






准备:
1.扒网页,根据URL来获取网页信息
importurllib.parseimporturllib.request
response= urllib.request.urlopen("https://www.cnblogs.com")print(response.read())
urlopen方法
urlopen(url, data, timeout)
url即为URL,data是访问URL时要传送的数据,timeout是设置超时时间
返回response对象
response对象的read方法,可以返回获取到的网页内容
POST
importurllib.parseimporturllib.request
values= {"username":"XXX","password":"XXX"}
data=urllib.parse.urlencode(values)
data= data.encode(‘utf-8‘)
url= "https://passport.cnblogs.com/user/signin?ReturnUrl=https://home.cnblogs.com/&AspxAutoDetectCookieSupport=1"response=urllib.request.urlopen(url,data)print(response.read())
GET
importurllib.parseimporturllib.request
values= {"itemCount":30}
data=urllib.parse.urlencode(values)
data= data.encode(‘utf-8‘)
url= "https://news.cnblogs.com/CommentAjax/GetSideComments"data=urllib.parse.urlencode(values)
response= urllib.request.urlopen(url+‘?‘+data)print(response.read())
2.正则表达式re模块
Python 自带了re模块,提供了对正则表达式的支持
#返回pattern对象
re.compile(string[,flag])
#以下为匹配所用函数
re.match(pattern, string[, flags]) #在字符串中查找,是否能匹配正则表达式
re.search(pattern, string[, flags]) #字符串的开头是否能匹配正则表达式
re.split(pattern, string[, maxsplit]) #通过正则表达式将字符串分离
re.findall(pattern, string[, flags]) #找到 RE 匹配的所有子串,并把它们作为一个列表返回
re.finditer(pattern, string[, flags]) #找到 RE 匹配的所有子串,并把它们作为一个迭代器返回
re.sub(pattern, repl, string[, count]) #找到 RE 匹配的所有子串,并将其用一个不同的字符串替换
re.subn(pattern, repl, string[, count])#返回 (sub(repl, string[, count]), 替换次数)
3.Beautiful Soup,是从网页抓取数据的库,使用时需要导入 bs4 库
4.MongoDB
使用的MongoEngine库
示例:
抓取博客园数据,保存到MongoDB中
1.获取博客园的数据
request.py
importurllib.parseimporturllib.requestdefgetHtml(url):response_result=urllib.request.urlopen(url).read()
html= response_result.decode(‘utf-8‘)returnhtmldefrequestCnblogs(num):print(‘请求数据page:‘,num)
url= ‘https://www.cnblogs.com/#p‘+str(num)
result=getHtml(url)return result
注:
观察url
第一页https://www.cnblogs.com
第二页https://www.cnblogs.com/#p2
2.解析获取来的数据
deal.py
from bs4 importBeautifulSoupimportrequestimportredefblogParser(index):
cnblogs=request.requestCnblogs(index)
soup= BeautifulSoup(cnblogs, ‘html.parser‘)
all_div= soup.find_all(‘div‘, attrs={‘class‘: ‘post_item_body‘}, limit=20)
blogs=[]#循环div获取详细信息
for item inall_div:
blog=analyzeBlog(item)
blogs.append(blog)returnblogsdefanalyzeBlog(item):
result={}
a_title= find_all(item,‘a‘,‘titlelnk‘)if a_title is notNone:#博客标题
result["title"] =a_title[0].string#博客链接
result["link"] = a_title[0][‘href‘]
p_summary= find_all(item,‘p‘,‘post_item_summary‘)if p_summary is notNone:#简介
result["summary"] =p_summary[0].text
footers= find_all(item,‘div‘,‘post_item_foot‘)
footer=footers[0]#作者
result["author"] =footer.a.string
str=footer.text
time= re.findall(r"发布于 .+? .+?", str)
result["create_time"] = time[0].replace(‘发布于‘,‘‘)returnresultdeffind_all(item,attr,c):return item.find_all(attr,attrs={‘class‘:c},limit=1)
注:
分析html结构
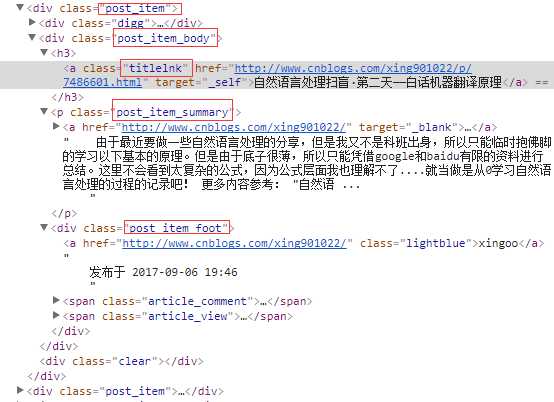
3.将处理好的数据保存到MongoDB
db.py
from mongoengine import *connect(‘test‘, host=‘localhost‘, port=27017)importdatetimeclassBlogs(Document):
title= StringField(required=True, max_length=200)
link= StringField(required=True)
author= StringField(required=True)
summary= StringField(required=True)
create_time= StringField(required=True)defsavetomongo(contents):for content incontents:
blog=Blogs(
title=content[‘title‘],
link= content[‘link‘],
author=content[‘author‘],
summary=content[‘summary‘],
create_time=content[‘create_time‘]
)
blog.save()return "ok"
defhaveBlogs():
blogs=Blogs.objects.all()return len(blogs)
4.开始抓取数据
test.py
importdbimportdealprint("start.......")for i in range(1, 21):
contents=deal.blogParser(i)
db.savetomongo(contents)print(‘page‘,i,‘OK.‘)
counts=db.haveBlogs()print("have",counts,"blogs")print("end.......")
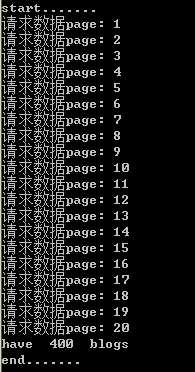
注:
当前使用的Python版本是3.6.1















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









