






[C++]字节对齐与结构体大小
转自:http://pppboy.blog.163.com/blog/static/30203796201082494026399/
结构体的sizeof值,并不是简单的将其中各元素所占字节相加,而是要考虑到存储空间的字节对齐问题。这些问题在平时编程的时候也确实不怎么用到,但在一些笔试面试题目中出是常常出现,对sizeof我们将在另一篇文章中总结,这篇文章我们只总结结构体的sizeof,报着不到黄河心不死的决心,终于完成了总结,也算是小有收获,拿出来于大家分享,如果有什么错误或者没有理解透的地方还望能得到提点,也不至于误导他人。
别忘了这里 http://pppboy.blog.163.com/blog/static/30203796201082494026399/
一、解释
现代计算机中内存空间都是按照byte划分的,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定类型变量的时候经常在特 定的内存地址访问,这就需要各种类型数据按照一定的规则在空间上排列,而不是顺序的一个接一个的排放,这就是对齐。
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问 一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐.其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对 数据存放进行对齐,会在存取效率上带来损失。比如有些平台每次读都是从偶地址开始,如果一个int型(假设为32位系统)如果存放在偶地址开始的地方,那 么一个读周期就可以读出这32bit,而如果存放在奇地址开始的地方,就需要2个读周期,并对两次读出的结果的高低字节进行拼凑才能得到该32bit数据。
二、准则
其实字节对齐的细节和具体编译器实现相关,但一般而言,满足三个准则:
1. 结构体变量的首地址能够被其最宽基本类型成员的大小所整除;
2. 结构体每个成员相对于结构体首地址的偏移量都是成员大小的整数倍,如有需要编译器会在成员之间加上填充字节;
3. 结构体的总大小为结构体最宽基本类型成员大小的整数倍,如有需要编译器会在最末一个成员之后加上填充字节。
三、基本概念
字节对齐:计算机存储系统中以Byte为单位存储数据,不同数据类型所占的空间不同,如:整型(int)数据占4个字节,字符型(char)数据占一个字节,短整型(short)数据占两个字节,等等。计算机为了快速的读写数据,默认情况下将数据存放在某个地址的起始位置,如:整型数据(int)默认存储在地址能被4整除的起始位置,字符型数据(char)可以存放在任何地址位置(被1整除),短整型(short)数据存储在地址能被2整除的起始位置。这就是默认字节对齐方式。
四、结构体长度求法
1.成员都相同时(或含数组且数组数据类型同结构体其他成员数据类型):
结构体长度=成员数据类型长度×成员个数(各成员长度之和);
结构体中数组长度=数组数据类型长度×数组元素个数;
2.成员不同且不含其它结构体时;
(1).分析各个成员长度;
(2).找出最大长度的成员长度M(结构体的长度一定是该成员的整数倍);
(3).并按最大成员长度出现的位置将结构体分为若干部分;
(4).各个部分长度一次相加,求出大于该和的最小M的整数倍即为该部分长度
(5).将各个部分长度相加之和即为结构体长度
3.含有其他结构体时:
(1).分析各个成员长度;
(2).对是结构体的成员,其长度按b来分析,且不会随着位置的变化而变化;
(3).分析各个成员的长度(成员为结构体的分析其成员长度),求出最大值;
(4).若长度最大成员在为结构体的成员中,则按结构体成员为分界点分界;
其他成员中有最大长度的成员,则该成员为分界点;
求出各段长度,求出大于该和的最小M的整数倍即为该部分长度
(5).将各个部分长度相加之和即为结构体长度
五、空结构体
struct S5 { };
sizeof( S5 ); // 结果为1
“空结构体”(不含数据成员)的大小不为0,而是1。试想一个“不占空间”的变量如何被取地址、两个不同的“空结构体”变量又如何得以区分呢于是,“空结构体”变量也得被存储,这样编译器也就只能为其分配一个字节的空间用于占位了。
六、有static的结构体
struct S4{
char a;
long b;
static long c; //静态
};
静态变量存放在全局数据区内,而sizeof计算栈中分配的空间的大小,故不计算在内,S4的大小为4+4=8。
七、举例说明
1.举例1
很显然默认对齐方式会浪费很多空间,例如如下结构:
struct student
{
char name[5];
int num;
short score;
}
本来只用了11bytes(5+4+2)的空间,但是由于int型默认4字节对齐,存放在地址能被4整除的起始位置,即:如果name[5]从0开始存放,它占5bytes,而num则从第8(偏移量)个字节开始存放。所以sizeof(student)=16。于是中间空出几个字节闲置着。但这样便于计算机快速读写数据,是一种以空间换取时间的方式。其数据对齐如下图:
|char|char|char|char|
|char|----|----|----|
|--------int--------|
|--short--|----|----|
如果我们将结构体中变量的顺序改变为:
struct student
{
int num;
char name[5];
short score;
}
则,num从0开始存放,而name从第4(偏移量)个字节开始存放,连续5个字节,score从第10(偏移量)开始存放,故sizeof(student)=12。其数据对齐如下图:
|--------int--------|
|char|char|char|char|
|char|----|--short--|
如果我们将结构体中变量的顺序再次改为为:
struct student
{
int num;
short score;
char name[5];
}
则,sizeof(student)=12。其数据对齐如下图:
|--------int--------|
|--short--|char|char|
|char|char|char|----|
2.举例2
(1)
struct test1
{ int a;
int b[4];
};
sizeof(test1)=sizeof(int)+4*sizeof(int)=4+4*4=20;
(2)
struct test2
{ char a;
int b;
double c;
bool d;
};
分析:该结构体最大长度double型,长度是8,因此结构体长度分两部分:
第一部分是a、 b、 c的长度和,长度分别为1,4,8,则该部分长度和为13,取8的大于13的最小倍数为16;
第二部分为d,长度为1,取大于1的8的最小倍数为8,
两部分和为24,故sizeof(test2)=24;
(3)
struct test3
{
char a;
test2 bb;//见上题
int cc;
}
分析:该结构体有三个成员,其中第二个bb是类型为test2的结构体,长度为24,且该结构体最大长度成员类型为double型,以后成员中没有double型,所以按bb分界为两部分:
第一部分有a 、bb两部分,a长度为1,bb长度为24,取8的大于25的最小倍数32;
第二部分有cc,长度为4,去8的大于4的最小倍数为8;
两部分之和为40,故sizeof(test3)=40;
(4)
struct test4
{
char a;
int b;
};
struct test5
{ char c;
test4 d;
double e;
bool f;
};
求sizeof(test5)
分析:test5明显含有结构体test4,按例2容易知道sizeof(test4)=8,且其成员最大长度为4;则结构体test5的最大成员长度为8(double 型),考试.大提示e是分界点,分test5为两部分:
第一部分由c 、d、e组成,长度为1、8、8,故和为17,取8的大于17的最小倍数为24;
第二部分由f组成,长度为1,取8的大于1的最小倍数为8,
两部分和为32,故sizeof(test5)=24+8=32;
八、union
union的长度取决于其中的长度最大的那个成员变量的长度。即union中成员变量是重叠摆放的,其开始地址相同。
其实union(共用体)的各个成员是以同一个地址开始存放的,每一个时刻只可以存储一个成员,这样就要求它在分配内存单元时候要满足两点:
1.一般而言,共用体类型实际占用存储空间为其最长的成员所占的存储空间;
2.若是该最长的存储空间对其他成员的元类型(如果是数组,取其类型的数据长度,例int a[5]为4)不满足整除关系,该最大空间自动延伸;
我们来看看这段代码:
union mm{
char a;//元长度1
int b[5];//元长度4
double c;//元长度8
int d[3];
};
本来mm的空间应该是sizeof(int)*5=20;但是如果只是20个单元的话,那可以存几个double型(8位)呢?两个半?当然不可以,所以mm的空间延伸为既要大于20,又要满足其他成员所需空间的整数倍,即24
所以union的存储空间先看它的成员中哪个占的空间最大,拿他与其他成员的元长度比较,如果可以整除就行。
九、指定对界
#pragma pack()命令
如何修改编译器的默认对齐值?
1.在VC IDE中,可以这样修改:[Project]|[Settings],c/c++选项卡Category的Code Generation选项的Struct Member Alignment中修改,默认是8字节。
2.在编码时,可以这样动态修改:#pragma pack .注意:是pragma而不是progma.
一般地,可以通过下面的方法来改变缺省的对界条件:
使用伪指令#pragma pack (n),编译器将按照n个字节对齐;
使用伪指令#pragma pack (),取消自定义字节对齐方式。
注意:如果#pragma pack (n)中指定的n大于结构体中最大成员size,则其不起作用,结构体仍然按照size最大的成员进行对界。
为了节省空间,我们可以在编码时通过#pragma pack()命令指定程序的对齐方式,括号中是对齐的字节数,若该命令括号中的内容为空,则为默认对齐方式。例如,对于上面第一个结构体,如果通过该命令手动设置对齐字节数如下:
#pragma pack(2) //设置2字节对齐
struct strdent
{
char name[5]; //本身1字节对齐,比2字节对齐小,按1字节对齐
int num; //本身4字节对齐,比2字节对齐大,按2字节对齐
short score; //本身也2字节对齐,仍然按2字节对齐
}
#pragma pack() // 恢复先前的pack设置,取消设置的字节对齐方式
则,num从第6(偏移量)个字节开始存放,score从第10(偏移量)个字节开始存放,故sizeof(student)=12,其数据对齐如下图:
|char|char|
|char|char|
|char|----|
|----int--|
|----int--|
|--short--|
这样改变默认的字节对齐方式可以更充分地利用存储空间,但是这会降低计算机读写数据的速度,是一种以时间换取空间的方式。
十、代码验证
- 代码
//------------------------------------
// 环境:VS2005
// 时间:2010.9.24
// 用途:结构体大小测试
// 作者:pppboy.blog.163.com
//-----------------------------------
#include "stdafx.h"
#include <iostream>
using namespace std;
//空
struct S0{ };
struct S1{
char a;
long b;
};
struct S2{
long b;
char a;
};
struct S3 {
char c;
struct S1 d;//结构体
long e;
};
struct S4{
char a;
long b;
static long c; //静态
};
struct S5{
char a;
long b;
char name[5]; //数组
};
//含有一个数组
struct S6{
char a;
long b;
int name[5]; //数组
};
struct student0
{
char name[5];
int num;
short score;
};
struct student1
{
int num;
char name[5];
short score;
};
struct student2
{
int num;
short score;
char name[5];
};
union union1
{
long a;
double b;
char name[9];
};
union union2{
char a;
int b[5];
double c;
int d[3];
};
int main(int argc, char* argv[])
{
cout << "char: " << sizeof(char) << endl; //1
cout << "long: " << sizeof(long) << endl; //4
cout << "int: " << sizeof(int) << endl; //4
cout << "S0: " << sizeof(S0) << endl; //1
cout << "S1: " << sizeof(S1) << endl; //8
cout << "S2: " << sizeof(S2) << endl; //8
cout << "S3: " << sizeof(S3) << endl; //24
cout << "S4: " << sizeof(S4) << endl; //8
cout << "S5: " << sizeof(S5) << endl; //16
cout << "S6: " << sizeof(S6) << endl; //28
cout << "union1 :" << sizeof(union1) << endl;
cout << "union2 :" << sizeof(union2) << endl;
cout << "student0: " << sizeof(student0) << endl;
cout << "student1: " << sizeof(student1) << endl;
cout << "student2: " << sizeof(student2) << endl;
system("pause");
return 0;
}
- 输出
//这是默认的结果(8字节对齐)
char: 1
long: 4
int: 4
S0: 1
S1: 8
S2: 8
S3: 16
S4: 8
S5: 16
S6: 28
union1 :16
union2 :24
student0: 16
student1: 12
student2: 12
请按任意键继续. . .
//这是16字节对齐的结果,可以看到当设置16字节对齐时,确实没什么效果,里面最大的是double,也就是8字节,#pragma pack (n)中指定的n大于结构体中最大成员size,则其不起作用。
char: 1
long: 4
int: 4
double:8
S0: 1
S1: 8
S2: 8
S3: 16
S4: 8
S5: 16
S6: 28
union1 :16
union2 :24
student0: 16
student1: 12
student2: 12
请按任意键继续. . .
//这是2字节对齐的结果,可以慢慢参考研究
char: 1
long: 4
int: 4
double:8
S0: 1
S1: 6
S2: 6
S3: 12
S4: 6
S5: 12
S6: 26
union1 :10
union2 :20
student0: 12
student1: 12
student2: 12
请按任意键继续. . .
- 说明:
(1)默认8字节对齐
(2)分析
S0:空
S1:
|char|----|----|----|
|-------long--------|
S2:
|-------long--------|
|char|----|----|----|
S3:
其中包含的S1中最长的为long,S3中也为long,以最长的为分界,那么为:1+8+4 = 13,那么这个结构体的长度就是8的倍数16。
内存是怎么样的现在还没有弄清楚。。。
S4:
静态变量存放在全局数据区内,而sizeof计算栈中分配的空间的大小,故不计算在内,S4的大小为4+4=8。
S5,S6,Student见上面例子。
union1:
最长double=8,但char c[9]用9个不够,再加一倍到16.
union2:
类型最长的是long=8,变量最长的是int b[5] = 4*5=20,20以上8的倍数为24。
十一、还没有解决的问题
虽然知道结构体中含有结构体的长度怎么计算,但不知道它的内存是什么样子的,在VS中用
cout << "&objS3.a: "<< hex << &objS3.a << endl;
为什么显示出来是乱码??
十二、字节对齐可能带来的隐患
(说明:从一个pdf复制,参考一下)
代码中关于对齐的隐患,很多是隐式的。比如在强制类型转换的时候。例如:
unsigned int i = 0x12345678;
unsigned char *p=NULL;
unsigned short *p1=NULL;
p=&i;
*p=0x00;
p1=(unsigned short *)(p+1);
*p1=0x0000;
最后两句代码,从奇数边界去访问unsignedshort型变量,显然不符合对齐的规定。
在x86上,类似的操作只会影响效率,但是在MIPS或者sparc上,可能就是一个error,因为它们要求必须字节对齐。
十三、参考引用
在上述内容中,引用参考了不少文章,现将链接给出,同时感谢Scorpions带来的音乐快感。这里仅供本人学习,谢谢作者。
http://blog.csdn.net/houghstc/archive/2009/06/30/4307523.aspx
http://blog.csdn.net/vincent_1011/archive/2009/08/25/4479965.aspx
http://www.baidu.com/index.php
http://apps.hi.baidu.com/share/detail/6503863
http://hmmanhui.blog.sohu.com/108007380.html
http://www.cppreference.com/wiki/keywords/sizeof
http://blog.csdn.net/goodluckyxl/archive/2005/10/17/506827.aspx
一共有3篇:
第一篇:
转自:http://blog.csdn.net/soloist/article/details/213717
当在C中定义了一个结构类型时,它的大小是否等于各字段(field)大小之和?编译器将如何在内存中放置这些字段?ANSI C对结构体的内存布局有什么要求?而我们的程序又能否依赖这种布局?这些问题或许对不少朋友来说还有点模糊,那么本文就试着探究它们背后的秘密。
首先,至少有一点可以肯定,那就是ANSI C保证结构体中各字段在内存中出现的位置是随它们的声明顺序依次递增的,并且第一个字段的首地址等于整个结构体实例的首地址。比如有这样一个结构体:
struct vector{int x,y,z;} s;
int *p,*q,*r;
struct vector *ps;
p = &s.x;
q = &s.y;
r = &s.z;
ps = &s;
assert(p < q);
assert(p < r);
assert(q < r);
assert((int*)ps == p);
// 上述断言一定不会失败
这时,有朋友可能会问:"标准是否规定相邻字段在内存中也相邻?"。 唔,对不起,ANSI C没有做出保证,你的程序在任何时候都不应该依赖这个假设。那这是否意味着我们永远无法勾勒出一幅更清晰更精确的结构体内存布局图?哦,当然不是。不过先让我们从这个问题中暂时抽身,关注一下另一个重要问题————内存对齐。
许多实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4或8)的倍数,这就是所谓的内存对齐,而这个k则被称为该数据类型的对齐模数(alignment modulus)。当一种类型S的对齐模数与另一种类型T的对齐模数的比值是大于1的整数,我们就称类型S的对齐要求比T强(严格),而称T比S弱(宽松)。这种强制的要求一来简化了处理器与内存之间传输系统的设计,二来可以提升读取数据的速度。比如这么一种处理器,它每次读写内存的时候都从某个8倍数的地址开始,一次读出或写入8个字节的数据,假如软件能保证double类型的数据都从8倍数地址开始,那么读或写一个double类型数据就只需要一次内存操作。否则,我们就可能需要两次内存操作才能完成这个动作,因为数据或许恰好横跨在两个符合对齐要求的8字节内存块上。某些处理器在数据不满足对齐要求的情况下可能会出错,但是Intel的IA32架构的处理器则不管数据是否对齐都能正确工作。不过Intel奉劝大家,如果想提升性能,那么所有的程序数据都应该尽可能地对齐。Win32平台下的微软C编译器(cl.exe for 80x86)在默认情况下采用如下的对齐规则: 任何基本数据类型T的对齐模数就是T的大小,即sizeof(T)。比如对于double类型(8字节),就要求该类型数据的地址总是8的倍数,而char类型数据(1字节)则可以从任何一个地址开始。Linux下的GCC奉行的是另外一套规则(在资料中查得,并未验证,如错误请指正):任何2字节大小(包括单字节吗?)的数据类型(比如short)的对齐模数是2,而其它所有超过2字节的数据类型(比如long,double)都以4为对齐模数。
现在回到我们关心的struct上来。ANSI C规定一种结构类型的大小是它所有字段的大小以及字段之间或字段尾部的填充区大小之和。嗯?填充区?对,这就是为了使结构体字段满足内存对齐要求而额外分配给结构体的空间。那么结构体本身有什么对齐要求吗?有的,ANSI C标准规定结构体类型的对齐要求不能比它所有字段中要求最严格的那个宽松,可以更严格(但此非强制要求,VC7.1就仅仅是让它们一样严格)。我们来看一个例子(以下所有试验的环境是Intel Celeron 2.4G + WIN2000 PRO + vc7.1,内存对齐编译选项是"默认",即不指定/Zp与/pack选项):
typedef struct ms1
{
char a;
int b;
} MS1;
假设MS1按如下方式内存布局(本文所有示意图中的内存地址从左至右递增):
_____________________________
| | |
| a | b |
| | |
+---------------------------+
Bytes: 1 4
因为MS1中有最强对齐要求的是b字段(int),所以根据编译器的对齐规则以及ANSI C标准,MS1对象的首地址一定是4(int类型的对齐模数)的倍数。那么上述内存布局中的b字段能满足int类型的对齐要求吗?嗯,当然不能。如果你是编译器,你会如何巧妙安排来满足CPU的癖好呢?呵呵,经过1毫秒的艰苦思考,你一定得出了如下的方案:
_______________________________________
| |///| |
| a |//padding//| b |
| |///| |
+-------------------------------------+
Bytes: 1 3 4
这个方案在a与b之间多分配了3个填充(padding)字节,这样当整个struct对象首地址满足4字节的对齐要求时,b字段也一定能满足int型的4字节对齐规定。那么sizeof(MS1)显然就应该是8,而b字段相对于结构体首地址的偏移就是4。非常好理解,对吗?现在我们把MS1中的字段交换一下顺序:
typedef struct ms2
{
int a;
char b;
} MS2;
或许你认为MS2比MS1的情况要简单,它的布局应该就是
_______________________
| | |
| a | b |
| | |
+---------------------+
Bytes: 4 1
因为MS2对象同样要满足4字节对齐规定,而此时a的地址与结构体的首地址相等,所以它一定也是4字节对齐。嗯,分析得有道理,可是却不全面。让我们来考虑一下定义一个MS2类型的数组会出现什么问题。C标准保证,任何类型(包括自定义结构类型)的数组所占空间的大小一定等于一个单独的该类型数据的大小乘以数组元素的个数。换句话说,数组各元素之间不会有空隙。按照上面的方案,一个MS2数组array的布局就是:
|<- array[1] ->|<- array[2] ->|<- array[3] .....
__________________________________________________________
| | | | |
| a | b | a | b |.............
| | | | |
+----------------------------------------------------------
Bytes: 4 1 4 1
当数组首地址是4字节对齐时,array[1].a也是4字节对齐,可是array[2].a呢?array[3].a ....呢?可见这种方案在定义结构体数组时无法让数组中所有元素的字段都满足对齐规定,必须修改成如下形式:
___________________________________
| | |///|
| a | b |//padding//|
| | |///|
+---------------------------------+
Bytes: 4 1 3
现在无论是定义一个单独的MS2变量还是MS2数组,均能保证所有元素的所有字段都满足对齐规定。那么sizeof(MS2)仍然是8,而a的偏移为0,b的偏移是4。
好的,现在你已经掌握了结构体内存布局的基本准则,尝试分析一个稍微复杂点的类型吧。
typedef struct ms3
{
char a;
short b;
double c;
} MS3;
我想你一定能得出如下正确的布局图:
padding
|
_____v_________________________________
| |/| |/| |
| a |/| b |/padding/| c |
| |/| |/| |
+-------------------------------------+
Bytes: 1 1 2 4 8
sizeof(short)等于2,b字段应从偶数地址开始,所以a的后面填充一个字节,而sizeof(double)等于8,c字段要从8倍数地址开始,前面的a、b字段加上填充字节已经有4 bytes,所以b后面再填充4个字节就可以保证c字段的对齐要求了。sizeof(MS3)等于16,b的偏移是2,c的偏移是8。接着看看结构体中字段还是结构类型的情况:
typedef struct ms4
{
char a;
MS3 b;
} MS4;
MS3中内存要求最严格的字段是c,那么MS3类型数据的对齐模数就与double的一致(为8),a字段后面应填充7个字节,因此MS4的布局应该是:
_______________________________________
| |///| |
| a |//padding//| b |
| |///| |
+-------------------------------------+
Bytes: 1 7 16
显然,sizeof(MS4)等于24,b的偏移等于8。
在实际开发中,我们可以通过指定/Zp编译选项来更改编译器的对齐规则。比如指定/Zpn(VC7.1中n可以是1、2、4、8、16)就是告诉编译器最大对齐模数是n。在这种情况下,所有小于等于n字节的基本数据类型的对齐规则与默认的一样,但是大于n个字节的数据类型的对齐模数被限制为n。事实上,VC7.1的默认对齐选项就相当于/Zp8。仔细看看MSDN对这个选项的描述,会发现它郑重告诫了程序员不要在MIPS和Alpha平台上用/Zp1和/Zp2选项,也不要在16位平台上指定/Zp4和/Zp8(想想为什么?)。改变编译器的对齐选项,对照程序运行结果重新分析上面4种结构体的内存布局将是一个很好的复习。
到了这里,我们可以回答本文提出的最后一个问题了。结构体的内存布局依赖于CPU、操作系统、编译器及编译时的对齐选项,而你的程序可能需要运行在多种平台上,你的源代码可能要被不同的人用不同的编译器编译(试想你为别人提供一个开放源码的库),那么除非绝对必需,否则你的程序永远也不要依赖这些诡异的内存布局。顺便说一下,如果一个程序中的两个模块是用不同的对齐选项分别编译的,那么它很可能会产生一些非常微妙的错误。如果你的程序确实有很难理解的行为,不防仔细检查一下各个模块的编译选项。
思考题:请分析下面几种结构体在你的平台上的内存布局,并试着寻找一种合理安排字段声明顺序的方法以尽量节省内存空间。
A. struct P1 { int a; char b; int c; char d; };
B. struct P2 { int a; char b; char c; int d; };
C. struct P3 { short a[3]; char b[3]; };
D. struct P4 { short a[3]; char *b[3]; };
E. struct P5 { struct P2 *a; char b; struct P1 a[2]; };
参考资料:
【1】《深入理解计算机系统(修订版)》,
(著)Randal E.Bryant; David O'Hallaron,
(译)龚奕利 雷迎春,
中国电力出版社,2004
【2】《C: A Reference Manual》(影印版),
(著)Samuel P.Harbison; Guy L.Steele,
人民邮电出版社,2003
第二篇:浅谈VC中的字节对齐
转自:http://blog.csdn.net/yunyun1886358/article/details/5651652
前几天时,在公司和同事说到了字节对齐,一直对这个概念比较模糊,只是在《程序员面试宝典》中看到过简单的描述和一些面试题。后来在论坛中有看到有朋友在询问字节对齐的相关问题,自己也答不上来,觉得应该研究一下,所以就有了这一篇博文,是对学习的一个总结,也是对成长轨迹的一个记录。
字节对齐,又叫内存对齐,个人理解就是一种C++中的类型在内存中空间分配策略。每一种类型存储的起始地址,都要求是一个对齐模数(alignment modulus)的整数倍。问题来了,为什么要有这种策略?计算中内存中的数据就是一个一个的字节(byte),直接按照一个字节一个字节存储就得了,为什么还要那么麻烦。把问题想简单了。
各个硬件平台对存储空间的处理上有很大的不同。一些平台对某些特定类型的数据只能从某些特定地址开始存取。比如有些架构的CPU在访问 一个没有进行对齐的变量的时候会发生错误,那么在这种架构下编程必须保证字节对齐.其他平台可能没有这种情况,但是最常见的是如果不按照适合其平台要求对 数据存放进行对齐,会在存取效率上带来损失。
计算机CPU一次处理可以处理多个字节,就拿32位系统来说,CPU一次可以处理32bit的数据,也就是4个字节。比如有些平台每次读都是从偶地址开始,假设有一个int型数据,存放在内存地址0x1的位置。CPU要读取这个int数据,并且从地址0x0开始读取数据。一次读取4字节,那么这个int型还有一个字节没有读到,就得再读取一次剩下的那一个字节,并且还要进行位操作,把两次读取的数据合并为一个int型数据。两个字--麻烦,效率太低了。那怎么办呢?为了提高效率,干脆在存储的时候把这个int数据放在内存地址0x4的位置,0x1、0x2、0x3的位置都空着,CPU直接从0x4取数据,只需一次就取到了这个数据,还不用进行位操作。就是拿空间换时间,没办法,谁让现在的存内存越来越大了呢?
下面一些知识的总结,部分来自互联网,感谢那些为C++奋斗的兄弟。
字节对齐的规则
许多实际的计算机系统对基本类型数据在内存中存放的位置有限制,它们会要求这些数据的首地址的值是某个数k(通常它为4的倍数,这就是所谓的字节对齐,而这个k则被称为该数据类型的对齐模数(alignment modulus)。当一种类型S的对齐模数与另一种类型T的对齐模数的比值是大于1的整数,我们就称类型S的对齐要求比T强(严格),而称T比S弱(宽松)。下面来讨论4种不同类型的对齐模数:
- 内置类型的自身对齐模数(有符号无符号相同)
char 1
short 2
int 4
float 4
double 8
- 自定义类型的自身对齐模数(struct 、class)
等同于其成员中最大的自身对齐模数
- 指定对齐模数
我们给编译器指定的对齐模数(在VC中使用指令:#pragma pack(n),如果不指定,在VS2010默认为8)
- 有效对齐模数
指定对齐模数与类型自身对齐模数的较小的值,就是实际生效的对齐模数。
- 自定义类型中各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个类型的地址相同
- 每个成员分别对齐,即每个成员按自己的方式对齐,并最小化长度,规则就是每个成员按其类型的对齐模数(通常是这个类型的大小)和指定对齐参模数中较小的一个对齐
- 结构、联合或者类的数据成员,第一个放在偏移为0的地方,以后每个数据成员的对齐,按照指定对齐模数和这个数据成员自身长度两个中比较小的那个进行。也就是说,当#pragma pack指定的值等于或者超过所有数据成员长度的时候,这个指定值的大小将不产生任何效果
- 自定义类型(如结构)整体的对齐(注意是“整体”)是按照结构体中长度最大的数据成员和指定对齐模数之间较小的那个值进行,这样在成员是复杂类型时,可以最小化长度
- 结构整体长度的计算必须是成员的所有对齐模数数中最大的那个值的整数倍,不够补空字节,因为对齐参数都是2的n次方。这样在处理数组时可以保证每一项都边界对齐
例如:
1 struct alignment 2 { 3 char ch; // 自身对齐模数1,指定对齐模数8,有效对齐模数1 4 int i; // 自身对齐模数4,指定对齐模数8,有效对齐模数4 5 short sht; // 自身对齐模数2,指定对齐模数8,有效对齐模数2 6 }; // 自身对齐模数4,指定对齐模数8,有效对齐模数4
在上例中,假设起始地址0x0,那么ch的地址为离0x0最近的且能被ch的有效对齐模数整除的地址,那么就是0x0;以此类推,i的地址为0x4,sht的地址为0x8,alignment的地址与ch的地址一致。
VC中的字节对齐设置
- 在VC IDE中,可以这样修改:[Project]|[Settings],c/c++选项卡Category的Code Generation选项的Struct Member Alignment中修改,默认是8字节。
- 在编码时,可以使用指令动态修改:#pragma pack
指令#pragma pack
作用:指定结构体、联合以及类成员的packing alignment;
语法:#pragma pack( [show] | [push | pop] [, identifier], n )
说明:
- pack提供数据声明级别的控制,对定义不起作用;
- 调用pack时不指定参数,n将被设成默认值;
- 一旦改变数据类型的alignment,直接效果就是占用memory的减少,但是performance会下降;
语法具体分析:
- show:可选参数;显示当前packing aligment的字节数,以warning message的形式被显示;
- push:可选参数;将当前指定的packing alignment数值进行压栈操作,这里的栈是the internal compiler stack,同时设置当前的packing alignment为n;如果n没有指定,则将当前的packing alignment数值压栈;
- pop:可选参数;从internal compiler stack中删除最顶端的record;如果没有指定n,则当前栈顶record即为新的packing alignment数值;如果指定了n,则n将成为新的packing aligment数值;如果指定了identifier,则internal compiler stack中的record都将被pop直到identifier被找到,然后pop出identitier,同时设置packing alignment数值为当前栈顶的record;如果指定的identifier并不存在于internal compiler stack,则pop操作被忽略;
- identifier:可选参数;当同push一起使用时,赋予当前被压入栈中的record一个名称;当同pop一起使用时,从internal compiler stack中pop出所有的record直到identifier被pop出,如果identifier没有被找到,则忽略pop操作;
- n:可选参数;指定packing的数值,以字节为单位;缺省数值是8,合法的数值分别是1、2、4、8、16。
使用示例:
1 #include<iostream> 2 3 using namespace std; 4 5 #pragma pack(show) // Output中输出如下信息:warning C4810: value of pragma pack(show) == 8 6 #pragma pack(push, alignmentDEfault) // 使用标识符alignmentDEfault压栈默认字节对齐模数 7 8 #pragma pack(1) // 将对齐模数设置为1 9 #pragma pack(show) 10 #pragma pack(push, alignment1) // 使用标识符alignment1压栈默认字节对齐模数 11 struct alignment1 12 { 13 char ch; 14 int i; 15 short sht; 16 }; 17 18 #pragma pack(2) // 将对齐模数设置为2 19 #pragma pack(show) 20 #pragma pack(push, alignment2) // 使用标识符alignment2压栈默认字节对齐模数 21 struct alignment2 22 { 23 char ch; 24 int i; 25 short sht; 26 }; 27 28 #pragma pack(push, alignment8, 8) // 使用标识符alignment2压栈默认字节对齐模数 29 #pragma pack(show) 30 struct alignment8 31 { 32 char ch; 33 int i; 34 short sht; 35 }; 36 37 #pragma pack(pop, alignmentDEfault) // 将标号alignmentDEfault对应的字节对齐模数弹出栈 38 #pragma pack(show) 39 struct alignmentDefault 40 { 41 char ch; 42 int i; 43 short sht; 44 }; 45 46 int main() 47 { 48 alignment1 align1; 49 cout << (int)&align1.i - (int)&align1.ch << endl; // 输出1 50 cout << (int)&align1.sht - (int)&align1.i << endl; // 输出4 51 52 alignment2 align2; 53 cout << (int)&align2.i - (int)&align2.ch << endl; // 输出2 54 cout << (int)&align2.sht - (int)&align2.i << endl; // 输出4 55 56 alignment8 align8; 57 cout << (int)&align8.i - (int)&align8.ch << endl; // 输出4 58 cout << (int)&align8.sht - (int)&align8.i << endl; // 输出4 59 60 alignmentDefault alignmentD; 61 cout << (int)&alignmentD.i - (int)&alignmentD.ch << endl; // 输出4 62 cout << (int)&alignmentD.sht - (int)&alignmentD.i << endl; // 输出4 63 }
程序中的字节对齐与空间占用
字节对齐规则影响着struct和class的内存占用。来看一个例子:
1 #include <iostream> 2 3 #pragma pack(8) 4 struct example1 5 { 6 short a; 7 long b; 8 }; 9 10 struct example2 11 { 12 char c; 13 example1 struct1; 14 short e; 15 }; 16 #pragma pack() 17 18 int main(int argc, char* argv[]) 19 { 20 example2 struct2; 21 22 cout << sizeof(example1) << endl; 23 cout << sizeof(example2) << endl; 24 cout << (unsigned int)(&struct2.struct1) - (unsigned int)(&struct2) << endl; 25 26 return 0; 27 }
程序中第2行#pragma pack (8)虽然指定了对齐模数为8,但是由于struct example1中的成员最大size为4(long变量size为4),故struct example1仍然按4字节对齐,struct example1的size为8,即第22行的输出结果;
struct example2中包含了struct example1,其本身包含的简单数据成员的最大size为2(short变量e),但是因为其包含了struct example1,而struct example1中的最大成员size为4,struct example2也应以4对齐,#pragma pack (8)中指定的对齐对struct example2也不起作用,故23行的输出结果为16;
由于struct example2中的成员以4为单位对界,故其char变量c后应补充3个空,其后才是成员struct1的内存空间,24行的输出结果为4。
字节对齐与程序的编写
如果在编程的时候要考虑节约空间的话,那么我们只需要假定结构的首地址是0,然后各个变量按照上面的原则进行排列即可,基本的原则就是把结构中的变量按照类型大小从小到大声明,尽量减少中间的填补空间.还有一种就是为了以空间换取时间的效率,我们显示的进行填补空间进行对齐,比如:有一种使用空间换时间做法是显式的插入reserved成员:
struct A{
char a;
char reserved[3];//使用空间换时间
int b;
}
reserved成员对我们的程序没有什么意义,它只是起到填补空间以达到字节对齐的目的,当然即使不加这个成员通常编译器也会给我们自动填补对齐,我们自己加上它只是起到显式的提醒作用.
代码中关于对齐的隐患,很多是隐式的。比如在强制类型转换的时候。例如:
unsigned int i = 0x12345678;
unsigned char *p=NULL;
unsigned short *p1=NULL;
p=&i;
*p=0x00;
p1=(unsigned short *)(p+1);
*p1=0x0000;
最后两句代码,从奇数边界去访问unsignedshort型变量,显然不符合对齐的规定。
在x86上,类似的操作只会影响效率,但是在MIPS或者sparc上,可能就是一个error,因为它们要求必须字节对齐.
如果出现对齐或者赋值问题首先查看
-
- 编译器的big little端设置
- 看这种体系本身是否支持非对齐访问
- 如果支持看设置了对齐与否,如果没有则看访问时需要加某些特殊的修饰来标志其特殊访问操作。
第三篇:谈谈关于内存对齐与补齐
转自:http://blog.csdn.net/cyousui/article/details/17655051
首先我们先看看下面的C语言的结构体:
- typedef struct MemAlign
- {
- int a;
- char b[3];
- int c;
- }MemAlign;
以上这个结构体占用内存多少空间呢?也许你会说,这个简单,计算每个类型的大小,将它们相加就行了,以32为平台为例,int类型占4字节,char占用1字节,所以:4 + 3 + 4 = 11,那么这个结构体一共占用11字节空间。好吧,那么我们就用实践来证明是否正确,我们用sizeof运算符来求出这个结构体占用内存空间大小,sizeof(MemAlign),出乎意料的是,结果居然为12?看来我们错了?当然不是,而是这个结构体被优化了,这个优化有个另外一个名字叫“对齐”,那么这个对齐到底做了什么样的优化呢,听我慢慢解释,再解释之前我们先看一个图,图如下:
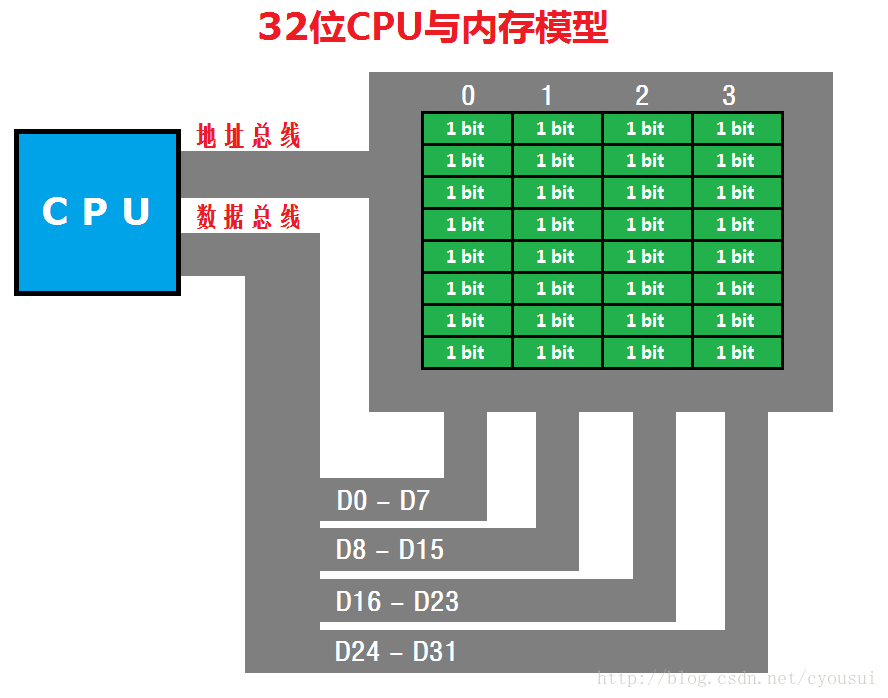
相信学过汇编的朋友都很熟悉这张图,这张图就是CPU与内存如何进行数据交换的模型,其中,左边蓝色的方框是CPU,右边绿色的方框是内存,内存上面的0~3是内存地址。这里我们这张图是以32位CPU作为代表,我们都知道,32位CPU是以双字(DWORD)为单位进行数据传输的,也正因为这点,造成了另外一个问题,那么这个问题是什么呢?这个问题就是,既然32位CPU以双字进行数据传输,那么,如果我们的数据只有8位或16位数据的时候,是不是CPU就按照我们数据的位数来进行数据传输呢?其答案是否定的,如果这样会使得CPU硬件变的更复杂,所以32位CPU传输数据无论是8位或16位都是以双字进行数据传输。那么也罢,8位或16位一样可以传输,但是,事情并非像我们想象的那么简单,比如,一个int类型4字节的数据如果放在上图内存地址1开始的位置,那么这个数据占用的内存地址为1~4,那么这个数据就被分为了2个部分,一个部分在地址0~3中,另外一部分在地址4~7中,又由于32位CPU以双字进行传输,所以,CPU会分2次进行读取,一次先读取地址0~3中内容,再一次读取地址4~7中数据,最后CPU提取并组合出正确的int类型数据,舍弃掉无关数据。那么反过来,如果我们把这个int类型4字节的数据放在上图从地址0开始的位置会怎样呢?读到这里,也许你明白了,CPU只要进行一次读取就可以得到这个int类型数据了。没错,就是这样,这次CPU只用了一个周期就得到了数据,由此可见,对内存数据的摆放是多么重要啊,摆放正确位置可以减少CPU的使用资源。
那么,内存对齐有哪些原则呢?我总结了一下大致分为三条:
第一条:第一个成员的首地址为0
第二条:每个成员的首地址是自身大小的整数倍
第二条补充:以4字节对齐为例,如果自身大小大于4字节,都以4字节整数倍为基准对齐。
第三条:最后以结构总体对齐。
第三条补充:以4字节对齐为例,取结构体中最大成员类型倍数,如果超过4字节,都以4字节整数倍为基准对齐。(其中这一条还有个名字叫:“补齐”,补齐的目的就是多个结构变量挨着摆放的时候也满足对齐的要求。)
上述的三原则听起来还是比较抽象,那么接下来我们通过一个例子来加深对内存对齐概念的理解,下面是一个结构体,我们动手算出下面结构体一共占用多少内存?假设我们以32位平台并且以4字节对齐方式:
- #pragma pack(4)
- typedef struct MemAlign
- {
- char a[18];
- double b;
- char c;
- int d;
- short e;
- }MemAlign;
下图为对齐后结构如下:
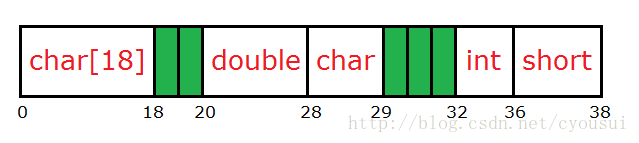
我们就以这个图来讲解是如何对齐的:
第一个成员(char a[18]):首先,假设我们把它放到内存开始地址为0的位置,由于第一个成员占18个字节,所以第一个成员占用内存地址范围为0~18。
第二个成员(double b):由于double类型占8字节,又因为8字节大于4字节,所以就以4字节对齐为基准。由于第一个成员结束地址为18,那么地址18并不是4的整数倍,我们需要再加2个字节,也就是从地址20开始摆放第二个成员。
第三个成员(char c):由于char类型占1字节,任意地址是1字节的整数倍,所以我们就直接将其摆放到紧接第二个成员之后即可。
第四个成员(int d):由于int类型占4字节,但是地址29并不是4的整数倍,所以我们需要再加3个字节,也就是从地址32开始摆放这个成员。
第五个成员(short e):由于short类型占2字节,地址36正好是2的整数倍,这样我们就可以直接摆放,无需填充字节,紧跟其后即可。
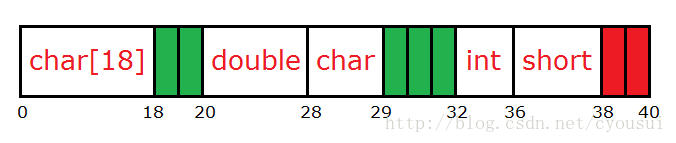
这样我们内存对齐就完成了。但是离成功还差那么一步,那是什么呢?对,是对整个结构体补齐,接下来我们就补齐整个结构体。那么,先让我们回顾一下补齐的原则:“以4字节对齐为例,取结构体中最大成员类型倍数,如果超过4字节,都以4字节整数倍为基准对齐。”在这个结构体中最大类型为double类型(占8字节),又由于8字节大于4字 节,所以我们还是以4字节补齐为基准,整个结构体结束地址为38,而地址38并不是4的整数倍,所以我们还需要加额外2个字节来填充结构体,如下图红色的就是补齐出来的空间:
到此为止,我们内存对齐与补齐就完毕了!接下来我们用实验来证明真理,程序如下:
- #include <stdio.h>
- #include <memory.h>
- // 由于VS2010默认是8字节对齐,我们
- // 通过预编译来通知编译器我们以4字节对齐
- #pragma pack(4)
- // 用于测试的结构体
- typedef struct MemAlign
- {
- char a[18]; // 18 bytes
- double b; // 08 bytes
- char c; // 01 bytes
- int d; // 04 bytes
- short e; // 02 bytes
- }MemAlign;
- int main()
- {
- // 定义一个结构体变量
- MemAlign m;
- // 定义个以指向结构体指针
- MemAlign *p = &m;
- // 依次对各个成员进行填充,这样我们可以
- // 动态观察内存变化情况
- memset( &m.a, 0x11, sizeof(m.a) );
- memset( &m.b, 0x22, sizeof(m.b) );
- memset( &m.c, 0x33, sizeof(m.c) );
- memset( &m.d, 0x44, sizeof(m.d) );
- memset( &m.e, 0x55, sizeof(m.e) );
- // 由于有补齐原因,所以我们需要对整个
- // 结构体进行填充,补齐对齐剩下的字节
- // 以便我们可以观察到变化
- memset( &m, 0x66, sizeof(m) );
- // 输出结构体大小
- printf( "sizeof(MemAlign) = %d", sizeof(m) );
- }
程序运行过程中,查看内存如下:
其中,各种颜色带下划线的代表各个成员变量,蓝色方框的代表为内存对齐时候填补的多余字节,由于这里看不到补齐效果,我们接下来看下图,下图篮框包围的字节就是与上图的交集以外的部分就是补齐所填充的字节。
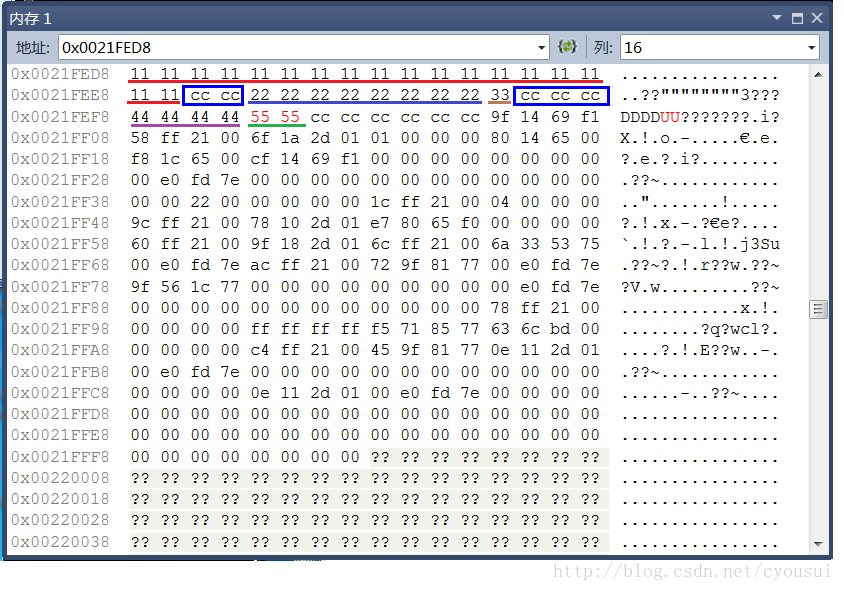
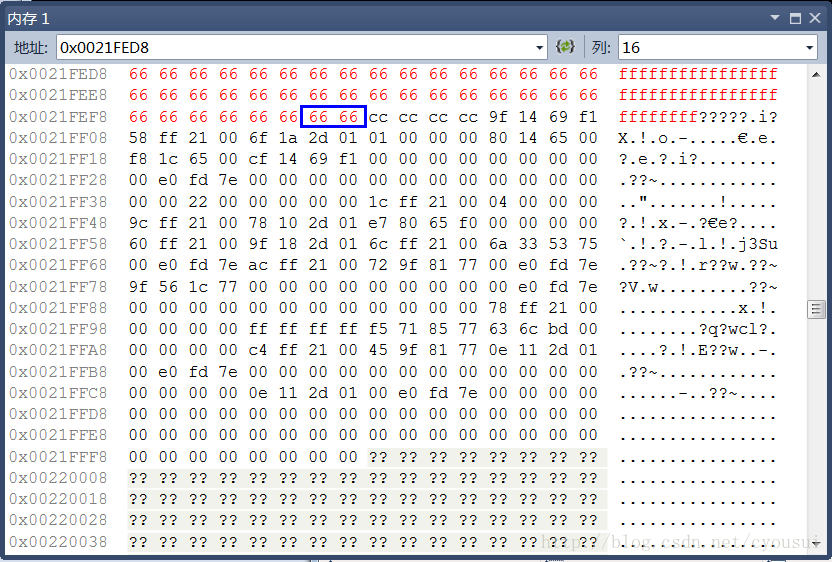
在最后,我在谈一谈关于补齐的作用,补齐其实就是为了让这个结构体定义的数组变量时候,数组内部,也同样满足内存对齐的要求,为了更好的理解这点,我做了一个跟本例子相对照的图:
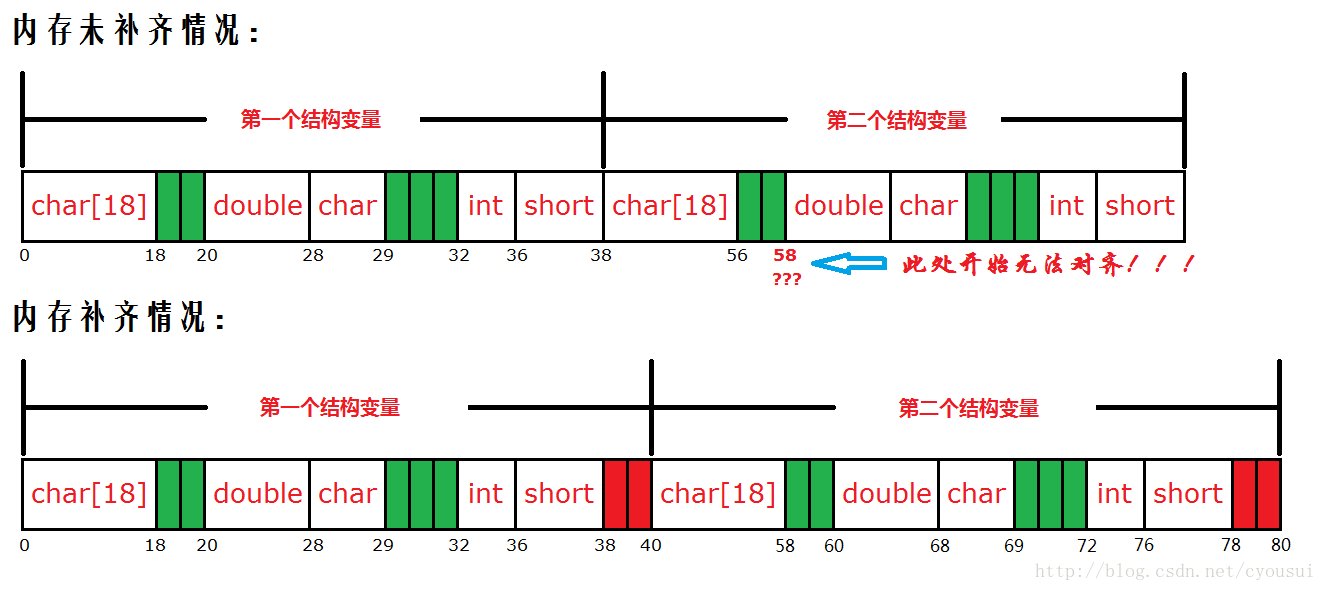















 1790
1790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









