







Python的历史我就不在这里介绍了。
首先了解一下Python这门语言以及它和其他几种广泛使用语言的区别:
python 是一种解释型通用语言,java是半执行语言,C是一种可编译型语言。编译型语言,是指程序输入到编译器,编译器再根据语言的语法进行解析,然后翻译成语言独立的机器码,最终链接成具有高度优化的机器码的可执行程序。而解释型语言,则是程序被输入到解释器来运行。解释器在程序执行之前对其并不了解;它所知道的只是Python的规则,以及在执行过程中怎样去动态的应用这些规则。Python中有全局解释器锁,也就是所谓的python GIL 全局锁,所以在同一时间内,python解释器只能运行一个线程的代码。由于解释器没法很好的对程序进行推导,Python的大部分优化其实是解释器自身的优化。
在python中有且只有一种最优解,而且python是一种面向对象的语言。在python中,经常有时候会出现缩进问题,在Linux的vim中,set ts=4 使table缩进4个空格,默认8个,所以有时候我们看python的报错,得注意是否为语法问题或者是缩进问题(SyntaxError:语法错误,IndentationError:缩进错误。)
。所以python中程序要注意语句对齐,用table补齐。
文件系统的作用:文件在系统中存放的方式,变量类型作用是变量在内存中存放的方式。类型转换,高->低,会失真,反之不会。
在Linux中,可用python或ipython进行测试,这里说一个Linux中的一个外设命令,会在编程时用到,为seq命令,一般用作一堆数字的简化写法。用seq 选择数字。 例:seq 1 99 则输出1-99,1-99相加时, seq -s + 1 99 | bc
接着说一下看一下python的简单脚本,例如:
应当注意的是,如果要输出中文,必须要有# coding=utf -8
然后看一下range()函数,range()函数很方便,使用range() 会生成一个列表。
例如:range(1,10,2)从1开始到10,步长为2.

Python的循环中, continue 只是结束当前循环, break则结束整个循环。
Python中与,或,非,异或等逻辑关系仍然适用
但它是以二进制来进行逻辑关系的。
Python中的if语句,跟shell之中基本类似,例如:

可以添加elif但是,当有一个elif成立,则会跳过以后的elif直接结束。
接下来说一下python中的四种基础数据结构。
一.列表
python中, 列表定义直接用 名= [数据] 查看列表时直接调用。如定义li = [1,12,3,[2,3],'a'],查看子列表中的元素时, 用li[3][1],则会显示出3这个子列表中的值。
len(列表名)取列表长度。
列表也可以直接遍历。



判断某个元素是否在列表里存在, 元素 in 列表名。

删除列表中的某一个元素,del 列表名[索引值]。

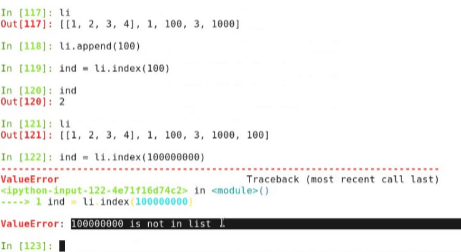
list.append 追加 li.append('a') 该操作没有返回值。
list.extend(li2) 使列表合并。将li2合并到li,这里的li2是参数。
可以用两个列表相加,但是只是生成了结果,并不会保存。li + li2 ,需要生成结果时, 用li3 = li + li2, 就能得到li+li2结果。
li.index(元素),查看第一个出现的元素在列表中的下标。该元素必须在列表中出现。如 kong = li.index(2),当查看kong时,会得到2(即从左往右数起第三个元素)这个元素在li列表中的下标。
li.insert(索引,值),插入一个数据。在最后一个位置插入一个数据,li.insert(len(li),数据)

删除,li.remove(加元素值),删除从左到右的第一个元素。但是当列表中没有该元素时,会直接退出, 在操作时, 用if进行一次判断。
li.pop()将列表最后的元素返回并且删除。 也可以用a=li.pop()使删除的元素保存,否则和执行完后,数据以及内存被删除。
li.count(元素)列出在列表中的某以元素出现的次数。

列表排序,li.sort(),从小到大排序, li.reverse,倒叙。
列表的切片, li[2:4]左半闭区间,有返回值,但必须接收,不会自动保存。如果不指定第一个元素,则从列表开头开始切,到结尾, 不指定第二个元素,则返回到最后一个值。
当对某一列表进行赋值,li3 = li, 改变li或者li3都会对列表进行改变。 此时,用切片进行赋值。 li4 = li[:],这时,改变li4就不会对li进行修改。
切片li[2:4:2]对li中的元素进行切片,步长为2,步长不管为多少,第一个元素必然存在。最后步长为-1时,则会将列表倒转。
li[::-1],就是反转。得到下标为偶数的元素时,li[::2],要得到下标为奇数的元素时li[1::2]

在python程序中,输出只能是print来执行,否则看不到结果。
二.元组
用小括号括起来的元素为元组。tuple 如 t = (2,3,4)
元组支持切片和下标操作。如有元组t = (2,3,4),则可以通过t[0],来通过下标查看元素, 也可以通过t[1:3]来对元组进行切片,但是不能对元组的数据进行操作。
元组中有列表时,可以对列表中的数据进行修改。如t = (1,2,3[2,3,4]),可以通过t[3][0]来修改列表中的第一个元素。
创建元组时,仅有一个数据时,要将逗号加上。t = (1,)
集和set 在创建时直接s = {1,2,3,4},要创建空集合时, 需要s = set(),并且集合不支持索引。集合是无序的。;列表不能放到集合里面。且集合中数据唯一。
将列表中的元素去重,将列表先变成集合再转化为列表。如 li= list(set([1,23,4,5,6])), 查看li 就完成了去重。
在集合中添加元素, 集合名.add(元素),删除某一个元素时,用s.discard(加元素),不会报错。
s.pop()随机删除集合中的某一个元素,有返回值。s.clear(),清空集合。
集合的差集,有s = {1,2,3,4,5,6} s1 = {2,4,5,6},s.difference(s1),以s集合为标准,求s1与s的相差的值。也可以用s - s1 来进行重载。


三.集合
以大括号括起来的元素为集合,集合中没有相同元素。


集合的差集,有s = {1,2,3,4,5,6} s1 = {2,4,5,6},s.difference(s1),以s集合为标准,求s1与s的相差的值。也可以用s - s1 来进行重载。


集合的交集 s.intersection(s1)如s = {1,2,3} s1 = {1,3,4}, 也可以用s & s1
集合的并集 s | s1
查看是否有交集 s.isdisjoint(s1),true 则没有。
查看是否是子集用s.issubset(s1),true 为有, false为没有。

四.字典dict
内置的数据结构,字典,dict, 生成一个空的字典 d = dict() . 用type(d)查看属性。字典里可以放若干个键值,但是字典中的元素不能重复。如:d = {'name(键)':'kong(值)','age':20}。当出现重复时 d2 = {'name ':kk,'name':yy}此时,用d2显示时,只会显示出后面的姓名。 字典内的键必须唯一, 可以hash。
用字典名.keys(),可以查看所有的键的名称,以列表返回。将值返回, 用d.values。用d.items也可以返回键值队。
iterkeys 迭代器。每执行一次,得到一个结果。
用for循环将字典中的键值都打印出来,
for i in d.keys():
print i,d[i]
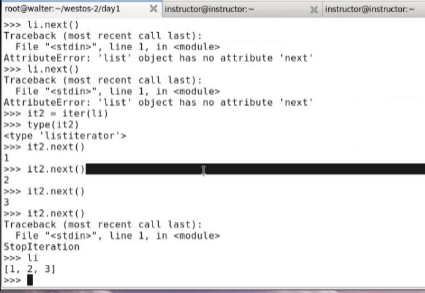
list如何转变为迭代器。 it2 = iter(li),此时li就变成了迭代器,用type查看it2.用for循环测试。 for i in li:
print i
也可以手动执行,it2.next。





python中可以进行多项赋值:a,b,c = [1,2,4]
用多重赋值遍历字典时,用for循环
for k,v in d.items():
print k,v
则会将元组中的数据打散输出。
在字典中,用:字典名.get("name")当字典中有值时返回,米有值时给定一个默认值。:字典名.get("name",100),没有name这个键就返回100
判断字典中有没有某一键且需要返回真假时,用:字典名.has_key('name'),true or false
字典也是引用赋值,仅是指向一块内存。字典没有切片,但是有copy,如:d4 = d2.copy。这种方式只是赋值了字典中所有的值, 不会改变内存中的数据。
字典中的数据改变直接用:字典名['name'] = '想改的内容'。


列表解析
有一个列表li = [1,2,3],要对解表中的所有数据+1,借助中间变量可以实现。定义一个新的变量j=0,for i in li:
li[j] = i+1
j += 1

就能成功。也可以直接列表解析:lib2 = [i+1 for i in li], 此处将i+1 赋值给了i。等于 for i in li:
li3.append(i+1)

如果在执行时, li2 = (i+1 for i in li)则生成一个迭代器, 可以用li2来执行li2.next。


带条件的列表解析,如 有 li = [1,2,3,4,5,6] li2 = [i+1 for i in li if i % 2 == 0]

遍历多个列表 [(i,x) for i in li for x in li2]。 li = [1,2,34,], li2 = [2,5,6,7]
得到的结果是笛卡尔积。















 107
107











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









