







简介:《计算机专业英语实用教程》为计算机专业人士提供了在计算机领域的英语阅读、理解和交流能力提升的系统性学习资料。涵盖硬件、软件、编程语言、网络、数据库、操作系统、算法和信息技术伦理等多个计算机科学和技术主题。本教程不仅教授基础技术词汇,如硬件组件和操作系统,还深入讲解编程语言关键概念、网络协议、数据库管理和算法原理,并包含信息技术伦理的讨论。通过学习,读者将增强在全球计算机行业英语环境中进行有效交流的能力,并能更好地掌握计算机科学的前沿知识。 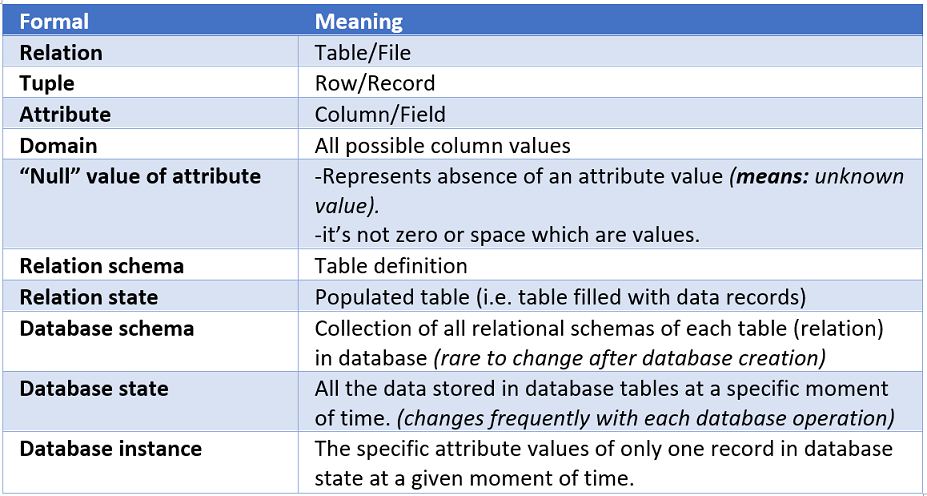
1. 计算机科学基础英语词汇
1.1 计算机科学基础词汇的重要性
在当今的全球信息化时代,掌握计算机科学基础英语词汇对于IT行业从业者来说至关重要。这些词汇不仅是进行专业阅读和交流的基础,还是理解最新技术动态和概念的钥匙。通过学习这些专业术语,从业者可以更有效地阅读国际资料、参加全球技术论坛,并且能够与来自不同文化背景的同行进行无障碍沟通。
1.2 常用术语举例
以下是一些基础的计算机科学术语及其含义:
- Algorithm (算法):是一组定义明确的指令,用于完成特定的任务或解决问题。
- Bug (错误):指软件程序中存在的问题或缺陷,导致程序无法正常工作。
- Compiler (编译器):一个程序,它将源代码转换成目标机器代码或虚拟机代码。
1.3 学习方法和资源推荐
学习计算机科学英语词汇,可以通过以下方法:
- 技术论坛和博客 :访问如Stack Overflow、GitHub等平台,阅读相关讨论和文档。
- 专业书籍 :查阅《Computer Science: An Overview》等基础教材来系统学习。
- 在线课程 :参加像edX、Coursera上的计算机科学入门课程。
掌握这些基础词汇,不仅可以提升个人的专业能力,还能帮助理解更高级的概念和术语,为深入学习和职业发展奠定坚实的基础。
2. 硬件和软件基础知识
2.1 计算机硬件相关英语词汇
2.1.1 计算机硬件组成部分
计算机硬件是构建计算机系统的基础,它包括多个核心组件,每个组件都有其特定的英语术语和功能。首先,处理器(Processor)是计算机的"大脑",它执行指令并进行计算。随机存取存储器(RAM)是用于暂存处理器正在处理数据的高速记忆体,它的速度直接影响着系统的运行效率。硬盘驱动器(HDD)或固态硬盘(SSD)负责长期存储数据。输入设备如键盘(Keyboard)和鼠标(Mouse),它们使用户能够与计算机互动。而输出设备如显示器(Monitor)和打印机(Printer),则将计算机处理的结果呈现给用户。
在了解这些基础硬件组件的同时,必须认识到它们的英文词汇在实际使用中扮演的角色。例如,在购买新硬件时,了解每个组件的英文表达可以帮助消费者更准确地获取所需产品信息。而在维护和升级计算机系统时,使用正确的硬件术语能够帮助技术人员更有效地沟通和解决问题。
2.1.2 硬件术语在实际使用中的应用
在实际使用中,硬件术语是不可或缺的,特别是在构建和维护计算机系统的过程中。比如,在安装一个新硬盘时,用户需要了解SATA(Serial Advanced Technology Attachment)接口和NVMe(Non-Volatile Memory Express)技术的区别。对于服务器管理员来说,掌握RAID(Redundant Array of Independent Disks)技术的原理和应用,能够帮助他们设计出既安全又高效的存储解决方案。
此外,硬件术语也常见于技术支持和故障排除的情景。在处理硬件相关问题时,技术支持人员可能需要询问客户关于电源供应器(Power Supply Unit, PSU)的规格信息,或是检查RAM模块(Random Access Memory Module)是否正确安装在内存插槽中。这些术语的正确使用有助于确定问题的根源,并迅速找到解决方案。
2.2 计算机软件相关英语词汇
2.2.1 常见软件的英语表达
软件是计算机的灵魂,它由程序和相关文档组成,指导计算机进行各种操作。在软件的英语词汇中,操作系统(Operating System, OS)是最基础的软件类型,它管理计算机硬件资源并提供用户接口。应用软件(Application Software)是指为完成特定任务而开发的程序,如办公软件(Office Software)、图像处理软件(Image Processing Software)等。
了解这些软件的英文表达对于国际交流和学习非常重要。例如,当你阅读来自国外的技术文章或者参加在线课程时,掌握这些词汇可以帮助你更容易理解所讨论的内容。同时,对于软件开发者而言,了解不同类型的软件的英文术语有助于在国际市场上推广他们的产品。
2.2.2 软件开发流程中的专业词汇
在软件开发流程中,涉及到大量专业术语。需求分析(Requirement Analysis)是确定软件所需完成任务的过程,它包括收集用户的需求并分析其可行性。设计阶段(Design Phase)涉及创建软件的架构和蓝图,定义系统的组件和它们如何相互作用。编码(Coding)是实际编写程序源代码的过程,通常会用到诸如Java、Python、C++等编程语言。测试(Testing)阶段是为了确保软件质量和稳定性,对软件进行各种测试,以找出并修复错误。
在使用这些专业词汇时,它们不仅帮助开发团队在内部沟通,而且也是团队与客户、利益相关者进行交流的基础。例如,在向客户解释项目的当前状态时,可能会提到“我们正在进行单元测试(Unit Testing)以确保各个独立模块的正确性”。这样的表述有助于让非技术背景的客户理解软件开发的复杂性和进度。
graph LR
A[需求分析] --> B[设计阶段]
B --> C[编码]
C --> D[测试]
D --> E[部署]
E --> F[维护]
以上流程图展示了软件开发中不同阶段的流程和依赖关系,从需求分析开始,经过设计、编码、测试、部署,最终到达维护阶段。这个过程是循环进行的,确保软件可以随着时间和用户需求的变化而更新和改进。
在下一章节,我们将深入探讨编程语言及其核心概念,理解如何通过编程语言实现计算机软硬件的互动,以及如何用代码来表达这些复杂的概念和技术。
3. 编程语言及其核心概念
3.1 编程语言概述
编程语言是计算机科学中的核心组成,它允许我们通过一种被计算机理解的语法来指挥计算机执行各种任务。理解编程语言的分类、特点、历史和趋势对于选择合适的工具解决实际问题至关重要。
3.1.1 编程语言的分类和特点
编程语言按设计范式大致分为命令式、声明式、函数式等。命令式语言,例如C和C++,侧重于通过明确指定计算机如何执行具体任务。声明式语言,如SQL和HTML,则更注重说明“是什么”,而不是“如何做”。
函数式语言,比如Haskell和Lisp,通过数学函数来表达计算逻辑,更加强调不可变性与函数的组合。
每种编程范式都有其独特的优势,适合不同的应用场景。例如,系统编程倾向于使用C和C++,因为它们能够提供底层硬件操作的精细控制;而快速原型开发或数据处理则更适合使用Python这类高级语言,因为其简洁的语法和强大的标准库。
3.1.2 编程语言的发展历史和趋势
计算机编程语言的发展始于1940年代的汇编语言,之后逐步演进至现今的多种编程语言。面向对象编程语言如Java和C#的兴起标志着编程范式的重大转变,而近年来,由于云计算和大数据技术的发展,函数式编程和响应式编程越来越受到关注。
未来的编程语言趋势倾向于更加强调安全性、并发性和表达性。这包括了使用更先进的类型系统来减少运行时错误,以及通过并行和分布式编程模型来提升系统性能。
3.2 核心编程概念
掌握编程的基础概念是成为高效程序员的基石。这些概念不仅适用于特定的编程语言,它们跨越了语言界限,为理解更复杂概念打下基础。
3.2.1 数据类型、变量和控制结构
数据类型定义了变量能够存储的数据种类,例如整数、浮点数、字符和字符串。变量则作为数据的容器,其值可以在程序运行时改变。控制结构,如if语句、循环等,提供了程序根据条件执行不同代码段的能力。
理解这些概念对于编写可靠的程序至关重要。例如,数据类型帮助程序员和编译器确保数据的正确使用,而控制结构则是程序逻辑决策的基础。在Python中,可以这样使用变量和基本控制结构:
# 定义一个整型变量
age = 25
# 使用if-else控制结构进行条件判断
if age >= 18:
print("You are an adult.")
else:
print("You are a minor.")
# 输出:You are an adult.
3.2.2 函数、类和对象的概念
函数是一段封装好的代码,它执行特定任务并可接受输入参数,还可以返回输出结果。面向对象编程中,类是创建对象的蓝图或模板,而对象是类的实例化。这三者是理解现代编程概念的关键。
通过函数可以实现代码复用并提高程序的模块化。面向对象编程中的类和对象则允许我们构建复杂的系统,模拟现实世界中的概念。Java中关于类和对象的定义如下:
// 定义一个名为Person的类
public class Person {
private String name;
private int age;
// 构造函数初始化Person对象
public Person(String name, int age) {
this.name = name;
this.age = age;
}
// 一个方法,用于描述Person对象
public String getDescription() {
return "Person named " + name + " who is " + age + " years old.";
}
}
// 创建Person类的实例
Person person = new Person("Alice", 30);
// 调用方法获取描述
String description = person.getDescription();
System.out.println(description); // 输出:Person named Alice who is 30 years old.
本章节讨论了编程语言的核心概念,深入到数据类型、变量、控制结构,以及函数、类和对象。这些知识构成了编程思维的基础,对于进一步学习更高级的编程技能和理解编程语言原理非常重要。随着技术的发展,这些概念也在不断地扩展和演进,为学习者提供了持续探索和挑战的领域。
4. 网络技术与协议
网络基础理论
网络的定义和组成
网络技术是现代信息技术的重要组成部分,它可以定义为通过传输介质,将独立的计算机和设备连接起来,以共享资源和信息。网络的组成包括硬件和软件两个基本要素,其中硬件指的是网络设备(如交换机、路由器、网卡、线缆等),而软件指的是网络操作系统、协议和应用软件等。
网络的核心组成通常包括:端点设备(如PC、服务器、智能手机等)、网络接口卡(NIC)、传输介质(双绞线、光纤、无线信道等)、网络互联设备(如交换机、路由器)以及协议和标准。端点设备通过网络接口卡连接到传输介质,再由传输介质连接到网络互联设备,最终形成一个可以相互通信的系统。
网络拓扑结构及其类型
网络拓扑结构指的是网络中各节点间的物理或逻辑布局。物理布局强调的是实体连接的方式,而逻辑布局关注的是数据流动和信息交换的路径。根据连接方式,网络拓扑可分为以下几种类型:
- 总线型拓扑(Bus Topology):所有节点共享同一传输介质,就像一条直线上串联了所有设备。信号会从源头传播到线路的每一端,任一节点的问题都可能影响整个网络。
- 星型拓扑(Star Topology):所有节点都直接连接到中央的中心节点(如交换机或集线器)。这种方式便于监控和管理,单点故障不会影响整个网络。
- 环型拓扑(Ring Topology):每个节点都通过点对点的连接形成一个封闭的环路。信息在环路上单向流动,每一节点既是发送者也是接收者。
- 网状拓扑(Mesh Topology):网络中的每个节点都与其他节点建立连接,具有极高的可靠性和冗余性。适合于大型网络,但布线复杂,成本较高。
graph LR
A[终端设备] -->|连接| B(总线型拓扑)
C[终端设备] -->|连接| D(星型拓扑)
E[终端设备] -->|连接| F(环型拓扑)
G[终端设备] -->|连接| H(网状拓扑)
以上是网络拓扑结构的简要介绍及示意图。在实际应用中,为了满足不同的网络需求和优化网络性能,这些拓扑结构往往会被组合使用。
网络协议详解
常见网络协议的英文表达和功能
网络协议是通信设备间交换信息时必须遵守的一组规则。它们定义了数据的格式、传输方式、错误检测与纠正方法,以及控制信息的交换。一些关键的网络协议及其功能如下:
- TCP/IP (Transmission Control Protocol/Internet Protocol):作为互联网的基础协议,负责数据包的传输、路由选择、错误检测和流量控制。
- HTTP (Hypertext Transfer Protocol):用于在万维网上传输超文本文件的协议,是互联网上使用最广泛的应用层协议之一。
- FTP (File Transfer Protocol):用于在网络上的两台计算机之间进行文件传输的协议,支持文件的下载和上传。
- DNS (Domain Name System):将人类可读的域名转换为机器能够理解的IP地址,是互联网中不可或缺的一部分。
网络协议在实际工作中的应用实例
在IT专业实践中,网络协议的应用是无处不在的。例如,在配置网络时,需要正确设置TCP/IP协议的参数,以确保设备间可以互相通信。使用Wireshark等工具可以抓取和分析网络中的数据包,确保数据按照HTTP协议的要求传输。如果在网络中部署FTP服务器,还需要配置防火墙规则,允许FTP协议的特定端口(如21和20)通信。
flowchart LR
A[网络配置] --> B[TCP/IP参数设置]
B --> C[网络通信]
D[文件传输] --> E[FTP服务器部署]
E --> F[防火墙规则配置]
G[数据包分析] --> H[Wireshark工具应用]
H --> I[HTTP协议检查]
在上述示例中,可以看到网络协议在不同场景下的实际应用。理解并掌握这些协议的使用对于IT专业人士而言至关重要。
在本章中,我们探究了网络技术的基础理论,讨论了网络的定义、组成及其常见的拓扑结构。我们也深入分析了关键网络协议的英文表达和功能,并通过实际应用实例展示了它们在日常工作中的应用。网络技术是任何IT专业人员都需要掌握的核心知识,希望本章的内容能为读者提供丰富的信息和实践指导。
5. 数据库技术与SQL语言
5.1 数据库基础知识
5.1.1 数据库的种类和作用
数据库系统是现代信息技术的核心,它为组织和个人提供了数据存储、管理和检索的强大工具。数据库可以分为几种基本类型,其中最常见的是关系型数据库和非关系型数据库(NoSQL数据库)。
-
关系型数据库 :使用表格形式存储数据,并通过行和列来组织数据。它们遵循ACID(原子性、一致性、隔离性、持久性)属性,确保数据在事务中被正确处理。关系型数据库的例子包括MySQL、PostgreSQL、Oracle和Microsoft SQL Server等。
-
非关系型数据库 :设计用于处理大量的非结构化或半结构化数据。NoSQL数据库如MongoDB、Cassandra和Redis等,适用于需要快速迭代、水平扩展和灵活的数据模型的场景。
数据库的主要作用包括:
- 数据管理 :提供一种高效、安全的方式来存储和管理数据。
- 数据持久性 :保证数据即使在系统崩溃的情况下也能持久存储。
- 数据一致性 :确保数据库中的数据符合一定的规则,比如唯一性约束和引用完整性。
- 并发控制 :允许多个用户或程序同时访问和修改数据,同时防止数据冲突和不一致。
- 事务支持 :数据库管理系统提供事务处理功能,能够确保一组操作的原子性和一致性。
5.1.2 关系型数据库的基本概念
关系型数据库的基本概念包括:
- 表(Table) :由行(记录)和列(字段)组成,是数据存储的基本单位。
- 字段(Field) :表中的一列,代表一个特定的数据类型。
- 记录(Record) :表中的一行,代表一个独立的数据项。
- 键(Key) :用来唯一标识记录的字段或字段组合,例如主键(Primary Key)和外键(Foreign Key)。
- 索引(Index) :提高数据库查询性能的一种数据结构,它允许数据库快速找到特定的记录。
- 视图(View) :一个虚拟表,由查询数据库表得到的结果集组成。
- 触发器(Trigger) :自动执行的存储过程,对数据库中的事件进行响应。
5.2 SQL语言的应用
5.2.1 SQL的结构和基础语句
SQL(Structured Query Language)是用于访问和操作数据库的标准语言。它包括数据查询语言(DQL)、数据操作语言(DML)、数据定义语言(DDL)、数据控制语言(DCL)和事务控制语言(TCL)。
基础的SQL语句包括:
-
SELECT :用于从数据库中检索数据。
sql SELECT column1, column2, ... FROM table_name;这条语句会从table_name表中检索column1和column2两列的数据。 -
INSERT :用于向表中插入新的数据行。
sql INSERT INTO table_name (column1, column2, column3, ...) VALUES (value1, value2, value3, ...);这条语句会向table_name表的column1、column2、column3列中插入相应的value1、value2、value3等值。 -
UPDATE :用于修改表中的现有数据。
sql UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;这条语句会将table_name表中满足condition条件的记录的column1、column2等列的值更新为value1、value2等。 -
DELETE :用于删除表中的行。
sql DELETE FROM table_name WHERE condition;这条语句会删除table_name表中满足condition条件的记录。
5.2.2 复杂查询和数据维护的SQL实例
复杂查询允许我们通过多个表的关联、使用聚合函数以及对数据进行排序和分组来检索数据。数据维护则涉及创建和修改表结构。
-
联结查询(JOINs) :用于从多个表中获取数据。
sql SELECT column1, column2, ... FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;这条语句会从table1和table2两个表中,联结它们具有相同column_name的记录,并返回column1和column2的数据。 -
聚合函数 :如
COUNT(),SUM(),AVG(),MAX(),MIN()等,通常与GROUP BY子句一起使用。sql SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;这条语句会根据column_name的不同值来分组table_name表中的记录,并统计每组的记录数。 -
子查询 :嵌套在其他查询内的查询。
sql SELECT column1 FROM table1 WHERE column2 IN (SELECT column2 FROM table2);这条语句从table1中选出column2为table2中column2值的记录。 -
创建和修改表 :
sql CREATE TABLE table_name ( column1 datatype, column2 datatype, column3 datatype, .... );sql ALTER TABLE table_name ADD column_name datatype;CREATE TABLE语句用于创建新表,而ALTER TABLE语句用于修改现有表的结构,如增加一个新列。
通过这些例子,我们可以看到SQL语言的强大能力,它为管理数据库提供了丰富的工具和方法。
6. 操作系统核心原理与术语
操作系统是计算机系统中的一个关键组成部分,它负责管理和调度计算机硬件资源,以及提供程序运行环境和用户交互界面。在本章中,我们将深入探讨操作系统的定义、功能、分类、以及核心组件,并且解析进程管理、内存管理、文件系统和输入输出管理等核心概念。
6.1 操作系统概述
6.1.1 操作系统的定义和功能
操作系统作为计算机硬件和用户之间的接口,它提供了一个抽象层,使得用户能够更加便捷地使用计算机资源。其核心功能包括:
- 硬件资源管理:操作系统负责计算机硬件的调度和管理,包括CPU、内存、存储设备和输入输出设备。
- 用户接口:操作系统提供命令行界面(CLI)和图形用户界面(GUI),使得用户可以方便地输入指令和管理文件。
- 程序执行:操作系统加载和执行用户程序,同时管理程序的生命周期。
- 安全性和权限控制:操作系统通过用户身份验证和访问控制列表(ACLs)来确保系统资源的安全性。
- 错误检测和恢复:操作系统可以检测和处理各种系统错误,保障系统稳定运行。
6.1.2 操作系统的分类及其核心组件
操作系统主要分为以下几类:
- 批处理系统:主要用于早期的大型机,通过批处理程序一次性处理大量任务。
- 分时系统:允许多个用户共享计算机资源,时间被分割成小块,轮流为每个用户服务。
- 实时系统:主要应用在需要即时响应的领域,如工业控制和嵌入式系统。
- 个人操作系统:针对个人用户设计,提供了便捷的用户界面和丰富的应用程序支持。
- 网络操作系统:专门用于网络环境,提供网络资源管理、文件共享和远程通信等服务。
- 分布式操作系统:管理多个计算机资源,使得它们协同工作,像单个系统一样运作。
操作系统的核心组件如下:
- 内核:操作系统的核心部分,负责管理CPU、内存和设备驱动程序。
- 设备驱动程序:控制硬件设备和与操作系统其他部分通信的软件模块。
- 文件系统:负责管理数据存储和检索,使得文件可以被有效地组织和访问。
- 用户界面:提供用户与计算机交互的接口,可以是命令行或图形用户界面。
6.2 操作系统的核心概念
6.2.1 进程管理和内存管理的原理
进程管理涉及操作系统对进程的创建、调度、同步、通信和终止的管理。进程是执行中的程序实例,具有独立的地址空间和系统资源。以下是进程管理的几个关键概念:
- 进程状态:包括就绪、运行和阻塞,描述了进程在生命周期内的不同阶段。
- 上下文切换:操作系统中断一个进程的执行,并保存其状态,以便稍后恢复。
- 进程调度:操作系统按照特定算法选择哪个进程获得CPU时间。
内存管理是操作系统对物理和虚拟内存的管理,包括以下关键技术:
- 分页和分段:将虚拟内存和物理内存划分为小块,以优化内存使用。
- 虚拟内存:允许计算机使用比实际物理内存更大的地址空间。
- 内存分配:动态内存分配算法如首次适应、最佳适应和最差适应等。
6.2.2 文件系统和输入输出管理
文件系统是操作系统用于组织和存储文件的结构和机制。其核心功能包括:
- 文件存储:在存储介质上,以特定格式保存文件内容。
- 文件访问权限:定义和执行文件的读写权限,确保数据安全。
- 目录结构:组织文件和子目录,形成树状结构。
输入输出(I/O)管理是操作系统对输入输出设备的管理,确保数据能够高效、正确地在系统内外传输。其包括:
- I/O调度:决定数据传输的顺序和优化传输效率。
- 设备驱动程序:使操作系统能够与特定的硬件设备通信。
- 缓冲管理:使用内存缓存提高I/O操作的效率。
示例代码:Linux中查看进程信息
在Linux系统中,可以使用 ps 命令来查看当前系统的进程信息。下面是一个示例代码块:
ps aux | grep firefox
这个命令会列出所有与 firefox 浏览器相关的进程信息。
示例代码:文件系统操作
Linux中可以使用 touch 、 mkdir 、 rm 等命令进行文件和目录的创建、删除等操作:
# 创建一个名为newfile.txt的文件
touch newfile.txt
# 创建一个名为newdir的新目录
mkdir newdir
# 删除一个名为newfile.txt的文件
rm newfile.txt
# 删除newdir目录及其所有内容
rm -r newdir
表格:进程状态转换
| 当前状态 | 转换事件 | 新状态 | |----------|-----------|--------| | 就绪 | CPU分配时间 | 运行 | | 运行 | 时间片耗尽 | 就绪 | | 运行 | I/O请求 | 阻塞 | | 阻塞 | I/O完成 | 就绪 |
代码逻辑逐行分析
对于上文提到的 ps 命令示例代码块,逐行分析如下:
-
ps:显示当前进程状态的快照。 -
aux:选项组合,提供所有用户的所有进程信息,包括进程的详细信息。 -
|:管道符,将前一个命令的输出作为后一个命令的输入。 -
grep:用于过滤文本,显示包含“firefox”文本的行。 -
firefox:需要匹配的关键词,这里指代所有与Firefox相关的进程。
通过上述内容的探讨,我们能够更好地理解操作系统的核心原理和术语,为深入的IT技术和管理实践打下坚实的基础。
7. 算法英文表述与理解
算法是计算机科学的基础,它是一系列解决问题的明确指令,对于理解和运用计算机解决问题至关重要。本章节我们将探讨算法的基础概念,并解析它们的英文表述和阅读技巧。
7.1 算法的基本概念
7.1.1 算法的定义和重要性
算法可以定义为完成特定任务的一系列步骤或指令。在计算机科学中,算法是用于指导计算机完成任务的指令集。它们的设计和分析是编程和软件开发的基础。算法的重要性在于其对程序效率的直接影响,一个高效的算法可以显著提升软件性能,节约系统资源。
7.1.2 算法的效率分析基础
算法效率通常通过时间复杂度和空间复杂度来衡量。时间复杂度表示算法执行所需时间随着输入规模的增长而增长的趋势,常以大O表示法来描述。例如,O(n)表示线性时间复杂度,它随着输入规模n线性增长。空间复杂度指的是算法执行过程中所需存储空间与输入数据量的关系。理解这些基础概念对于设计高效算法至关重要。
7.2 算法的英文表述
7.2.1 常见算法的英文名称和概念
在英文文献中,常见的算法有:
- Bubble Sort (冒泡排序): A simple comparison-based algorithm that repeatedly steps through the list, compares adjacent elements and swaps them if they are in the wrong order.
- Quick Sort (快速排序): A divide-and-conquer algorithm that picks an element as pivot and partitions the given array around the picked pivot.
- Merge Sort (归并排序): A divide-and-conquer algorithm that divides the unsorted list into n sublists, each containing one element (a list of one element is considered sorted).
这些算法名称在英文文献中均会被按照上述方式表述,理解这些基础术语对于阅读英文算法文献至关重要。
7.2.2 算法的英文文献阅读技巧
当阅读英文算法文献时,读者应当掌握以下技巧:
- 术语识别 : 学习和熟悉算法相关的专业术语,这可以通过学习算法教材或查阅专业词汇表来实现。
- 逻辑理解 : 尝试理解算法的整体结构和逻辑流程,而不是逐字翻译每个单词。
- 代码注释 : 大多数算法文献会包含伪代码,学会读懂伪代码是理解算法的关键。
- 实例验证 : 对于复杂的算法,理解理论的同时,通过实例代码来验证其工作原理。
通过遵循这些阅读技巧,即使不是母语为英语的读者,也能有效地阅读和理解英文算法文献。
# 一个快速排序的代码示例
def quick_sort(arr):
if len(arr) <= 1:
return arr
pivot = arr[len(arr) // 2]
left = [x for x in arr if x < pivot]
middle = [x for x in arr if x == pivot]
right = [x for x in arr if x > pivot]
return quick_sort(left) + middle + quick_sort(right)
# 示例数据
example = [3, 6, 8, 10, 1, 2, 1]
print("Sorted array:", quick_sort(example))
以上代码块展示了如何使用Python实现快速排序算法。通过代码执行逻辑说明,读者可以更好地理解算法的实际应用和操作步骤。
简介:《计算机专业英语实用教程》为计算机专业人士提供了在计算机领域的英语阅读、理解和交流能力提升的系统性学习资料。涵盖硬件、软件、编程语言、网络、数据库、操作系统、算法和信息技术伦理等多个计算机科学和技术主题。本教程不仅教授基础技术词汇,如硬件组件和操作系统,还深入讲解编程语言关键概念、网络协议、数据库管理和算法原理,并包含信息技术伦理的讨论。通过学习,读者将增强在全球计算机行业英语环境中进行有效交流的能力,并能更好地掌握计算机科学的前沿知识。

















 2551
2551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









