






explain主要是用来获取一个query的运行计划,描写叙述mysql怎样运行查询操作、运行顺序,使用到的索引,以及mysql成功返回结果集须要运行的行数。能够帮助我们分析 select 语句,让我们知道查询效率低下的原因,从而改进我们的查询。让查询优化器能够更好的工作。
explain语法及描写叙述

从上面我们能够看到explain的语法是在select语句之前加上explain关键字即可了。
然后在运行explain之后会包括下面列信息:
id:标识符,表示运行顺序.
select_type:查询类型。
table:查询的表。
partitions:使用的哪个分区,须要结合表分区才干看到(since 5.7)
type:查询类型,比如index索引
possible_key:可能用到的索引,假设是多个索引以逗号隔开
key:实际用到的索引,保存的是索引的名称,假设是多个索引以逗号隔开
key_len:使用到索引的长度
ref:引用索引相应的表中哪些行
rows:显示mysql觉得运行查询时必须要返回的行数
filtered:通过过滤条件之后对照总数的百分比
Extra:额外的信息,using file sort,using where
1、ID
id表示select标识符,同一时候表明sql运行顺序,也就是说他是一个序列号.分为三种情况:
1.1 id同样 – 顺序运行

对于以上三表关联查询。我们能够看到id列的值同样。都是1.在这样的情况下,它们的运行顺序是按顺序运行,也是就是按列名从上往下运行。
1.2 id全不同 – 数字越大,越先运行

在这里我们能够看到在这个子查询中。ID全然不同。这对这样的情况,mysql的运行机制就是数字越大,越先运行。由于要先获取到子查询里的信息做为条件,然后才干查询外面的信息。
1.3 id部分同样 – 先大的运行,小的顺序运行

对于这样的id部分同样的情况。事实上就是前面2种情况的综合。
运行顺序是先依照数字大的先运行,然后数字同样的依照从上往下的顺序运行。
2、select_type – 查询类型
select_type包括下面几种类型:
simple:表示不须要union操作或者不包括子查询的简单select查询。有连接查询时,外层的查询为simple,且仅仅有一个
primary:一个须要union操作或者含有子查询的select,位于最外层的单位查询的select_type即为primary。且仅仅有一个
union:union连接的两个select查询,第一个查询是dervied派生表。除了第一个表外,第二个以后的表select_type都是union
dependent union:与union一样,出如今union 或union all语句中,可是这个查询要受到外部查询的影响
union result:包括union的结果集,在union和union all语句中,由于它不须要參与查询,所以id字段为null
subquery:除了from字句中包括的子查询外,其它地方出现的子查询都可能是subquery
dependent subquery:与dependent union相似。表示这个subquery的查询要受到外部表查询的影响
derived:from字句中出现的子查询,也叫做派生表,其它数据库中可能叫做内联视图或嵌套select
2.1 primary/subquery
explain select * from student s where s. classid = (select id from classes where classno='2017001');

2.2 union / union result
explain select * from student where id = 1 union select * from student where id = 2;

2.3 dependent union/dependent subquery
explain select * from student s where s.classid in (select id from classes where classno='2017001'
union select id from classes where classno='2017002');

2.4 derived
explain select * from (select * from student) s;
在mysql5.5、mysql5.6.x中:

可是在5.7中显示会不一样:

3、table
显示的查询表名。假设查询使用了别名,那么这里显示的是别名。假设不涉及对数据表的操作,那么这显示为null,假设显示为尖括号括起来的就表示这个是暂时表,后边的N就是运行计划中的id,表示结果来自于这个查询产生。假设是尖括号括起来的。与相似,也是一个暂时表。表示这个结果来自于union查询的id为M,N的结果集。
4、partitions – 分区
partitions这列是建立在你的表是分区表才行。
explain select * from test_partition where id > 7;

在5.7之前默认不显示分区信息须要手动指明。
explain partitions select * from emp;

5、type – 查询结果类型
表示依照某种类型来查询,比如依照索引类型查找,依照范围查找,主要是下面几种类型:
const:表示 表中最多有一个匹配行
eq_ref:对于每一个来自于前面的表的记录,从该表中读取唯一一行
ref:对于每一个来自于前面的表的记录,全部匹配的行从这张表中取出
ref_or_null:相似于ref,可是能够搜索包括null值的行
index_merge:出如今使用一张表中的多个索引时。mysql会讲这多个索引合并到一起
range:按指定的范围来检索,非经常见
index:从索取树中查找
ALL:全表扫描
从上面的分类描写叙述中我们能够看出来,查询效率是依据从上往下排列的。
5.1 const
使用唯一索引或者主键,返回记录一定是1行记录的等值where条件时,通常type是const。其它数据库也叫做唯一索引扫描
explain select * from student where id = 1;

5.2 eq_ref
对于每一个来自于前面的表的记录。从该表中读取唯一一行。
出如今要连接过个表的查询计划中。驱动表仅仅返回一行数据,且这行数据是第二个表的主键或者唯一索引,且必须为not null。唯一索引和主键是多列时,仅仅有全部的列都用作比較时才会出现eq_ref。
explain select * from student s, student ss where s.id = ss.id;

5.3 ref
对于每一个来自于前面的表的记录。全部匹配的行从这张表中取出
不像eq_ref那样要求连接顺序,也没有主键和唯一索引的要求,仅仅要使用相等条件检索时就可能出现,常见与辅助索引的等值查找。或者多列主键、唯一索引中,使用第一个列之外的列作为等值查找也会出现,总之,返回数据不唯一的等值查找就可能出现。
explain select * from student s, student_detail sd where s.id = sd.id;

5.4 ref_or_null
相似于ref,可是能够搜索包括null值的行。实际用的不多。
explain select * from student_detail where address = 'xxx' or address is null;

5.5 index_merge
出如今使用一张表中的多个索引时。mysql会讲这多个索引合并到一起.
表示查询使用了两个以上的索引,最后取交集或者并集。常见and 。or的条件使用了不同的索引。官方排序这个在ref_or_null之后。可是实际上由于要读取所个索引。性能可能大部分时间都不如range.

5.6 range
索引范围扫描,常见于使用>,

5.7 index
索引全表扫描,把索引从头到尾扫一遍,常见于使用索引列就能够处理不须要读取数据文件的查询、能够使用索引排序或者分组的查询。

5.8 ALL
这个就是全表扫描数据文件。然后再在server层进行过滤返回符合要求的记录。

6、possible_keys & key
possible_key:查询可能使用到的索引都会在这里列出来。
key:查询真正使用到的索引。select_type为index_merge时,这里可能出现两个以上的索引。其它的select_type这里仅仅会出现一个。
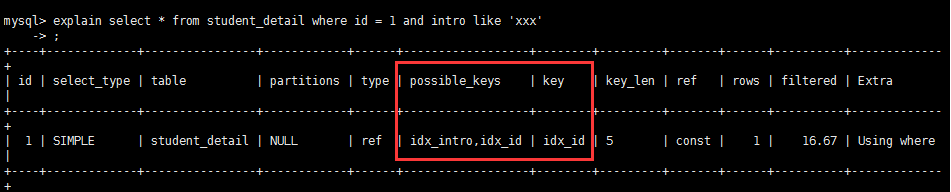
7、key_len
用于处理查询的索引长度,假设是单列索引。那就整个索引长度算进去。假设是多列索引,那么查询不一定都能使用到全部的列,具体使用到了多少个列的索引,这里就会计算进去,没有使用到的列。这里不会计算进去。
留意下这个列的值,算一下你的多列索引总长度就知道有没有使用到全部的列了。
要注意,mysql的ICP特性使用到的索引不会计入当中。另外,key_len仅仅计算where条件用到的索引长度。而排序和分组就算用到了索引,也不会计算到key_len中。
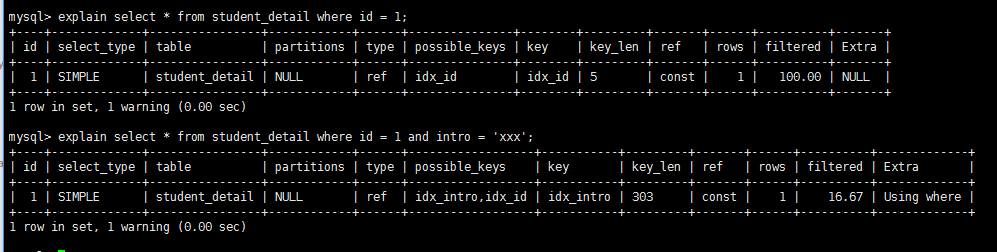
假设key字段值为null,则key_len字段值也为null,并且对于key_len越小越好,当然不能为null.
8、ref
假设是使用的常数等值查询,这里会显示const,假设是连接查询,被驱动表的运行计划这里会显示驱动表的关联字段,假设是条件使用了表达式或者函数,或者条件列发生了内部隐式转换,这里可能显示为func
9、rows
这里是运行计划中估算的扫描行数,不是精确值
10、filtered
使用explain extended时会出现这个列,5.7之后的版本号默认就有这个字段,不须要使用explain extended了。这个字段表示存储引擎返回的数据在server层过滤后。剩下多少满足查询的记录数量的比例。注意是百分比,不是具体记录数。

11、extra
这个列能够显示的信息非常多,有几十种。经常使用的有:
distinct:在select部分使用了distinc关键字
no tables used:不带from字句的查询或者From dual查询
使用not in()形式子查询或not exists运算符的连接查询,这样的叫做反连接。即,一般连接查询是先查询内表。再查询外表,反连接就是先查询外表,再查询内表。
using filesort:排序时无法使用到索引时,就会出现这个。
常见于order by和group by语句中
using index:查询时不须要回表查询。直接通过索引就能够获取查询的数据。
using join buffer(block nested loop),using join buffer(batched key accss):5.6.x之后的版本号优化关联查询的BNL。BKA特性。主要是降低内表的循环数量以及比較顺序地扫描查询。
using sort_union,using_union,using intersect,using sort_intersection:
using intersect:表示使用and的各个索引的条件时,该信息表示是从处理结果获取交集
using union:表示使用or连接各个使用索引的条件时,该信息表示从处理结果获取并集
using sort_union和using sort_intersection:与前面两个相应的相似。仅仅是他们是出如今用and和or查询信息量大时。先查询主键。然后进行排序合并后,才干读取记录并返回。
using temporary:表示使用了暂时表存储中间结果。暂时表能够是内存暂时表和磁盘暂时表,运行计划中看不出来,须要查看status变量,used_tmp_table,used_tmp_disk_table才干看出来。
using where:表示存储引擎返回的记录并非全部的都满足查询条件。须要在server层进行过滤。查询条件中分为限制条件和检查条件,5.6之前,存储引擎仅仅能依据限制条件扫描数据并返回,然后server层依据检查条件进行过滤再返回真正符合查询的数据。5.6.x之后支持ICP特性,能够把检查条件也下推到存储引擎层,不符合检查条件和限制条件的数据。直接不读取,这样就大大降低了存储引擎扫描的记录数量。
extra列显示using index condition
firstmatch(tb_name):5.6.x開始引入的优化子查询的新特性之中的一个,常见于where字句含有in()类型的子查询。假设内表的数据量比較大,就可能出现这个
loosescan(m..n):5.6.x之后引入的优化子查询的新特性之中的一个。在in()类型的子查询中,子查询返回的可能有反复记录时。就可能出现这个
除了这些之外,还有非常多查询数据字典库,运行计划过程中就发现不可能存在结果的一些提示信息。
12、总结
通过对上面explain中的每一个字段的具体解说。我们不难看出,对查询性能影响最大的几个列是:
select_type:查询类型
type:连接使用了何种类型
rows:查询数据须要查询的行
key:查询真正使用到的索引
extra:额外的信息
尽量让自己的SQL用上索引,避免让extra里面出现file sort(文件排序),using temporary(使用暂时表)。















 1475
1475

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









