






XML DOM简介
XML DOM 是用于获取、更改、添加或删除 XML 元素的标准。
XML 文档中的每个成分都是一个节点。
- DOM 是这样规定的:
整个文档是一个文档节点
每个 XML 标签是一个元素节点
包含在 XML 元素中的文本是文本节点
每一个 XML 属性是一个属性节点
注释属于注释节点
元素节点不包括文本,元素节点的文本是存储在文本节点中的。
XML 文档的 documentElement 属性是根节点。
在jdk中,Document接口继承自Node接口
Element接口也继承自Node接口
DOM方式读取XML文件
项目目录结构图:
config包下language.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<languages cat = "it">
<lan id = "1">
<name>java</name>
<ide>Eclipse</ide>
</lan>
<lan id = "2">
<name>swift</name>
<ide>XCode</ide>
</lan>
<lan id = "3">
<name>C#</name>
<ide>Visual Studio</ide>
</lan>
</languages>ReadXML.java
import java.io.File;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
import org.w3c.dom.Node;
import org.w3c.dom.NodeList;
public class ReadXML {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.parse(new File("src/config/language.xml"));//解析文档
Element root = document.getDocumentElement(); //获取根节点
System.out.println("language=" + root.getAttribute("cat"));
System.out.println("-------------");
NodeList list = root.getElementsByTagName("lan");//获取根节点的标签名为“lan”的子节点
for (int i = 0; i < list.getLength(); i ++) {
Element lan = (Element) list.item(i); //遍历得到每个"lan"节点
System.out.println(lan.getTagName()+ "=" + lan.getAttribute("id"));
NodeList lanList = lan.getChildNodes(); //获取“lan”节点的子节点
for (int j = 0; j < lanList.getLength(); j++) {
Node node = lanList.item(j);
if (node instanceof Element) {
System.out.println(node.getNodeName()+"="+node.getTextContent());
}
}
System.out.println("*****************");
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
控制台输出如下:
language=it
-------------
lan=1
name=java
ide=Eclipse
*****************
lan=2
name=swift
ide=XCode
*****************
lan=3
name=C#
ide=Visual Studio
*****************DOM方式创建XML文件
项目结构图如下:

CreateXML.java文件
import java.io.File;
import java.io.StringWriter;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import javax.xml.transform.Transformer;
import javax.xml.transform.TransformerConfigurationException;
import javax.xml.transform.TransformerException;
import javax.xml.transform.TransformerFactory;
import javax.xml.transform.dom.DOMSource;
import javax.xml.transform.stream.StreamResult;
import org.w3c.dom.Document;
import org.w3c.dom.Element;
public class CreateXML {
public static void main(String[] args) {
try {
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
Document document = builder.newDocument();
Element languages = document.createElement("languages");
languages.setAttribute("cat", "it");
Element lan_1 = document.createElement("lan");
lan_1.setAttribute("id", "1");
Element name_1 = document.createElement("name");
name_1.setTextContent("Java");
Element ide_1 = document.createElement("ide");
ide_1.setTextContent("Eclipse");
lan_1.appendChild(name_1);
lan_1.appendChild(ide_1);
languages.appendChild(lan_1);
document.appendChild(languages);
//将构建好的xml输出
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
//输出到控制台
StringWriter writer = new StringWriter();
transformer.transform(new DOMSource(document), new StreamResult(writer));
System.out.println(writer.toString());
//输出到文件
transformer.transform(new DOMSource(document), new StreamResult(new File("language.xml")));
} catch (ParserConfigurationException e) {
e.printStackTrace();
} catch (TransformerConfigurationException e) {
e.printStackTrace();
} catch (TransformerException e) {
e.printStackTrace();
}
}
}控制台输出如下:
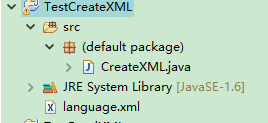
<?xml version="1.0" encoding="UTF-8" standalone="no"?><languages cat="it"><lan id="1"><name>Java</name><ide>Eclipse</ide></lan></languages>运行之后刷新项目目录,可看到已经产生language.xml文件:

language.xml文件:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<languages cat="it">
<lan id="1">
<name>Java</name>
<ide>Eclipse</ide>
</lan>
</languages>














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









