






Sql Server有三种物理连接Loop Join,Merge Join,Hash Join, 当表之间连接的时候会选择其中之一,不同的连接产生的性能不同,理解这三种物理连接对性能调优有很大帮助。
Nested Loop Join
简介
两表连接就相当于二重循环,从A表抽一条记录,遍历B表查找匹配记录,然后从a表抽下一条,遍历B表
例如:
IF OBJECT_ID('dbo.Tbl10') IS NOT NULL DROP TABLE dbo.Tbl10;
CREATE TABLE dbo.Tbl10(
Id INT IDENTITY(1,1),
Val INT,
Fill CHAR(7000) NOT NULL DEFAULT REPLICATE('Fill',1750)
);
IF OBJECT_ID('dbo.Tbl100') IS NOT NULL DROP TABLE dbo.Tbl100;
CREATE TABLE dbo.Tbl100(
Id INT IDENTITY(1,1),
Val INT,
Fill CHAR(7000) NOT NULL DEFAULT REPLICATE('Fill',1750)
);
INSERT INTO dbo.Tbl10(Val)
SELECT TOP(10) 1+ROW_NUMBER()OVER(ORDER BY (SELECT 1))%100
FROM sys.all_columns A, sys.all_columns B, sys.all_columns C;
INSERT INTO dbo.Tbl100(Val)
SELECT TOP(100) ROW_NUMBER()OVER(ORDER BY (SELECT 1))
FROM sys.all_columns A, sys.all_columns B, sys.all_columns C;
SELECT index_type_desc, alloc_unit_type_desc, index_depth, page_count, record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Tbl10'),NULL,NULL,'SAMPLED');
SELECT index_type_desc, alloc_unit_type_desc, index_depth, page_count, record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),OBJECT_ID('dbo.Tbl100'),NULL,NULL,'SAMPLED');
表被设计为每一行都占用一页。

通过上面查询结果可以看出表都没有聚集索引,执行下面代码:
SET STATISTICS IO ON;
GO
SELECT *
FROM dbo.Tbl100 A
INNER LOOP JOIN dbo.Tbl10 B
ON A.Val = B.Val;
GO
SET STATISTICS IO OFF;
查询中用到了loop 提示,所以使用的物理连接是nested loop join
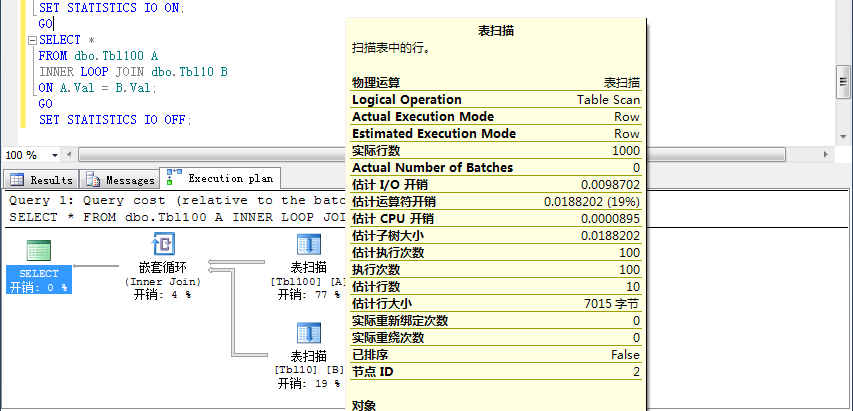
可以看到对表dbo.Tbl10扫描了100次,对外表dbo.Tbl100的每一行都扫描一次表dbo.Tbl10,可以通过SET STATISTICS IO ON,查看:
(10 row(s) affected)
Table 'Tbl10'. Scan count 1, logical reads 1000, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Tbl100'. Scan count 1, logical reads 100, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
因为在表Tbl10上的逻辑读是1000次,表一共有10页,所以整个表被读取了100次。
可以想象执行效率是很低的,我们可以在内层表上加上聚集索引优化查询,内层表如果没有索引就会表扫描,如果加了聚集索引就会使用索引查找。
在表Tbl10上添加聚集索引:
CREATE UNIQUE CLUSTERED INDEX [dbo.Tbl10(Val, Id) CL] ON dbo.Tbl10(Val, Id);
再次执行loop join查询

通过sys.dm_db_index_physical_stats 查看 index depth, index depth 决定了执行一次查找需要读多少次。

这个执行计划现在不算是一个真正的嵌套循环了。SQL Server仍然通过左输入循环一行一次。但它不循环第二个输入。相反,它是通过直接查找读取需要的行。然而,查找仍执行了100次。因此,我们可以预期200个读取发生在该表。让我们来看一下统计数据SET STATISTICS IO ON:
Table 'Tbl10'. Scan count 100, logical reads 227, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
Table 'Tbl100'. Scan count 1, logical reads 100, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
发现有227个读取,比预期的要多一些,这些额外的读取是因为需要访问额外的元数据页, 如IAM页(索引分配映射(Index Allocation Map:IAM)http://www.tuicool.com/articles/UVZ7Bj)。
Loop Join 优点和缺点:
- 跟merge join和hash join相比只有一步,merge join在join之前需要排序,hash join在join之前需要构建哈希表
- 只要找到一个匹配就立即返回。merge join在没有排完序之前不能返回,hash join在哈希表构建完成前也不能返回。
- 它是唯一的可以处理非等连接的算法。
- 在右输入上一个合适的索引可以节省大量的读取。
- 如果在右输入上没有可用的索引,必须完全读取每一行,使此算法非常昂贵(特别是在大数据集上)。
引用博客
http://sqlity.net/en/1471/a-join-a-day-the-nested-loops-join/
http://www.cnblogs.com/CareySon/archive/2013/01/09/2853094.html
http://www.2cto.com/database/201301/186885.html















 6070
6070











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









