






简介
channel 是 Go 语言中的一个核心类型,可以把它看成管道。并发核心单元通过它就可以发送或者接收数据进行通讯,这在一定程度上又进一步降低了编程的难度。
channel 是一个数据类型,主要用来解决 go 程的同步问题以及 go 程之间数据共享(数据传递)的问题。
goroutine 运行在相同的地址空间,因此访问共享内存必须做好同步。goroutine 奉行通过通信来共享内存,而不是共享内存来通信。
引⽤类型 channel 可用于多个 goroutine 通讯。其内部实现了同步,确保并发安全(通过 CSP)。
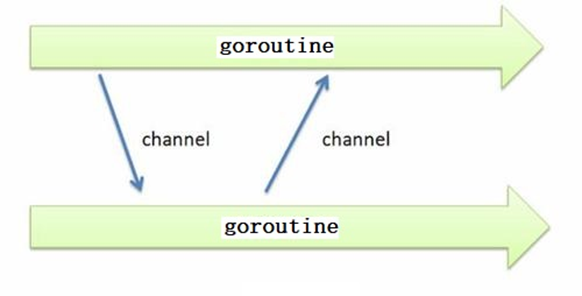
强调一下:
channel 是一个数据类型,对应一个“管道(通道)”。
定义 channel 变量
和 map 类似,channel 也是一个对应 make 创建的底层数据结构的引用。既然是引用, 那么我们在传参的时候就能完成在 A 函数栈帧内修改 B 函数栈帧数据的目的. 说白了就是传的地址.
当我们复制一个 channel 或用于函数参数传递时,我们只是拷贝了一个 channel 引用,因此调用者和被调用者将引用同一个 channel 对象。 和其它的引用类型一样,channel 的零值也是 nil。
定义一个 channel 时,也需要定义发送到 channel 的值的类型。channel 可以使用内置的 make() 函数来创建:make(chan Type) // 等价于 make(chan Type, 0)
make(chan Type, capacity)chan 是创建 channel 所需使用的关键字。
Type 代表指定 channel 收发数据的类型。
当参数 capacity = 0 时,channel 是无缓冲阻塞读写的;当 capacity > 0 时,channel 有缓冲、是非阻塞的,直到写满 capacity 个元素才阻塞写入。
channel 非常像生活中的管道,一边可以存放东西,另一边可以取出东西。channel 通过操作符
x :=
x, ok :=
默认情况下,channel 接收和发送数据都是阻塞的,除非另一端已经准备好,这样就使得 goroutine 同步变的更加的简单,而不需要显式的 lock。
我们先看一下没有用 channel 的例子:package main
import (
"fmt"
"time"
)
// 定义一个打印机
func printer(s string) {
for _, value := range s {
fmt.Printf("%c", value)
time.Sleep(time.Millisecond * 300)
}
}
/* 定义两个人使用打印机 */
func person1() {
printer("hello")
}
func person2() {
printer("world")
}
func main() {
go person1()
go person2()
time.Sleep(time.Second * 5) // 注意,只写上面两行会直接运行完毕,想一想 go 程的特性
}
结果:hwoelrllod
那么,怎么用 channel 实现来保证顺序输出呢?
因为,person1 与 person2 都需要用一个 channel,所以要在全局定义一个 channel。具体代码如下:
PS:你要传的什么类型数据与 channel 中定义的类型没有必然的联系。package main
import (
"fmt"
"time"
)
// 全局定义一个 channel,用来完成数据同步
var ch = make(chan int) // 传的什么类型数据与 channel 中定义的类型没有必然的联系
// 定义一个打印机
func printer(s string) {
for _, value := range s {
fmt.Printf("%c", value)
time.Sleep(time.Millisecond * 300)
}
}
/* 定义两个人使用打印机 */
func person1() {
printer("hello")
ch
}
func person2() {
printer("world")
}
func main() {
go person1()
go person2()
time.Sleep(time.Second * 3) // 注意,只写上面两行会直接运行完毕,想一想 go 程的特性
}
这个时候,当运行 person2 函数时,会阻塞在
但是这时,ch
我们再来看一段代码:package main
import "fmt"
func main() {
c := make(chan int)
go func() {
defer fmt.Println("子 go 程结束")
fmt.Println("子 go 程正在运行 ...")
c
}()
num :=
fmt.Println("num = ", num)
fmt.Println("main go 程结束")
}
运行结果:子 go 程正在运行 ...
子 go 程结束
num = 666
main go 程结束
以上我们都是用 channel 用来做数据同步,并没有用到 channel 中的数据,下面我们看一个用 channel 完成数据传递的例子:package main
import "fmt"
func main() {
ch := make(chan string)
// len(ch): channel 中剩余未读取的数据个数; cap(ch): channel 的容量
fmt.Println("len(ch) = ", len(ch), "cap(ch) = ", cap(ch))
go func() {
for i := 0; i < 2; i++ {
fmt.Println("i = ", i)
}
ch
}()
str :=
fmt.Println(str)
}
注意:len(ch): channel 中剩余未读取的数据个数; cap(ch): channel 的容量
运行结果:len(ch) = 0 cap(ch) = 0
i = 0
i = 1
子 go 程打印完毕
强调一下:
channel 有两个端:写端(传入端):chan
读端(传出端):
要求:读端和写端必须同时满足条件(读端有数据可读,写端有数据可写),才能在 channel 中完成数据流动。否则,阻塞。
【补充知识点】
每当有一个进程启动时,系统会自动打开三个文件:标准输入、标准输出、标准错误,对应三个文件:stdin、stdout、stderr。
当进程运行结束时,系统会自动关闭这三个文件。
无缓冲的channel - 同步通信
无缓冲的通道(unbuffered channel)是指在接收前没有能力保存任何值的通道。
这种类型的通道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。否则,通道会导致先执行发送或接收操作的 goroutine 阻塞等待。
这种对通道进行发送和接收的交互行为本身就是同步的。其中任意一个操作都无法离开另一个操作单独存在。
阻塞:由于某种原因数据没有到达,当前协程(线程)持续处于等待状态,直到条件满足,才接触阻塞。
同步:在两个或多个协程(线程)间,保持数据内容一致性的机制。
下图展示两个 goroutine 如何利用无缓冲的通道来共享一个值:
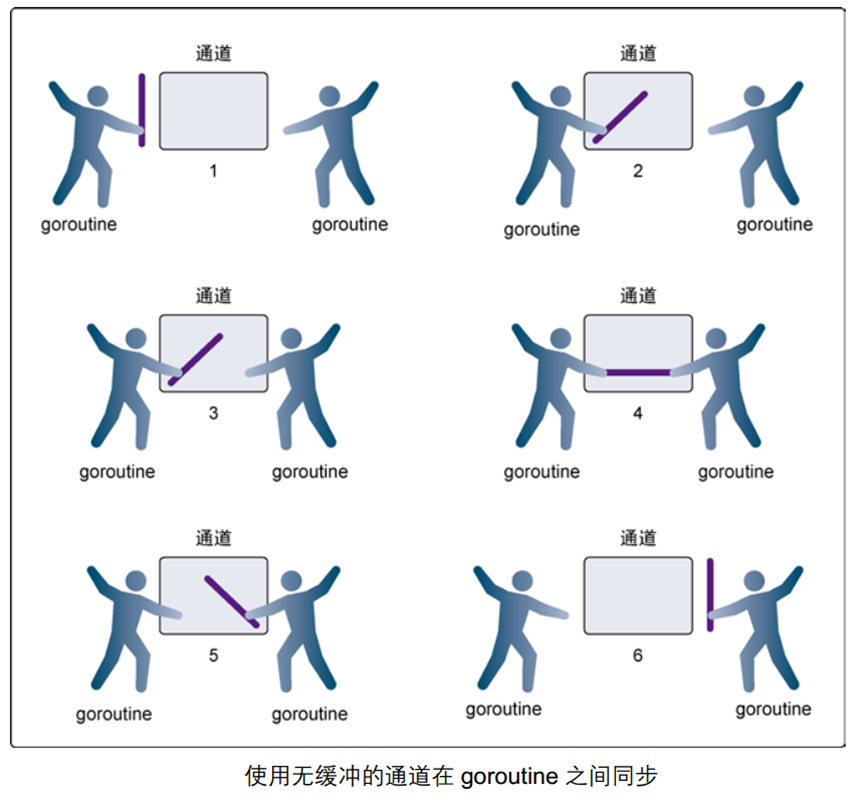
简单说明:在第 1 步,两个 goroutine 都到达通道,但哪个都没有开始执行发送或者接收。
在第 2 步,左侧的 goroutine 将它的手伸进了通道,这模拟了向通道发送数据的行为。这时,这个 goroutine 会在通道中被锁住,直到交换完成。
在第 3 步,右侧的 goroutine 将它的手放入通道,这模拟了从通道里接收数据。这个 goroutine 一样也会在通道中被锁住,直到交换完成。
在第 4 步和第 5 步,进行交换,并最终,在第 6 步,两个 goroutine 都将它们的手从通道里拿出来,这模拟了被锁住的 goroutine 得到释放。两个 goroutine 现在都可以去做别的事情了。
无缓冲的 channel 创建格式:make(chan Type) // 等价于 make(chan Type, 0)
如果没有指定缓冲区容量,那么该通道就是同步的,因此会阻塞到发送者准备好发送和接收者准备好接收。
例如:package main
import (
"fmt"
"time"
)
func main() {
// 创建无缓冲的 channel
ch := make(chan int, 0)
go func() {
defer fmt.Println("子 go 程结束")
for i := 0; i < 3; i++ {
fmt.Println("子 go 程正在运行, i = ", i)
ch
}
}()
time.Sleep(time.Second) // 延时一秒
for i := 0; i < 3; i++ {
// 从 ch 中接收数据, 并赋值给 num
num :=
fmt.Println("num = ", num)
}
fmt.Println("main go程结束")
}
运行结果:子 go 程正在运行, i = 0
num = 0
子 go 程正在运行, i = 1
子 go 程正在运行, i = 2
num = 1
num = 2
main go程结束
强调一下:
无缓冲 channel 的容量为0。
channel 至少应用于两个 go 程中:一个读、另一个写。
具备同步能力。读、写同步。(比如 打电话)
有缓冲的channel - 异步通信
有缓冲的通道(buffered channel)是一种在被接收前能存储一个或者多个数据值的通道。
这种类型的通道并不强制要求 goroutine 之间必须同时完成发送和接收。通道会阻塞发送和接收动作的条件也不同。
只有通道中没有要接收的值时,接收动作才会阻塞。
只有通道没有可用缓冲区容纳被发送的值时,发送动作才会阻塞。
这导致有缓冲的通道和无缓冲的通道之间的一个很大的不同:无缓冲的通道保证进行发送和接收的 goroutine 会在同一时间进行数据交换;有缓冲的通道没有这种保证。
使用有缓冲channel在goroutine之间同步的示例图:
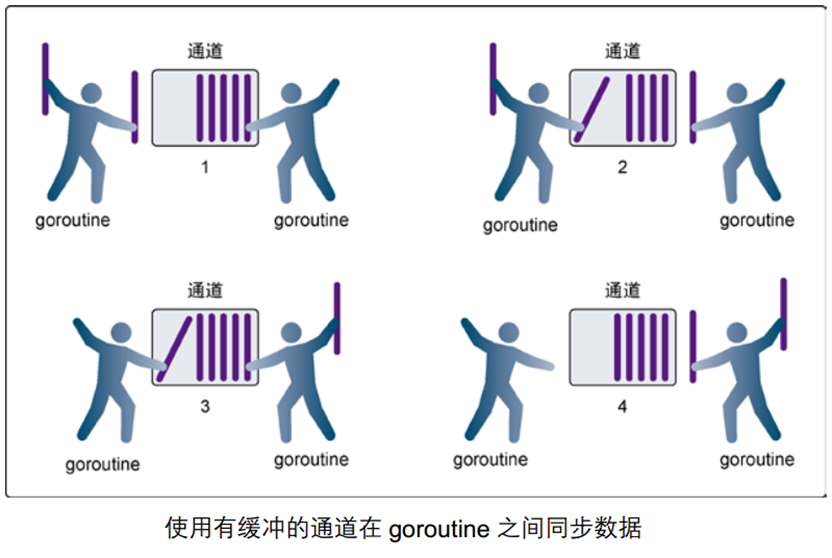 在第 1 步,右侧的 goroutine 正在从通道接收一个值。
在第 1 步,右侧的 goroutine 正在从通道接收一个值。
在第 2 步,右侧的这个 goroutine 独立完成了接收值的动作,而左侧的 goroutine 正在发送一个新值到通道里。
在第 3 步,左侧的 goroutine 还在向通道发送新值,而右侧的 goroutine 正在从通道接收另外一个值。这个步骤里的两个操作既不是同步的,也不会互相阻塞。
最后,在第 4 步,所有的发送和接收都完成,而通道里还有几个值,也有一些空间可以存更多的值。
有缓冲的 channel 创建格式:make(chan Type, capacity)
如果给定了一个缓冲区容量,通道就是异步的。只要缓冲区有未使用空间用于发送数据,或还包含可以接收的数据,那么其通信就会无阻塞地进行。
请看以下代码:package main
import (
"fmt"
"time"
)
func main() {
// 创建一个有缓冲的 channel
ch := make(chan int, 3) // 存满 3 个元素之前不会阻塞
// 查看一下 channel 的未被读取的缓冲元素数量以及 channel 容量
fmt.Printf("len(ch) = %d, cap(ch) = %d\n", len(ch), cap(ch))
go func() {
defer fmt.Println("子 go 程结束")
for i := 0; i < 5; i++ {
ch
fmt.Println("子 go 程正在运行, i = ", i)
}
}()
time.Sleep(time.Second)
for i := 0; i < 5; i++ {
num :=
fmt.Println("num = ", num)
}
fmt.Println("main go 程结束")
}
运行结果:len(ch) = 0, cap(ch) = 3
子 go 程正在运行, i = 0
子 go 程正在运行, i = 1
子 go 程正在运行, i = 2
num = 0
num = 1
num = 2
num = 3
子 go 程正在运行, i = 3
子 go 程正在运行, i = 4
子 go 程结束
num = 4
main go 程结束
强调一下:
有缓冲 channel 的容量大于 0。
channel 应用于两个 go 程中:一个读、另一个写。
缓冲区可以进行数据存储,存储至容量上限才阻塞。
具备异步的能力,不需要同时操作 channel 缓冲区。(比如发短信)
关闭channel
如果发送者知道,没有更多的值需要发送到 channel 的话,那么让接收者也能及时知道没有多余的值可接收将是有用的,因为接收者可以停止不必要的接收等待。
这可以通过内置的 close 函数来关闭 channel 实现。当我们确定不再向对端发送、接收数据时,我们可以关闭 channel。(一般关闭发送端)
对端可以判断 channel 是否关闭:if num, ok :=
// 对端没有关闭,num 保存读到的数据
} else {
// 对端已经关闭,num 保存对应类型的零值
}
例如:package main
import "fmt"
func main() {
ch := make(chan int)
go func() {
for i := 0; i < 5; i++ {
ch
}
// 如果没有 close(ch), 那么当程序打印完 0 1 2 3 4 时, 会因为没有写端 channel 造成死锁
close(ch) // 写端,写完数据主动关闭 channel
}()
// 从 channel 中读取数据,但是不知道读多少次,我们可以判断当 channel 关闭时意味着读取数据完毕
for true {
// ok 为 true说明 channel 没有关闭, 为 false 说明 channel 已经关闭
if data, ok :=
fmt.Println("写端没有关闭,data = ", data)
} else {
fmt.Println("写端关闭,data = ", data)
break
}
}
fmt.Println("结束.")
}
运行结果:写端没有关闭,data = 0
写端没有关闭,data = 1
写端没有关闭,data = 2
写端没有关闭,data = 3
写端没有关闭,data = 4
写端关闭,data = 0
结束.
我们也可以用 for range 获取 channel 中的数据:package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan int, 5)
go func() {
for i := 0; i < 5; i++ {
ch
}
// 如果没有 close(ch), 那么当程序打印完 0 1 2 3 4 时, 会因为没有写端 channel 造成死锁
close(ch) // 写端,写完数据主动关闭 channel
fmt.Println("子 go 程结束")
}()
time.Sleep(time.Second)
// 使用 for range 循环读取 channel 的数据,注意这里前面只接收一个变量
for num := range ch {
fmt.Println(num)
}
fmt.Println("结束.")
}
运行结果:子 go 程结束
0
1
2
3
4
结束.
强调一下:channel 不像文件一样需要经常去关闭,只有当你确实没有任何发送数据了,或者你想显式的结束 range 循环之类的,才去关闭 channel。简单说就是数据没发送完,不应该关闭 channel
关闭 channel 后,无法向 channel 再发送数据(引发 panic 错误后导致接收立即返回零值)【panic: send on closed channel】
写端关闭 channel 后,可以继续从 channel 接收数据如果 channel 中无数据,则读到的为对应类型的零值(注意与无缓冲 channel 的区别)
如果 channel 中有数据,则先读该数据,读完数据后,继续读则读到的为对应类型的零值
对于 nil channel,无论收发都会被阻塞。
可以使用 for range 替代 ok 那种形式:for num := range ch{} // 注意形式,不是
单向 channel 及应用
默认情况下,通道 channel 是双向的,也就是,既可以往里面发送数据也可以同里面接收数据。
但是,我们经常见一个通道作为参数进行传递而只希望对方是单向使用的,要么只让它发送数据,要么只让它接收数据,这时候我们可以指定通道的方向。
单向 channel 变量的声明非常简单,如下:var ch1 chan int // ch1 是一个正常的 channel,是双向的
var ch2 chan
var ch3
可以将 channel 隐式转换为单向队列,只收或只发,不能将单向 channel 转换为双向 channel:ch := make(chan int, 3)
var sendCh chan
var recvCh
来看一下单向 channel 的简单示例(记住了,channel 是传引用):package main
import "fmt"
// 只写
func send(sendCh chan
sendCh
close(sendCh)
}
// 只读
func recv(recvCh
num :=
fmt.Println("num = ", num)
}
func main() {
ch := make(chan int)
go send(ch)
recv(ch)
}
运行结果:num = 777
生产者消费模型
生产者消费者模型分析
单向 channel 最典型的应用是: 生产者消费者模型.
所谓生产者消费者模型: 某个模块(函数等)负责产生数据, 这些数据由另一个模块来负责处理(此处的模块是广义的, 可以是类, 函数, 协程, 线程, 进程等). 产生数据的模块, 就形象地称为生产者; 而处理数据的模块, 就称为消费者.
单单抽象出生产者和消费者, 还够不上是生产者消费者模型. 该模式还需要有一个缓冲区处于生产者和消费者之间, 作为一个中介. 生产者把数据放入缓冲区, 而消费者从缓冲区取出数据. 如下图所示
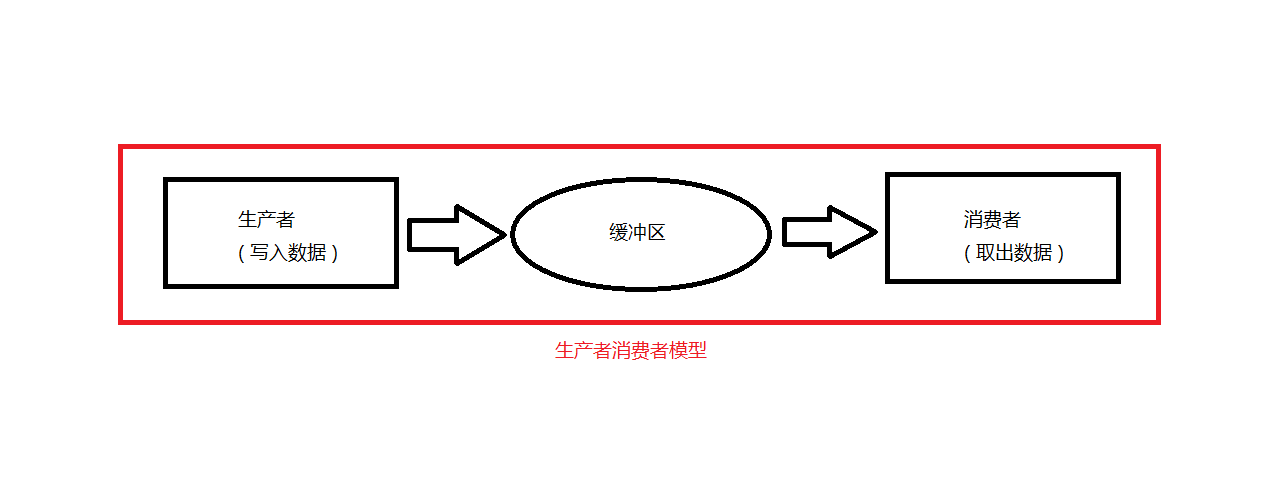
可以这样理解, 假设你要寄一封信, 大致过程如下:把信写好 -- 相当于生产者制造数据
把信放入邮筒 -- 相当于生产者把数据放入缓冲区
邮递员把信从邮筒取出 -- 相当于消费者把数据取出缓冲区
邮递员把信拿去邮局做相应的处理 -- 相当于消费者处理数据
那么, 这个缓冲区有什么用呢? 为什么不让生产者直接调用消费者的某个函数, 直接把数据传递过去, 而去设置一个缓冲区呢?
缓冲区的好处大概如下:
1: 解耦 ( 降低 生产者 和 消费者 之间的耦合度 )
假设生产者和消费者分别是两个类. 如果让生产者直接调用消费者的某个方法, 那么生产者对于消费者就会产生依赖(也就是耦合). 将来如果消费者的代码发生变化, 可能会直接影响到生产者. 而如果两者都依赖某个缓冲区, 两者之间不直接依赖, 耦合度也就相应降低了.
依然用寄信的例子简单说一下, 假设生产者就是你, 你负责写信, 如果没有邮筒(即缓冲区), 你就需要直接把信给邮递员(消费者). 但是, 过了几个月, 邮递员换人了, 你想要寄信就必须再认识新的邮递员, 你刚和新的邮递员熟悉之后, 又换了一个邮递员, 你又要重新认识... 这就显得很麻烦, 就是想寄个信而已, 不想认识那么多邮递员...
但是如果有邮筒(缓冲区)呢, 无论邮递员怎么更换, 这个与你无关, 我依然是把信放入邮筒就可以了. 这样一来, 就简单多了.
2: 提高并发能力 ( 生产者与消费者数量不对等时, 能保持正常通信 )
生产者直接调用消费者的某个方法, 还有另一个弊端
由于函数调用是同步的(或者叫阻塞的), 在消费者的方法没有返回之前, 生产者只好一直等在那边. 万一消费者处理数据很慢, 生产者只能白白浪费时间.
使用了生产者/消费者模式之后, 生产者和消费者可以是两个独立的并发主体.
生产者把制造出来的数据放入缓冲区, 就可以再去生产下一个数据. 基本上不用依赖消费者的处理速度.
其实最初这个生产者消费者模式, 主要就是用来处理并发问题的.
从寄信的例子来看, 如果没有邮筒, 你得拿着信傻站在路口等邮递员过来收(相当于生产者阻塞); 又或者邮递员得挨家挨户问, 谁要寄信(相当于消费者轮询).
3: 缓存 ( 生产者与消费者数据处理速度不一致时, 暂存数据 )
如果生产者制造数据的速度时快时慢, 缓冲区的好处就体现出来了.
当数据制造快的时候, 消费者来不及处理, 未处理的数据可以暂时存在缓冲区中. 等生产者的制造速度慢下来, 消费者再慢慢处理掉.
再拿寄信的例子举例, 假设邮递员一次只能带走1000封信. 万一某次碰上情人节送贺卡, 需要寄出的信超过1000封, 这时候邮筒这个缓冲区就派上用场了. 邮递员把来不及带走的信暂存在邮筒中, 等下次过来时再拿走.
生产者消费者模型实现
先来看一下无缓冲的例子package main
import "fmt"
// 生产者
func producer(ch chan
for i := 0; i < 5; i++ {
fmt.Println("生产者写入数据, num = ", i)
ch
}
close(ch)
}
// 消费者
func consumer(ch
for num := range ch {
fmt.Println("消费者拿到数据, num = ", num)
}
}
func main() {
// 无缓冲 channel
ch := make(chan int)
go producer(ch) // 子 go 程,生产者
consumer(ch) // 主 go 程,消费者
}
运行结果:生产者写入数据, num = 0
生产者写入数据, num = 1
消费者拿到数据, num = 0
消费者拿到数据, num = 1
生产者写入数据, num = 2
生产者写入数据, num = 3
消费者拿到数据, num = 2
消费者拿到数据, num = 3
生产者写入数据, num = 4
消费者拿到数据, num = 4
再来看一下有缓冲的例子 两者对比结果package main
import "fmt"
// 生产者
func producer(ch chan
for i := 0; i < 5; i++ {
fmt.Println("生产者写入数据, num = ", i)
ch
}
close(ch)
}
// 消费者
func consumer(ch
for num := range ch {
fmt.Println("消费者拿到数据, num = ", num)
}
}
func main() {
// 有缓冲 channel
ch := make(chan int, 2)
go producer(ch) // 子 go 程,生产者
consumer(ch) // 主 go 程,消费者
}
运行结果:生产者写入数据, num = 0
生产者写入数据, num = 1
生产者写入数据, num = 2
生产者写入数据, num = 3
消费者拿到数据, num = 0
消费者拿到数据, num = 1
消费者拿到数据, num = 2
消费者拿到数据, num = 3
生产者写入数据, num = 4
消费者拿到数据, num = 4
简单说明
首先创建一个双向的 channel, 然后开启一个新的 goroutine, 把双向通道作为参数传递到 producer 方法中, 同时转成只写通道. 子 go 程开始执行循环, 向只写通道中添加数据, 这就是生产者.
主 go 程直接调用 consumer 方法, 该方法将双向通道转成只读通道, 通过循环每次从通道中读取数据, 这就是消费者.
注意, channel 作为参数传递, 是引用传递.
生产者消费者 - 模拟订单
在实际的开发中, 生产者消费者模式应用也非常的广泛.
例如, 在电商网站中, 订单处理, 就是非常典型的生产者消费者模式.
当很多用户单击下订单按钮后, 订单生产的数据全部放到缓冲区(队列)中, 然后消费者将队列中的数据取出来发送至仓库管理等系统.
通过生产者消费者模式, 将订单系统与仓库管理系统隔离开, 且用户可以随时下单(生产数据). 如果订单系统直接调用仓库系统, 那么用户单击下订单按钮后, 要等到仓库系统的结果返回, 这样速度很慢.
接下来我们就来模拟一下订单处理的过程.package main
import "fmt"
type OrderInfo struct {
id int
}
func producer2(out chan
for i:=0; i < 10; i++ { // 循环生成10个订单
order := OrderInfo{id: i+1}
fmt.Println("生成的订单ID: ", order.id)
out
}
close(out) // 写完, 关闭channel
}
func consumer2(in
for order := range in { // 从channel取出订单
fmt.Println("订单ID为: ", order.id) // 模拟处理订单
}
}
func main() {
ch := make(chan OrderInfo, 5)
go producer2(ch)
consumer2(ch)
}
简单说明: OrderInfo 为订单信息, 这里为了简单只定义了一个订单编号属性, 然后生产者模拟生成10个订单, 消费者对产生的订单进行处理.
定时器
time.Timer
Timer 是一个定时器. 代表未来的一个单一事件, 你可以告诉 Timer 你要等待多长时间.type Timer struct {
C
r runtimeTimer
}
它提供一个channel, 在定时时间到达之前, 没有数据写入 Timer.C 会一直阻塞. 直到定时时间到, 系统会自动向 Timer.C 这个channel中写入当前时间, 阻塞即被解除.
定时器的启动
示例代码:package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("当前时间: ", time.Now())
// 创建定时器, 指定定时时长
myTimer := time.NewTimer(time.Second * 2)
// 定时到达后, 系统会自动向定时器的成员 C 写入系统当前系统时间
//读取 myTimer.C 得到定时后的系统时间, 并完成一次chan的读操作.
nowTime :=
fmt.Println("当前时间: ", nowTime)
}
3 种定时方法1. Sleep
time.Sleep(time.Second)
2. Time.C
fmt.Println("当前时间: ", time.Now())
myTimer := time.NewTimer(time.Second * 2)
nowTime :=
fmt.Println("现在时间: ", nowTime)
3. time.After
fmt.Println("当前时间: ", time.Now())
nowTime :=
fmt.Println("现在时间: ", nowTime)
定时器的停止package main
import (
"fmt"
"time"
)
func main(){
myTimer := time.NewTimer(time.Second * 3) // 创建定时器
go func() {
fmt.Println("子go程, 定时完毕")
}()
myTimer.Stop() // 设置定时器停止
for {
;
}
}
死循环只是为了方便查看结果.
定时器的重置package main
import (
"fmt"
"time"
)
func main() {
myTimer := time.NewTimer(time.Second * 10)
myTimer.Reset(time.Second * 2) // 重置定时时长为 2 秒
go func(){
fmt.Println("子go程, 定时完毕")
}()
for {
;
}
}创建定时器: myTimer := time.NewTimer(time.Second * 2)
停止定时器: myTimer.Stop() [此时
重置定时器: myTimer.Reset(time.Second * 2)
周期定时器 Time.Ticker
Ticker是一个周期触发定时的计时器, 它会按照一个时间间隔往channel发送系统当前时间, 而channel的接受者可以以固定的时间间隔从channel中读取.type Ticker struct {
C
r runtimeTimer
}package main
import (
"fmt"
"time"
)
func main() {
myTicker := time.NewTicker(time.Second) // 定义一个周期定时器
go func() {
for {
nowTime :=
fmt.Println("现在时间: ", nowTime)
}
}()
// 死循环, 特地不让main goroutine结束
for {
;
}
}package main
import (
"fmt"
"time"
)
func main(){
quit := make(chan bool) // 创建一个判断是否终止的channel
myTicker := time.NewTicker(time.Second) // 定义一个周期定时器
go func() {
i := 0
for {
nowTime :=
i++
fmt.Println("现在时间: ", nowTime)
if i == 5 {
quit
}
}
}()
}
李培冠博客
欢迎访问我的个人网站:















 2744
2744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









