







简介:本文介绍了在Qt环境下使用QTextToSpeech类实现文字转语音功能的方法。QTextToSpeech类提供了设置语言、速度、音调和音量等多种控制选项。通过示例代码展示了如何创建QTextToSpeech对象、选择语音引擎、设置语音参数和异步播放文本。为了提高开发的兼容性和用户体验,文章建议在不同操作系统和设备上进行测试,并使用系统提供的语音选项。最终,结合Qt的其他组件,开发者能够构建出丰富的多媒体应用程序。 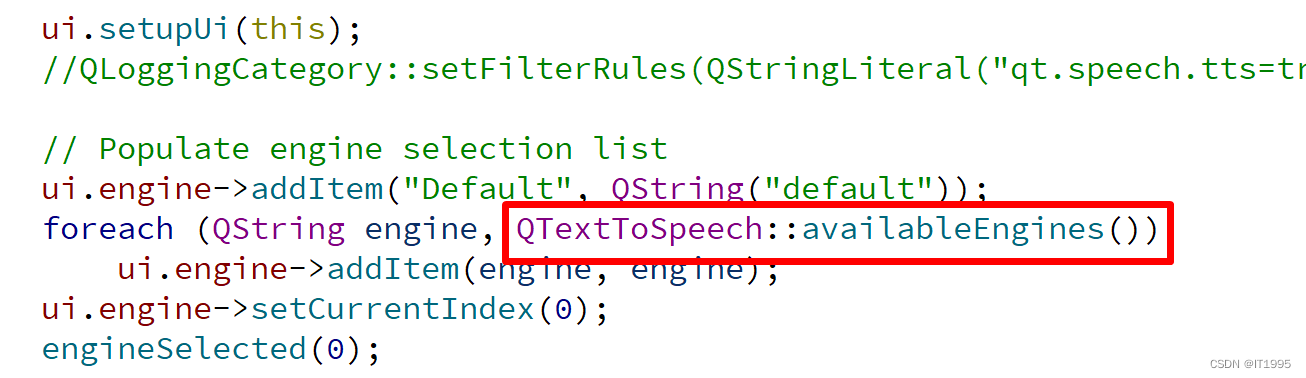
1. QTextToSpeech类的基本使用方法
简介
QTextToSpeech 是Qt框架中的一个类,允许开发者轻松地将文本信息转化为语音信息,使得应用程序能够发声。它提供了多个平台的后端支持,包括Linux、Windows以及macOS上的合成语音服务。
基本使用步骤
-
导入模块 :首先需要在你的Qt项目中导入Qt语音模块。
cpp #include <QTextToSpeech> -
创建QTextToSpeech对象 :在你的类的构造函数中实例化
QTextToSpeech对象。cpp QTextToSpeech *textToSpeech; textToSpeech = new QTextToSpeech(this); -
设置文本和语言 :使用
setLocale方法来设置目标语言,并使用say方法来开始语音合成。cpp textToSpeech->setLocale(QLocale::English); textToSpeech->say("Hello, world!"); -
处理信号与槽 :连接
QTextToSpeech的stateChanged信号到你的槽函数中,以监控状态变化,例如当文本开始被朗读。cpp connect(textToSpeech, &QTextToSpeech::stateChanged, this, &YourClass::onStateChanged);
这些步骤提供了实现基本文本到语音功能的基础框架。随着后续章节的深入,我们将探索更高级的功能,如语音引擎配置、音量控制和错误处理。
2. 设置文本、语音、语速、音量和音调
在本章中,我们将深入探讨如何在使用 QTextToSpeech 类时设置和调整文本、语音、语速、音量和音调,从而使得语音合成更加接近我们所期望的效果。我们将从设置文本和语言开始,讨论如何输入和输出文本,并解决文本的语言和字符集问题。随后,我们会研究如何选择合适的语音类型和语音库,以及如何调整语速、音量和音调。
2.1 文本的设置与处理
2.1.1 文本的输入和输出
QTextToSpeech 类允许用户设置要被转换为语音的文本。文本的输入可以通过多种方式实现,包括直接在代码中硬编码、从文件读取、通过网络请求获取等。输出则是通过语音合成后播放,用户可以通过电脑的扬声器或连接的耳机听到。
为了设置要发音的文本,我们可以使用 QTextToSpeech 类的 say 方法。下面的代码展示了如何设置文本并开始语音输出:
QTextToSpeech textToSpeech;
textToSpeech.say("Hello, world!");
2.1.2 文本的语言和字符集问题
文本的语言选择对于语音合成至关重要,因为它影响到语音的正确发音和语调。 QTextToSpeech 提供了 setLocale 方法来指定语言环境。例如,如果你想要文本使用美国英语发音,可以设置如下:
textToSpeech.setLocale(QLocale::English_USA);
同时,字符集问题也不容忽视。确保文本编码与应用程序中使用的编码一致是非常重要的,否则可能会出现乱码。在处理多语言文本时,应当明确文本编码为UTF-8或其它兼容的编码格式。
2.2 语音的设置与选择
2.2.1 语音类型的设置
QTextToSpeech 提供了多种语音类型供用户选择,包括但不限于默认语音、特定人物的语音等。用户可以通过 setVoice 方法来指定语音类型。
QVoice voice = textToSpeech.availableVoices().at(0);
textToSpeech.setVoice(voice);
2.2.2 语音库的选择与安装
在某些情况下,你可能需要安装额外的语音库来支持不同的语言或语音类型。 QTextToSpeech 可能不包含所有语言的语音数据,因此需要从第三方源获取。以Linux系统为例,可以使用包管理器安装特定的语音包。
sudo apt-get install espeak-ng
安装完毕后,在应用程序中就可以使用新安装的语音了。
2.3 语速、音量和音调的调整
2.3.1 语速的调整方法和影响
语速的调整可以通过 setRate 方法实现。 setRate 方法接受一个浮点数参数,其中1.0为默认语速,小于1.0会使语音播放变慢,大于1.0则会使播放变快。
textToSpeech.setRate(1.5); // 将语速设置为默认速度的1.5倍
调整语速会影响用户的听感和理解,需要根据实际情况选择合适的语速。
2.3.2 音量的调整方法和影响
音量的调整可以通过 setVolume 方法实现。 setVolume 方法接受一个从0.0到1.0的浮点数作为参数,其中1.0代表最大音量。
textToSpeech.setVolume(0.8); // 将音量设置为最大值的80%
音量的调整会直接影响用户的听感清晰度,音量过小会导致听不清楚,而过大会引起不适。
2.3.3 音调的调整方法和影响
音调的调整可以通过 setPitch 方法实现。 setPitch 接受一个浮点数作为参数,该参数调整语音的音调高低。1.0为默认音调,小于1.0会使声音变低,大于1.0会使声音变高。
textToSpeech.setPitch(1.2); // 将音调调整为默认音调的1.2倍
音调的调整对于改善用户体验非常重要,特别是在不同的语音和文本内容下。适当的音调调整可以使语音合成更加自然、悦耳。
在设置语音合成的各种参数时,需要综合考虑用户的听感体验,以及不同语言和文化对语音合成的影响。正确地设置和调整这些参数,可以使最终的语音输出更加接近自然人声,提高应用的可用性和吸引力。
3. 使用 setEngine() 和 setVoice() 方法配置语音引擎和语音类型
3.1 setEngine() 方法的使用
3.1.1 语音引擎的选择和配置
在使用 QTextToSpeech 类进行文本到语音转换时, setEngine() 方法允许开发者指定使用的语音合成引擎。语音引擎的不同可以导致合成语音的自然度、音质、速度等特性存在差异,因此选择合适的语音引擎对于应用的最终体验至关重要。
开发者可以根据平台的不同选择不同的语音引擎。例如,在Windows系统上,可以选择Microsoft提供的语音引擎,而在Linux系统上,可以选择eSpeak或Festival等开源语音引擎。此外,一些商业和专业级的引擎,如Google TTS或IBM Watson,也可能为特定的应用提供更为丰富的语音选项和定制化服务。
配置语音引擎通常涉及到以下几个步骤:
- 确定支持的引擎列表 :通过调用
availableEngines()方法获取系统上安装并支持的语音引擎列表。 - 选择合适的引擎 :基于应用需求和平台特性,从列表中选择最适合的语音引擎。
- 配置引擎参数 :一些引擎可能支持额外的配置参数,比如发音的性别、语言、语速等,开发者可以利用这些参数进一步优化语音输出。
3.1.2 setEngine() 方法的参数和返回值
setEngine() 方法的定义如下:
void QTextToSpeech::setEngine(const QString &name);
该方法接受一个 QString 类型的参数 name ,该参数指定了要使用的语音引擎的名称。返回值为无,该方法执行后立即应用所选的语音引擎。
参数说明: - name : 一个 QString 类型的值,指定了语音引擎的名称。该名称必须与 availableEngines() 返回的列表中的一个条目相匹配。
返回值: - 无返回值。
在实际的应用中,可以通过如下方式使用 setEngine() :
QTextToSpeech textToSpeech;
QStringList engines = textToSpeech.availableEngines();
if (engines.contains("com.apple.speech.synthesis JSONObject"))
{
textToSpeech.setEngine("com.apple.speech.synthesis JSONObject");
// 进行语音输出配置
}
else
{
// 处理引擎不可用的情况
// 例如可以尝试其他的引擎,或者通知用户需要安装额外的语音数据包
}
在上面的代码示例中,首先检查了可用的引擎列表,并尝试设置了一个特定的引擎名称。实际使用时,开发者应该根据用户的系统环境选择合适的引擎名称,并处理可能出现的错误,比如引擎不可用或配置失败的情况。
3.2 setVoice() 方法的使用
3.2.1 语音类型的设置和选择
setVoice() 方法允许开发者为 QTextToSpeech 对象设置特定的语音类型,从而改变文本到语音的输出音色。这在需要文本朗读支持不同语言或不同性别的场合中非常有用。
语音类型通常包括语言、地区、性别和声音特征等信息。例如,同一个英语引擎可能提供英式和美式两种发音,或者提供男性和女性的声音选项。选择合适的语音类型可以使得应用更加亲和和自然。
选择语音类型时,可以参照以下几个步骤:
- 列出支持的语音类型 :通过
availableVoices()方法获取当前语音引擎支持的所有语音类型。 - 评估应用需求 :根据应用的用户群体、内容类型等因素选择最合适的语音类型。
- 设置并测试语音 :使用
setVoice()方法设置所选的语音类型,并进行测试以确保其符合需求。
3.2.2 setVoice() 方法的参数和返回值
setVoice() 方法的定义如下:
void QTextToSpeech::setVoice(const QTextToSpeech::Voice &voice);
该方法接受一个 QTextToSpeech::Voice 类型的参数 voice ,该参数指定了要使用的语音类型。返回值为无,该方法执行后立即应用所选的语音类型。
参数说明: - voice : 一个 QTextToSpeech::Voice 类型的值,指定了语音类型的详细信息。 Voice 是一个结构体,包含了语音相关的属性,如语言、地区、性别等。
返回值: - 无返回值。
在实际的应用中,可以通过如下方式使用 setVoice() :
QTextToSpeech textToSpeech;
QList<QTextToSpeech::Voice> voices = textToSpeech.availableVoices();
for (const QTextToSpeech::Voice &voice : voices)
{
if (voice.language == "en-US")
{
textToSpeech.setVoice(voice);
// 进行语音输出配置
break;
}
}
在上面的代码示例中,首先获取了所有可用的语音类型,并遍历这些类型,寻找与"en-US"(美国英语)相匹配的语音类型。一旦找到,就使用 setVoice() 方法来设置应用所需的语音类型。实际开发时,应根据应用需求仔细选择和测试语音类型,以确保输出的语音质量能够达到预期的效果。
4. 信号 speechFinished() 和 error() 的使用
在进行文本到语音的转换过程中,信号处理是至关重要的部分。在Qt框架中,我们主要通过两个信号来处理语音播放的结束和错误情况: speechFinished() 和 error() 。在这一章节中,我们将深入探讨这两个信号的使用方法和理解。
4.1 speechFinished() 信号的使用和理解
4.1.1 speechFinished() 信号的意义和用途
speechFinished() 信号是一个反馈机制,用来通知开发者文本到语音(TTS)播放已经完成。该信号通常在文本被完全朗读后触发,是一个非常有用的机制来判断何时可以进行下一步操作,例如播放下一则消息,或者关闭语音服务。
信号是Qt中的一个核心概念,它允许对象之间进行通信,而无需知道对方的具体实现细节。在 QTextToSpeech 类中, speechFinished() 信号让我们可以在语音播放完毕后执行一些特定的逻辑,比如更新用户界面或执行其他任务。
4.1.2 如何正确处理 speechFinished() 信号
为了正确处理 speechFinished() 信号,我们需要将其连接到一个槽函数上。在Qt中,槽函数是能够响应信号并执行某些操作的函数。下面是一个简单的例子,展示了如何将 speechFinished() 信号连接到一个槽函数,并在该函数中执行一些操作。
#include <QTextToSpeech>
#include <QObject>
class MyTextToSpeechHandler : public QObject {
Q_OBJECT
public:
MyTextToSpeechHandler(QTextToSpeech *textToSpeech) {
connect(textToSpeech, &QTextToSpeech::speechFinished, this, &MyTextToSpeechHandler::onSpeechFinished);
}
private slots:
void onSpeechFinished() {
// 当语音播放完成时,将调用此槽函数
// 在这里编写处理语音播放完成后的逻辑
}
};
int main(int argc, char *argv[]) {
QCoreApplication a(argc, argv);
QTextToSpeech *textToSpeech = new QTextToSpeech();
MyTextToSpeechHandler handler(textToSpeech);
textToSpeech->say("Hello, world!");
return a.exec();
}
#include "main.moc"
在上述代码示例中,我们首先创建了一个 QTextToSpeech 对象。然后创建了一个 MyTextToSpeechHandler 对象,并将 QTextToSpeech 对象的 speechFinished() 信号连接到 MyTextToSpeechHandler 的 onSpeechFinished() 槽函数。当语音播放完毕时, onSpeechFinished() 槽函数会被自动调用,允许我们在这个函数内部实现后续的逻辑处理。
4.2 error() 信号的使用和理解
4.2.1 error() 信号的意义和用途
error() 信号用于处理在文本到语音转换过程中可能出现的错误。当遇到错误时,比如指定的语音引擎不可用、语音数据读取失败、或者语音服务端出现异常时, error() 信号将被发射。通过监听这个信号,我们可以在错误发生时及时作出响应并采取相应的处理措施。
错误处理是软件开发中的一个关键部分,特别是在涉及到外部服务和资源调用时。在Qt中, error() 信号为我们提供了一个清晰的方式,来处理TTS过程中的异常情况。
4.2.2 如何正确处理 error() 信号
为了处理 error() 信号,我们需要将其连接到一个合适的槽函数,以便在发生错误时可以执行自定义的错误处理逻辑。下面是一个处理 error() 信号的示例:
#include <QTextToSpeech>
#include <QObject>
class MyTextToSpeechErrorHandler : public QObject {
Q_OBJECT
public:
MyTextToSpeechErrorHandler(QTextToSpeech *textToSpeech) {
connect(textToSpeech, &QTextToSpeech::error, this, &MyTextToSpeechErrorHandler::onError);
}
private slots:
void onError(QTextToSpeech::Error error, const QString &errorString) {
// 当遇到错误时,将调用此槽函数
// error参数告诉我们错误的类型,errorString提供了错误描述
// 在这里编写处理错误的逻辑
qDebug() << "Error occurred:" << errorString;
}
};
int main(int argc, char *argv[]) {
QCoreApplication a(argc, argv);
QTextToSpeech *textToSpeech = new QTextToSpeech();
MyTextToSpeechErrorHandler errorHandler(textToSpeech);
textToSpeech->say("This text may cause an error if the engine is not set.");
return a.exec();
}
#include "main.moc"
在这个例子中,我们创建了一个槽函数 onError() ,用于处理 error() 信号。该函数有两个参数: error 和 errorString 。 error 参数是一个枚举值,描述了错误的类型,而 errorString 则提供了关于错误的详细描述。在 onError() 函数中,我们可以根据这些信息来确定错误的严重程度,并执行相应的处理,比如显示一个错误消息给用户,或者尝试其他的语音服务。
以上,我们通过实例讲解了如何在实际的代码中处理 speechFinished() 和 error() 这两个重要信号。正确使用这些信号可以极大提高应用程序的健壮性,提高用户满意度。
5. 处理多段文本和异步播放,兼容性测试和用户体验优化
在现代的IT应用开发中,处理多段文本和实现异步播放是提升用户体验的重要环节。此外,兼容性测试确保软件能够在不同的设备和操作系统上稳定运行,而用户体验优化则涉及诸多细节,旨在让应用更加友好和易用。
5.1 处理多段文本和异步播放
5.1.1 多段文本的处理方法
处理多段文本通常是为了支持更复杂的语音反馈和交互场景,例如在阅读器应用或语音助手功能中。为了实现这一功能,开发者需要确保文本数据被正确地组织和处理。
文本数据的组织方式
- 文本块存储:将每段文本存储为独立的字符串,使用数组或链表进行管理。
- 文本流:连续的文本数据可以通过流式处理,逐段输入到语音合成器中。
- 动态生成文本:根据用户输入或程序运行时的状态动态生成文本。
代码示例(使用伪代码表示)
// 初始化文本数据
textArray = ["第一段文本内容", "第二段文本内容", "第三段文本内容"]
// 逐段处理文本
for text in textArray:
qtSpeechInstance.say(text) // 假设 qtSpeechInstance 是 QTextToSpeech 的一个实例
wait until speechFinished // 等待当前文本播放完毕
// 动态文本生成示例
def generateText():
dynamicText = ""
for i in range(1, numSegments + 1):
dynamicText += "这是动态生成的第" + i + "段文本。\n"
return dynamicText
qtSpeechInstance.say(generateText())
5.1.2 异步播放的实现和优化
异步播放指的是在不阻塞主程序执行的情况下,完成语音的播放任务。在多线程环境中,异步播放显得尤为重要。
异步播放的实现
- 使用多线程:创建一个单独的线程负责语音播放,主线程继续执行其他任务。
- 使用回调函数:当语音播放完成时,触发一个回调函数,处理后续逻辑。
- 使用事件通知:通过事件机制,当语音播放完成后发送一个事件,由监听此事件的代码执行后续操作。
代码示例(使用Python的线程为例)
import threading
def play_text(text):
# 这里是播放文本的代码
pass
def play_async(text):
# 创建并启动线程
threading.Thread(target=play_text, args=(text,)).start()
# 使用异步播放
play_async("异步播放的文本内容")
5.2 兼容性测试和用户体验优化
5.2.1 兼容性测试的重要性
兼容性测试是指确保软件能在不同的硬件、操作系统、浏览器和设备上正常工作。这对于开发者来说至关重要,因为不通过兼容性测试的软件可能会失去大量的潜在用户。
兼容性测试的策略
- 跨平台测试:在Windows、macOS、Linux等多种操作系统上进行测试。
- 跨设备测试:针对不同品牌和型号的设备进行测试,如智能手机、平板、笔记本电脑等。
- 跨浏览器测试:如果应用需要支持Web端,应确保兼容主流浏览器。
测试工具和方法
- 虚拟机或容器:使用虚拟机或Docker容器进行环境隔离和测试。
- 自动化测试框架:如Selenium、Appium等,可以用于自动化测试流程。
- 云测试平台:使用Sauce Labs、BrowserStack等云测试服务可以覆盖更多的测试场景。
5.2.2 用户体验优化的方法和技巧
用户体验优化的目的是提升用户与产品的交互质量,增加用户满意度。以下是几种常用的方法和技巧:
用户体验优化的方法
- 界面设计:简洁、直观的界面设计能帮助用户快速上手。
- 性能优化:提高应用的响应速度和运行效率。
- 功能明确:确保每个功能都有明确的目的和指示。
- 文档和教程:提供清晰的用户手册或在线帮助文档。
优化技巧示例
- **即时反馈**:在用户操作后提供即时反馈,如加载提示或操作确认。
- **交互动画**:使用平滑的动画效果,增强用户操作的连贯性。
- **错误处理**:友好的错误提示和恢复建议,避免用户困惑。
- **用户调研**:定期进行用户调研,收集反馈以优化产品。
进行用户体验优化时,重要的是要站在用户的角度考虑问题,并不断迭代改进。通过收集和分析用户数据、反馈,可以不断发现潜在的改进点,并作出相应的优化措施。
简介:本文介绍了在Qt环境下使用QTextToSpeech类实现文字转语音功能的方法。QTextToSpeech类提供了设置语言、速度、音调和音量等多种控制选项。通过示例代码展示了如何创建QTextToSpeech对象、选择语音引擎、设置语音参数和异步播放文本。为了提高开发的兼容性和用户体验,文章建议在不同操作系统和设备上进行测试,并使用系统提供的语音选项。最终,结合Qt的其他组件,开发者能够构建出丰富的多媒体应用程序。

















 2129
2129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









