







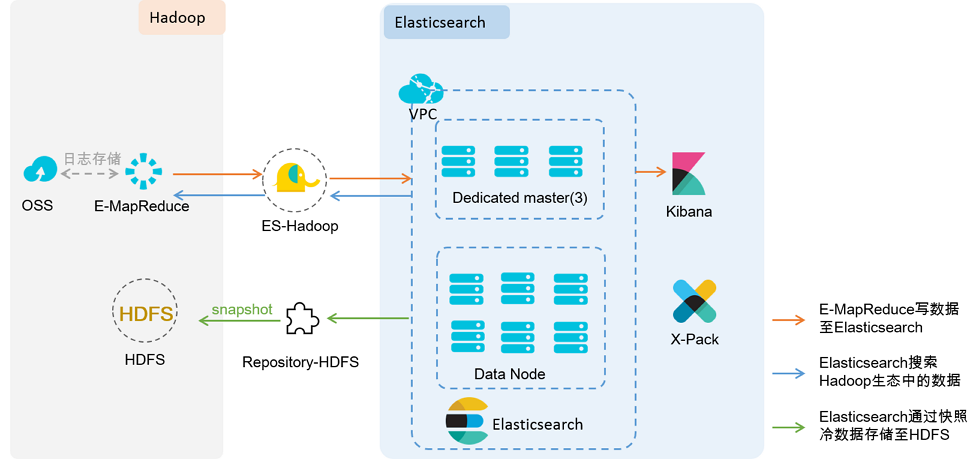
Elasticsearch简单介绍
Elasticsearch (ES)是一个基于Lucene构建的开源、分布式、RESTful 接口全文搜索引擎。Elasticsearch 还是一个分布式文档数据库,其中每个字段均是被索引的数据且可被搜索,它能够扩展至数以百计的服务器存储以及处理PB级的数据。它可以在很短的时间内在储、搜索和分析大量的数据。它通常作为具有复杂搜索场景情况下的核心发动机。
Elasticsearch就是为高可用和可扩展而生的。可以通过购置性能更强的服务器来完成
Elasticsearch优势
1.横向可扩展性:只需要增加台服务器,做一点儿配置,启动一下Elasticsearch就可以并入集群。
2.分片机制提供更好的分布性:同一个索引分成多个分片(sharding), 这点类似于HDFS的块机制;分而治之的方式可提升处理效率。
3.高可用:提供复制( replica) 机制,一个分片可以设置多个复制,使得某台服务器在宕机的情况下,集群仍旧可以照常运行,并会把服务器宕机丢失的数据信息复制恢复到其他可用节点上。
4.使用简单:共需一条命令就可以下载文件,然后很快就能搭建一一个站内搜索引擎。
Elasticsearch应用场景
大型分布式日志分析系统ELK elasticsearch(存储日志)+logstash(收集日志)+kibana(展示数据)
大型电商商品搜索系统、网盘搜索引擎等。什么是倒排索引
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
倒排索引案例分析
文档内容:
序号
文档内容
1
小俊是一家科技公司创始人,开的汽车是奥迪a8l,加速爽。
2
小薇是一家科技公司的前台,开的汽车是保时捷911
3
小红买了小薇的保时捷911,加速爽。
4
小明是一家科技公司开发主管,开的汽车是奥迪a6l,加速爽。
5
小军是一家科技公司开发,开的汽车是比亚迪速锐,加速有点慢
倒排索引会对以上文档内容进行关键词分词,可以使用关键次直接定位到文档内容。
单词ID
单词
倒排列表docId
1
小
1,2,3,4,5
2
一家
1,2,4,5
3
科技公司
1,2,4,5
4
开发
4,5
5
汽车
1,2,4,5
6
奥迪
1,4
7
加速爽
1,3,4
8
保时捷
2,3
9
保时捷911
2
10
比亚迪
5
基于mapreduce纯手写打造自己的倒排索引
需求:有大量的文本文档,如下所示:
a.txt
hello tom
hello jim
hello kitty
hello rose
b.txt
hello jerry
hello jim
hello kitty
hello jack
c.txt
hello jerry
hello java
hello c++
hello c++
需要得到以下结果:
hello a.txt-->4 b.txt-->4 c.txt-->4
java c.txt-->1
jerry b.txt-->1 c.txt-->1
....
思路:
1、先写一个mr程序:统计出每个单词在每个文件中的总次数
hello-a.txt 4
hello-b.txt 4
hello-c.txt 4
java-c.txt 1
jerry-b.txt 1
jerry-c.txt 1
要点1:map方法中,如何获取所处理的这一行数据所在的文件名?
worker在调用map方法时,会传入一个context,而context中包含了这个worker所读取的数据切片信息。而切片信息又包含这个切片所在的文件信息,那么就可以在map中:
FileSplit split=context.getInputSplit();
String fileName=split.getPath().getName();
要点二:setup方法
worker在正式处理数据之前,会先调用一次setup方法,所以,常利用这个机制来做一些初始化操作
2、然后在写一个mr程序,读取上述结果数据:
map: 根据-切,以单词做key,后面一段作为value
reduce: 拼接values里面的每一段,以单词做key,拼接结果做value,输出即可
代码实现
public class IndexStepOne {
public static class IndexStepOneMapper extends Mapper<LongWritable,Text,Text,IntWritable>{
/**
* 产生: <单词-文件名,1><单词-文件名,1>
*/
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
/**
* 如果map task读的是文件:划分范围是:《文件路径,偏移量范围》
* 如果map task读的是数据库的数据,划分的任务范围是:《库名.表名,行范围》
* 所以给抽象的getInputSplit
*/
//每个map task所处理的数据任务范围
FileSplit inputSplit = (FileSplit) context.getInputSplit();
String fileName = inputSplit.getPath().getName();
String[] words = value.toString().split(" ");
for(String w:words){
//单词-文件名 1
context.write(new Text(w+"-"+fileName),new IntWritable(1));
}
}
}
public static class IndexStepOneReduce extends Reducer<Text,IntWritable,Text,IntWritable>{
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count=0;
for(IntWritable value:values){
count+=value.get();
}
context.write(key,new IntWritable(count));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//动态获取jar包在哪里
job.setJarByClass(IndexStepOne.class);
//2.封装参数:本次job所要调用的mapper实现类
job.setMapperClass(IndexStepOneMapper.class);
job.setReducerClass(IndexStepOneReduce.class);
//3.封装参数:本次job的Mapper实现类产生的数据key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//4.封装参数:本次Reduce返回的key,value数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(3);
FileInputFormat.setInputPaths(job,new Path("F:\\mrdata\\index\\input"));
FileOutputFormat.setOutputPath(job,new Path("F:\\mrdata\\index\\out1"));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0:-1);
}
}
运行输出
part-r-000000 part-r-000001 part-r-0000002
hello-c.txt 4
jack-b.txt 1
java-c.txt 1
jerry-b.txt 1
kitty-a.txt 1
rose-a.txt 1
c++-c.txt 2
hello-a.txt 4
jerry-c.txt 1
jim-a.txt 1
kitty-b.txt 1
tom-a.txt 1
hello-b.txt 4
jim-b.txt 1
public class IndexStepOne2 {
public static class IndexStepOneMapper extends Mapper<LongWritable,Text,Text,Text>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] split = value.toString().split("-");
context.write(new Text(split[0]),
new Text(split[1].
replaceAll("\t","-->")));
}
}
public static class IndexStepOneReduce extends Reducer<Text,Text,Text,Text>{
//reduce阶段对相同的key进行处理,相同key发给同一个reduce task处理
@Override
protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
//StringBuffer是线程安全的,StringBuild是线程不安全的
//这里没有多线程并发,用StringBuild更快
StringBuilder sb = new StringBuilder();
/**
* <hello a.txt-->4> <hello b.txt-->4> <hello c.txt-->4>
* <java c.txt-->1>
* <jetty b.txt-->1><jetty c.tex-->1>
*/
/**
* hello a.txt-->4 b.txt-->4 c.txt-->4
* java c.txt-->1
* jerry b.txt-->1 c.txt-->1
*/
for(Text value:values){
sb.append(value.toString()).append("\t");
}
context.write(key,new Text(sb.toString()));
}
}
public static void main(String[] args) throws Exception{
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//动态获取jar包在哪里
job.setJarByClass(IndexStepOne2.class);
//2.封装参数:本次job所要调用的mapper实现类
job.setMapperClass(IndexStepOneMapper.class);
job.setReducerClass(IndexStepOneReduce.class);
//3.封装参数:本次job的Mapper实现类产生的数据key,value的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//4.封装参数:本次Reduce返回的key,value数据类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
//6.封装参数:想要启动的reduce task的数量
job.setNumReduceTasks(1);
FileInputFormat.setInputPaths(job,new Path("F:\\mrdata\\index\\out1"));
FileOutputFormat.setOutputPath(job,new Path("F:\\mrdata\\index\\out2"));
boolean res = job.waitForCompletion(true);
System.exit(res ? 0:-1);
}
}
运行输出
c++ c.txt-->2
hello a.txt-->4 b.txt-->4 c.txt-->4
jack b.txt-->1
java c.txt-->1
jerry b.txt-->1 c.txt-->1
jim a.txt-->1 b.txt-->1
kitty b.txt-->1 a.txt-->1
rose a.txt-->1
tom a.txt-->1
版权@须臾之余https://my.oschina.net/u/3995125















 884
884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









