






各位好,相信你已经看了前面我写的京东和苏宁图书的爬虫了,那么既然爬图书,我就把时下热门的图书网站都爬完!今天来给大家讲解一下当当图书的爬虫写法,实际操作和前面的基本都差不多,主要是要会抓包,分析想要的东西在哪里,怎么找到等,接下就进入正题吧!
第一步:网站分析
首先,我们用Chrome浏览器打开当当图书网主页:http://book.dangdang.com/,我们发现当当图书和上一次爬取的京东图书不一样,分了三层,例如:教育->教材->研究生/本科/专科教材这样的三层,那我们就一层一层的写下去就好了,也就是多个for循环的事,如下图:
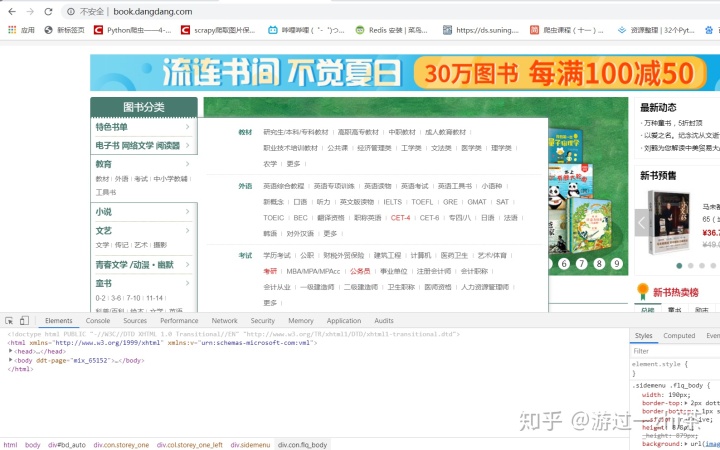
接下来开始抓包,我们就从图书分类的教育这里入手吧,我们按照:教育->教材->研究生/本科/专科教材 这三部一步一步进行抓包。使用选择工具点到大标题教育,在Elements中出现如下图:
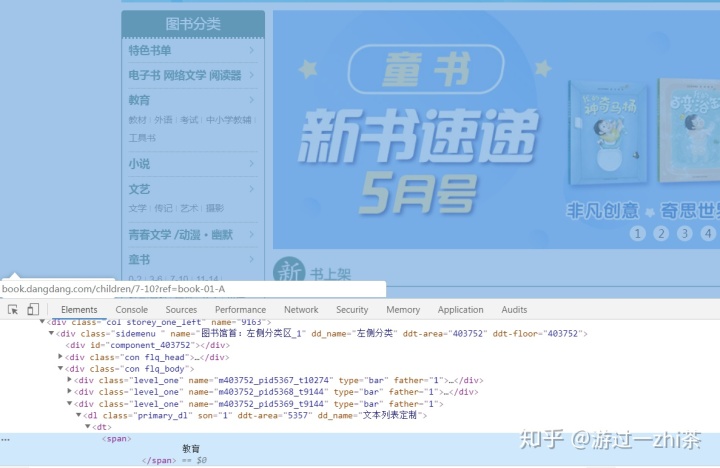
我们将鼠标移动到标签<div class="con flq_body">,发现菜单栏全部变蓝,说明我们要找的信息都在这个标签下面:
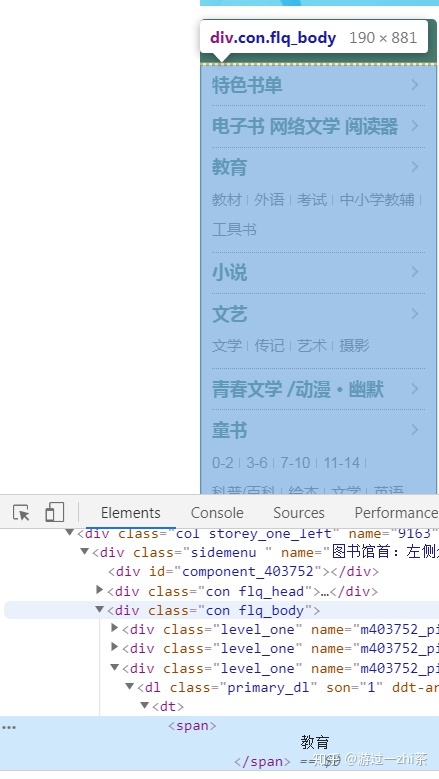
也就是在Elements中,教育类是在标签<div class="con flq_body">下的<div>标签下<dl>标签下的<dt>标签下的<span>里面,而所有的分类在<div class="con flq_body">下的<div class="level_one">标签里面,如下图:
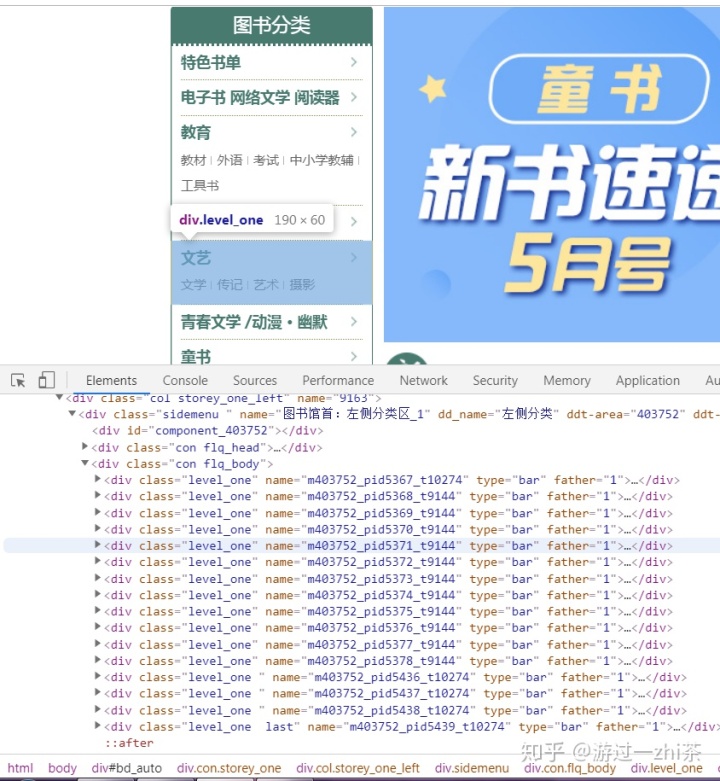
在上面我们找到了Elements中大分类:教育 的位置,接下来,我们得验证在网页的响应中也有这样的信息才行,因此我们点击Network,刷新一下网页,然后点击左下角的http://book.dangdang.com这个网站,最终出现如下图:
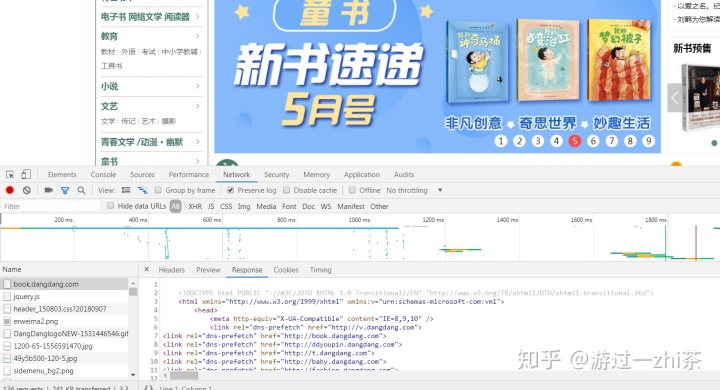
然后Ctrl+f 出现搜索框,我们搜索一下con flq_body这个标签,如下图,我们发现不好看对应信息:
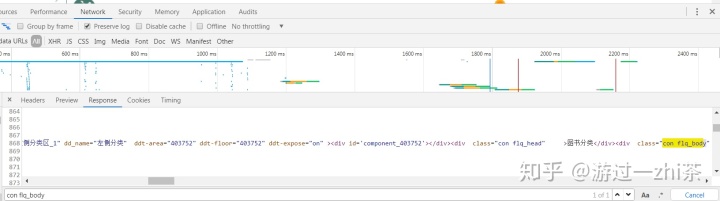
这个时候我们就在网页上点击反键,然后查看网页源代码,然后继续Ctrl+f 出现搜索框,我们搜索一下con flq_body这个标签,这样就比较容易对比了:

因为我们选择走教育->教材->研究生/本科/专科教材这条路线,所以我们朝下拉一下,找到教育的分类,然后经过与Elements对比,发现对应的标签都一样,这样我们就可以按照Element写代码了。
这样大分类找出来了,接下来找:教育->教材->研究生/本科/专科教材这条路线中的中分类:教材。我们用选择工具选中教材,发现在Elements,中它在<div class="con flq_body">下的<div>标签下<dl>标签下的<dd>标签下的<a>标签里面,同样的对照Networks,我们发现标签也是一样的,这样我们就找到了中分类了,如下图:
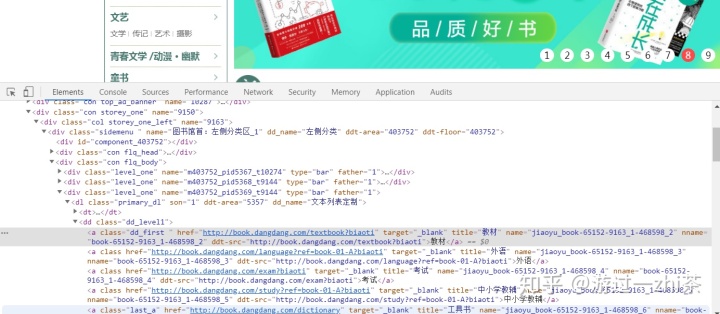
现在我们需要找教育->教材->研究生/本科/专科教材这条路线中的研究生/本科/专科教材这部分类容位置,我们经过在Elements中查找,发现它在如下图的位置,也是在<div class="con flq_body">的子标签里面,接着对比分析Network,内容也是一样的:
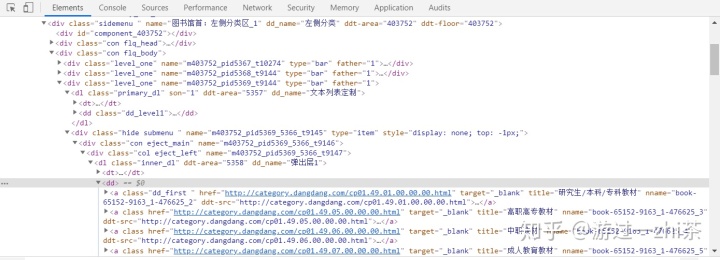
到这里我们首页就分析完了,我们提取数首页的大中小标题,以及小标题的href就行了,接下来就是请求小标题的href,比如请求:教材->研究生/本科/专科教材的href"http://category.dangdang.com/cp01.49.01.00.00.00.html"
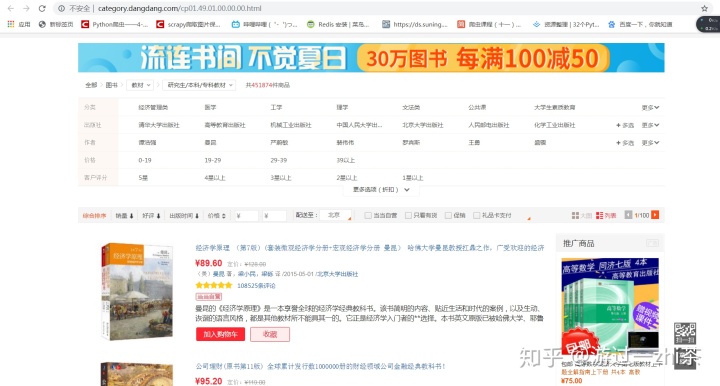
我们继续分析这个网页,先进行抓包,来找到我们想要提取的信息,比如图书名,内容简介,出版时间,出版社,作者,价格等等。用选择工具随便选一本图书,发现它们都是在<ul class='bigimg' id='component_59'>这个标签下的<li>标签里面

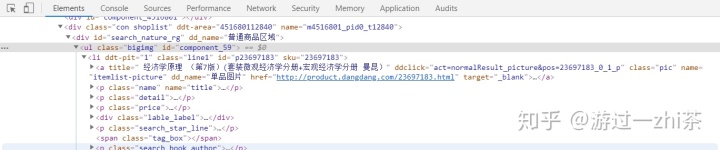
然后根据我们要爬取的信息,都在上面这个标签里面找到就行了,然后和Network进行对照,是否一样,很幸运的事,我们想找的内容在网页的响应中都有,包括价格,不需要构造额外的请求,这样减轻了我们的代码量。
这也我们把这一页的内容都找到了,只需要构造翻页请求就行了,我们把网页拉到最下面,寻找翻页的位置,用选择工具选中,下一页就在<ul name='Fy'>标签下:
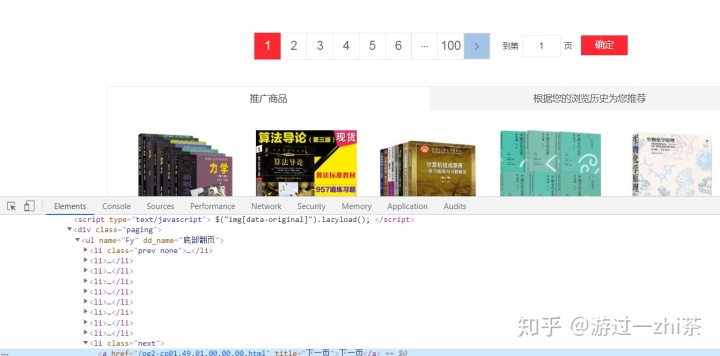
我们在Network中搜索下FY,如下图:
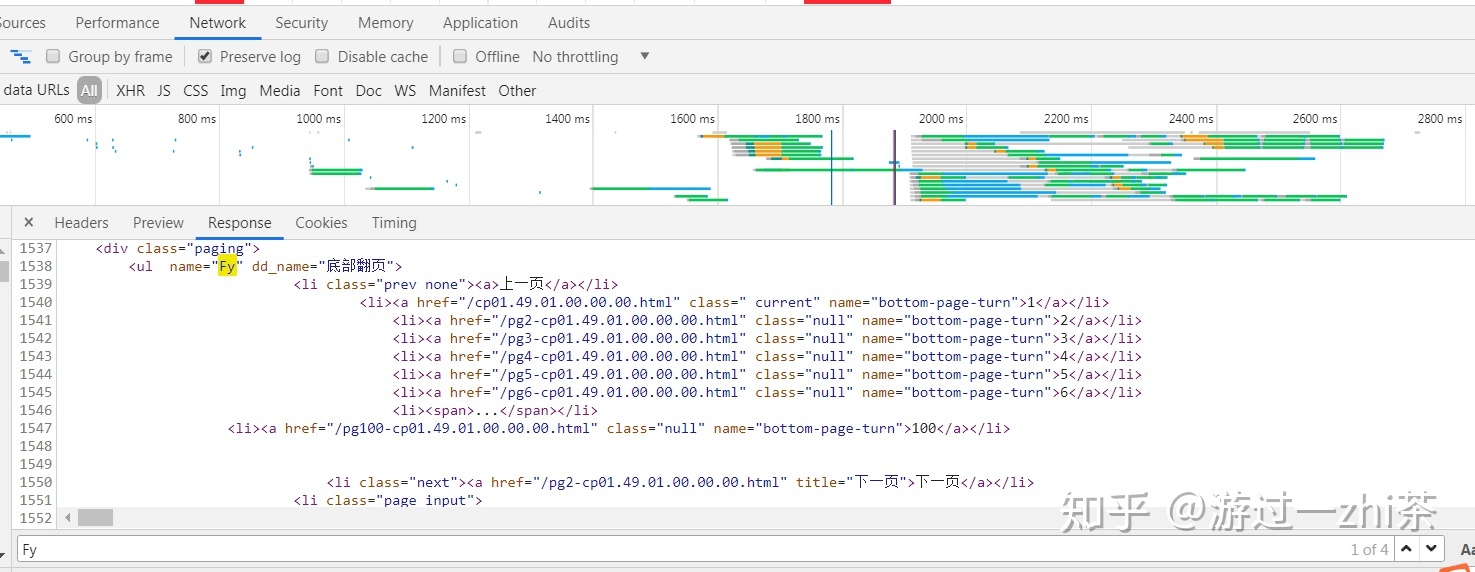
发现和Elements中一样的,直接可以找到下一页的href,到此我们的网页都分析完了,下面我分享一下我的代码
第二步:代码分享
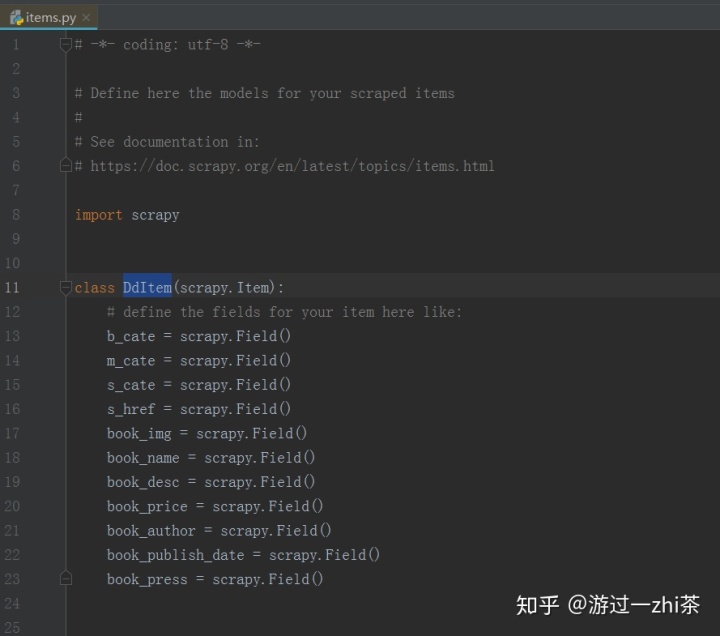
items.py代码:
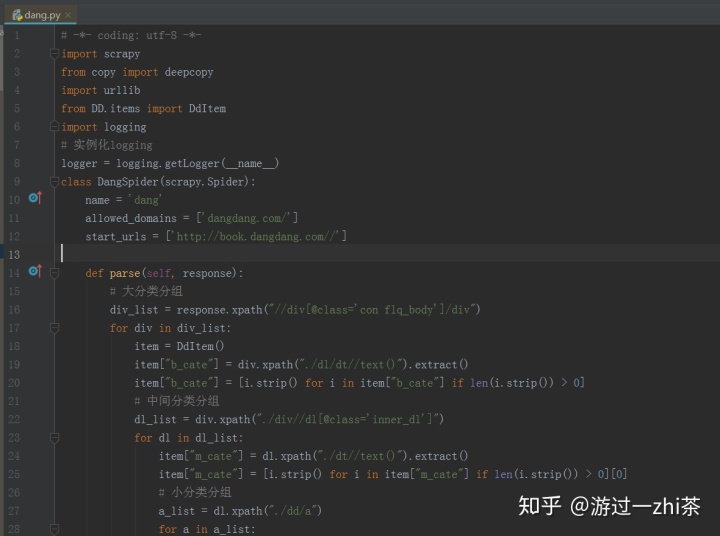
spider代码dang.py:
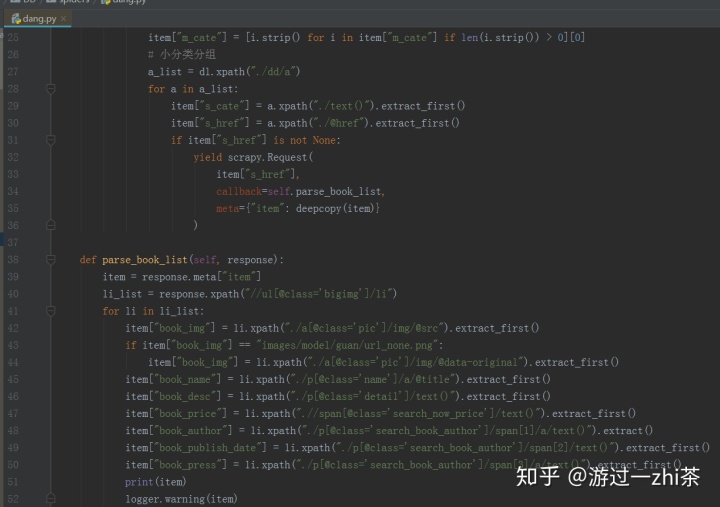
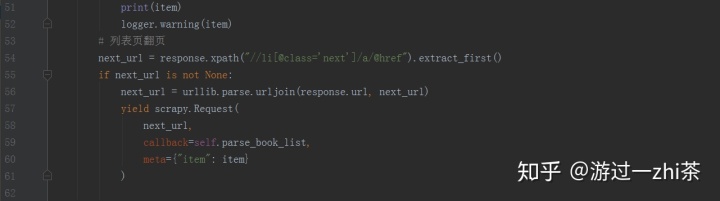
settings.py:
第三步:成果分享
40s爬取了4.6W条数据,大概3500本书左右
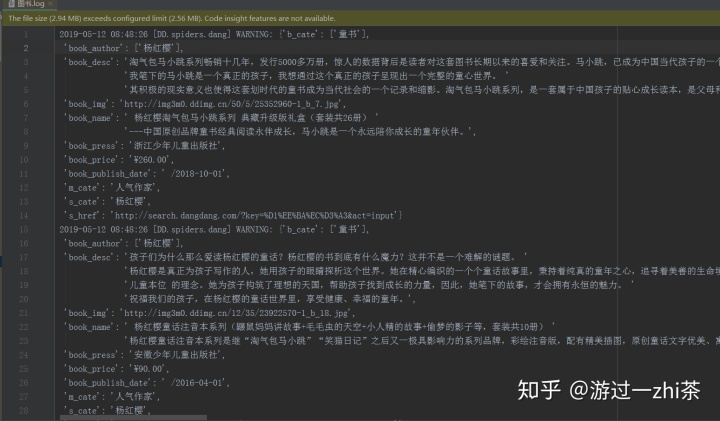

因为我要数据没什么用,所有就没存在数据库中,也没用其他的反爬措施,只是一些效果的展示,主要还是要学习分析网站的思路,对了,这个代码还可以改成scrapy-redis分布式爬虫,只需要添加几行代码就可以了。















 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









