







前言
作为一款缓存型nosql数据库,redis在诞生之初就以高性能、丰富的数据结构等特性获得业界的青睐。redis默认提供了五种数据类型的支持:string、list、set、zset、hash。针对一般性的日常应用,这些数据结构基本可以满足我们了,但是针对一些特定业务场景,需要一些新的数据结构来简化业务的开发和使用,比如在物流行业中,可能需要存储多边形地理信息并对点、线和多边形的关系进行一些位置相关运算(比如使用R-tree结构)。因此,为redis开发新的数据结构显得尤为重要,本文就将以一个简单的实例来介绍开发一个新的redis数据结构所需要做的所有事情,虽然redis4开始已经提供了module机制,使用module机制开发数据结构更为方便,但是为了更深入的理解redis内部的源码细节,本文不使用module方式。
首先,先以一张图从宏观上展示一下redis现有数据结构的概况,由于空间有限,下图没有列出redis所有数据结构,以及对每一种数据结构只展示了一种编码方式,但是这对理解起来没有任何影响(本文所有图片看不清的可以单独放大图片观看)。
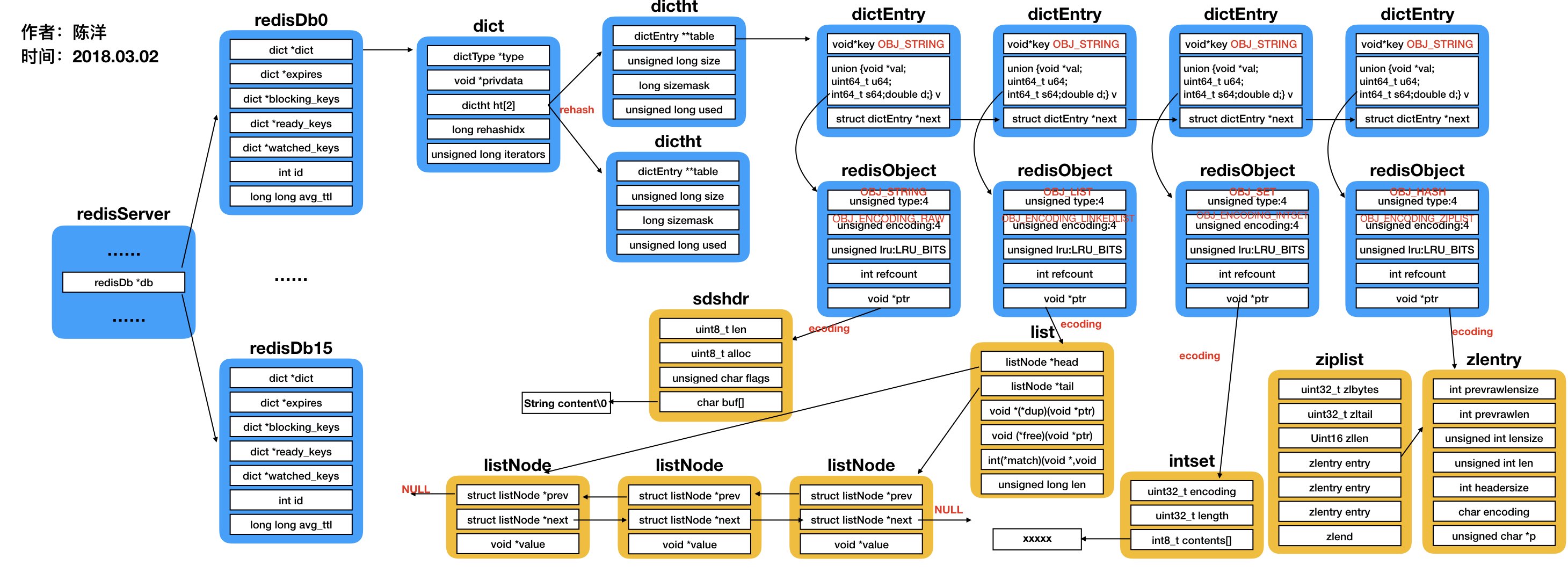
流程
为了行文的方便,我先直接给出要开发一个redis新数据结构所需要做的基本流程:
- 数据结构定义
- 添加新的对象类型(redisObject)、编码方式以及对象创建和销毁方法
- 编写rdb的save和load方法
- 编写aof rewrite方法
- 编写数据结构内存使用统计方法
- 实现命令
- 编写unit test
下面我就分别按照上面的几个步骤来实现。
1、数据结构定义
为了叙述简单,本文以一个并没有实际业务意义的数据结构实现为目的。它实际上就是一个单向链表,我将该数据结构命名为HelloType。将我们的数据结构定义在hellotype.h中。
在hellotype.h文件中,我们首先定义链表节点:
struct HelloTypeNode {
int64_t value;// 节点承载值
struct HelloTypeNode *next;// 节点指针
};然后定义redis数据结构:
struct HelloTypeObject {
struct HelloTypeNode *head;// 链表头结点
size_t len; // 已经添加的链表节点的个数
}HelloTypeObject;2、添加对象类型、对象创建方法和销毁方法
定义好了数据结构,那么该数据结构在什么时候初始化或者是创建呢?在redis中,所有数据结构都是以对象(redisObject)的形式存在的,对象的定义如下(定义在server.h):
typedef struct redisObject {
unsigned type:4;
unsigned encoding:4;
unsigned lru:LRU_BITS; /* LRU time (relative to global lru_clock) or
* LFU data (least significant 8 bits frequency
* and most significant 16 bits decreas time). */
int refcount;
void *ptr;
} robj;所有数据结构对上都呈现为redisObject,对下使用不同的encoding进行编码、存储,不同的数据类型使用type字段进行区分,type只有4 bit,因此使用传统方式最多只能定义16种redis数据结构(使用module方式则没有这个限制),redis现在支持的数据结构type定义如下(定义在server.h):
/* The actual Redis Object */
#define OBJ_STRING 0 /* String object. */
#define OBJ_LIST 1 /* List object. */
#define OBJ_SET 2 /* Set object. */
#define OBJ_ZSET 3 /* Sorted set object. */
#define OBJ_HASH 4 /* Hash object. */
/* The "module" object type is a special one that signals that the object
* is one directly managed by a Redis module. In this case the value points
* to a moduleValue struct, which contains the object value (which is only
* handled by the module itself) and the RedisModuleType struct which lists
* function pointers in order to serialize, deserialize, AOF-rewrite and
* free the object.
*
* Inside the RDB file, module types are encoded as OBJ_MODULE followed
* by a 64 bit module type ID, which has a 54 bits module-specific signature
* in order to dispatch the loading to the right module, plus a 10 bits
* encoding version. */
#define OBJ_MODULE 5 /* Module object. */
#define OBJ_STREAM 6 /* Stream object. */
#define OBJ_HELLO_TYPE 7 // 我们自己的新类型如上所示,我们添加了OBJ_HELLO_TYPE类型字段,但是该对象还没有办法创建,在redis中,对象的创建需要定义create*之类的创建函数,比如hash的创建函数实现为(定义在object.c):
robj *createHashObject(void) {
unsigned char *zl = ziplistNew();// 创建ziplist
robj *o = createObject(OBJ_HASH, zl);
o->encoding = OBJ_ENCODING_ZIPLIST;// 使用ziplist编码方式
return o;
}set的创建函数如下(针对不同的编码方式会有多个创建函数):
robj *createSetObject(void) {
dict *d = dictCreate(&setDictType,NULL);
robj *o = createObject(OBJ_SET,d);
o->encoding = OBJ_ENCODING_HT;// 使用hashtable编码方式存储
return o;
}
robj *createIntsetObject(void) {
intset *is = intsetNew();
robj *o = createObject(OBJ_SET,is);
o->encoding = OBJ_ENCODING_INTSET;// 使用intset编码方式存储
return o;
}上面所有的创建函数最终都会用到createObject创建对象,其定义如下(定义在object.c):
robj *createObject(int type, void *ptr) {
robj *o = zmalloc(sizeof(*o));
o->type = type;
o->encoding = OBJ_ENCODING_RAW;// 默认的编码方式是RAW
o->ptr = ptr; // 针对不同的编码方式,这里指向的数据结构是不同的
o->refcount = 1;
/* Set the LRU to the current lruclock (minutes resolution), or
* alternatively the LFU counter. */
if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) {
o->lru = (LFUGetTimeInMinutes()<<8) | LFU_INIT_VAL;
} else {
o->lru = LRU_CLOCK();
}
return o;
}上面的创建函数一直在使用encoding这个概念,出于性能和内存占用的权衡考虑,redis为每种数据结构至少定义了两种encoding方式,它们和数据结构的对应关系如下:

有了上面的概念,那么我们可以定义自己的对象创建函数了,如下(定义在object.c):
robj *createHelloTypeObject(void){
HelloTypeObject *h = hellotypeNew();// 创建我们自定义的数据结构
robj *o = createObject(OBJ_HELLO_TYPE,h);// 次数默认使用OBJ_ENCODING_RAW编码类型,这里也可以自定义新的编码类型,对实现而言没有本质的影响
return o;
}
其中hellotypeNew函数是自定义数据结构的创建函数,那么它在哪里定义呢?由redis源码可以看出,redis的所有数据结构(创建函数和命令的实现函数)都定义在一个单独的文件中,并且文件名都以t_开头(t为type的缩写),比如t_set.c、t_hash.c等,那么我们也遵循这个约束,将其定义为t_hellotype.c,并在其中添加如下内容:
#include "server.h"
#include "hellotype.h"
HelloTypeObject *hellotypeNew(void){
HelloTypeObject *h = zmalloc(sizeof(*h));
h->head = NULL;// 头指针为NULL
h->len = 0;
return h;
}同时,为了便于被其他文件引用,在hellotype.h中为该函数添加声明,因此此时的hellotype.h文件内容如下:
#ifndef HELLO_TYPE_H
#define HELLO_TYPE_H
#include "server.h"
struct HelloTypeNode {
int64_t value;
struct HelloTypeNode *next;
};
typedef struct HelloTypeObject {
struct HelloTypeNode *head;
size_t len;
}HelloTypeObject;
HelloTypeObject *hellotypeNew(void);
#endif对象被创建之后,什么时候被释放呢?redis使用引用计数的方式来管理对象的生命周期,每次删除一个对象的时候都将其引用计数减1,如果引用计数为0才会真正的执行删除操作,该逻辑在 object.c中的decrRefCount函数中实现:
void decrRefCount(robj *o) {
if (o->refcount == 1) {
switch(o->type) {
case OBJ_STRING: freeStringObject(o); break;
case OBJ_LIST: freeListObject(o); break;
case OBJ_SET: freeSetObject(o); break;
case OBJ_ZSET: freeZsetObject(o); break;
case OBJ_HASH: freeHashObject(o); break;
case OBJ_MODULE: freeModuleObject(o); break;
case OBJ_STREAM: freeStreamObject(o); break;
case OBJ_HELLO_TYPE:freeHelloTypeObject(o); break;// 添加我们自己的数据结构释放函数
default: serverPanic("Unknown object type"); break;
}
zfree(o);
} else {
if (o->refcount <= 0) serverPanic("decrRefCount against refcount <= 0");
if (o->refcount != OBJ_SHARED_REFCOUNT) o->refcount--;
}
}
freeHelloTypeObject函数也实现在object.c中,其本质就是循环释放一个链表的所有节点,如下:
void freeHelloTypeObject(robj *o){
struct HelloTypeNode *cur, *next;
cur = (( struct HelloTypeObject * )o->ptr)->head;// 先找到头结点
while(cur) {
next = cur->next;
zfree(cur);
cur = next;
}
zfree(o);
}3、编写rdb的save和load方法
我们都知道,rdb是redis持久化的一种机制,为了能让我们自己的数据结构也能被正确的备份和恢复,就需要我们实现其save和load方法。
首先,还是先大致介绍些RDB文件的组织结构,大致可以用下图表示:
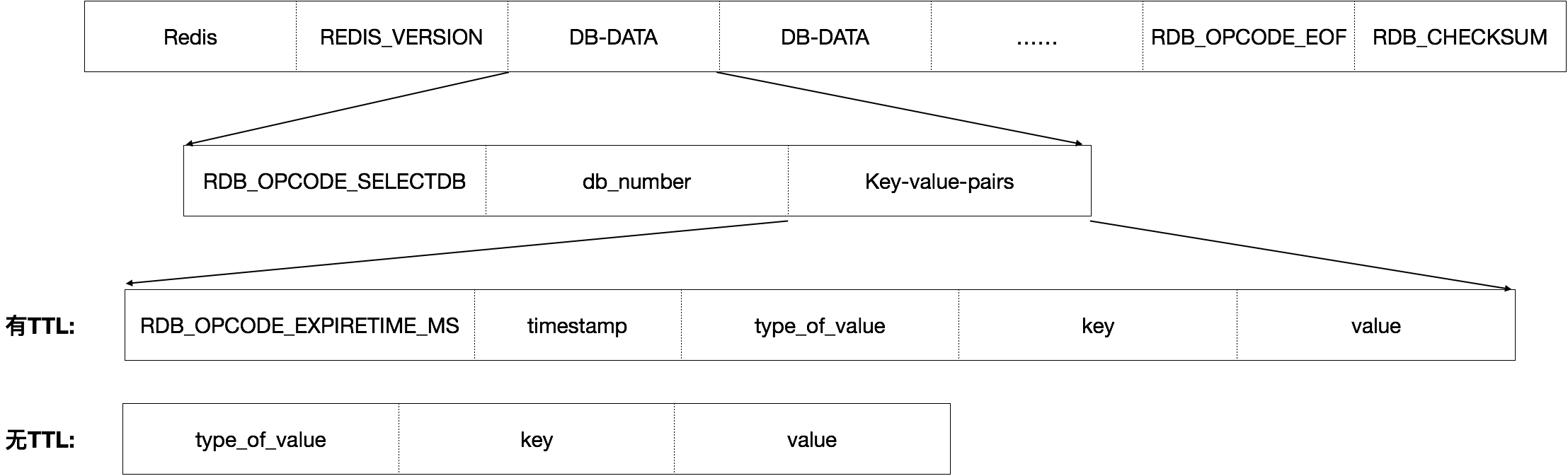
可以看到,RDB对每一个kv pair都使用一个类型来标识后面存储的value的类型(key的类型永远为string),因此为了让RDB可以正确的识别出我们自定义的类型,也需要增加一个RDB类型,在rdb.h中更改如下:
/* Map object types to RDB object types. Macros starting with OBJ_ are for
* memory storage and may change. Instead RDB types must be fixed because
* we store them on disk. */
#define RDB_TYPE_STRING 0
#define RDB_TYPE_LIST 1
#define RDB_TYPE_SET 2
#define RDB_TYPE_ZSET 3
#define RDB_TYPE_HASH 4
#define RDB_TYPE_ZSET_2 5 /* ZSET version 2 with doubles stored in binary. */
#define RDB_TYPE_MODULE 6
#define RDB_TYPE_MODULE_2 7 /* Module value with annotations for parsing without
the generating module being loaded. */
#define RDB_TYPE_HELLO_TYPE 8 // 我们自己的RDB类型
/* NOTE: WHEN ADDING NEW RDB TYPE, UPDATE rdbIsObjectType() BELOW */
/* Object types for encoded objects. */
#define RDB_TYPE_HASH_ZIPMAP 9
#define RDB_TYPE_LIST_ZIPLIST 10
#define RDB_TYPE_SET_INTSET 11
#define RDB_TYPE_ZSET_ZIPLIST 12
#define RDB_TYPE_HASH_ZIPLIST 13
#define RDB_TYPE_LIST_QUICKLIST 14
#define RDB_TYPE_STREAM_LISTPACKS 15
/* NOTE: WHEN ADDING NEW RDB TYPE, UPDATE rdbIsObjectType() BELOW */
/* Test if a type is an object type. */
#define rdbIsObjectType(t) ((t >= 0 && t <= 8) || (t >= 9 && t <= 15)) // 不要忘记更改此处类型添加完成之后,先来实现save的功能。有上面的RDB格式可以看出,在保存真正的kv之前,必须先保存类型,这个动作是由rdbSaveObjectType完成的,在rdb.c中,实现如下:
/* Save the object type of object "o". */
int rdbSaveObjectType(rio *rdb, robj *o) {
switch (o->type) {
case OBJ_STRING:
return rdbSaveType(rdb,RDB_TYPE_STRING);
case OBJ_LIST:
if (o->encoding == OBJ_ENCODING_QUICKLIST)
return rdbSaveType(rdb,RDB_TYPE_LIST_QUICKLIST);
else
serverPanic("Unknown list encoding");
case OBJ_SET:
if (o->encoding == OBJ_ENCODING_INTSET)
return rdbSaveType(rdb,RDB_TYPE_SET_INTSET);
else if (o->encoding == OBJ_ENCODING_HT)
return rdbSaveType(rdb,RDB_TYPE_SET);
else
serverPanic("Unknown set encoding");
case OBJ_ZSET:
if (o->encoding == OBJ_ENCODING_ZIPLIST)
return rdbSaveType(rdb,RDB_TYPE_ZSET_ZIPLIST);
else if (o->encoding == OBJ_ENCODING_SKIPLIST)
return rdbSaveType(rdb,RDB_TYPE_ZSET_2);
else
serverPanic("Unknown sorted set encoding");
case OBJ_HASH:
if (o->encoding == OBJ_ENCODING_ZIPLIST)
return rdbSaveType(rdb,RDB_TYPE_HASH_ZIPLIST);
else if (o->encoding == OBJ_ENCODING_HT)
return rdbSaveType(rdb,RDB_TYPE_HASH);
else
serverPanic("Unknown hash encoding");
case OBJ_STREAM:
return rdbSaveType(rdb,RDB_TYPE_STREAM_LISTPACKS);
case OBJ_MODULE:
return rdbSaveType(rdb,RDB_TYPE_MODULE_2);
case OBJ_HELLO_TYPE:
return rdbSaveType(rdb,RDB_TYPE_HELLO_TYPE);// 添加保存自定义类型
default:
serverPanic("Unknown object type");
}
return -1; /* avoid warning */
}接下来实现保存value部分,需要修改rdb.c中的rdbSaveObject函数,添加我们定义的数据结构,如下:
/* Save a Redis object. Returns -1 on error, number of bytes written on success. */
ssize_t rdbSaveObject(rio *rdb, robj *o) {
ssize_t n = 0, nwritten = 0;
if (o->type == OBJ_STRING) {
/* Save a string value */
if ((n = rdbSaveStringObject(rdb,o)) == -1) return -1;
nwritten += n;
} else if (o->type == OBJ_LIST) {
} else if (o->type == OBJ_SET) {
} else if (o->type == OBJ_ZSET) {
} else if (o->type == OBJ_HASH) {
} else if (o->type == OBJ_STREAM) {
} else if (o->type == OBJ_MODULE) {
} else if (o->type == OBJ_HELLO_TYPE){
if(o->encoding == OBJ_ENCODING_RAW){
struct HelloTypeObject *hto = o->ptr;
struct HelloTypeNode *node = hto->head;
if ((n = rdbSaveLen(rdb,hto->len)) == -1) return -1;// 持久化链表长度
nwritten += n;// 每次都要更新nwritten,表示向RDB文件中写入的字节数
while(node) {
if ((n = rdbSaveLen(rdb,node->value)) == -1) return -1;// 持久化节点值
nwritten += n;
node = node->next;
}
} else {
serverPanic("Unknown hellotype encoding");
}
} else {
serverPanic("Unknown object type");
}
return nwritten;
}save完成之后开始实现load,其实就是save的相反过程,按照什么格式存进去的就按照什么格式读出来,在rdb.c的rdbLoadObject函数中:
/* Load a Redis object of the specified type from the specified file.
* On success a newly allocated object is returned, otherwise NULL. */
robj *rdbLoadObject(int rdbtype, rio *rdb) {
robj *o = NULL, *ele, *dec;
uint64_t len;
unsigned int i;
if (rdbtype == RDB_TYPE_STRING) {
/* Read string value */
if ((o = rdbLoadEncodedStringObject(rdb)) == NULL) return NULL;
o = tryObjectEncoding(o);
} else if (rdbtype == RDB_TYPE_LIST) {
} else if (rdbtype == RDB_TYPE_SET) {
} else if (rdbtype == RDB_TYPE_ZSET_2 || rdbtype == RDB_TYPE_ZSET) {
} else if (rdbtype == RDB_TYPE_HASH) {
} else if (rdbtype == RDB_TYPE_LIST_QUICKLIST) {
} else if (rdbtype == RDB_TYPE_HASH_ZIPMAP ||
rdbtype == RDB_TYPE_LIST_ZIPLIST ||
rdbtype == RDB_TYPE_SET_INTSET ||
rdbtype == RDB_TYPE_ZSET_ZIPLIST ||
rdbtype == RDB_TYPE_HASH_ZIPLIST)
{
} else if (rdbtype == RDB_TYPE_STREAM_LISTPACKS) {
} else if (rdbtype == RDB_TYPE_MODULE || rdbtype == RDB_TYPE_MODULE_2) {
} else if (rdbtype == RDB_TYPE_HELLO_TYPE){
uint64_t len;
if ((len = rdbLoadLen(rdb,NULL)) == RDB_LENERR) return NULL;// 加载链表长度
uint64_t elements = len;
robj *hto = createHelloTypeObject();
while(elements--) {
if ((len = rdbLoadLen(rdb,NULL)) == RDB_LENERR) return NULL;// 加载链表值
int64_t ele = len;
HelloTypeInsert(hto->ptr,ele);// 插入链表
}
o = hto;
} else {
rdbExitReportCorruptRDB("Unknown RDB encoding type %d",rdbtype);
}
return o;
}
4、编写aof rewrite方法
aof是redis的另一个持久化方法,由于aof需要rewrite机制来降低aof文件的大小,因此我们添加相应的代码来让redis可以正确的识别并rewrite我们自己的数据结构,入口在aof.c的rewriteAppendOnlyFileRio函数中:
int rewriteAppendOnlyFileRio(rio *aof) {
/* Save the key and associated value */
if (o->type == OBJ_STRING) {
/* Emit a SET command */
char cmd[]="*3\r\n$3\r\nSET\r\n";
if (rioWrite(aof,cmd,sizeof(cmd)-1) == 0) goto werr;
/* Key and value */
if (rioWriteBulkObject(aof,&key) == 0) goto werr;
if (rioWriteBulkObject(aof,o) == 0) goto werr;
} else if (o->type == OBJ_LIST) {
if (rewriteListObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_SET) {
if (rewriteSetObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_ZSET) {
if (rewriteSortedSetObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_HASH) {
if (rewriteHashObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_STREAM) {
if (rewriteStreamObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_MODULE) {
if (rewriteModuleObject(aof,&key,o) == 0) goto werr;
} else if (o->type == OBJ_HELLO_TYPE) {// 此处添加我们自己的数据结构
if (rewritreHelloTypeObject(aof,&key,o) == 0) goto werr;
} else {
serverPanic("Unknown object type");
}
}
同样在aof中实现rewritreHelloTypeObject函数,其本质就是根据rewirte时刻aof中的数据构造等价的redis 命令:
int rewritreHelloTypeObject(rio *r, robj *key, robj *o){
struct HelloTypeObject *hto = o->ptr;
struct HelloTypeNode *node = hto->head;
while(node) {
/* Bulk count. */
if (rioWriteBulkCount(r,'*',3) == 0) return 0;
if (rioWriteBulkString(r,"HELLOTYPE.INSERT",sizeof "HELLOTYPE.INSERT") == 0) return 0;
if (rioWriteBulkObject(r,key) == 0) return 0;
if (rioWriteBulkLongLong(r,node->value) == 0) return 0;
node = node->next;
}
return 1;
}上面的构造需要对redis协议有一定的理解,具体的可以参见这里:https://redis.io/topics/protocol
5、编写数据结构内存使用统计方法
redis经常需要获取数据结构当前堆内存的使用情况,该功能在object.c中objectComputeSize函数完成:
size_t objectComputeSize(robj *o, size_t sample_size) {
sds ele, ele2;
dict *d;
dictIterator *di;
struct dictEntry *de;
size_t asize = 0, elesize = 0, samples = 0;
if (o->type == OBJ_STRING) {
if(o->encoding == OBJ_ENCODING_INT) {
asize = sizeof(*o);
} else if(o->encoding == OBJ_ENCODING_RAW) {
asize = sdsAllocSize(o->ptr)+sizeof(*o);
} else if(o->encoding == OBJ_ENCODING_EMBSTR) {
asize = sdslen(o->ptr)+2+sizeof(*o);
} else {
serverPanic("Unknown string encoding");
}
} else if (o->type == OBJ_LIST) {
} else if (o->type == OBJ_SET) {
} else if (o->type == OBJ_ZSET) {
} else if (o->type == OBJ_HASH) {
} else if (o->type == OBJ_STREAM) {
} else if (o->type == OBJ_MODULE) {
} else if (o->type == OBJ_HELLO_TYPE){// 此处添加我们的实现
const struct HelloTypeObject *hto = o->ptr;
struct HelloTypeNode *node = hto->head;
asize = sizeof(*hto) + sizeof(*node)*hto->len; // 将头节点和链表节点内存使用计算和并复制给asize
} else {
serverPanic("Unknown object type");
}
return asize;
}6、实现命令
现在一切都准备就绪了,到了实现命令的时候了,命令的实现包括两个方面,分别对应redis的通用命令和类型特有的命令。redis中键空间通用的命令有很多,比如DEL、DUMP、EXISTS、TYPE、SCAN等,此处我们以支持TYPE命令为例,该命令的实现在db.c的typeCommand函数中,它很简单,只需要返回一个类型字符串就可以了。
void typeCommand(client *c) {
robj *o;
char *type;
o = lookupKeyReadWithFlags(c->db,c->argv[1],LOOKUP_NOTOUCH);
if (o == NULL) {
type = "none";
} else {
switch(o->type) {
case OBJ_STRING: type = "string"; break;
case OBJ_LIST: type = "list"; break;
case OBJ_SET: type = "set"; break;
case OBJ_ZSET: type = "zset"; break;
case OBJ_HASH: type = "hash"; break;
case OBJ_STREAM: type = "stream"; break;
case OBJ_MODULE: {
moduleValue *mv = o->ptr;
type = mv->type->name;
}; break;
case OBJ_HELLO_TYPE: type = "hello_type";break;// 这里添加我们自己的实现
default: type = "unknown"; break;
}
}
addReplyStatus(c,type);
}接着我们开始实现类型特有的命令,也就是这些命令只能作用在我们定义的hellotype类型上,根据前文所述,这些命令都会实现在t_hellotype.c中,本实例我们一共会实现三个命令,分别为
- HELLOTYPE.RANGE : 获取指定个数的链表元素
- HELLOTYPE.LEN : 获取链表当前长度
- HELLOTYPE.INSERT : 向链表中掺入一个数据
三个命令分别对应三个处理函数,实现如下:
/* HELLOTYPE.INSERT key value */
void HelloTypeInsert_RedisCommand(client *c) {
robj *o =o = lookupKeyWrite(c->db,c->argv[1]);
if (o != NULL && checkType(c,o,OBJ_HELLO_TYPE)) return;
long long value;
if (!string2ll(c->argv[2]->ptr,sdslen(c->argv[2]->ptr), &value)) {
addReplyError(c,"invalid value: must be a signed 64 bit integer");
return;
}
/* Create an empty value object if the key is currently empty. */
struct HelloTypeObject *hto = NULL;
if (o == NULL) {
// 如果键不存在,就新建并添加到db中
o = createHelloTypeObject();
dbAdd(c->db,c->argv[1],o);
}
hto = o->ptr;
HelloTypeInsert(hto,value);// 执行链表插入
addReplyLongLong(c,hto->len);// 响应客户端当前链表长度
return;
}
/* HELLOTYPE.RANGE key first count */
void HelloTypeRange_RedisCommand(client * c) {
void *replylen = NULL;
robj *o = lookupKeyWrite(c->db,c->argv[1]);
if (o != NULL && checkType(c,o,OBJ_HELLO_TYPE)) return;// 键类型检测
long long first, count;
if (!string2ll(c->argv[2]->ptr,sdslen(c->argv[2]->ptr),&first) ||
!string2ll(c->argv[3]->ptr,sdslen(c->argv[3]->ptr),&count) ||
first < 0 || count < 0)
{
addReplyError(c,
"invalid first or count parameters");
return;
}
struct HelloTypeObject *hto = o ? o->ptr:NULL;
struct HelloTypeNode *node = hto ? hto->head : NULL;
replylen = addDeferredMultiBulkLength(c);// 注意这里需要特殊处理一下,因此实现无法知道链表节点的个数
long long arraylen = 0;
while(node && count--) {
addReplyLongLong(c,node->value);
arraylen++;
node = node->next;
}
setDeferredMultiBulkLength(c, replylen, arraylen);// 填充真正的长度
return ;
}
/* HELLOTYPE.LEN key */
void HelloTypeLen_RedisCommand(client * c) {
robj *o = lookupKeyWrite(c->db,c->argv[1]);
if (o != NULL && checkType(c,o,OBJ_HELLO_TYPE)) return;
struct HelloTypeObject *hto = o ? o->ptr:NULL;
addReplyLongLong(c,hto ? hto->len : 0);
return ;
}命令实现完之后需要在server.h中进行声明:
/* 声明我们实现的命令 */
void htlenCommand(client * c);
void htrangeCommand(client * c);
void htinsertCommand(client *c);声明之后,进行最后一步,将命令写入redisCommandTable中,至此redis才能识别我们新加入的命令并找到命令对应的处理函数,redisCommandTable定义在server.c中,顾名思义就是redisCommand类型数组,redisCommandTable定义如下:
struct redisCommand {
char *name;
redisCommandProc *proc;
int arity;
char *sflags; /* Flags as string representation, one char per flag. */
int flags; /* The actual flags, obtained from the 'sflags' field. */
/* Use a function to determine keys arguments in a command line.
* Used for Redis Cluster redirect. */
redisGetKeysProc *getkeys_proc;
/* What keys should be loaded in background when calling this command? */
int firstkey; /* The first argument that's a key (0 = no keys) */
int lastkey; /* The last argument that's a key */
int keystep; /* The step between first and last key */
long long microseconds, calls;
};- name: 命令名
- proc: 指针函数,指向该命令对应的处理函数
- arity: 参数个数(包括命令本身),当为-N时表示大于等于N个参数
- sflags: 命令标志位字符串表示,码表请参考下面
* w: write command (may modify the key space).
* r: read command (will never modify the key space).
* m: may increase memory usage once called. Don't allow if out of memory.
* a: admin command, like SAVE or SHUTDOWN.
* p: Pub/Sub related command.
* f: force replication of this command, regardless of server.dirty.
* s: command not allowed in scripts.
* R: random command. Command is not deterministic, that is, the same command
* with the same arguments, with the same key space, may have different
* results. For instance SPOP and RANDOMKEY are two random commands.
* S: Sort command output array if called from script, so that the output
* is deterministic.
* l: Allow command while loading the database.
* t: Allow command while a slave has stale data but is not allowed to
* server this data. Normally no command is accepted in this condition
* but just a few.
* M: Do not automatically propagate the command on MONITOR.
* k: Perform an implicit ASKING for this command, so the command will be
* accepted in cluster mode if the slot is marked as 'importing'.
* F: Fast command: O(1) or O(log(N)) command that should never delay
* its execution as long as the kernel scheduler is giving us time.
* Note that commands that may trigger a DEL as a side effect (like SET)
* are not fast commands.
- flag: sflags的位掩码,初始化全为0,在void populateCommandTable(void)方法中会进行初始化
- getkeys_proc: 指针函数,通过此方法来指定key的位置
- first_key_index: 第一个key的位置,为0时表示没有key
- last_key_index: 最后一个key的位置
- key_step: key之间的间距
- microseconds: 该命令的总调用时间,初始化都为0
- calls: 该命令的总调用次数,初始化都为0
get_keys_proc和[first_key_index, last_key_index, key_step]都是指定key的位置,区别在于前者通过函数的方式返回一个int*来指定,后者则是通过指定第一个key值和最后一个key值,并告诉你key值之间的间隔step来表示。目前redis大部分的命令都是通过[first_key_index,last_key_index,key_step]来指定,因为大部分的命令的Key的位置都是有固定规律的。
最终我们的命令实现如下:
struct redisCommand redisCommandTable[] = {
{"module",moduleCommand,-2,"as",0,NULL,0,0,0,0,0},
{"get",getCommand,2,"rF",0,NULL,1,1,1,0,0},
{"set",setCommand,-3,"wm",0,NULL,1,1,1,0,0},
......
/* 下面添加我们自己的命令 */
{"HELLOTYPE.LEN",htlenCommand,1,"r",0,NULL,1,1,1,0,0},
{"HELLOTYPE.INSERT",htinsertCommand,2,"m",0,NULL,1,1,1,0,0},
{"HELLOTYPE.RANGE",htrangeCommand,3,"r",0,NULL,1,1,1,0,0}
};这里为了让不了解redis命令执行过程的人有一个大致的了解,从网上找到一张图,个人感觉画的还不错,我就不自己重新画了:
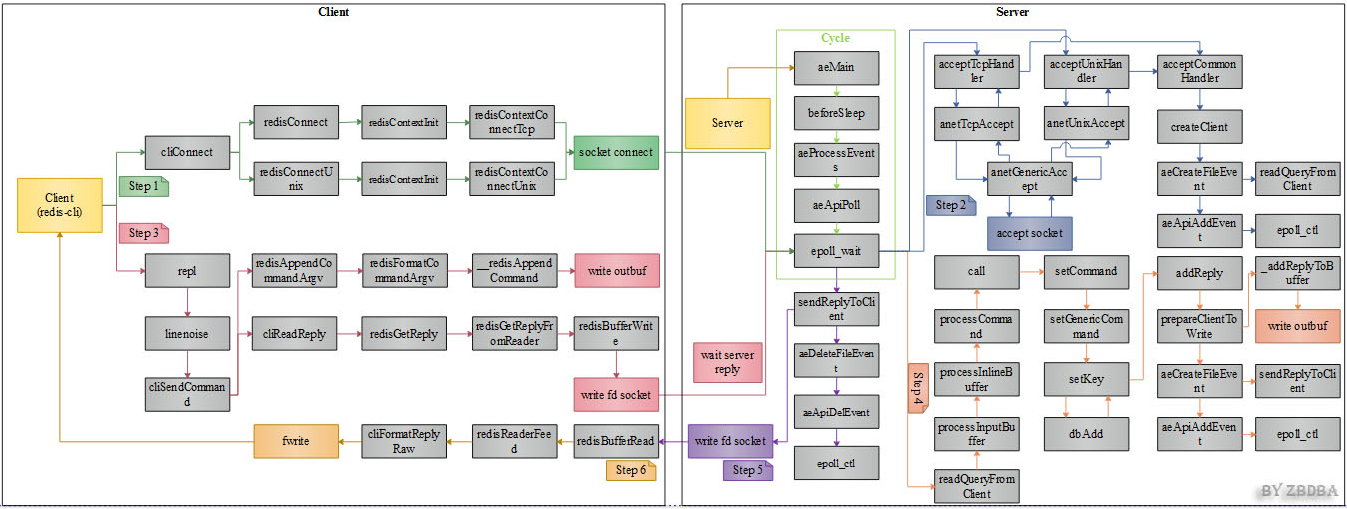
7、编写unit test
编写unit test之前我们最好先用原生redis-cli测试一下我们新加的命令:
127.0.0.1:6379> HELLOTYPE.INSERT h1 1
(integer) 1
127.0.0.1:6379> HELLOTYPE.INSERT h1 2
(integer) 2
127.0.0.1:6379> HELLOTYPE.INSERT h1 3
(integer) 3
127.0.0.1:6379> HELLOTYPE.INSERT h1 4
(integer) 4
127.0.0.1:6379> HELLOTYPE.INSERT h1 5
(integer) 5
127.0.0.1:6379> HELLOTYPE.LEN h1
(integer) 5
127.0.0.1:6379> HELLOTYPE.RANGE h1 1 1
1) (integer) 1
127.0.0.1:6379> HELLOTYPE.RANGE h1 1 2
1) (integer) 1
2) (integer) 2
127.0.0.1:6379> HELLOTYPE.RANGE h1 1 4
1) (integer) 1
2) (integer) 2
3) (integer) 3
4) (integer) 4一切正常之后,我们可以添加unit test,参照redis原生数据结构,我们在redis/tests/unit/type目录下新加文件hellotype.tcl,并写入如下内容:
start_server {tags {"hellotype"}} {
test {HELLOTYPE.INSERT key value} {
r del hellotype1
assert_equal 1 [r HELLOTYPE.INSERT hellotype1 1]
assert_equal 2 [r HELLOTYPE.INSERT hellotype1 2]
assert_equal 3 [r HELLOTYPE.INSERT hellotype1 3]
assert_equal 4 [r HELLOTYPE.INSERT hellotype1 4]
assert_equal 5 [r HELLOTYPE.INSERT hellotype1 5]
}
test { HELLOTYPE.LEN key } {
assert_equal 5 [r HELLOTYPE.LEN hellotype1 ]
}
test {HELLOTYPE.RANGE key start count } {
assert_equal 1 [r HELLOTYPE.RANGE hellotype1 1 1 ]
assert_equal {1 2} [r HELLOTYPE.RANGE hellotype1 1 2 ]
assert_equal {1 2 3 4 5} [r HELLOTYPE.RANGE hellotype1 1 5 ]
}
}
然后在test_helper.tcl加入unit/type/hellotype,执行make test就可以执行unit test了。
[ok]: HELLOTYPE.INSERT key value
[ok]: HELLOTYPE.LEN key
[ok]: HELLOTYPE.RANGE key start count
本文修改代码放在这里:https://github.com/chenyang8094/redis_with_new_datastructure















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









