






视觉预训练新思路!RevColV2:首次在MIM视觉预训练中实现特征解耦学习
不再需要大量带标签的数据集进行有监督训练!RevColV2基于可逆列网络,首次在MIM视觉预训练中实现了特征解耦学习,统一了上下游任务的网络结构,在COCO检测和ADE20K分割任务上达到了62.1的AP和60.4的mIoU。
RevColV2 是 RevCol 这个模型的自监督训练版本,主要探索的是如何把掩码图像建模 (Masked image modeling, MIM) 的思想应用于 RevCol 这个可逆的柱状神经网络,不再需要大量带标签的数据集进行有监督训练。RevColV2 的观点是:现有的 MIM 方法的 Backbone 由 Encoder 和 Decoder 组成,在预训练完成之后的微调环节中,会丢弃掉 Decoder 这个模块,而只保留 Encoder 这个模块。这就导致预训练和微调过程的架构变得不再一致了。
RevColV2 的架构保持了 RevCol 的可逆柱状神经网络的做法,这种架构的特点是不同 Column 的末端保持了解耦的高级的语义信息和低级的视觉信息。RevColV2 的架构中,单个 Column 的模型从 V1 的 ConvNeSt 架构变为了 ViT 架构。
RevColV2 可以看成是把 MIM 方法使用在 RevCol 这种特殊的架构的一种尝试,在视觉下游任务上取得了不错的性能。
RevColV2:可逆柱状神经网络遇见掩码图像建模
论文名称:RevColV2: Exploring Disentangled Representations in Masked Image Modeling
论文地址: https://arxiv.org/pdf/2309.01005.pdf
MAE 式掩码图像建模方法的局限性
视觉基础模型预训练的一个关键环节是:如何学习到泛化性能较强的特征,以满足各种视觉应用的需求。典型的一系列方法比如有监督学习,对比学习,还是自监督学习,都在探索这个问题。
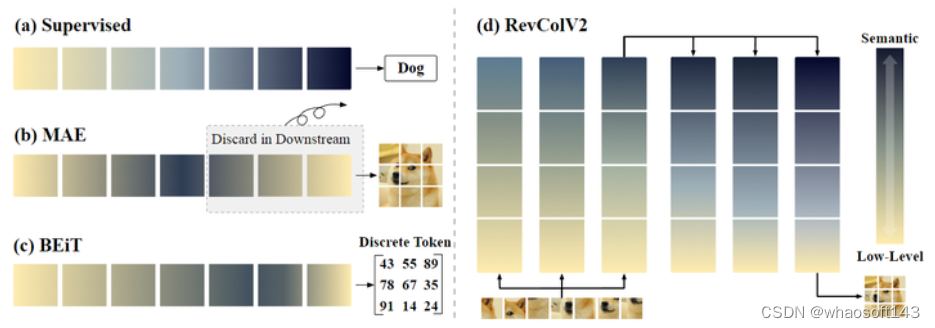
图1:不同预训练范式的信息分布表征
典型的自监督学习方法比如掩码图像建模 (Masked image modeling, MIM) 的代表工作 MAE,使用 Encoder 将 mask 之后的图片提取嵌入信息到语义表征中,并使用 Decoder 来重建 mask 掉的图片内容。在这种预训练范式下,特征在输入和输出中都具有丰富的低级信息。下游任务所需的语义特征保留在网络中。
如果想要去利用 MAE 的语义特征,常见的做法是人为手动来划分 Encoder 和 Decoder,并且在下游任务上面微调的时候丢弃掉 Decoder。但是这种做法带来的问题是:人为划分的 Encoder 和 Decoder 会约束语义信息出现的位置。而且,在进行下游任务时丢弃掉预训练网络的 Decoder 可能会导致 low-level 信息的丢失,导致此类方法的泛化能力一般而言较差。作者给出的原因是:因为用于重建图像 low-level 信息和 high-level 的语义信息会在 MIM 期间相互纠缠和交织。
本文依赖于 RevCol 这个可逆的柱状神经网络,从架构设计的角度解决这个问题,试图去借助 RevCol 模型在架构设计方面的特点和优势来解决丢弃 Decoder 导致的 low-level 信息丢失的问题。本文方法不丢弃 Decoder,而是将整个 Auto Encoder Decoder 架构保留在预训练和微调中。为了使得预训练之后的模型获得更好的迁移性能,作者认为应该在预训练的过程中分离 low-level 的细节信息和 high-level 的语义信息。
一种简单的做法是将 RevCol 与 MAE 中使用的解码器直接组合起来进行 MIM 预训练。但是这种做法需要借助 RevCol 的 low-level 和 high-level 的信息来推理被遮挡住的看不见的图片细节,从而产生纠缠的信息。这不仅会损害下游任务,而且破坏了 RevCol 的解耦学习目标。
因此本文的 RevColV2 就是为了设计全新的适合 MIM 的 RevCol 架构。
RevColV2 架构设计
RevColV2 的架构设计在基本模块上面遵循 RevCol(V1) 的架构设计,下面链接这里有比较详细的介绍。下面摘录一段:
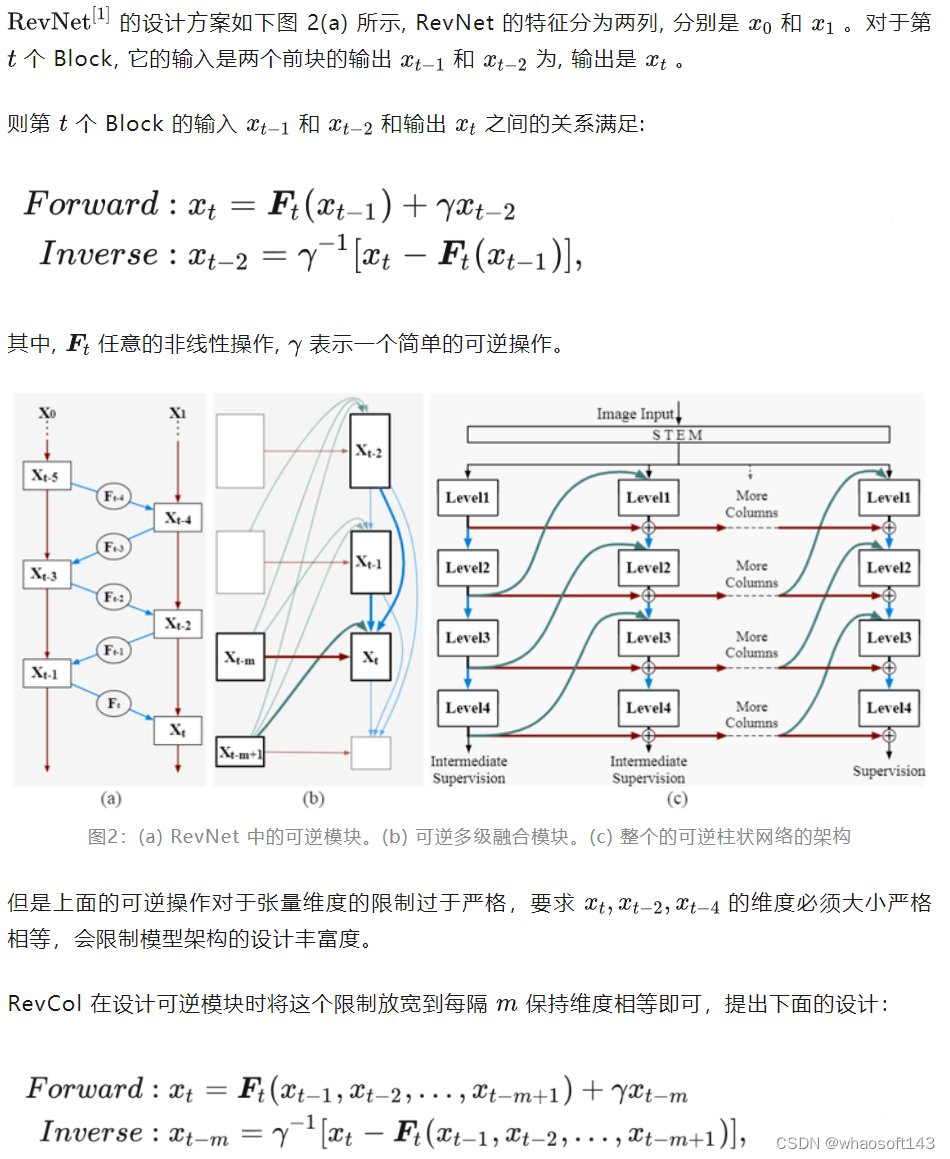

最后,图 2(b) 可以改画成图 2(c) 的 Multi-Column 的形式,每个 Column 都是一个子网络,由 mm 个特征组成,而且是可逆的,也是 RevCol 的基本组成架构。RevCol 整个模型由多个这样的子网络 (Column) 构成,各个子网络之间通过可逆变换 (Reversible Transformation) 进行连接。给定一个 Column 的特征,可以根据式 1 在前向和后向传播期间递归地计算其他 Column 的特征。在反向传播时,可以动态地从最后一个 Column 的特征激活值重建其他 Column 的激活值。只需要在训练期间在内存中维护一个 Column 的激活值即可。
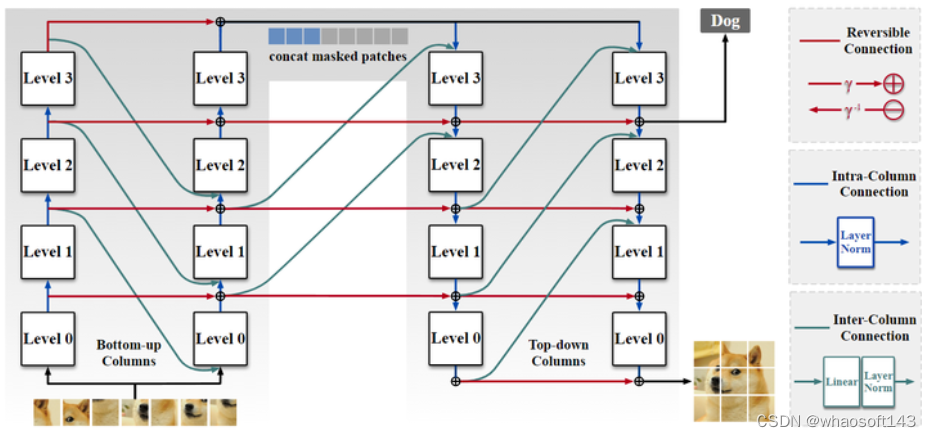
图3:RevColV2 架构设计
RevColV2 架构如上图3所示,其特点是:
- 由对称的自下而上的 bottom-up Columns 和自上而下的 top-down Columns 组成。
- 前者可以看成是 Encoder,后者可以看成是 Decoder。
- 输入图片首先按照 ViT 的方式执行分 Patch 的操作。
- 按照 MAE 的做法随机 mask 掉一些 token,将剩余部分输入给 bottom-up 的 Column 中。

RevColV2 架构的设计模式有两点优势:
1) 适合 MIM 的训练策略,high-level 的语义信息和 low-level 的细节信息可以在预训练的过程中间同时保存,并通过可逆变换在不同 Column 之间传输。
2) low-level 的细节信息在自下而上的 bottom-up Columns 和自上而下的 top-down Columns 中都有保存,因此,在微调期间不需要丢弃网络的一部分。可以在下游任务中同时使用所有的架构。
RevColV2 预训练方法
MIM 预训练
如上图3所示,在 MIM 预训练中,mask 之后剩下的图像 token 被送到自下而上的 bottom-up Columns 中,并通过自上而下的 top-down Columns 组成重建被 mask 掉的 token。在最后一个 Column 的 level0 特征使用 Mean-Square Error (MSE) 损失函数来重建图像。在这种情况下,自上而下的 top-down Columns Decoder 不仅学习重建细节,还学习语义特征,这表明下游任务可以直接利用这些解码器输出。
联合预训练
作者还借助了 CLIP[2] 模型作为教师模型,并使用余相似度作为损失函数对语义特征进行建模。因为可逆柱状网络的特征是解耦的,所以作者可以同时借助 high-level 的特征做蒸馏损失函数,和 low-level 的特征做 pixel 级别的图像重建损失函数。
下游任务微调
对于图像分类这样需要很多 highly semantic 特征的任务来讲,RevColV2 把分类头放在最后一个 Column 的最后一个 level 上面。由于整个网络通过 MSE 优化重建特征,所以底层信息汇聚到了前面的 level,语义信息保留在了顶层的 level。
对于既需要 high-level 语义信息和 low-level 细节信息的密集预测任务,作者取最后一个自上而下的 Column 的所有 level 的特征,然后将它们直接连到面向任务的密集预测头。
RevColV2 模型细节
RevColV2 模型有两种变体,分别是 RevColV2-Base 和 RevColV2-Large。Encoder (自下而上的 Column) 和 Decoder (自上而下的 Column) 的深度分别为12和4。模型参数包括整个自下而上的 Column 和自上而下的 Column。
在图像分类等下游任务中,并非所有的 level 都参与计算,因此参数的数量略低。与原始版本 RevCol(V1) 相比,不会对每一列使用中间监督,因为它需要仔细调整。

图4:RevColV2 模型变体配置细节
ImageNet-1K 实验结果
实验设置:作者在 ImageNet-1K 数据集上进行 MIM 预训练。主要设置遵循 MAE[3],其中 mask ratio 设置为 75%,图像重建的目标是归一化的像素值。一共预训练了 1600 个 Epochs。预训练图像的分辨率是 224×224,Batch Size 设置为 4096,基础学习率 1.5e-4,weight decay 设置为 0.05。
MIM 预训练结束后,作者再以预训练结束的权重做初始化,再在 ImageNet-1K 上面做微调。为了充分利用 RevColV2 的潜力,作者在 MIM 预训练后之后,再在 ImageNet-22K 上做中间微调,最后再在 ImageNet-1K 上面微调模型,这里遵循的是 ConvNeXt V2[4] 的实验设置。
实验结果如下图5所示。RevColV2-B 在只使用 ImageNet-1K 做微调的情况下达到了 84.7% 的精度,相比于 MIM 方法训练的 ViT 超过了不少。作为纯 Transformer 的 Isotropic 的架构,RevColV2-B 达到了比 SwinV2-B 、HorNetGF-B 更高的性能。RevColV2-L 达到了 86.3% 的性能,超过了 ConNeXt V2,MAE,CAE 的性能。
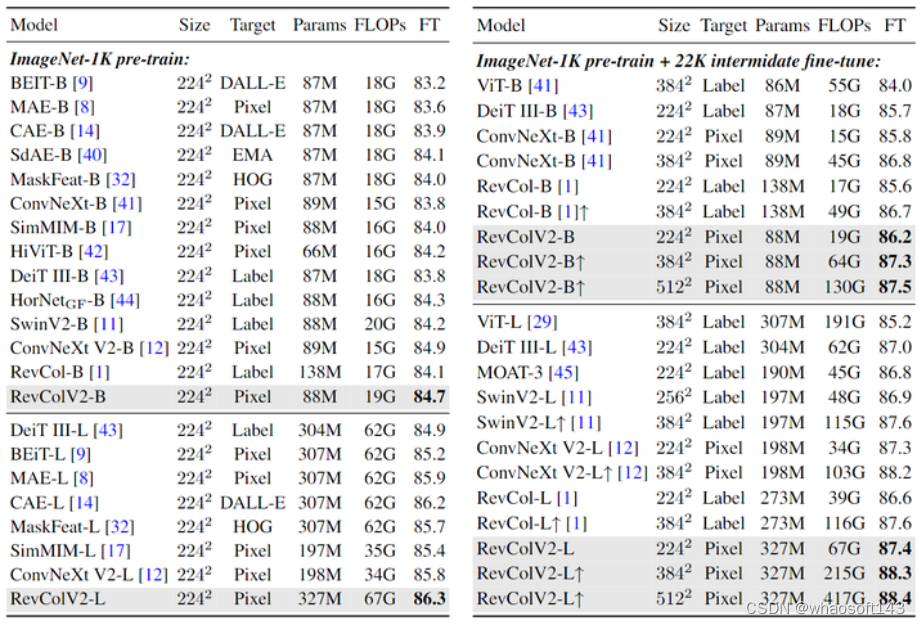
图5:ImageNet 实验结果
ADE20K 语义分割实验结果
语义分割头:UperNet 和 Mask2Former。初始化权重使用的是 ImageNet-1K 预训练的权重。实验结果如下图6所示,RevColV2 模型在不同的 Transformer 和 CNN 架构上的单尺度和多尺度 mIoU 上获得了具有竞争力的性能。在 ImageNet-1K 上预训练的 RevCol-B/L 在 ADE20K 上实现了 52.3 和 54.4 的 mIoU,输入分辨率为 512×512,优于 ConvNeXt V2。
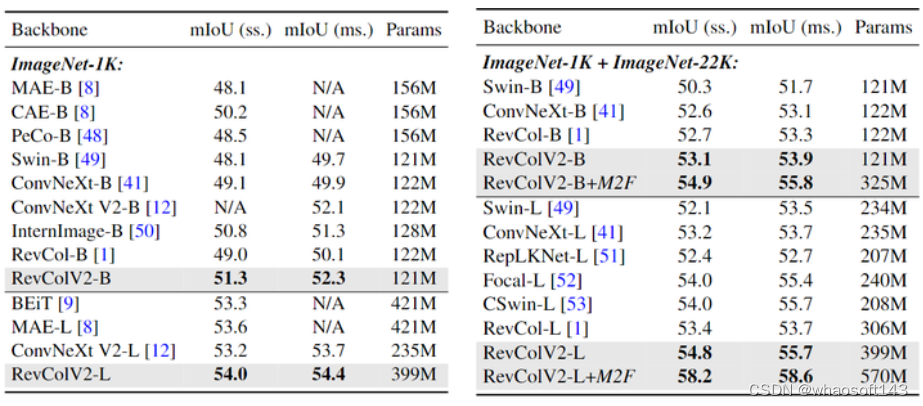
图6:ADE20K 语义分割实验结果
COCO 目标检测和实例分割实验结果
目标检测和实例分割头:Mask R-CNN 和 Cascade Mask R-CNN。初始化权重使用的是 ImageNet-1K 预训练的权重。实验结果如下图7所示,左侧是 Mask R-CNN 实验结果,右侧是 Cascade Mask R-CNN 实验结果。RevColV2 系列实现了基础模型和大模型的 52.4 和 54.0 box AP,优于 MAE 系列的性能。当使用 Cascade Mask R-CNN 检测时,RevColV2-B 达到了 55.2 box AP 和 47.9 mask AP,优于 RevCol(V1)-B,ViTDet-B 等。注意在所有密集预测任务中,不使用任何额外的特征金字塔结构,像 FPN 或者 BiFPN。
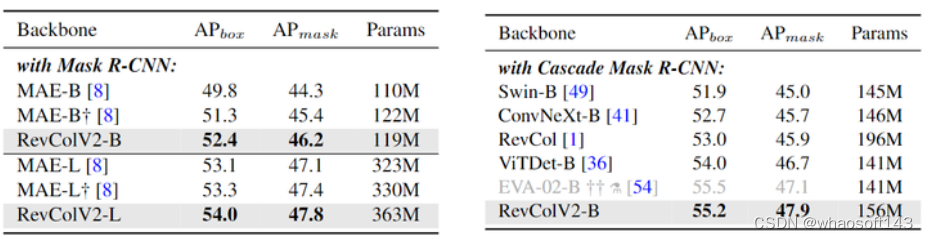
图7:COCO 目标检测和实例分割实验结果
联合训练实验结果
在联合训练的实验设置中,作者使用 OpenCLIP-L 作为教师模型,并使用 Laion400M[5] 作为训练数据。作者在 Laion400M 上训练了 800 Epochs,并在 ImageNet-1K 数据集上训练了 300 Epochs。
在这种设置下,RevColv2-L 达到了 87.7% 的 ImageNet-1K 精度,这个值超过了 ImageNet-1K MIM 预训练的结果 (86.3%) 以及 ImageNet-1K MIM + ImageNet-22K 中间微调的结果 (87.4%)。COCO 检测和实例分割结果:62.1 box AP 以及 52.3 mask AP。ADE20K 语义分割结果:60.4 mIoU。
RevColV2 分析
RevColV2 能够学习到解耦的表征。
Linear Probing 是评估特征稀疏性的有用工具。作者假设 high-level 的语义信息往往更加稀疏,而 low-level 的低级信息更丰富。因此,作者评估了每个 level 的 Linear Probing 精度,以可视化语义和低级信息的分布。
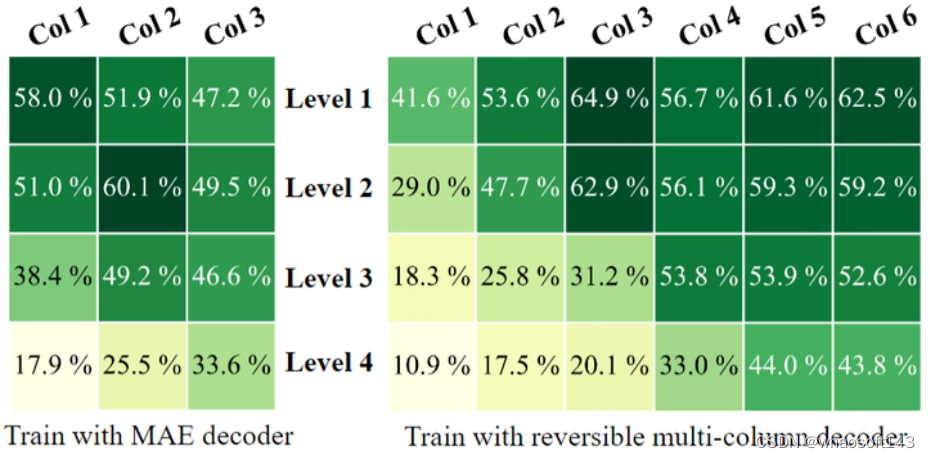
图8:预训练300个 Epoch 后 ImageNet-1K 上每个 level 的 Linear Probing 精度。左边是 RevCol+MAE 基线,右边是具有可逆多列解码器的 RevColV2
作者进行了两种设置:
RevCol(V1) + MAE: RevCol(V1) 的 Encoder 有3个 Column,MAE 的 Decoder 有8个 ViT Block。
RevColV2: 3个 bottom-up Columns Encoder 以及 3个 top-down Columns Decoder,每个 Column 包含12个 Block。
图8显示了 ImageNet-1K 实验结果。RevCol(V1) + MAE 只有 47.2% 的精度,远低于上一个 level 的 60.1%。RevCol(V1) + MAE 在 Column 的传播过程中纠缠 low-level 的信息和 high-level 的语义信息,因为 MAE Decoder 需要低级和语义特征来重建看不见的图像 Patch。而 RevColV2 可以学习解纠缠的表征,使得 Encoder 和 Decoder 的最后一个 level 达到了较高的 Linear Probing 精度,并且随着 level 的降低,精度也下降。说明 low-level 的信息和语义信息解耦或者分离了,分离的语义信息显著提高了 Linear Probing 的精度。
RevColV2 这种 Auto Encoder 的架构对于微调性能很重要。
作者对比了两种设置:1) 只有 bottom-up Columns Encoder 的变体。2) 全部 AutoEncoder 的 RevColV2 架构。在ImageNet-1K 上的微调精度是:83.8% v.s. 84.7%。显示 top-down Columns Decoder 在下游微调中至关重要。为了消除模型容量的影响 (Params 和 FLOPs),作者还进行了一个实验,其中包含相同数量的 Params 和 FLOPs 进行比较。实验结果表明,该bottom-up Columns Encoder 的变体精度 83.9% 仍然低于全部 AutoEncoder 的 RevColV2 架构的 84.7%。















 4504
4504

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









