







预期特性;
函数还支持多种调用方式以及参数类型并实现了一些函数式编程接口;
变量的作用域和递归函数;
11.1 什么是函数?
函数是对程序逻辑进行结构化或过程化的一种编程方法。下面简单展示了一些创建、使用,或者引用函数的方法。
declaration/definition def foo(): print 'bar'
function object/reference foo
function call/invocation foo()11.1.1 函数vs 过程
经常拿函数和过程比较。两者都是可以被调用的实体:
函数可能不带任何输入参数,经过一定的处理,最后向调用者传回返回值,一个非零或者零值;
过程是简单,特殊,没有返回值的函数;
从后面内容你会看到,过程就是函数,因为解释器会隐式地返回默认值None。
11.1.2.返回值与函数类型
“什么都不返回”的函数在C语言中默认为“void"的返回类型。 在python 中, 对应的返回对象类型是none。
下面hello()函数的行为就像一个过程,没有返回值。如果保存了返回值,该值为None:
>>> def hello():
... print 'hello world'
>>> res = hello()
hello world
>>> res
>>> print res
None
>>> type(res)
<type 'None'>另外,与其他大多数的语言一样,python 里的函数可以返回一个值或者对象。只是在返回一个容器对象的时候有点不同,看起来像是能返回多个对象。
def foo():
return ['xyz', 1000000, -98.6]
def bar():
return 'abc', [42, 'python'], "Guido" # return ('abc', [4-2j, 'python'], "Guido")foo()函数返回一个列表,bar()函数返回一个元组。由于元组语法上不需要一定带上圆括号, 所以让人真的以为可以返回多个对象。
从返回值的角度来看, 可以通过很多方式来存储元组。接下来的3 种保存返回值的方式是等价的:
>>> aTuple = bar()
>>> x, y, z = bar()
>>> (a, b, c) = bar()
>>> aTuple
('abc', [(4-2j), 'python'], 'Guido')
>>> x, y, z
('abc', [(4-2j), 'python'], 'Guido')
>>> (a, b, c)
('abc', [(4-2j), 'python'], 'Guido')元组既可以被分解成为单独的变量,也可以直接用单一变量对其进行引用。
简而言之,当没有显式地返回元素或者如果返回None 时,python 会返回一个None.那么调用者接收的就是python 返回的那个对象,且对象的类型仍然相同。如果函数返回多个对象,python 把他们聚集起来并以一个元组返回。

表11.1 总结了从一个函数中返回的元素的数目,以及python 实际返回的对象。
许多静态类型的语言主张一个函数的类型就是其返回值的类型。由于python 是动态地确定类型而且函数能返回不同类型的值,所以没有进行直接的类型关联。因为重载并不是语言特性,程序员需要使用type()这个内建函数作为代理,来处理有着不同参数类型的函数的多重声明以模拟类C 语言的函数重载(以参数不同选择函数的多个原型)。
11.2 调用函数
11.2.1.函数操作符
用一对圆括号调用函数。虽然没有正式地学习类和面向对象编程,但在python 中,函数的操作符同样用于类的实例化。
11.2.2.关键字参数
关键字参数的概念仅仅针对函数的调用。让调用者通过函数调用中的参数名字来区分参数。这样规范允许参数缺失或者不按顺序,解释器能通过给出的关键字来匹配参数的值。eg:
def foo(x):
foo_suite
# presumably does some processing with 'x'标准调用 foo():foo(42) foo('bar') foo(y);关键字调用foo():foo(x=42) foo(x='bar') foo(x=y)
再举个更实际的例子, 假设你有一个函数叫做net_conn(),需要两个参数host 和port:
def net_conn(host, port):
net_conn_suite只要按照函数声明中参数定义的顺序,输入恰当的参数,自然就可以调用这个函数:
net_conn('kappa', 8080)当然也可以不按照函数声明中的参数顺序输入,但是要输入相应的参数名,如下例:
net_conn(port=8080, host='chino')当参数允许"缺失“的时候,也可以使用关键字参数.这取决于函数的默认参数, 我们将在下一小节对它进行介绍。
11.2.3.默认参数
默认参数就是声明了默认值的参数。因为给参数赋予了默认值,所以, 在函数调用时,不向该参数传入值也是允许的。我们将在11.5.2 章对默认参数进行更全面的介绍。
11.2.4.参数组
Python 同样允许执行一个没有显式定义参数的函数,相应的方法是通过一个把元组(非关键字参数)或字典(关键字参数)作为参数组传递给函数。基本上,你可以将所有参数放进一个元组或者字典中,仅仅用这些装有参数的容器来调用一个函数,而不必显式地将它们放在函数调用中:
func(*tuple_grp_nonkw_args, **dict_grp_kw_args)其中的tuple_grp_nonkw_args 是以元组形式体现的非关键字参数组, dict_grp_kw_args 是装有关键字参数的字典。
实际上,你也可以给出形参!这些参数包括标准的位置参数和关键字参数,所以在python 中允许的函数调用的完整语法为:
func(positional_args, keyword_args, *tuple_grp_nonkw_args, **dict_grp_kw_args)该语法中的所有的参数都是可选的---从参数传递到函数的过程来看,在单独的函数调用时,每个参数都是独立的。
示例:easyMath.py 程序是一个儿童算术游戏,可以随机选择算术加减法。接着我们生成一个参数列表(两个)。接着选择任意的数字作为算子。因为我们没打算在这个程序的基础版本中支持负数,所以我们将两个数字的列表按从大到小的顺序排序,然后用这个参数列表和随机选择的算术运算符去调用相对应的函数。在3 次错误的尝试以后给出结果,等到用户输入一个正确的answer后便会继续运行.[看ans = ops[op](*nums) ]
from operator import add,sub
from random import randint, choice
# 全局变量
ops = {'+':'add', '-':'sub'}
MAXTRIES = 2
def doprob():
# 随机选择一个操作数
op = choice('+-')
# 生成两个操作数
nums = [randint(1, 10) for i in range(2)]
# 将两个算子从大到小排序
# 因为list.sort()方法原本不支持倒转的标志位,因此添加True
# 如果你使用的是更早一点的python 版本,你要么:
# 增加一个反序的比较函数来获得倒转的排序,如:lambda x, y: cmp(y, x), 或者
# 在 nums.sort()后调用nums.reverse()
nums.sort(reverse=True)
# 计算出正确的解
ans = ops[op](*nums)
pr = '%d %s %d = ' % (nums[0], op, nums[1])
oops = 0
while True:
try:
if int(input(pr)) == ans:
print ('correct')
break
if oops == MAXTRIES:
print ('answer \n %s %d' % (pr, ans))
else:
print ('incorect... try again')
oops+1
except (KeyboardInterrupt, EOFError, ValueError):
print ('invalid input ... try again')
def main():
while True:
doprob()
try:
opt = input('Again? [y]').lower()
if opt and opt[0] == 'n':
break
except (KeyboardInterrupt, EOFError):
break
if __name__ == '__main__':
main()11.3 创建函数
11.3.1. def 语句
函数是用def 语句来创建的,语法如下:
def function_name(arguments):
"function_documentation_string"
function_body_suite由def 关键字,函数的名字,以及参数的集合组成。def 子句的剩余部分包括了一个虽然可选但是强烈推荐的文档字串,和必需的函数体。
11.3.2.声明与定义比较
在声明和定义有区别的C语言中,往往是因为函数的定义可能和其声明放在不同的文件中。python将这两者视为一体,函数的子句由声明的行以及随后的定义体组成的。
11.3.3 前向引用
Python 也不允许在函数未声明之前,对其进行引用或者调用.eg:
def foo():
print 'in foo()'
bar()如果我们调用函数foo(),肯定会失败,因为函数bar()还没有声明:
>>> foo()
in foo()
Traceback (innermost last): File "<stdin>", line 1, in ?
File "<stdin>", line 3, in foo
NameError: bar若定义函数bar(),在函数foo()前给出bar()的声明,就不会有错了。
事实上,我们甚至可以在函数bar()前定义函数foo():
def foo():
print 'in foo()'
bar()
def bar():
print 'in bar()'太神奇了,这段代码可以非常好的运行,不会有前向引用的错误:
>>> foo()
in foo() in bar()这段代码是正确的因为即使(在foo()中)对bar()进行的调用出现在bar()的定义之前,但foo()本身不是在bar()声明之前被调用的。换句话说,我们声明foo(),然后再声明bar(),接着调用foo(),但是到那时,bar()已经存在了,所以调用成功。
11.3.4.函数属性
我们稍后将对命名空间进行简短的讨论,尤其是与变量作用域的关系。这里我们只是想要指出python 名字空间的基本特征。
你可以获得每个pyhon 模块,类,和函数中任意的名字空间。你可以在模块foo 和bar 里都有名为x 的一个变量,,在将这两个模块导入你的程序后,仍然可以使用这两个变量。所以,即使在两个模块中使用了相同的变量名字,这也是安全的,因为句点属性标识对于两个模块意味了不同的命名空间,eg:
import foo, bar
print foo.x + bar.x函数属性是python 另外一个使用了句点属性标识并拥有名字空间的领域。
def foo():
'foo() -- properly created doc string'
def bar():
pass
bar.__doc__ = 'Oops, forgot the doc str above' # 当声明bar()时,用了句点属性标识来增加文档字串以及其他属性。
bar.version = 0.1我们可以接着任意地访问属性。下面是一个使用了交互解释器的例子。(你可能已经发现,用内建函数help()显示会比用__doc__属性更漂亮)
>>> help(foo)
Help on function foo in module __main__:
foo()
foo() -- properly created doc string
>>> print bar.version
0.1
>>> print foo.__doc__
foo() -- properly created doc string
>>> print bar.__doc__
Oops, forgot the doc str above我们仍然可以就像平常一样,在运行时刻访问它。然而你不能在函数的声明中访问属性。换句话说,在函数声明中没有'self‘这样的东西让你可以进行诸如__dict__['version'] = 0.1 的赋值。这是因为函数体还没有被创建,但之后你有了函数对象,就可以按我们在上面描述的那样方法来访问它的字典。
函数属性是在2.1 中添加到python 中的,你可以在PEP232 中阅读到更多相关信息。
11.3.5 内部/内嵌函数
在函数体内创建另外一个函数(对象)是完全合法的。这种函数叫做内部/内嵌函数。因为现在python 支持静态地嵌套域,内部函数实际上很有用的。
最明显的创造内部函数的方法是在外部函数的定义体内定义函数(用def 关键字),如在:
def foo():
def bar():
print 'bar() called'
print 'foo() called'
bar()
foo()
bar()运行:
foo() called bar() called
Traceback (most recent call last): File "inner.py", line 11, in ?
bar()
NameError: name 'bar' is not defined内部函数一个有趣的方面在于整个函数体都在外部函数的作用域之内。如果没有任何对bar()的外部引用,那么除了在函数体内,任何地方都不能对其进行调用,这就是在上述代码执行到最后你看到异常的原因
另外一个函数体内创建函数对象的方式是使用lambda 语句。如果内部函数的定义包含了在外部函数里定义的对象的引用(这个对象甚至可以是在外部函数之外),内部函数会变成被称为闭包(closure)的特别之物。在接下来的11.8.4 小节,我们将对闭包进行更多的学习。在下一小节中,我们将介绍装饰器,但是例子程序也包含了闭包的预览。
11.3.6 *函数(与方法)装饰器
装饰器背后的主要动机源自python面向对象编程。装饰器是在函数调用之上的修饰。这些修饰仅是当声明一个函数或者方法的时候,才会应用的额外调用。
装饰器的语法以@开头,接着是装饰器函数的名字和可选的参数。紧跟着装饰器声明的是被修饰的函数:
@decorator(dec_opt_args)
def func2Bdecorated(func_opt_args):装饰器背后的灵感是什么?当静态方法和类方法在2.2 时被加入到python 中的时候,实现方法很笨拙:
class MyClass(object):
def staticFoo():
staticFoo = staticmethod(staticFoo)在这个类的声明中,我们定义了叫staticFoo()的方法。现在因为打算让它成为静态方法,我们省去它的self 参数,而你会在12 章中看到,self 参数在标准的类方法中是必需的。接着用staticmethod()内建函数来将这个函数“转化“为静态方法,但是在def staticFoo()后跟着staticFoo = staticmethod (sta- ticFoo)显得有多么的臃肿。使用装饰器,你现在可以用如下代码替换掉上面的:
class MyClass(object):
@staticmethod
def staticFoo():此外,装饰器可以如函数调用一样“堆叠“起来,eg:
@deco2
@deco1
def func(arg1, arg2, ...):
pass这和创建一个组合函数是等价的。
def func(arg1, arg2, ...):
pass
func = deco2(deco1(func))函数组合用数学来定义就像这样: (g · f)(x) = g(f(x))。对于在python 中的一致性
@g
@f
def foo():......与foo=g(f(foo))相同
有参数和无参数的装饰器
什么时候使用带参数的装饰器。带参数的装饰器decomaker()
@decomaker(deco_args)
def foo():
pass
. . .需要自己返回以函数作为参数的装饰器。换句话说,decomaker()用deco_args 做了些事并返回函数对象,而该函数对象正是以foo 作为其参数的装饰器。简单的说来:
foo = decomaker(deco_args)(foo)这里有一个含有多个装饰器的例子,其中的一个装饰器带有一个参数
@deco1(deco_arg)
@deco2
def func(): pass
这等价于:
func = deco1(deco_arg)(deco2(func))下面我们会给出简单实用的脚本,该脚本中装饰器不带任何参数。那么什么是装饰器?
现在我们知道装饰器实际就是函数。我们也知道他们接受函数对象。但它们是怎样处理那些函数的呢?一般说来,当你包装一个函数的时候,你最终会调用它。最棒的是我们能在包装的环境下在合适的时机调用它。我们在执行函数之前,可以运行些预备代码,如post-morrem 分析,也可以在执行代码之后做些清理工作。所以当你看见一个装饰器函数的时候,很可能在里面找到这样一些代码,它定义了某个函数并在定义内的某处嵌入了对目标函数的调用或者至少一些引用。从本质上看,这些特征引入了java 开发者称呼之为AOP(面向方面编程)的概念。
你可以kao虑在装饰器中置入通用功能的代码来降低程序复杂度。例如,可以用装饰器来:
引入日志
增加计时逻辑来检测性能
给函数加入事务的能力
对于用python 创建企业级应用,支持装饰器的特性是非常重要的。
修饰符举例
让你开始真正地了解装饰器是如何工作的。这个例子通过显示函数执行的时间"装饰"了一个(没有用的)函数。这是一个"时戳装饰",与我们在16章讨论的时戳服务器非常相似。
(deco.py)这个装饰器(以及闭包)示范表明装饰器仅仅是用来“装饰“(或者修饰)函数的包装,返回一个修改后的函数对象,将其重新赋值原来的标识符,并永久失去对原始函数对象的访问。
from time import ctime, sleep
# 一个显示何时调用函数的时戳的装饰器
# 装饰器的返回值是一个“包装了”的函数
def tsfunc(func):
def wrappedFunc():
print ('[%s] %s() calld ' % (ctime(), func.__name__))
return func()
return wrappedFunc
@tsfunc
def foo():
pass
foo()
sleep(4)
for i in range(2):
sleep(1)
foo()运行脚本,我们得到如下输出:
[Sun Mar 19 22:50:28 2006] foo() called
[Sun Mar 19 22:50:33 2006] foo() called
[Sun Mar 19 22:50:34 2006] foo() called
你可以在python langugae reference, python2.4 中“What’s New in Python 2.4”的文档以及PEP 318 中来阅读更多关于装饰器的内容。
11.4 传递函数
函数是可以被引用的(访问或者以其他变量作为其别名),也作为参数传入函数,以及作为列表和字典等等容器对象的元素,函数有一个独一无二的特征使它同其他对象区分开来,那就是函数是可调用的。
举例来说,可以通过函数操作来调用他们。(在python 中有其他的可调用对象。更多信息,参见14 章)在以上的描述中,我们注意到可以用其他的变量来做作为函数的别名因为所有的对象都是通过引用来传递的,函数也不例外。当对一个变量赋值时,实际是将相同对象的引用赋值给这个变量。如果对象是函数的话,这个对象所有的别名都是可调用的。
>>> def foo():
... print 'in foo()'
...
>>> bar = foo
>>> bar()
in foo()稍微深入下我们引用的例子,我们甚至可以把函数作为参数传入其他函数来进行调用。
>>> def bar(argfunc):
... argfunc()
...
>>> bar(foo)
in foo()现在我们来研究下一个更加实际的例子,numconv.py,代码在例子11.3 中给出例11.3 传递和调用(内建)函数(numConv.py)
一个将函数作为参数传递,并在函数体内调用这些函数,更加实际的例子。
def convert(func, seq):
'conv. sequence of numbers to same type'
return [func(eachNum) for eachNum in seq]
myseq = (123, 45.67, -6.2e8, 999999999)
print (convert(int, myseq))
print (convert(float, myseq))运行:
[123, 45, -620000000, 999999999]
[123.0, 45.67, -620000000.0, 999999999.0]11.5 形式参数
python 函数的形参集合由在调用时要传入函数的所有参数组成,这参数与函数声明中的参数列表精确的配对。这些参数包括了所有必要参数(以正确的定位顺序来传入函数的),关键字参数(以顺序或者不按顺序传入,但是带有参数列表中曾定义过的关键字),以及所有含有默认值,函数调用时不必要指定的参数。(声明函数时创建的)局部命名空间为各个参数值,创建了一个名字。一旦函数开始执行,即能访问这个名字。
11.5.1 位置参数
这些我们都是熟悉的标准化参数。
位置参数必须以在被调用函数中定义的准确顺序来传递。另外,没有任何默认参数(见下一个部分)的话,传入函数(调用)的参数的精确的数目必须和声明的数字一致。作为一个普遍的规则,无论何时调用函数,都必须提供函数的所有位置参数。
可以不按位置地将关键字参数传入函数。
由于默认参数的特质,他们是函数调用的可选部分。
11.5.2.默认参数
如果没有值传递给那个参数,那么这个参数将取默认值。python 中用默认值声明变量的语法是所有的位置参数必须出现在任何一个默认参数之前。
def func(posargs, defarg1=dval1, defarg2=dval2,...):
"function_documentation_string"
function_body_suite让我们再看下关键字参数,用我们的老朋友net_conn()
def net_conn(host, port):
net_conn_suite读者应该还记得,如果命名了参数,这里可以不按顺序给出参数。我们可以做出如下(规则的)位置或者关键字参数调用:
net_conn('kappa', 8000)
net_conn(port=8080, host='chino')然而,如果我们将默认参数引入这个等式,情况就会不同,虽然上面的调用仍然有效:
def net_conn(host, port=80, stype='tcp'):
net_conn_suite我们已经扩展了调用net_conn()的方式。以下就是所有对net_conn()有效的调用
net_conn('phaze', 8000, 'udp') # no def args used
net_conn('kappa') # both def args used
net_conn('chino', stype='icmp') # use port def arg
net_conn(stype='udp', host='solo') # use port def arg
net_conn('deli', 8080) # use stype def arg
net_conn(port=81, host='chino') # use stype def arg在上面所有的例子中,我们发现什么是一直不变的?唯一的必须参数,host。host 没有默认值,所以他必须出现在所有对net_conn()的调用中。关键字参数已经被证明能给不按顺序的位置参数提供参数,结合默认参数,它们同样也能被用于跳过缺失参数,上面例子就是极好的证据。
默认函数对象参数举例
grabWeb.py 脚本,从互联网上抓取一个Web 页面并暂时储存到一个本地文件中用于分析的简单脚本。这类程序能用来测试web 站点页面的完整性或者能监测一个服务器的负载(通过测量可链接性或者下载速度)。process()函数可以做我们想要的任何事,表现出了无限种的用途。我们为这个练习选择的用法是显示从web 页面上获得的第一和最后的非空格行。
例子 抓取网页 这段脚本下载了一个web 页面(默认为本地的www 服务器)并显示了html 文件的第一个以及最后一个非空格行。由于download()函数的双默认参数允许用不同的urls 或者指定不同的处理函数来进行覆盖,灵活性得倒了提高。
from urllib import urlretrieve
def firstNonBlank(lines):
for eachLine in lines:
if not eachLine.strip():
continue
else:
return eachLine
def firstLast(webpage):
f = open(webpage)
lines = f.readlines()
f.close()
print (firstNonBlank(lines)),
lines.reverse()
print (firstNonBlank(lines)),
def download(url='http://www', process=firstLast):
try:
retval = urlretrieve(url)[0]
except IOError:
retval = None
if retval:
process(retval)
if __name__ == '__main__':
download()11.6 可变长度的参数
会有需要用函数处理可变数量参数的情况。这时可使用可变长度的参数列表。变长的参数在函数声明中不是显式命名的,因为参数的数目在运行时之前是未知的(甚至在运行的期间,每次函数调用的参数的数目也可能是不同的),这和常规参数(位置和默认)明显不同,常规参数都是在函数声明中命名的。由于函数调用提供了关键字以及非关键字两种参数类型,python 用两种方法来支持变长参数,在11.2.4 小节中,我们了解了在函数调用中使用*和**符号来指定元组和字典的元素作为非关键字以及关键字参数的方法。在这个部分中,我们将再次使用相同的符号,但是这次在函数的声明中,表示在函数调用时接收这样的参数。这语法允许函数接收在函数声明中定义的形参之外的参数。
11.6.1.非关键字可变长参数(元组)
当函数被调用的时候,所有的形参(必须的和默认的)都将值赋给了在函数声明中相对应的局部变量。剩下的非关键字参数按顺序插入到一个元组中便于访问。代表了在函数调用时,接受一个不定(非固定)数目的参数。
可变长的参数元组必须在位置和默认参数之后,带元组(或者非关键字可变长参数)的函数普遍的语法如下:
def function_name([formal_args,] *vargs_tuple):
"function_documentation_string"
function_body_suite星号操作符之后的形参将作为元组传递给函数,元组保存了所有传递给函数的"额外"的参数(匹配了所有位置和具名参数后剩余的)。如果没有给出额外的参数,元组为空。
只要在函数调用时给出不正确的函数参数数目,就会产生一个TypeError异常。通过末尾增加一个可变的参数列表变量,我们就能处理当超出数目的参数被传入函数的情形,因为所有的额外(非关键字)参数会被添加到变量参数元组。正如预料的那样,由于和位置参数必须放在关键字参数之前一样的原因,所有的形式参数必须先于非正式的参数之前出现。
def tupleVarArgs(arg1, arg2='defaultB', *theRest):
'display regular args and non-keyword variable args'
print 'formal arg 1:', arg1 print 'formal arg 2:', arg1
for eachXtrArg in theRest:
print 'another arg:', eachXtrArg我们现在调用这个函数来说明可变参数元组是如何工作的。
>>> tupleVarArgs('abc')
formal arg 1: abc
formal arg 2: defaultB
>>>
>>> tupleVarArgs(23, 4.56)
formal arg 1: 23
formal arg 2: 4.56
>>>
>>> tupleVarArgs('abc', 123, 'xyz', 456.789)
formal arg 1: abc
formal arg 2: 123
another arg: xyz
another arg: 456.78911.6.2.关键字变量参数(Dictionary)
在我们有不定数目的或者额外集合的关键字的情况中,参数被放入一个字典中,字典中键为参数名,值为相应的参数值。为什么一定要是字典呢?因为为每个参数-参数的名字和参数值--都是成对给出---用字典来保存这些参数自然就最适合不过了。这给出使用了变量参数字典来应对额外关键字参数的函数定义的语法:
def function_name([formal_args,][*vargst,] **vargsd):
function_documentation_string function_body_suite为了区分关键字参数和非关键字非正式参数,使用了双星号(**)。 **是被重载了的以便不与幂运算发生混淆。关键字变量参数应该为函数定义的最后一个参数,带**:
def dictVarArgs(arg1, arg2='defaultB', **theRest):
'display 2 regular args and keyword variable args'
print 'formal arg1:', arg1
print 'formal arg2:', arg2
for eachXtrArg in theRest.keys():
print 'Xtra arg %s: %s' % \ (eachXtrArg, str(theRest[eachXtrArg]))在解释器中执行这个代码,我们得到以下输出。
>>> dictVarArgs(1220, 740.0, c='grail')
formal arg1: 1220
formal arg2: 740.0
Xtra arg c: grail
>>>
>>> dictVarArgs(arg2='tales', c=123, d='poe', arg1='mystery')
formal arg1: mystery
formal arg2: tales
Xtra arg c: 123
Xtra arg d: poe
>>>
>>> dictVarArgs('one', d=10, e='zoo', men=('freud', 'gaudi'))
formal arg1: one
formal arg2: defaultB
Xtra arg men: ('freud', 'gaudi')
Xtra arg d: 10
Xtra arg e: zoo关键字和非关键字可变长参数都有可能用在同一个函数中,只要关键字字典是最后一个参数并且非关键字元组先于它之前出现,正如在如下例子中的一样:
def newfoo(arg1, arg2, *nkw, **kw):
display regular args and all variable args'
print 'arg1 is:', arg1 print 'arg2 is:', arg2
for eachNKW in nkw:
print 'additional non-keyword arg:', eachNKW
for eachKW in kw.keys():
print "additional keyword arg '%s': %s" % (eachKW, kw[eachKW])在解释器中调用我们的函数,我们得到如下的输出:
>>> newfoo('wolf', 3, 'projects', freud=90, gamble=96)
arg1 is: wolf arg2 is: 3
additional non-keyword arg: projects
additional keyword arg 'freud': 90
additional keyword arg 'gamble': 9611.6.3 调用带有可变长参数对象函数
接下来带着对函数接受变长参数的些许偏见,我们会向你展示更多那种语法的例子,注意看上节newfoo的调用和输出;
现在,我们将非关键字参数放在元组中将关键字参数放在字典中,而不是逐个列出变量参数:
>>> newfoo(2, 4, *(6, 8), **{'foo': 10, 'bar': 12})
arg1 is: 2
arg2 is: 4
additional non-keyword arg: 6
additional non-keyword arg: 8
additional keyword arg 'foo': 10
additional keyword arg 'bar': 12最终,我们将再另外进行一次调用,但是是在函数调用之外来创建我们的元组和字典。
>>> aTuple = (6, 7, 8)
>>> aDict = {'z': 9}
>>> newfoo(1, 2, 3, x=4, y=5, *aTuple, **aDict)
arg1 is: 1
arg2 is: 2
additional non-keyword arg: 3
additional non-keyword arg: 6
additional non-keyword arg: 7
additional non-keyword arg: 8
additional keyword arg 'z': 9
additional keyword arg 'x': 4
additional keyword arg 'y': 5下面演示了如何使用这些符号来把任意类型任意个数的参数传递给任意函数对象。
函数式编程举例
函数式编程的另外一个有用的应用出现在调试和性能测量方面上。你正在使用需要每夜都被完全测试或需要给对潜在改善进行多次迭代计时的函数来工作。你所要做的就是创建一个设置测试环境的诊断函数,然后对有疑问的地方,调用函数。因为系统应该是灵活的, 所以想testee 函数作为参数传入。那么这样的函数对,timeit()和testit(),可能会对如今的软件开发者有帮助。
我们现在将展示这样的一个testit()函数的例子的源代码testit.py;该模块给函数提供了一个执行测试的环境。testit()函数使用了一个函数和一些参数,然后在异常处理的监控下,用给定的参数调用了那个函数。如果函数成功的完成, 会返回True 和函数的返回值给调用者。任何的失败都会导致False 和异常的原因一同被返回。
def testit(func, *nkwargs, **kwargs):
try:
retval = func(*nkwargs, **kwargs)
result = (True, retval)
except Exception as diag:
result = (False, str(diag))
return result
def test():
funcs = (int, float)
vals = (1234, 12.34, '1234', '12.34')
for eachFunc in funcs:
print ('_' * 20)
for eachVal in vals:
retval = testit(eachFunc, eachVal)
if retval[0]:
print ('%s(%s) =' % (eachFunc.__name__, eachVal), retval[1])
else:
print ('%s(%s) = FAILED:' % (eachFunc.__name__, eachVal), retval[1])
if __name__ == "__main__":
test()运行
____________________
int(1234) = 1234
int(12.34) = 12
int(1234) = 1234
int(12.34) = FAILED: invalid literal for int() with base 10: '12.34'
____________________
float(1234) = 1234.0
float(12.34) = 12.34
float(1234) = 1234.0
float(12.34) = 12.3411.7 函数式编程
Python 不是也不大可能会成为一种函数式编程语言,但支持许多有价值的函数式编程语言构建。也有些表现得像函数式编程机制但从传统上也不能被认为是函数式编程语言的构建。Python提供以4 种内建函数和lambda 表达式的形式出现
11.7.1.匿名函数与lambda
python 允许用lambda关键字创造匿名函数。匿名是因为不需要以标准的方式来声明,比如说,标准方式需要使用def 语句(除非将lambda表达式赋值给一个局部变量,lambda表达式也不会在任何的名字空间内创建名字.)。
lambda作为函数,它们也能有参数。一个完整的lambda“语句”代表了一个表达式,这个表达式的定义体必须和声明放在同一行:
lambda [arg1[, arg2, ... argN]]: expression参数是可选的,如果使用的参数话,参数通常也是表达式的一部分。
核心笔记:lambda 表达式返回可调用的函数对象。
(1)用合适的表达式调用一个lambda 生成一个可以像其他函数一样使用的函数对象;
(2)lambda表达式可被传入给其他函数,用额外的引用别名化,作为容器对象以及作为可调用的对象被调用(如果需要的话,可以带参数),当被调用的时候,如果给定相同的参数的话,这些对象会生成一个和相同表达式等价的结果。lambda表达式和那些返回等价表达式计算值相同的函数是不能区分的。
先复习下单行语句:
def true():
return True我们重写下我们的true()函数以使其看其来像如下的东西:
def true(): return True我们的true()函数,使用lambda 的等价表达式(没有参数,返回一个True)为:
lambda :True我们仅仅是这样用,或者我们需要在某些地方用它进行赋值吗?一个lambda 函数自己就是无目地服务,正如在这里看到的:
>>> lambda :True
<function <lambda> at f09ba0>在上面的例子中,我们简单地用lambda 创建了一个函数(对象),但是既没有在任何地方保存它,也没有调用它。这个函数对象的引用计数在函数创建时被设置为True,但是因为没有引用保存下来,计数又回到零,然后被垃圾回收掉。为了保留住这个对象,我们将它保存到一个变量中,以后可以随时调用。
>>> true = lambda :True
>>> true()
True可以把一个如列表和元组的数据结构传递给lambda表达式,其中,基于一些输入标准,我们可以选择哪些函数可以执行,以及参数应该是什么。
我们现在来设计一个带2 个数字或者字符串参数,返回数字之和或者已拼接的字符串的函数:
def add(x, y): return x + y
等价于:lambda x, y: x + y默认以及可变的参数也是允许的,如下例所示:
def usuallyAdd2(x, y=2): return x+y
lambda x, y=2: x+y
def showAllAsTuple(*z): return z
lambda *z: z我们现在将通过演示如何能在解释器中尝试这种做法:
>>> a = lambda x, y=2: x + y
>>> a(3)
5
>>> a(3,5)
8
>>> a(0)
2
>>> a(0,9)
9
>>> b = lambda *z: z
>>> b(23, 'zyx')
(23, 'zyx')
>>> b(42)
(42,)11.7.2 内建函数apply()、filter()、map()、reduce()
看看apply(),filter(), map(), 以及reduce()内建函数并给出一些如何使用它们的例子。这些函数可以找到函数式编程的特征。lambda 函数很好的和使用了这些函数的应用程序结合起来,因为它们都带了一个可执行的函数对象,lambda 表达式提供了迅速创造这些函数的机制。

filter()
给定一个对象的序列和一个“过滤”函数,每个序列元素都通过这个过滤器进行筛选, 保留函数返回为真的的对象。filter函数为已知的序列的每个元素调用给定布尔函数。每个filter 返回的非零(true)值元素添加到一个列表中(确保你的函数确实返回一个真或假)。返回的对象是一个从原始队列中“过滤后”的队列。
如果我们想要用纯python 编写filter(),它或许就像这样:
def filter(bool_func, seq):
filtered_seq = []
for eachItem in seq:
if bool_func(eachItem):
filtered_seq.append(eachItem)
return filtered_seq我们下面展示在一个使用了filer()来获得任意奇数的简短列表的脚本。该脚本产生一个较大的随机数集合,然后过滤出所有的的偶数,留给我们一个需要的数据集。oddnogen.py 如下:
from random import randint
def odd(n):
return n % 2
allNums = []
for eachNum in range(9):
allNums.append(randint(1, 99))
print filter(odd, allNums)运行:
$ python oddnogen.py
[9, 33, 55, 65]
$ python oddnogen.py
[39, 77, 39, 71, 1]
$ python oddnogen.py
[23, 39, 9, 1, 63, 91]
$ python oddnogen.py
[41, 85, 93, 53, 3]在第二次浏览时,我们注意到odd()是非常的简单的以致能用一个lambda 表达式替换
from random import randint
allNums = []
for eachNum in range(9):
allNums.append(randint(1, 99))
print filter(lambda n: n%2, allNums)
Refactoring Pass 2我们已经提到list 综合使用如何能成为filter()合适的替代者,如下便是:
from random import randint
allNums = []
for eachNum in range(9):
allNums.append(randint(1, 99))
print [n for n in allNums if n%2]
Refactoring Pass 3我们通过整合另外的列表解析将我们最后的列表放在一起,来进一步简化我们的代码。正如你如下看到的一样, 由于列表解析灵活的语法,就不再需要一个暂时的变量了。
from random import randint as ri
print [n for n in [ri(1,99) for i in range(9)] if n%2]虽然比原来的长些, 但是这行扮演了该例子中核心部分的代码不再如其他人想的那么模糊不清。
map()
map()内建函数与filter()相似,因为它也能通过函数来处理序列。然而,不像filter(), map()将函数调用“映射”到每个序列的元素上,并返回一个含有所有返回值的列表。
在最简单的形式中,map()带一个函数和队列, 将函数作用在序列的每个元素上, 然后创建由每次函数应用组成的返回值列表。所以如果你的映射函数是给每个进入的数字加2,并且你将这个函数和一个数字的列表传给map(),返回的结果列表是和原始集合相同的数字集合,但是每个数字都加了2.
# 若自行实现,可能如下:
def map(func, seq):
mapped_seq = []
for eachItem in seq:
mapped_seq.append(func(eachItem))
return mapped_seq我们可以列举一些简短的lambda 函数来展示如何用map()处理实际数据:
>>> map((lambda x: x+2), [0, 1, 2, 3, 4, 5])
[2, 3, 4, 5, 6, 7]
>>>
>>> map(lambda x: x**2, range(6))
[0, 1, 4, 9, 16, 25]
>>> [x+2 for x in range(6)]
[2, 3, 4, 5, 6, 7]
>>>
>>>[x**2 for x in range(6)]
[0, 1, 4, 9, 16, 25]形式更一般的map()能以多个序列作为其输入。如果是这种情况, 那么map()会并行地迭代每个序列。在第一次调用时, map()会将每个序列的第一个元素捆绑到一个元组中, 将func 函数作用到map()上, 当map()已经完成执行的时候,并将元组的结果返回到mapped_seq 映射的,最终以整体返回的序列上。如果我们用带有每个序列有N 个对象的M 个序列来的map(),我们前面的图表会转变成如图11-3 中展示的图表那样。
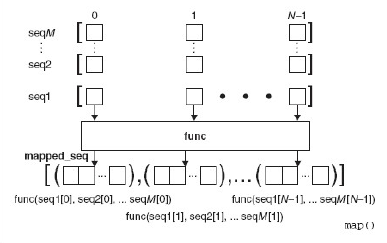
这里有些使用带多个序列的map()的例子
>>> map(lambda x, y: x + y, [1,3,5], [2,4,6])
[3, 7, 11]
>>> map(lambda x, y: (x+y, x-y), [1,3,5], [2,4,6])
[(3, -1), (7, -1), (11, -1)]
>>> map(None, [1,3,5], [2,4,6])
[(1, 2), (3, 4), (5, 6)]上面最后的例子使用了map()和一个为None 的函数对象来将不相关的序列归并在一起。这种思想在一个新的内建函数,zip,被加进来之前的python2.0 是很普遍的。而zip 是这样做的:
>>> zip([1,3,5], [2,4,6])
[(1, 2), (3, 4), (5, 6)]reduce()
reduce 使用了一个二元函数(一个接收带两个值作为输入,进行了一些计算然后返回一个值作为输出),一个序列,和一个可选的初始化器,卓有成效地将那个列表的内容“减少”为一个单一的值,如同它的名字一样。
它通过取出序列的头两个元素,将他们传入二元函数来获得一个单一的值来实现。然后又用这个值和序列的下一个元素来获得又一个值,然后继续直到整个序列的内容都遍历完毕以及最后的值会被计算出来为止。
你可以尝试去形象化reduce 如下面的等同的例子:
reduce(func, [1, 2, 3]) = func(func(1, 2), 3)有些人认为reduce()合适的函数式使用每次只需要仅需要一个元素。在上面一开始的迭代中,我们拿了两个元素因为我们没有从先前的值(因为我们没有任何先前的值)中获得的一个“结果”。这就是可选初始化器出现的地方(参见下面的init 变量)。如果给定初始化器, 那么一开始的迭代会用初始化器和一个序列的元素来进行,接着和正常的一样进行。
如果我们想要试着用纯python 实现reduce(), 它可能会是这样:
if init is None:
res = lseq.pop(0) # no
else:
res = init # yes
for item in lseq: # reduce sequence
res = bin_func(res, item) # apply function
return res # return result从概念上说这可能4 个中最难的一个, 所以我们应该再次向你演示一个例子以及一个函数式图表(见图11-4)。reduce()的“hello world”是其一个简单加法函数的应用或在这章前面看到的与之等价的lamda
? def mySum(x,y): return x+y
? lambda x,y: x+y
给定一个列表, 我们可以简单地创建一个循环, 迭代地遍历这个列表,再将现在元素加到前面元素的累加和上,最后当循环结束就能获得所有值的总和。
>>> def mySum(x,y): return x+y
>>> allNums = range(5) # [0, 1, 2, 3, 4]
>>> total = 0
图11-4 reduce()内建函数是如何工作的。
>>> for eachNum in allNums:
... total = mySum(total, eachNum)
...
>>> print 'the total is:', total the total is: 10
使用lambda 和reduce(),我们可以以一行代码做出相同的事情。
>>> print 'the total is:', reduce((lambda x,y: x+y), range(5))
the total is: 10
给出了上面的输入,reduce()函数运行了如下的算术操作。
((((0 + 1) + 2) + 3) + 4) => 10
用list 的头两个元素(0,1),调用mySum()来得到1,然后用现在的结果和下一个元素2 来再次调用mySum(),再从这次调用中获得结果,与下面的元素3 配对然后调用mySum(),最终拿整个前面的求和和4 来调用mySum()得到10,10 即为最终的返回值。
11.7.3 偏函数应用
currying 的概念将函数式编程的概念和默认参数以及可变参数结合在一起。一个带n 个参数,curried 的函数固化第一个参数为固定参数,并返回另一个带n-1 个参数函数对象,分别类似于LISP的原始函数car 和cdr 的行为。Currying 能泛化成为偏函数应用(PFA), 这种函数将任意数量(顺序)参数的函数转化成另一个带剩余参数的函数对象。
在某种程度上,这似乎和不提供参数,就会使用默认参数情形相似。 在PFA 的例子中, 参数不需要调用函数的默认值,只需明确的调用集合。你可以有很多的偏函数调用,每个都能用不同的参数传给函数,这便是不能使用默认参数的原因。这个特征是在python2.5 的时候被引入的,通过functools 模块能很好的给用户调用。
简单的函数式例子
我们来使用下两个简单的函数add()和mul(), 两者都来自operator 模块。经常想要给数字加一或者乘以100,除了大量的,如add(1,foo),add(1,bar),mul(100, foo), mul(100, bar)般的调用,拥有已存在的并使函数调用简化的函数不是一件很美妙的事吗?举例来说,add1(foo), add1(bar),mul100(foo),mul100(bar)但是却不用去实现函数add1()和mul100()?用PFAs 就可以这样做。可以通过使用functional模块中的partial()函数来创建PFA:
>>> from operator import add, mul
>>> from functools import partial
>>> add1 = partial(add, 1) # add1(x) == add(1, x)
>>> mul100 = partial(mul, 100) # mul100(x) == mul(100, x)
>>> add1(10)
11
>>> add1(1)
2
>>> mul100(10)
1000
>>> mul100(500)
50000这个例子或许不能让你看到PFAs 的威力,但是我们不得不从从某个地方开始。当调用带许多参数的函数的时候,PFAs 是最好的方法。使用带关键字参数的PFAs 也是较简单的, 因为能显示给出特定的参数,要么作为curried 参数,要么作为那些更多在运行时刻传入的变量, 并且我们不需担心顺序。下面的一个例子:将二进制(作为字符串)转换成为整数。
>>> baseTwo = partial(int, base=2)
>>> baseTwo.__doc__ = 'Convert base 2 string to an int.'
>>> baseTwo('10010')
18这个例子使用了int()内建函数并将base 固定为2 来指定二进制字符串转化。现在我们没有多次用相同的第二参数(2)来调用int(),比如('10010', 2),相反,可以只用带一个参数的新baseTwo()函数。接着给新的函数加入了新的文档,这是很好的风格。注意:需要关键字参数base,如果你创建了不带base 关键字的偏函数,比如, baseTwo- BAD = partial(int, 2),这可能会让参数以错误的顺序传入int(),因为固定参数的总是放在运行时刻参数的左边, 比如baseTwoBAD(x) == int(2, x)。如果你调用它, 它会将2 作为需要转化的数字,base 作为'10010'来传入,接着产生一个异常:
>>> baseTwoBAD = partial(int, 2)
>>> baseTwoBAD('10010')
Traceback (most recent call last): File "<stdin>", line 1, in <module>
TypeError: an integer is required由于关键字放置在恰当的位置, 顺序就得固定下来,因为,如你所知,关键字参数总是出现在形参之后, 所以baseTwo(x) == int(x, base=2).
简单GUI 类的例子。
PFAs 也扩展到所有可调用的东西,如类和方法。一个使用PFAs 的优秀的例子是提供了“部分gui 模范化”。GUI 小部件通常有很多的参数,如文本,长度,最大尺寸, 背景和前景色,活动或者非活动,等等。如果想要固定其中的一些参数, 如让所有的文本标签为蓝底白字, 你可以准确地以PFAs 的方式,自定义为相似对象的伪模板。
例 11.6 偏函数应用GUI (ppfaGUI.py)这是较有用的偏函数应用的例子,或者更准确的说,“部分类实例化” 。。。。为什么呢?
1 #!/usr/bin/env python
2
3 from functools import partial
4 import Tkinter
5
6 root = Tkinter.Tk()
7 MyButton = partial(Tkinter.Button, root,
8 fg='white', bg='blue')
9 b1 = MyButton(text='Button 1')
10 b2 = MyButton(text='Button 2')
11 qb = MyButton(text='QUIT', bg='red',
12 command=root.quit)
13 b1.pack()
14 b2.pack()
15 qb.pack(fill=Tkinter.X, expand=True)
16 root.title('PFAs!')
17 root.mainloop()
在7-8 行,我们给Tkinter.Button 创建了"部分类实例化器”(因为那便是它的名字,而不是偏函数),固定好父类的窗口参数然后是前景色和背景色。我们创建了两个按钮b1 和b2 来与模板匹配,只让文本标签唯一。quit 按钮(11-12 行)是稍微自定义过的,带有不同的背景色(红色, 覆盖了默认的蓝色)并配置了一个回调的函数,当按钮被按下的时候,关闭窗口。(另外的的两个按钮没有函数,当他们被按下的的时候)
没有MyButton“模板”的话,你每次会不得不使用“完全”的语法(因为你仍然没有给全参数,由于有大量你不传入的,含有默认]值的参数)
b1 = Tkinter.Button(root, fg='white', bg='blue', text='Button 1') b2 =
Tkinter.Button(root, fg='white', bg='blue', text='Button 2') qb = Tkinter.Button(root,
fg='white', text='QUIT', bg='red',
command=root.quit)
这就一个简单的GUI 的截图:
当你的代码可以变得更紧凑和易读的时候,为什么要还有重复的做令人心烦的事?你能在18 张章找到更多关于GUI 编程的资料, 在那我们着重描写了一个使用PFAs 的例子。从你迄今为止看到的内容中,可以发现,在以更函数化编程环境提供默认值方面,PFA 带有模板以及“style-sheeting”的感觉。
你可以在Python Library Reference,“What’s New in Python 2.5”文档和指定的PEP309里,关于functools 模块的文档中阅读到更多关于pfa 的资料。
11.8 变量作用域
标识符的作用域:为其声明在程序里的可应用范围, 或者说变量可见性。变量可以是局部域或者全局域。
11.8.1 全局变量与局部变量
定义在函数内的变量有局部作用域,在一个模块中最高级别的变量有全局作用域。
“声明适用的程序的范围被称为声明的作用域。在一个过程中,如果名字在过程的声明之内,它的出现即为过程的局部变量;否则的话,出现即为非局部的“全局变量的一个特征是除非被删除掉,否则它们的存活到脚本运行结束,且对于所有的函数,他们的值都是可以被访问的,然而局部变量,就像它们存放的栈,暂时地存在,仅仅只依赖于定义它们的函数现阶段是否处于活动。当一个函数调用出现时,其局部变量就进入声明它们的作用域。在那一刻,一个新的局部变量名为那个对象创建了,一旦函数完成,框架被释放,变量将会离开作用域。"
global_str = 'foo'
def foo():
local_str = 'bar'
return global_str + local_strfoo()函数可以对全局和局部变量进行访问,而代码的主体部分只能访问全局变量。
核心笔记:搜索标识符(aka 变量,名字,等等)
搜索一个标识符的时候,python 先从局部作用域开始搜索。如果在局部作用域内没有找到那个名字,会在全局域找到这个变量否则抛出NameError 异常。
一个变量的作用域和它寄住的名字空间相关。我们会在12 章正式介绍名字空间;对于现在只能说子空间仅仅是将名字映射到对象的命名领域,现在使用的变量名字虚拟集合。作用域的概念和用于找到变量的名字空间搜索顺序相关。当一个函数执行的时候,所有在局部命名空间的名字都在局部作用域内。那就是当查找一个变量的时候,第一个被搜索的名字空间。如果没有在那找到变量的话,那么就可能找到同名的全局变量。这些变量存储(搜索)在一个全局以及内建的名字空间。
仅仅通过创建一个局部变量来“隐藏“或者覆盖一个全局变量是有可能的。回想一下,局部名字空间是首先被搜索的,存在于其局部作用域。如果找到一个名字,搜索就不会继续去寻找一个全局域的变量,所以在全局或者内建的名字空间内,可以覆盖任何匹配的名字。
同样,当使用全局变量同名的局部变量的时候要小心。如果在赋予局部变量值之前,你在函数中(为了访问这个全局变量)使用了这样的名字,你将会得到一个异常(NAMEERROR 或者 Unbound-LocalError),而这取决于你使用的python 版本。
11.8.2. globa 语句
如果将全局变量的名字声明在一个函数体内的时候,全局变量的名字能被局部变量给覆盖掉。这里有另外的例子,与第一个相似,但是该变量的全局和局部的特性就不是那么清晰了。
def foo():
print "\ncalling foo()..."
bar = 200
print "in foo(), bar is", bar
bar = 100
print "in __main__, bar is", bar foo()
print "\nin __main__, bar is (still)", bar得到如下输出:
in __main__, bar is 100
calling foo()...
in foo(), bar is 200
in __main__, bar is (still) 100为了明确地引用一个已命名的全局变量,必须使用global 语句。global 的语法如下:
global var1[, var2[, ... varN]]]修改上面的例子,可以更新我们代码,这样我们便可以用全局版本的is_this_global 而无须创建一个新的局部变量。
>>> is_this_global = 'xyz'
>>> def foo():
... global is_this_global
... this_is_local = 'abc'
... is_this_global = 'def'
... print this_is_local + is_this_global
...
>>> foo()
abcdef
>>> print is_this_global
def11.8.3.作用域的数字
python 从句法上支持多个函数嵌套级别,就如在python2.1 中的,匹配静态嵌套的作用域。然而,在2.1 至前的版本中,最多为两个作用域:一个函数的局部作用域和全局作用域。虽然存在多个函数的嵌涛,但你不能访问超过两个作用域。
def foo():
m = 3
def bar():
n = 4
print m + n
print m
bar()虽然这代码在今天能完美的运行....
>>> foo()
3
7. . .在python2.1 之前执行它将会产生错误。
>>> foo()
Traceback (innermost last):
File "<stdin>", line 1, in ?
File "<stdin>", line 7, in foo
File "<stdin>", line 5, in bar
NameError: m在函数bar()内访问foo()的局部变量m 是非法的,因为m 是声明为foo()的局部变量。从bar()中可访问唯一的作用域为局部作用域和全局作用域。foo()的局部作用域没有包含在上面两个作用域的列表中。注意'print m'语句的输出成功了,而而对bar()的函数调用却失败了。幸运的是,由于python 的现有嵌套作用语规则,今天就不存在这个错误了。
11.8.4 闭包
由于python 的静态嵌套域,定义内部函数变得很有用处。下面将着重讨论作用域和lambda。
如果在一个内部函数里,对在外部作用域(但不是在全局作用域)的变量进行引用,那么内部函数就被认为是closure;
定义在外部函数内的但由内部函数引用或者使用的变量被称为自由变量;
closures 在函数式编程中是一个重要的概念,Scheme 和Haskell 便是函数式编程中两种。Closures 从句法上看很简单(和内部函数一样简单)但是仍然很有威力。
闭包将内部函数自己的代码和作用域以及外部函数的作用结合起来。闭包的词法变量不属于全局名字空间域或者局部的--而属于其他的名字空间,带着“流浪"的作用域。(注意这不同于对象,因为那些变量是存活在一个对象的名字空间但闭包变量存活在一个函数的名字空间和作用域)
那么为什么你会想要用closues?
Closurs 对于安装计算,隐藏状态,以及在函数对象和作用域中随意地切换是很有用的。closurs在GUI 或者在很多API 支持回调函数的事件驱动编程中是很有些用处的。以绝对相同的方式,应用于获取数据库行和处理数据。回调就是函数。闭包也是函数,但是他们能携带一些额外的作用域。
它们仅仅是带了额外特征的函数……另外的作用域。
你可能会觉得闭包的使用和这章先前介绍的偏函数应用非常的相似,但是与闭包的使用相比,PFA 更像是currying, 因为闭包和函数调用没多少相关,而是关于使用定义在其他作用域的变量。
简单的闭包的例子
下面是使用闭包简单的例子。模拟一个计数器。
def counter(start_at=0):
count = [start_at]
def incr():
count[0] += 1
return count[0]
return incrcounter()做的唯一一件事就是接受一个初始化的的值来开始计数,并将该值赋给列表count 唯一一个成员。定义一个incr()的内部函数,通过在内部使用变量count,我们创建了一个闭包因为它现在携带了整个counter()作用域。incr()增加了正在运行的count 然后返回它。然后最后的魔法就是counter()返回一个incr,一个(可调用的)函数对象。运行将得到如下的输出---------注意这看起来和实例化一个counter 对象并执行这个实例有多么相似:
>>> count = counter(5)
>>> print count()
6
>>> print count()
7
>>> count2 = counter(100)
>>> print count2()
101
>>> print count()
8有点不同的是我们能够做些原来需要我们写一个类做的事,并且不仅仅是要写,而且必需覆盖掉这个类的__call__()特别方法来使他的实例可调用。这里我们能够使用一对函数来做这事。
现在,在很多情况下,类是最适合使用的。闭包更适合需要一个必需有自己的作用域的回调函数情况,尤其是回调函数是很小巧而且简单的,通常也很聪明。跟平常一样,如果你使用了闭包,对你的代码进行注释或者用文档字符串来解释你正做的事是很不错的主意
追踪闭包词法的变量
下面两个部分包含了给高级读者的材料……如果你愿意的话,你可以跳过去。我们将讨论如何能使用函数的func_closure 属性来追踪自由变量。这里有个显示追踪的代码片断。如果我们运行这段代码,将得到如下输入:
f2 closure vars: ['<cell at 0x5ee30: int object at0x200377c>']
f3 closure vars: ['<cell at 0x5ee90: int object at0x2003770>', '<cell at 0x5ee30: int object at0x200377c>']
<int 'w' id=0x2003788 val=1>
<int 'x' id=0x200377c val=2>
<int 'y' id=0x2003770 val=3>
<int 'z' id=0x2003764 val=4>
例子11.7 追踪闭包变量(closureVars.py)
这个例子说明了如何能通过使用函数的func_closure 属性来追踪闭包变量
1 #!/usr/bin/env python
2
3 output = '<int %r id=%#0x val=%d>'
4 w = x = y = z = 1
5
6 def f1():
7 x = y = z = 2
8
9 def f2():
10 y = z = 3
11
12 def f3():
13 z = 4
14 print output % ('w', id(w), w)
15 print output % ('x', id(x), x)
16 print output % ('y', id(y), y)
17 print output % ('z', id(z), z)
18
19 clo = f3.func_closure
20 if clo:
21 print "f3 closure vars:", [str(c) for c in clo]
22 else:
23 print "no f3 closure vars"
24 f3()
25
26 clo = f2.func_closure
27 if clo:
28 print "f2 closure vars:", [str(c) for c in clo]
29 else:
30 print "no f2 closure vars"
31 f2()
32
33 clo = f1.func_closure
34 if clo:
35 print "f1 closure vars:", [str(c) for c in clo]
36 else:
37 print "no f1 closure vars"
38 f1()
逐行解释
Lines 1–4
这段脚本由创建模板来输出一个变量开始:它的名字,ID,以及值,然后设置变量w,x,y 和z。
Edit By Vheavens
Edit By Vheavens
我们定义了模板,这样便不需要多次拷贝相同输出格式的字符串
Lines 6–9, 26–31
f1()函数的定义包括创建一个局部变量x,y 和z,以及一个内部函数f2()的定义。(注意所有的
局部变量遮蔽或者隐藏了对他们同名的全局变量的访问)。如果f2()使用了任何的定义在f1()作用
域的变量,比如说,非全局的和非f2()的局部域的,那么它们便是自由变量,将会被f1.func_closure
追踪到。
Lines 9–10, 19–24
这几行实际上是对f1()的拷贝,对f2()做相同的事,定义了局部变量y 和z,以及对一个内部
函数f3().此外,这里的局部变量会遮蔽全局以及那些在中间局部化作用域的变量,比如,f1()的。
如果对于f3()有任何的自由变量,他们会在这里显示出来。
毫无疑问,你会注意到对自由变量的引用是存储在单元对象里,或者简单的说,单元。这些东
西是什么呢?单元是在作用域结束后使自由变量的引用存活的一种基础方法。
举例来说,我们假设函数f3()已经被传入到其他一些函数,这样便可在稍后,甚至是f2()完成
之后,调用它。你不想要让f2()的栈出现,因为即使我们仅仅在乎f3()使用的自由变量,栈也会让
所有的f2()'s 的变量保持存活。单元维持住自由变量以便f2()的剩余部分能被释放掉。
Lines 12–17
这个部分描绘了f3()的定义,创建一个局部的变量z。接着显示w,x,y,z,这4 个变量从最内
部作用域逐步向外的追踪到的。在f3(), f2(), 或者 f1()中都是找不到变量w 的,所以,这是个全
局变量。在f3()或者f2()中,找不到变量x,所以来自f1()的闭包变量。相似地,y 是一个来自f2()
的闭包变量。最后,z 是f3()的局部变量。
Lines 33–38
main()中剩余的部分尝试去显示f1()的闭包变量,但是什么都不会发生因为在全局域和f1()的
作用域之间没有任何的作用域---没有f1()可以借用的作用域,因此不会创建闭包---所以第34 行的
条件表达式永远不会求得True。这里的这段代码仅仅是有修饰的目的。
*高级闭包和装饰器的例子
回到11.3.6 部分,我们看到了一个使用闭包和装饰器的简单例子,deco.py。接下来就是稍微
高级点的例子,来给你演示闭包的真正的威力。应用程序“logs"函数调用。用户选择是要在函数调
用之前或者之后,把函数调用写入日志。如果选择贴日志,执行时间也会显示出来。
例子11.8 用闭包将函数调用写入日至。
Edit By Vheavens
Edit By Vheavens
这个例子演示了带参数的装饰器,该参数最终决定哪一个闭包会被用的。这也是闭包的威力的
特征。
1 #!/usr/bin/env python
2
3 from time import time
4
5 def logged(when):
6 def log(f, *args, **kargs):
7 print '''Called:
8 function: %s
9 args: %r
10 kargs: %r''' % (f, args, kargs)
11
12 def pre_logged(f):
13 def wrapper(*args, **kargs):
14 log(f, *args, **kargs)
15 return f(*args, **kargs)
16 return wrapper
17
18 def post_logged(f):
19 def wrapper(*args, **kargs):
20 now = time()
21 try:
22 return f(*args, **kargs)
23 finally:
24 log(f, *args, **kargs)
25 print "time delta: %s" % (time()-now)
26 return wrapper
27
28 try:
29 return {"pre": pre_logged,
30 "post": post_logged}[when]
31 except KeyError, e:
32 raise ValueError(e), 'must be "pre" or "post"'
33
34 @logged("post")
35 def hello(name):
36 print "Hello,", name
37
Edit By Vheavens
Edit By Vheavens
38 hello("World!")
如果执行这个脚本,你将会得到和下面相似的输出:
$ funcLog.py Hello, World! Called:
function: <function hello at 0x555f0>
args: ('World!',)
kargs: {}
time delta: 0.000471115112305
逐行解释
Lines 5–10, 28–32
这段代码描绘了logged()函数的核心部分,其职责就是获得关于何时函数调用应该被写入日志
的用户请求。它应该在目标函数被调用前还是之后呢?logged()有3 个在它的定义体之内的助手内
部函数:log(),pre_logged()以及post_logged()。log()是实际上做日志写入的函数。它仅仅是显
示标准输出函数的名字和参数。如果你愿意在“真实的世界中”使用该函数的话,你很有可能会把
输出写到一个文件,数据库,或者标准错误(sys.stderr)。logged()在28-32 行的最后的部分实际
上是函数中非函数声明的最开始的代码。读取用户的选择然后返回*logged()函数中的一个便能用
目标函调用并包裹它。
Lines 12–26
pre_logged()和post_logged()都会包装目标函数然后根据它的名字写入日志,比如,当目标函
数已经执行之后,post_loggeed()会将函数调用写入日志,而pre_logged()则是在执行之前。
根据用户的选择,pre_logged()和post_logged()其中之一会被返回。当这个装饰器被调用的时
候,首先对装饰器和其参数进行求值,比如logged(什么时候)。然后返回的函数对象作为目标的函
数的参数进行调用,比如,pre_logged(f)或者post_logged(f).
两个*logged()函数都包括了一个名为wrapper()的闭包。当合适将其写入日志的时候,它便会
调用目标函数。这个函数返回了包裹好的函数对象,该对象随后将被重新赋值给原始的目标函数标
识符。
Lines 34–38
这段脚本的主要部分简单地装饰了hello()函数并将用修改过的函数对象一起执行它。当你在
38 行调用hello()的时候,它和你在35 行创建的函数对象已经不是一回事了。34 行的装饰器用特殊
的装饰将原始函数对象进行了包裹并返回这个包裹后的hello()版本。
11.8.5 作用域和lambda
Edit By Vheavens
Edit By Vheavens
python 的lambda 匿名函数遵循和标准函数一样的作用域规则。一个lambda 表达式定义了新的
作用域,就像函数定义,所以这个作用域除了局部lambda/函数,对于程序其他部分,该作用域都是
不能对进行访问的。
那些声明为函数局部变量的lambda 表达式在这个函数体内是可以访问的;然而,在lambda 语
句中的表达式有和函数相同的作用域。你也可以认为函数和一个lambda 表达式是同胞。
x = 10
def foo():
y = 5
bar = lambda :x+y
print bar()
我们现在知道这段代码能很好的运行。
>>> foo()
15
.....然而,我们必须在回顾下过去,去看下原来的python 版本中让代码运行必需的,一种极
其普遍的做法。在2.1 之前,我们将会得到一个错误,如同你在下面看到的一样,因为函数和lambda
都可访问全局变量,但两者都不能访问彼此的局部作用域。
>>> foo()
Traceback (innermost last):
File "<stdin>", line 1, in ?
File "<stdin>", line 4, in foo
File "<stdin>", line 3, in <lambda>
NameError: y
在上面的例子中,虽然lambda 表达式在foo()的局部作用域中创建,但他仅仅只能访问两个作
用域:它自己的局部作用域和全局的作用域(同样见Section 11.8.3).解决的方法是加入一个变量
作为默认参数,这样我们便能从外面的局部作用域传递一个变量到内部。在我们上面的例子中,我
们将lambda 的那一行修改成这样:
bar = lambda y=y: x+y
由于这个改变,程序能运行了。外部y 的值会作为一个参数传入,成为局部的y(lambda 函数
的局部变量)。你可以在所有你遇到的python 代码中看到这种普遍的做法;然而,这不表明存在改
变外部y 值的可能性,比如:
x = 10
Edit By Vheavens
Edit By Vheavens
def foo():
y = 5
bar = lambda y=y: x+y
print bar()
y = 8
print bar()
输出“完全错误“
>>> foo()
15
15
原因是外部y 的值被传入并在lambda 中“设置“,所以虽然其值在稍后改变了,但是lambda
的定义没有变。那时唯一替代的方案就是在lambda 表达式中加入对函数局部变量y 进行引用的局部
变量z。
x = 10
def foo():
y = 5
bar = lambda z:x+z
print bar(y)
y = 8
print bar(y)
为了获得正确的输出所有的一切都是必需的:
>>> foo()
15
18
这同样也不可取因为现在所有调用bar()的地方都必需改为传入一个变量。从python2.1 开始,
在没有任何修改的情况下整个程序都完美的运行。
x = 10
def foo():
y = 5
bar = lambda :x+y
print bar(y)
y = 8
Edit By Vheavens
Edit By Vheavens
print bar(y)
>>> foo()
15
18
正确的静态嵌套域(最后)被加入到python 中,你会不高兴吗?许多老前辈一定不会。你可以
在pep227 中阅读到更多关于这个重要改变的信息。
11.8.6 变量作用域和名字空间。
从我们在这章的学习中,我们可以看见任何时候,总有一个或者两个活动的作用域---不多,不
少。我们要么在只能访问全局作用域的模块的最高级,要么在一个我们能访问函数局部作用域和全
局作用域的函数体内执行。名字空间是怎么和作用域关联的呢?
从11.8.1 小节的核心笔记中,我们也可以发现,在任何给定的时间,存在两个或者三个的活动
的名字空间。从函数内部,局部作用域包围了局部名字空间,第一个搜寻名字的地方。如果名字存
在的话,那么将跳过检查全局作用域(全局和内建的名字空间)
我们现在将给出例子11.9,一个到处混合了作用域的脚本。我们将确定此程序输出作为练习留
给读者。
例子11.9 变量作用域(scope.py)
局部变量隐藏了全局变量,正如在这个变量作用程序中显示的。程序的输出会是什么呢?(以
及为什么)
1 #!/usr/bin/env python
2 j, k = 1, 2
3
4 def proc1():
5
6 j, k = 3, 4
7 print "j == %d and k == %d" % (j, k)
8 k = 5
9
10 def proc2():
11
Edit By Vheavens
Edit By Vheavens
12 j = 6
13 proc1()
14 print "j == %d and k == %d" % (j, k)
15
16
17 k = 7
18 proc1()
19 print "j == %d and k == %d" % (j, k)
20
21 j = 8
22 proc2()
23 print "j == %d and k == %d" % (j, k)
12.3.1 小节有更多关于名字空间和变量作用域的信息。
11.9 *递归
如果函数包含了对其自身的调用,该函数就是递归的。根据Aho, Sethi, 和Ullman, ”[a] 如
果一个新的调用能在相同过程中较早的调用结束之前开始,那么该过程就是递归的“
递归广泛地应用于语言识别和使用递归函数的数学应用中。在本文的早先部分,我们第一次看
到了我们定义的阶乘函数
N! ? factorial(N) ? 1 * 2 * 3 ... * N
我们可以用这种方式来看阶乘:
factorial(N) = N!
= N * (N-1)!
= N * (N-1) * (N-2)!
:
= N * (N-1) * (N-2) ... * 3 * 2 * 1
我们现在可以看到阶乘是递归的,因为factorial(N) = N* factorial(N-1).换句话说,为了获
得factorial(N)的值,需要计算factorial(N-1).而且,为了找到factorial(N-1),需要计算
factorial(N-2)等等。我们现在给出阶乘函数的递归版本。
def factorial(n):
if n == 0 or n == 1: # 0! = 1! = 1
return 1
Edit By Vheavens
Edit By Vheavens
else:
return (n * factorial(n-1))
11.10 生成器
早先在第8 章,我们讨论了迭代器背后的有效性以及它们如何给非序列对象一个像序列的迭代
器接口。这很容易明白因为他们仅仅只有一个方法,用于调用获得下个元素的next()
然而,除非你实现了一个迭代器的类,迭代器真正的并没有那么“聪明“。难道调用函数还没
有强大到在迭代中以某种方式生成下一个值并且返回和next()调用一样简单的东西?那就是生成器
的动机之一。
生成器的另外一个方面甚至更加强力.....协同程序的概念。协同程序是可以运行的独立函数调
用,可以暂停或者挂起,并从程序离开的地方继续或者重新开始。在有调用者和(被调用的)协同
程序也有通信。举例来说,当协同程序暂停的时候,我们能从其中获得一个中间的返回值,当调用
回到程序中时,能够传入额外或者改变了的参数,但仍能够从我们上次离开的地方继续,并且所有
状态完整。挂起返回出中间值并多次继续的协同程序被称为生成器,那就是python 的生成器真正在
做的事。在2.2 的时候,生成器被加入到python 中接着在2.3 中成为标准(见PEP255),虽然之前
足够强大,但是在Python2.5 的时候,得到了显著的提高(见pep342)。这些提升让生成器更加接
近一个完全的协同程序,因为允许值(和异常)能传回到一个继续的函数中。同样地,当等待一个
生成器的时候,生成器现在能返回控制。在调用的生成器能挂起(返回一个结果)之前,调用生成
器返回一个结果而不是阻塞等待那个结果返回。让我们更进一步观察生成器自顶向下的启动.
什么是python 式的生成器?从句法上讲,生成器是一个带yield 语句的函数。一个函数或者子
程序只返回一次,但一个生成器能暂停执行并返回一个中间的结果----那就是yield 语句的功能, 返
回一个值给调用者并暂停执行。当生成器的next()方法被调用的时候,它会准确地从离开地方继续
(当它返回[一个值以及]控制给调用者时)
当在2.2 生成器被加入的时候,因为它引入了一个新的关键字,yield,为了向下兼容,你需要
从_future_模块中导入generators 来使用生成器。从2.3 开始,当生成器成为标准的时候,这就不
再是必需的了。
11.10.1.简单的生成器特性
与迭代器相似,生成器以另外的方式来运作:当到达一个真正的返回或者函数结束没有更多的
值返回(当调用next()),一个StopIteration 异常就会抛出。这里有个例子,简单的生成器:
def simpleGen():
yield 1
yield '2 --> punch!'
Edit By Vheavens
Edit By Vheavens
现在我们有自己的生成器函数,让我们调用他来获得和保存一个生成器对象(以便我们能调用它
的next()方法从这个对象中获得连续的中间值)
>>> myG = simpleGen()
>>> myG.next()
1
>>> myG.next()
'2 --> punch!'
>>> myG.next()
Traceback (most recent call last):
File "", line 1, in ?
myG.next() StopIteration
由于python 的for 循环有next()调用和对StopIteration 的处理,使用一个for 循环而不是手
动迭代穿过一个生成器(或者那种事物的迭代器)总是要简洁漂亮得多。
>>> for eachItem in simpleGen():
... print eachItem
...
1
'2 --> punch!'
当然这是个挺傻的例子:为什么不对这使用真正的迭代器呢?许多动机源自能够迭代穿越序列,
而这需要函数威力而不是已经在某个序列中静态对象。
在接下来的例子中,我们将要创建一个带序列并从那个序列中返回一个随机元素的随机迭代器:
from random import randint
def randGen(aList):
while len(aList) > 0:
yield aList.pop(randint(0, len(aList)))
不同点在于每个返回的元素将从那个队列中消失,像一个list.pop()和random.choice()的结
合的归类。
>>> for item in randGen(['rock', 'paper', 'scissors']):
... print item
...
scissors
rock
Edit By Vheavens
Edit By Vheavens
paper
在接下来的几章中,当我们谈到面向对象编程的时候,将看见这个生成器较简单(和无限)的
版本作为类的迭代器。在几章前的8.12 小节中,我们讨论了生成器表达式的语法。使用这个语法返
回的对象是个生成器,但只以一个简单的形式,并允许使用过分简单化的列表解析的语法。
这些简单的例子应该让你有点明白生成器是如何工作的,但你或许会问。"在我的应用中,我可
以在哪使用生成器?“或许,你会问“最适合使用这些个强大的构建的地方在哪?“
使用生成器最好的地方就是当你正迭代穿越一个巨大的数据集合,而重复迭代这个数据集合是
一个很麻烦的事,比如一个巨大的磁盘文件,或者一个复杂的数据库查询。对于每行的数据,你希
望执行非元素的操作以及处理,但当正指向和迭代过它的时候,你“不想失去你的地盘“。
你想要抓取一块数据,比如,将它返回给调用者来处理以及可能的对(另外一个)数据库的插
入,接着你想要运行一次next()来获得下一块的数据,等等。状态在挂起和再继续的过程中是保留
了的,所以你会觉得很舒服有一个安全的处理数据的环境。没有生成器的话,你的程序代码很有可
能会有很长的函数,里面有一个很长的循环。当然,这仅仅是因为一个语言这样的特征不意味着你
需要用它。如果在你程序里没有明显适合的话,那就别增加多余的复杂性!当你遇到合适的情况时,
你便会知道什么时候生成器正是要使用的东西。
11.10.2 加强的生成器特性
在python2.5 中,一些加强特性加入到生成器中,所以除了next()来获得下个生成的值,用户
可以将值回送给生成器[send()],在生成器中抛出异常,以及要求生成器退出[close()]
由于双向的动作涉及到叫做 send()的代码来向生成器发送值(以及生成器返回的值发送回来),
现在yield 语句必须是一个表达式,因为当回到生成器中继续执行的时候,你或许正在接收一个进
入的对象。下面是一个展示了这些特性的,简单的例子。我们用简单的闭包例子,counter:
def counter(start_at=0):
count = start_at
while True:
val = (yield count) if val is not None:
count = val
else:
count += 1
生成器带有一个初始化的值,对每次对生成器[next()]调用以1 累加计数。用户已可以选择重
置这个值,如果他们非常想要用新的值来调用send()不是调用next()。这个生成器是永远运行的,
Edit By Vheavens
Edit By Vheavens
所以如果你想要终结它,调用close()方法。如果我们交互的运行这段代码,会得到如下输出:
>>> count = counter(5)
>>> count.next()
5
>>> count.next()
6
>>> count.send(9)
9
>>> count.next()
10
>>> count.close()
>>> count.next()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
StopIteration
你可以在PEP 的255 和342 中,以及给读者介绍python2.2 中新特性的linux 期刊文章中阅读
到更多关于生成器的资料:
http://www.linuxjournal.com/article/5597
11.11 练习















 703
703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









