







索引
保证数据完整性。
关注索引的两个点:树和有序(树可以定位索引的起点,有序可以定位索引的终点)
1.每个表都是一个索引组织表(集群表)
以主键来组织的一个表
主键索引
2.其他索引都是二级索引
每个二级索引上都有主键列
3.对于每个唯一约束,系统会自动在这个约束上建一个唯一索引!
建立外键时,也会自动建立外键索引!
eg:建立一张表:
> create table t2(id int,name varchar(20),bir_th data, constraint primary key (id),constraint unique (name));
#对id列主键约束/id列作为主键,name列作唯一约束
> show create table t2 \G #看t2表建立时的语法
> show index from t2; #显示t2表的索引
> insert into t2 values(1,'skj','2011-11-12');
如果插入的新数据id列或者name列与已有的值相同,就不允许建立!!
> create table t3(id int,name varchar(20),bir_th data, constraint primary key (id),constraint foreign key (name) references t2 (name));
#给新建的t3表的name列建立外键索引,到t2表的name列。
给外表t3插入数据时,插入的name列的值必须是主表t2里已经存在的!!
对主表做delete时,外表是有影响的;
对主表update时,外表也是有影响的。
PS:级联删除:
删除主表的数据时,关联的从表数据也删除,则需要在建立外键约束的后面增加on delete cascade 或on delete set null,前者是级联删除,后者是将从表的关联列的值设置为null。
在主表删除一行数据并且从表有对主表的引用时:
①restrict:系统不允许这个删除操作。
②cascade:顺带着也会删除从表上面引用的那些数据行。
③set null:主表删除时,从表上面引用的那些数据行外键值会置空。
④no action:主表随便删,对从表不作任何访问。
一般将外键消灭,因为批量导入数据的时候要大量访问主表,而且会锁主表。
索引的功能:提高访问的速度
通过索引访问表的特点:
1.通过扫描索引,找到我们要访问的行
2.需要几行,访问几行
全表扫描:
1.访问所有的行,使用条件过滤掉不满足条件的行
2.过滤的数据,就是额外消耗的资源
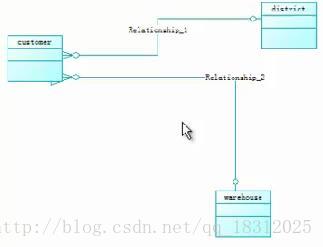
customer表引用了district表(区域表)和warehouse表(仓库):
select c.c_first,c.c_last,c.c_city,o.o_id,o_entry_d
from customer c,orders o
where o.o_d_id=c.c_d_id and o.o_w_id=c.c_w_id and o.o_c_id=c.c_id and c.c_id=1 and c_w_id=1;
select …
from 主表,外表
where 主表.主键=外表.外键(主外键关联条件)
and 主表的约束条件 | 外表的约束条件
没加 c_w_id=1 时 SQL的执行计划:

可以看到,走customer表时,没有走索引,而且访问的行巨大,必然执行起来慢。
explain 中id大的先执行,相同的按顺序执行

(因为customer表是三个列作主键索引。而我们只用了一个列,所以,再加一个试试)
加了 c_w_id=1 后:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









