






虽然目前的MLLMs在科学图表解读方面取得了一定成果,但在处理自然图像与图表图像的数据差异时,尤其是在从图表中提取数值信息的能力上存在不足。为了克服这一挑战,研究团队通过三种策略优化了模型的图表理解能力:
- 一是引入原始数据值进行预训练以增强对图表数据的理解;
- 二是利用文本表示随机替代图像,在端到端微调过程中提升模型的语言推理到图表解析技能;
- 三是要求模型先解析图表数据再作答,以提高准确性。
基于这些发现,研究人员开发了CHOPINLLM,这是一种专为深度图表理解设计的MLLM,它不仅能够解析多种类型的图表,包括无标注图表,还能保持稳健的推理能力。此外,文中还建立了一个新的评估基准,用于测试MLLMs对不同图表类型和理解层次的掌握情况,实验结果证实了CHOPINLLM在图表理解方面的出色性能。
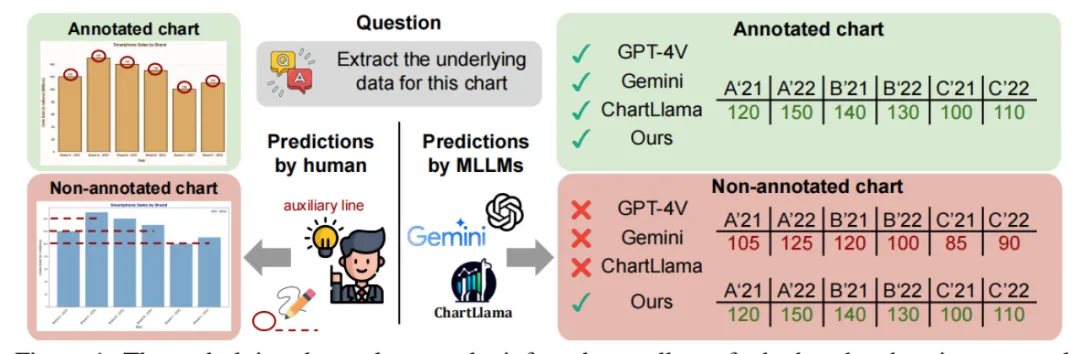
1 MLLMs在图表理解领域存在的问题
当前数据集的局限性,如图表的过度简化和同质化,以及模板化问题设计,可能夸大了模型的实际进展。MLLMs在从图表中精确提取数值信息方面仍有不足,特别是在数值未直接标注的情形下。误导性问题更是凸显了模型在复杂情境下的脆弱性。此外,现有评估方法未能充分反映MLLMs在视觉数学问题解决上的全貌,而训练这类模型所需的庞大资源限制了其可扩展性。随着图表类型的日益丰富与复杂,模型需不断提升以满足更高层次的分析需求。
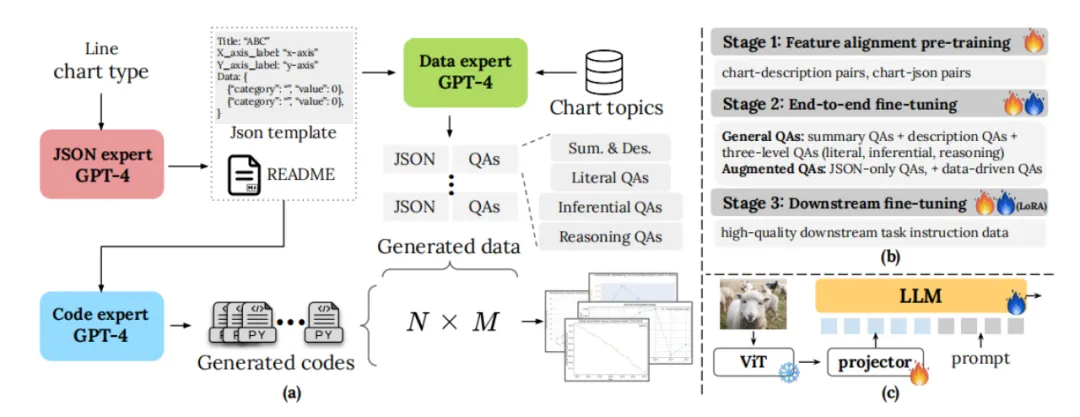
2 如何改善MLLMs的图表理解能力
(1)融合策略
- 引入原始数据值:在预训练阶段融入图表的原始数值数据,这有助于模型更好地理解和关联图表中的视觉元素与实际数值,从而显著提升对图表数据的理解能力。
- 生成多样化图表数据:通过创新的数据生成管道,创建包含多种图表类型、主题和样式的大型数据集,确保模型接触到广泛的变化,增强其理解和适应能力。
- 合成数据的利用:在不同的训练阶段使用合成数据,实验表明,在预训练和微调阶段早期使用合成数据比仅在LoRA下游微调阶段使用更为有效,有助于模型更好地学习图表理解的基础知识。
(2)端到端微调技术
- 随机文本表示替换:在端到端微调过程中,随机地用图表的文本描述代替图像本身,这一过程帮助模型将语言推理能力迁移至图表解读技能,提高模型的泛化能力。
- 两步法微调:首先要求模型从图表中提取底层数据,然后再基于这些数据回答问题,这种策略进一步提高了模型回答图表相关问题的准确度。
(3)图表数据的处理方式
- 特征对齐预训练:通过特征对齐的预训练,模型可以学习到图表图像与其对应的文本描述之间的关联,这有助于模型更有效地从图表中抽取信息。
- 多阶段微调:在多个阶段进行微调,特别是在LoRA微调之前,将合成数据与真实图表数据结合使用,可以优化模型对图表数据的偏好,避免输出偏向与下游任务不匹配的情况。
- 构建全面的基准测试:建立一个包含不同类型图表和不同理解层级的新基准测试,用于全面评估MLLMs在图表理解上的能力,确保模型不仅能在基本数据提取、总结上表现出色,也能处理复杂的数学推理和推断性问题。
3 结语
本文介绍了针对图表理解定制的多模态大型语言模型(MLLM)的最新进展,通过改进预训练方法以提升模型对图表数据的解析能力和推理准确性,同时提出了一种新模型CHOPINLLM及相应的评估基准,展示了其在各类图表理解任务中的优异表现。
论文题目:On Pre-training of Multimodal Language Models Customized for Chart Understanding
论文链接:https://arxiv.org/abs/2407.14506
PS: 欢迎大家扫码关注公众号_,并回复“资料”获取书籍学习资源。我们一起在AI的世界中探索前行,期待共同进步!
















 982
982

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









