






/一、java性能调优概述
Amdahl定律:加速比与系统并行度和处理器数量的关系。
Speedup≤\frac{1}{F+\frac{1-F}{N}}
设加速比为Speedup,系统内必须串行化的程序比重为F,CPU处理器数量为N
性能调优的层次:
1.设计调优
2.代码调优
3.JVM调优
4.数据库调优
5.操作系统调优
二、设计优化
1.善用设计模式
2.常用优化组件和方法
2.1缓冲buffer
2.2缓存cache
EHCache
2.3对象复用-池
2.4并行替代串行
2.5负载均衡
2.6时间换空间
2.7空间换时间
三、java程序优化
1.字符串优化处理
1.1 String对象及其特点
1.2 subString()方法的内存泄漏
1.3字符串分割和查找
1.4 StringBuffer 和 StringBuilder
2.核心数据结构
3.使用NIO提升性能
4.引用类型
5.有助于改善性能的技巧
1.慎用异常
2.使用局部变量
3.位运算代替乘除法
4.替换switch
5.一维数组代替二维数组
6.提取表达式
7.展开循环
8.布尔运算代替位运算
9.使用arrayCopy()
10.使用Buffer进行I/O操作
11.使用clone()代替new
12.静态方法替代实例方法
四、并行程序开发及优化
1.Executor框架
//Executors工厂类的主要方法:
public static ExecutorService newFixedThreadPool(int nThreads)
返回一个固定线程数量的线程池,该线程池中的线程数量始终不变。当有一个新的任务提交时,线程池中若有空闲线程,则立即执行。若没有,则新任务会被暂存在一个任务队列中,待有线程空闲时,便处理在任务队列中的任务。
public static ExecutorService newSingleThreadExecutor()
返回一个只有一个线程的线程池。若多余一个任务被提交到该线程池,任务会被保存在一个任务队列中,待线程空闲,按先入先出的顺序执行队列中的任务。
public static ExecutorService newCachedThreadPool()
返回一个可根据实际情况调整线程数量的线程池。线程池的线程数量不确定,但若有空闲线程可以复用,则会优先使用可复用的线程。若所有线程均在工作,又有新的任务提交,则会创建新的线程处理任务。所有线程在当前任务执行完毕后,将返回线程池进行复用。
public static ScheduledExecutorService newSingleThreadScheduledExecutor()
返回一个ScheduledExecutorService对象,线程池大小为1.ScheduledExecutorService接口在ExecutorService接口之上扩展了在给定时间执行某任务的功能,如在某个固定的延时之后执行,或者周期性执行某个任务
public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize)
返回一个ScheduledExecutorService对象,该线程池可以指定线程数量。
//都是对ThreadPoolExecutor的封装
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
//corePoolSize:指定了线程池中的线程数量
//maximumPoolSize:制定了线程池中的最大线程数量
//keepAliveTime:当线程池线程数量超过corePoolSize时,多余的空闲线程的存活时间。
//unit:keepAliveTime单位
//workQueue:任务队列,被提交但尚未被执行的任务
//threadFactory:线程工厂,用于创建线程,一般用默认的即可
//handler:拒绝策略
优化线程池大小:
最优的线程池的大小等于:
Ncpu:CPU的数量
Ucpu:目标CPU的使用率,0≤Ucpu≤1
W/C:等待时间与计算时间的比率
java中
Runtime.getRuntime().availableProcessors();
//获取CPU数量
2、JDK并发数据结构
并发List:Vector CopyOnWriteArrayList
并发Set : CopyOnWriteArraySet
并发Map: ConcurrentHashMap
并发Queue: ConcurrentLinkedQueue
并发Deque: LinkedBlockingDeque
3.并发控制方法
3.1 Java内存模型与volatile
一个线程可以执行的操作有使用(use)、赋值(assign)、装载(load)、存储(store)、锁定(lock)、解锁(unlock)。主内存可以执行的操作有读(read)、写(write)、锁定(lock)、解锁(unlock)
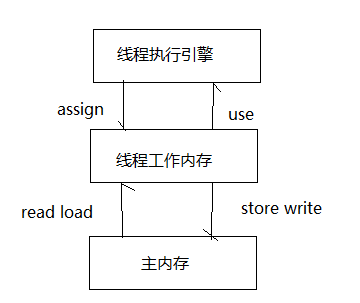
use:把一个变量在线程工作内存中的拷贝内容传送给线程执行引擎
assign:把一个值从线程执行引擎传送到变量的线程工作内存。
read:把一个变量的主内存拷贝的内容传输到线程的工作内存,以便load操作使用
load:把read操作从主内存中得到的值放入变量的线程工作内存中
store:把一个变量的线程工作内存拷贝内容传送到主内存中,以便write操作使用
write:把store操作从线程工作内存中得到的值放入主内存中变量拷贝中
主内存lock:使线程获得一个独占锁
主内存unlock:使线程释放一个独占锁
声明为volatile的变量可以做以下保证:
1.其他线程对变量的修改,可以即时反应在当前线程中
2.确保当前线程对volatile变量的修改,能即时写回共享主内存中,并被其他线程所见
3.使用volatile声明的变量,编译器会保证其有序性
3.2 synchronize同步关键字
3.3 ReentrantLock重入锁
重要的方法:
lock():获得锁,如果锁已经被占用,则等待
lockaInterruptibly():获得锁,但优先相应中断
tryLock():尝试获得锁,如果成功,返回true,失败返回false。该方法不等待,立即返回
tryLock(long time,TimeUnit unit):在给定时间内尝试获得锁
unlock():释放锁
3.4 ReadWriteLock读写锁
3.5 Condition对象
Condition接口提供的基本方法:
await():使当前线程等待,同时释放当前锁,当其他线程中使用signal()或者signalAll()方法时,线程会重新获得锁并继续执行。或者当线程被中断时,也能跳出等待。
awaitUninterruptibly():与await基本相同,但并不会在等待过程中响应中断
singal():唤醒一个在等待中的线程,相对的singalAll()方法会唤醒所有在等待中的线程
3.6 Semaphore信号量
//信号量准入数 是否公平
public Semaphore(int permits)
public Semaphore(int permits, boolean fair)
public void acquire()
//尝试获得一个准入的许可。若无法获得,则线程会等待,直到有线程释放一个许可或者当前线程被中断。
public void acquireUninterruptibly()
//与acquire相似,但不响应中断
public boolean tryAcquire()
//尝试获得一个许可,如果成功返回true,失败返回false,不会等待,立即返回
public boolean tryAcquire(long timeout, TimeUnit unit)
public void release()
//用于在线程访问资源结束后,释放一个许可,以使其他等待许可的线程可以进行资源访问
3.7 ThreadLocal线程局部变量
public void set(T value)
//将此线程局部变量的当前线程副本中的值设置为指定值
public T get()
//返回此线程局部变量的当前线程副本中的值
public void remove()
//移除此线程局部变量当前线程的值
4.“锁”的性能和优化
1.线程的开销
2.避免死锁
3.减小锁持有时间
4.减小锁粒度
5.读写分离锁来替换独占锁
6.锁分离
7.重入锁和内部锁
8.锁粗化(Lock Coarsening)
9.自旋锁
10.锁消除
11.锁偏向
5.无锁的并行计算
1.非阻塞的同步/无锁
2.原子操作
3.Amino框架介绍
6.协程
Kilim框架
五、JVM调优
1. java虚拟机内存模型
程序计数器、虚拟机栈、本地方法栈、java堆、方法区(JDK8前)
程序计数器、虚拟机栈、本地方法栈、java堆、元数据区
1.1 java虚拟机栈
请求的栈深度大于最大可用的栈深度,则抛出 StackOverflowError;
没有足够的内存空间来支持栈的扩展,则抛出 OutOfMemoryError。
在Hot Spot虚拟机中,可以使用-Xss参数来设置栈的大小。栈的大小直接决定函数调用的可达深度。
private int count=0;
public void recursion(){
count++;
recursion();
}
@Test
public void test1(){
try{
//调用递归,等待溢出
recursion();
}catch (Throwable e){
System.out.println("deep:"+count);
e.printStackTrace();
}
}
deep:6712
-Xss1M 扩大栈空间的最大值。函数调用深度上升
deep:39226
java.lang.StackOverflowError
1.2 java堆
堆空间简单分为新生代和老年代。新生代细分:eden、survivor space0(s0或者from space) survivor space1(s1或者 to space)
2.JVM内存分配参数
2.1设置最大堆内存
-Xmx 指的是新生代和老年代的大小之和的最大值
public static void main(String[] args) {
Vector v=new Vector();
for(int i=0;i<10;i++){
byte[] b=new byte[1024*1024];
v.add(b);
System.out.println(i+"M is allocated");
}
System.out.println("Max memory:"+Runtime.getRuntime().maxMemory()/1024/1024+"M");
}
2.2设置最小堆内存
-Xms
2.3设置新生代
-Xmn 一般设置为整个堆空间的1/4到1/3左右
在Hot Spot虚拟机中,-XX:NewSize 用于设置新生代的初始大小,-XX:MaxNewSize用于设置新生代的最大值。但通常情况下,只设置-Xmn可以满足绝大部分应用的需求。-Xmn的效果等同于设置了相同的-XX:NewSize和-XX:MaxNewSize.
若设置不同的-XX:NewSize 和-XX:MaxNewSize可能会导致内存震荡,从而产生不必要的系统开销
2.4设置持久代(java8已经没有了)
持久代(方法区)不属于堆的一部分。在Hot Spot虚拟机中,使用-XX:MaxPermSize可以设置持久代的最大值,使用-XX:PermSize可以设置持久代的初始大小。
2.5设置线程栈
-Xss -Xss1M,即设置每个线程拥有1MB的栈空间
2.6堆的比例分配
-XX:SurvivorRatio:用来设置新生代中,eden空间和s0空间的比例关系。s0和s1是相同的,职能也是一样的,并在Minor GC后,会互换角色。
-XX:NewRatio:用来设置新生代和老年代的比例
-XX:MinHeapFreeRatio:设置堆空间最小空闲比例。当堆空间的空闲内存小于这个数值时,JVM便会扩展堆空间
-XX:MaxHeapFreeRatio:设置堆空间最大空闲比例。当堆空间的空闲内存大于这个数值时,便会压缩堆空间,得到一个较小的堆。
-XX:TargetSurvivorRatio:设置survivior区的可使用率。当survivior区的空间使用率达到这个数值时,会将对象送入老年代。
3.垃圾收集基础
3.1垃圾回收算法
1.引用计数法(Reference Counting)
无法处理循环引用的问题,不适合用于JVM的垃圾回收。
2.标记-清除算法(Mark-Sweep)
先通过根节点标记所有可达对象,然后清除所有不可达对象,完成垃圾回收。
3.复制算法(Copying)(适用于新生代)
比较适用于新生代。因为垃圾对象通常多于存活对象,
在java的新生代串行垃圾回收器中,使用了复制算法的思想。新生代分为eden、from、to3个部分。其中from和to空间可以视为复制的两块大小相同、地位相等,且可进行角色互换的空间块。用于存放未被回收的对象。
在垃圾回收时,eden中存活对象会被复制到未使用的survivor中(假设是to),正在使用的survivor(假设是from)中年轻对象也会被复制到to空间中(大对象,或者老年对象会直接进入老年代,如果to空间已满,则对象也会直接进入老年代)。此时,eden和from中的剩余对象就是垃圾对象,可以直接清空,to空间则存放此次回收后的存活的对象。
4.标记-压缩算法(Mark-Compact)(适用于老年代)
首先从根节点开始,对所有可达对象做一次标记。清理未标记的对象,将所有存活的对象压缩到内存的一端。之后,清理边界外所有的空间。
5.增量算法(Incremental Collecting)
6.分代(Generational Collecting)
3.2垃圾收集器的类型
分类垃圾回收器类型
线程数
串行垃圾回收器
并行垃圾回收器
工作模式
并发垃圾回收器
独占垃圾回收器
碎片处理
压缩垃圾回收器
非压缩垃圾回收器
分代
新生代垃圾处理器
老年代垃圾处理器
3.3评价GC策略的指标
1.吞吐量:指在应用程序的生命周期内,应用程序所花费的时间和系统总运行时间的比值。系统总运行时间=应用程序耗时+GC耗时。
2.垃圾回收器负载:和吞吐量相反,垃圾回收器负载指垃圾回收器耗时与系统运行总时间的比值。
3.停顿时间:指垃圾回收器正在运行时,应用程序的暂停时间。对于独占回收器而言,停顿时间可能会比较长。使用并发的回收器时,由于垃圾回收和应用程序交替运行,程序的停顿时间会很短,但是,由于其效率很可能不如独占垃圾回收器,故系统的吞吐量可能会较低。
4.垃圾回收频率:指垃圾回收器多长时间会运行一次。一般来说,对于固定的应用而言,垃圾回收器的频率应该是越低越好。通常增大堆空间可以有效降低垃圾回收发生的频率,但是可能会增加回收产生的停顿时间
5.反应时间:指当一个对象称为垃圾后,多长时间内,它所占据的内存空间会被释放。
6.堆分配:不同的垃圾回收器对堆内存的分配方式可能是不同的。
3.4新生代串行收集器
两个特点:第一,仅仅使用单线程进行垃圾回收;第二,是独占式的垃圾回收。
在Hot Spot虚拟机中,使用-XX:+UseSerialGC参数可以指定新生代串行收集器和老年代串行收集器。当JVM在Client模式下运行时,它是默认的垃圾收集器。
3.5老年代串行收集器
标记-压缩算法。
启用老年代串行回收器,
-XX:+UseSerialGC:新生代、老年代都使用串行回收器
-XX:+UseParNewGC:新生代使用并行收集器,老年代使用串行收集器
-XX:+UseParallelGC:新生代使用并行回收收集器,老年代使用串行收集器
3.6并行收集器
-XX:+UseParNewGC:新生代使用并行收集器,老年代使用串行回收器
-XX:+UseConcMarkSweepGC:新生代使用并行收集器,老年代使用CMS
3.7新生代并行回收(Parallel Scavenge)收集器
-XX:+UseParallelGC:新生代使用并行回收收集器,老年代使用串行收集器
-XX:+UseParallelOldGC:新生代和老年代都使用并行回收处理器
1.-XX:MaxGCPauseMillis:设置最大垃圾收集停顿时间,它的值是一个大于0的整数。
2.-XX:GCTimeRatio:设置吞吐量大小,它的值是一个0~100之间的整数
3.8老年代并行回收收集器
-XX:+UseParallelOldGC
3.9 CMS收集器
CMS收集器主要关注于系统停顿时间。CMS是Concurrent Mark Sweep,意为并发标记清除
3.10 G1收集器(Garbage First)
与CMS收集器相比,G1收集器是基于标记-压缩算法的。
启用G1回收器:
-XX:+UnlockExperimentalVMOptions -XX:+UseG1GC
设置G1回收器的目标停顿时间:
-XX:MaxGCPauseMillis=50
-XX:GCPauseIntervalMillis=200
4.常用调优案例和方法
4.1将新对象预留在新生代
4.2大对象进入老年代
4.3设置对象进入老年代的年龄
4.4稳定与震荡的堆大小
4.5吞吐量优先案例
4.6使用大页案例
-XX:LargePageSizeInBytes:设置大页的大小
4.7降低停顿案例
5.实用JVM参数
1.JIT编译参数
2.堆快照
3.错误处理
4.取得GC信息
5.类和对象跟踪
6.控制GC
7.选择类校验器
8.Solaris下线程控制
9.使用大页
10.压缩指针
六、Java性能调优工具
1.Linux命令行工具
1.top命令
2.sar命令
3.vmstat命令
4.iostat命令
5.pidstat工具
2.JDK命令行工具
2.1jps命令
参数 -q 指定jps只输出进程ID,而不输出类的短名称
-m 用于输出传递给Java进程(主函数)的参数
-l 用于输出主函数的完整路径
-v 可以显示传递给JVM的参数
2.2jstat命令
jstat - [-t] [-h] [ []]
选项option可以由以下值构成:
-class:显示ClassLoader的相关信息
-compiler:显示JIT编译的相关信息
-GC:显示与GC相关的堆信息
-gccapacity:显示各个代的容量及使用情况
-gccause:显示垃圾收集相关信息(同-gcutil),同时显示最后一次或当前正在发生的垃圾收集的诱发原因
-gcnew:显示新生代信息
-gcnewcapacity:显示新生代大小与使用情况
-gcold:显示老年代和永久代的信息
-gcoldcapacity:显示老年代的大小
-gcpermcapacity:显示永久代的大小
-gcutil:显示垃圾收集信息
-printcompilation:输出JIT编译的方法信息
-t参数可以在输出信息前加上一个Timestamp列,显示程序的运行时间。
-h参数可以在周期性数据输出时,输出多少行数据后,跟着输出一个表头信息。
interval参数用于指定输出统计数据的周期,单位为毫秒
count用于指定一共输出多少次数据
C:\Users\Administrator>jstat -class -t 5804 1000 3
Timestamp Loaded Bytes Unloaded Bytes Time
5027.2 49553 101341.9 348 477.9 81.22
5028.2 49553 101341.9 348 477.9 81.22
5029.1 49553 101341.9 348 477.9 81.22
Loaded:载入了类的数量,Bytes:载入类的合计大小,Unloaded:卸载类的数量,第二个Bytes:卸载类的大小,Time:在加载和卸载类上所花的时间
C:\Users\Administrator>jstat -compiler -t 5804
Timestamp Compiled Failed Invalid Time FailedType FailedMethod
5219.5 29476 4 0 153.95 1 org/apache/xerces/im
pl/XMLNSDocumentScannerImpl scanStartElement
Compiled:编译任务执行的次数,Failed:编译失败的次数,Invalid:编译不可用的次数,Time:编译的总耗时,FailedType:最后一次编译失败的类型,FailedMethod:最后一次编译失败的类名和方法名
C:\Users\Administrator>jstat -gc 5804
S0C S1C S0U S1U EC EU OC OU MC MU
CCSC CCSU YGC YGCT FGC FGCT GCT
15872.0 15872.0 0.0 299.3 127360.0 112589.0 318040.0 132609.4 286800.0 2
68977.1 40824.0 36673.9 213 2.469 19 1.275 3.744
S0C:s0(from)的大小(KB)
S1C:s1(from)的大小(KB)
S0U:s0(from)已使用的空间(kb)
S1U:s1(from)已使用的空间(kb)
EC:eden区的大小
EU:eden区的使用空间(KB)
OC:老年代大小
OU:老年代已经使用空间
PC:永久区大小
PU:永久区使用空间
YGC:新生代GC次数
YGCT:新生代GC耗时
FGC:FullGC次数
FGCT:FullGC耗时
GCT:GC总耗时
C:\Users\Administrator>jstat -gccapacity 5804
NGCMN NGCMX NGC S0C S1C EC OGCMN OGCMX OGC
OC MCMN MCMX MC CCSMN CCSMX CCSC YGC FGC
43648.0 256000.0 159104.0 15872.0 15872.0 127360.0 87424.0 512000.0 3180
40.0 318040.0 0.0 1296384.0 286800.0 0.0 1048576.0 40824.0 216
19
NGCMN:新生代最小值(KB)
NGCMX:新生代最大值
NGC:当前新生代大小
OGCMN:老年代最小值
OGCMX:老年代最大值
PGCMN:永久代最小值
PGCMX:永久代最大值
C:\Users\Administrator>jstat -gccause 5804
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
LGCC GCC
0.00 2.54 42.82 41.70 93.79 89.83 217 2.502 19 1.275 3.77
7 Allocation Failure No GC
LGCC:上次GC的原因
GCC:当前GC的原因
C:\Users\Administrator>jstat -gcnew 5804
S0C S1C S0U S1U TT MTT DSS EC EU YGC YGCT
15872.0 15872.0 0.0 403.3 6 6 7936.0 127360.0 99925.4 217 2.502
TT:新生代对象晋升到老年代对象的年龄
MTT:新生代对象晋升到老年代对象的年龄最大值
DSS:所需的survior区大小
C:\Users\Administrator>jstat -gcnewcapacity 5804
NGCMN NGCMX NGC S0CMX S0C S1CMX S1C ECMX
EC YGC FGC
43648.0 256000.0 159104.0 25600.0 15872.0 25600.0 15872.0 204800.0
127360.0 218 19
S0CMX:s0区的最大值
S1CMX:s1区的最大值
ECMX:eden区的最大值
C:\Users\Administrator>jstat -gcutil 5804
S0 S1 E O M CCS YGC YGCT FGC FGCT GCT
2.24 0.00 61.90 41.70 93.79 89.83 218 2.511 19 1.275 3.78
6
S0:s0区使用的百分比
S1:s1区使用的百分比
E:eden区使用的百分比
O:Old区使用的百分比
P:永久区使用的百分比
2.3jinfo命令
jinfo
-flag :打印指定JVM的参数值
-flag [+|-]:设置指定JVM参数的布尔值
-flag =:设置指定JVM参数的值
2.4jmap命令
可以生成JAVA应用程序的堆快照和对象的统计信息
2.5jhat命令
用于分析Java应用程序的堆快照内容
2.6jstack命令
用于导出Java应用程序的线程堆栈
jstack [-l]
2.7jstatd命令
2.8hprof工具
2.9jconsole














 2070
2070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









