 分,超参数键值对,用户优化算法的参数挑选。
可以看到,与其他优化算法不同的其实就是:
- 目标函数会返回一个需要优化的分值(其实就是模型结果我觉得)
- 我们的搜索空间会是一个概率分布空间,而不是一个简单的数组
将会使用到的工具包和技术
Hyperopt
这是一个开源的Python贝叶斯优化工具包,可以用它来构建我们的surrogate function(不知道怎么翻译比较好),下面也会用它来构建我们的优化器
梯度学习期(GradientBoostingMachine)
下面将会使用梯度提升器中的LightGBM来结合贝叶斯优化进行学习。选LightGBM是因为此类算法对于超参数的选择非常重要,(也是我为什么选这篇,因为没怎么用过LightGBM,更详细的介绍可以看这篇中文文档
交叉验证与早停(Early Stopping)
在随机和网格搜索中,我们会对每一组超参数进行五折验证。GBM模型也支持进行早停训练,其实就是当验证分数在x轮迭代都没有进一步改进时,就停止训练。这是一个非常好的找到最优树数量的方法,可以用LightGBM的cv模块来实现,这点和XGBoost功能一样
前倾提要基本就是这些,接下来开始coding!
首先导入库,然后读取一部分HomedDefaultRisk的数据
import pandas as pd
import numpy as np
import lightgbm as lgb
from sklearn.model_selection import KFold, train_test_split
from sklearn.metrics import roc_auc_score
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
plt.rcParams['font.size'] = 18
%matplotlib inline
# 定义验证数
N_FOLDS = 2 # 小水管,原kernal 是5折
MAX_EVALS = 5
features.iloc[:,:50].head()
features = pd.read_csv('application_train.csv')
.sample(n=10000,random_state=42).select_dtypes('number').iloc[:,:10]
labels = np.array(features['TARGET'].astype(np.int32)).reshape((-1,))
features = features.drop(columns = ['TARGET','SK_ID_CURR'])
train_features, test_features, train_labels, test_labels =
train_test_split(features, labels, test_size = 2000, random_state = 42)
print('Train shape: ', train_features.shape)
print('Test shape: ', test_features.shape)
train_features.head()
建立Baseline Model
- 建立一个用默认超参数的lgm模型作为baseline
model = lgb.LGBMClassifier(random_state=50)
train_set = lgb.Dataset(train_features,label = train_labels)
test_set = lgb.Dataset(test_features,label = test_labels)
hyperparameters = model.get_params()
hyperparameters
#{'boosting_type': 'gbdt',
# 'class_weight': None,
# 'colsample_bytree': 1.0,
# 'importance_type': 'split',
# 'learning_rate': 0.1,
# 'max_depth': -1,
# 'min_child_samples': 20,
# 'min_child_weight': 0.001,
# 'min_split_gain': 0.0,
# 'n_estimators': 100,
# 'n_jobs': -1,
# 'num_leaves': 31,
# 'objective': None,
# 'random_state': 50,
# 'reg_alpha': 0.0,
# 'reg_lambda': 0.0,
# 'silent': True,
# 'subsample': 1.0,
# 'subsample_for_bin': 200000,
del hyperparameters['n_estimators']
cv_results = lgb.cv(hyperparameters, train_set,num_boost_round=10000, nfold=N_FOLDS,metrics='auc',
early_stopping_rounds=100,verbose_eval=False,seed=42)
cv_results.keys()
>>> dict_keys(['auc-mean', 'auc-stdv'])
best = cv_results['auc-mean'][-1]
best_std = cv_results['auc-stdv'][-1]
print('Best score {:.5f} with std {:.5f}, num of iterations is {}'.format(
best,best_std, len(cv_results['auc-mean'])))
>>> Best score 0.58771 with std 0.00842, num of iterations is 33目标函数(Objective Function)
- 我们第一步首先构建一个以超参数作为输入,输出交叉验证分的函数。在
Hyperopt
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 580
580











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









