






Generating Classification Weights with GNN Denoising Autoencoders for Few-Shot Learning
https://arxiv.org/pdf/1905.01102.pdfarxiv.org一、论文出发点
少样本学习出发点老生常谈:并不是所有情况下,训练样本都足够,那么训练样本少,怎么学习模型参数了。
二、灵感来源
很多类具有相似性,那么他们的分类参数实际也有关联,所以是不是可以从已有的基础类分类参数,学习新类的分类参数,并调整旧类参数了。 作者将灵感公式化如下:

三、论文核心思想
那么作者是怎么实现上面公式中的分类参数生成器的了??
先直接上结果,论文从一组初始化分类参数,根据下述梯度上升公式(黄色部分),来调整W,其中r(w)为一个降噪编码的输出。
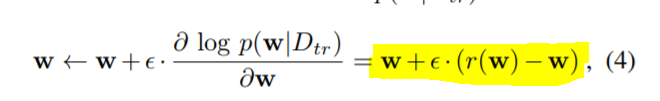
而初始化参数是这样的:基础类的参数就用基础类的,新类的初始化为他们少量样本输出特征的求平均。
为什么可行??
降噪编码的目标是要完美复现噪声污染前的信号,但是基本不可能,所以复现中存在偏差,而理论表明,这个降噪复现偏差向量(因为多特征,所以是向量)可以近似认为与特征密度分布函数梯度向量一致。(论文中公式2表达的意思)
也就是说,公式就是让W往密度分布高(真实数据所在位置:黄色部分)的位置走。

核心思想总结为:
根据已有基础类的分类参数数据分布,利用一个降噪自编码器去同时复现基础类分类参数分布和新类分类参数分布,由于要复现出大量基础类分类参数分布信息,可以认为复现的新数据分布能够合理的体现真实数据分布。
注意上述DAE是已经训练好的情况下,用于计算真正的新类参数。
四 、DAE的训练
为训练DAE,作者定义损失函数如下。注意这个里面没有真正的新类,新类样本是从基础类中选的,所以作者将其叫做伪新类,这样做是为了训练出DAE,因为基础类的分类参数才有真值。

关于DAE的图卷积结构,有兴趣的可以自读。















 4244
4244











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









