







平均数的误差
上一篇文章介绍了一个机会过程抽得数之和的标准误差SE是:
在从装有标上数字的卡片的盒中作随机有放回的抽取时,抽得数之和的标准误差是:
SquareRoot ( 抽取次数 ) ×(盒子的SD)
若要求出抽得数的平均数的SE也很简单:
抽得的平均数的SE等于
它们的和的SE / 抽取次数 = 盒子的SD / SquareRoot ( 抽取次数 )
通过它可以估计抽得的平均数的变异性。注意,有时我们是不知道盒子的SD的,可以用样本的SD来近似代替。
例如,对某砝码的质量做100次测量,这些测量的平均数是(1kg + 715μg), SD是 80μg,给出如下两个问题:
(1)单次测量值可能偏离确切重量多少?
(2)所有100次测量的平均数可能偏离确切重量多少?
对问题(1)的回答是 80μg。因为SD衡量的就是平均而言单次测量相对于均值的偏离程度(这里认为 均值≈真值)。
对问题(2)的回答是 8μg。因为 平均数的SE = 盒子的SD / SquareRoot ( 抽取次数 ) = 80 / SquareRoot(100) = 8。
最终,测量人员可以说:
砝码的质量以 68% 的置信度落在这个区间内:(1kg + 715μg)± 8μg
或
砝码的质量以 95% 的置信度落在这个区间内:(1kg + 715μg)± 16μg
而“置信”(Confidence)这个词也提醒我们:
机会存在于测量过程中,而不是在被测量的事物中
可以这样理解这句话:
砝码的质量是一个客观存在的常量,不因测量手段的不同而变化,并且误差是在测量过程中被引入的。
机会模型
如果一个随机场合能够抽象成从一个盒子中抽取的过程,我们就可以应用频率理论对其进行研究。这个盒子模型也被称为机会模型或随机模型。
机会模型有它的适用范围:
如果整个期间数据呈现一定趋势或规律模式,盒子模型不能应用。
下表给出中国在2004-2013年的城市化率:
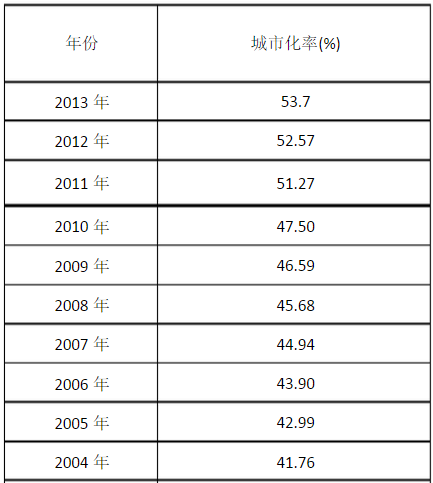
这十年间中国城市化率稳定的上升,它不能被抽象为盒子模型。从盒子中抽取的数有时上升,有时下降。
举个散点图的例子:
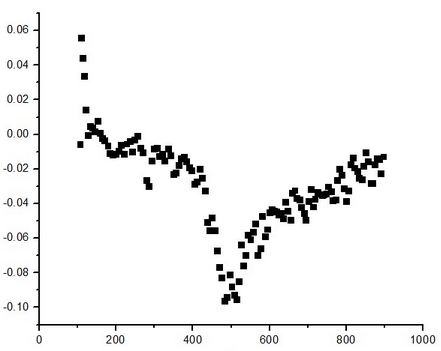
如果把每个点看做一次抽取,x 值代表抽取的编号,y 值代表抽到的值,可以看出散点具有明显的规律性分布,也即 y 与 x 具有相关性。例如,一国的城市化率与年份具有相关性、某地的月平均气温与月份具有相关性,此时用回归模型分析更合理。
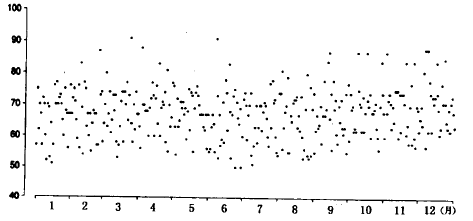
一个盒子模型的统计数据看上去应该是这样的:
或者是这样的
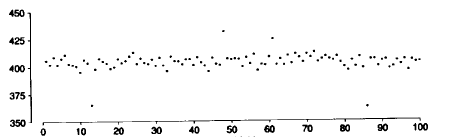
显然,每次抽取的值的概率分布都是一样的,并没有因为是第1次抽取还是第100次抽取而有所不同。
Z-检验
最好通过例子来说明,这是《统计学》书中的一道习题:
问:
一个公司最近采用了弹性时间工作制,希望该制度能提高员工的出勤率。为了检验效果,管理层简单随机地抽取了100名员工作为样本,并对他们进行了跟踪。一年下来,这些雇员平均缺勤 5.5 天,SD是 2.9 天。已知在弹性时间工作制实施之前员工平均缺勤 6.3 天,这能否说明该制度有效减少了缺勤率?还是这个抽样数据仅仅是一个机会变异?
答:
假设(1):样本平均缺勤率的减少由机会变异造成。
假设(2):该制度有效减少了缺勤率。
把假设(1)称为【原假设】,把假设(2)称为【备选假设】。
如果将全公司员工的出勤情况抽象成一个盒子模型,那么原假设和备选假设都是对盒子模型的一种描述。他们是互斥的。
把 6.3 天称为【期望值】,把 5.5 天称为【观察值】
缺勤平均数的SE = 盒子SD / SquareRoot(抽取次数) = 2.9 / 10 = 0.29
检验统计常量:
Z = (观察值 - 期望值)/ SE = (5.5 - 6.3) / 0.29 = -2.76
该公式说明观察值相对于期望值向左偏移了 2.76 个 SE。
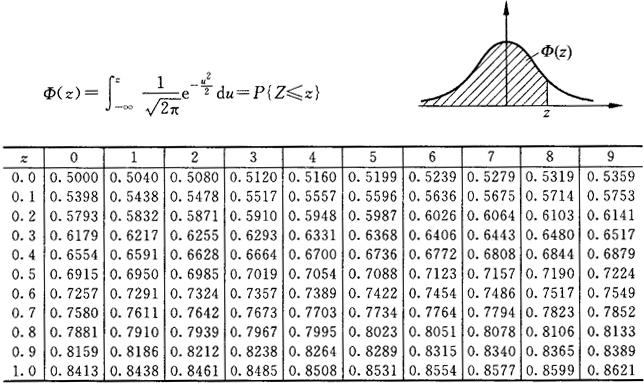
如果原假设正确,这样程度的偏移发生的概率约为 0.3% (通过正态表可查得)。我们认为这个概率太小了,所以原假设是错误的,也即,新制度确实降低了缺勤率,它明确地反映在抽样数据上,并且这不是一个机会变异。
答毕。
上题中求得的概率 0.3% 就是统计结果的【显著性】,用 P 来表示。
若 P < 5%,我们称此结果为统计显著。
若 P < 1%,我们称此结果为高度显著。
不同的应用场合下,拒绝原假设的触发条件不同,可以是统计显著,也可以是高度显著,甚至可以是任何规定的条件。
上述检验过程是单样本检验,样本从同一个盒子抽取。如果两个相互独立且适当大的简单随机样本取自两个分开的盒子,对它们平均数之间差异的统计量做检验称为双样本Z-检验。
此时原假设称这两个盒子有相同的平均数,而备选假设称两个盒子均值的差异是显著的。合适的检验统计量为:
Z = (均值1 - 均值2)/ 差的SE
而两个独立随机变量的差的标准误差是 SquareRoot ( a^2 + b^2 ),其中 a 是第一个量的 SE,b 是第二个量的 SE。
其他与单样本检验相同。
附,标准正态表:

t-检验
当抽样次数太少时(比如小于25次),Z检验将是不精确的,此时使用 t 检验。
使用 t 检验可分为 3 个步骤:
(1)测量值较少时,用其 SD 去估计盒子的 SD 不够精确,可以对测量值的 SD 做一个偏大的修正:
盒子 SD ≈ SquareRoot [ 抽样个数 / (抽样个数 - 1) ] × 测量值的SD
(2)确定统计的自由度:
自由度 = 抽样个数 - 1
根据自由度选定 t 曲线。
(3)计算 P 值。
这一块 t 检验与 Z 检验是一样的。
t = (观察值 - 期望值)/ SE
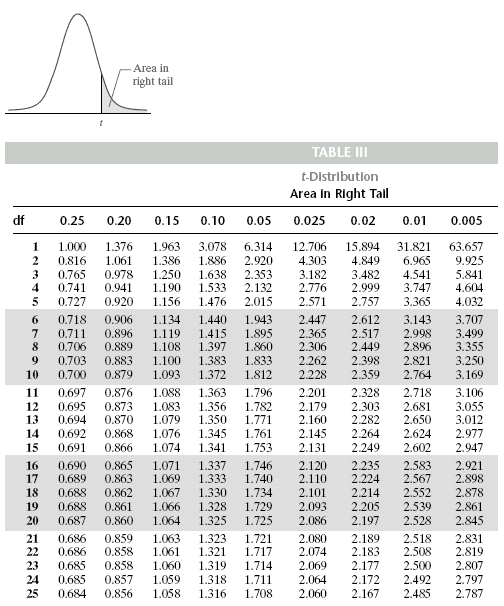
根据检验统计量 t 在对应的 t 曲线上查表得到 P。
t-分布可以理解成是对正态分布的近似,自由度越大就越接近正态分布。
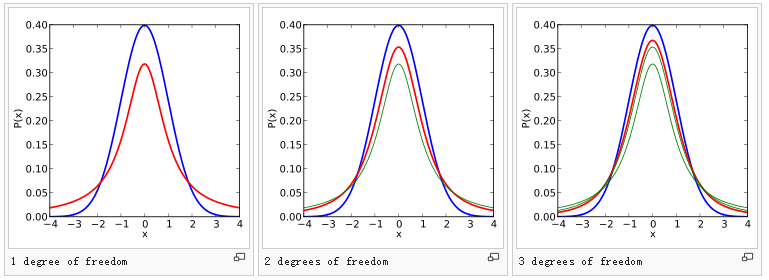
(上图中蓝色曲线为正态分布)。
附,t分布表:
总结
本文所有的讨论都是基于机会模型(盒子模型),有规律的统计数据不适合抽象为机会模型。
Z-检验 与 t-检验针对抽样数据的均值做显著性检验,能够反映出一些趋势性的信息,为决策提供支持。
本文讨论的显著性检验都是单尾(Single Tail)检验,它反映均值偏向某一方向的趋势大小。有时均值同时可能从两个方向偏离期望值,既可以大于期望值,也可以小于期望值。例如,对于弹性时间工作问题,修改备选假设为:新的制度可能降低平均缺勤率,也可能提高了它。此时 Z = -2.76 或 Z = 2.76 都将是高度显著的。这就是双尾检验。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









