






 本文介绍了推荐系统中的离线排序流程,利用逻辑回归(LR)模型进行点击率预估。数据集通过横向或纵向划分,模型训练与验证后更新到定时任务。评估指标包括AUC、分类准确率和召回率。最后展示了如何使用Spark构建训练集、训练LR模型及进行模型评估。
本文介绍了推荐系统中的离线排序流程,利用逻辑回归(LR)模型进行点击率预估。数据集通过横向或纵向划分,模型训练与验证后更新到定时任务。评估指标包括AUC、分类准确率和召回率。最后展示了如何使用Spark构建训练集、训练LR模型及进行模型评估。
排序流程包括离线排序和在线排序:
- 离线排序 读取前天(第 T - 2 天)之前的用户行为数据作为训练集,对离线模型进行训练;训练完成后,读取昨天(第 T - 1 天)的用户行为数据作为验证集进行预测,根据预测结果对离线模型进行评估;若评估通过,当天(第 T 天)即可将离线模型更新到定时任务中,定时执行预测任务;明天(第 T + 1 天)就能根据今天的用户行为数据来观察更新后离线模型的预测效果。(注意:数据生产有一天时间差,第 T 天生成第 T - 1 天的数据)
- 在线排序 读取前天(第 T - 2 天)之前的用户行为数据作为训练集,对在线模型进行训练;训练完成后,读取昨天(第 T - 1 天)的用户行为数据作为验证集进行预测,根据预测结果对在线模型进行评估;若评估通过,当天(第 T 天)即可将在线模型更新到线上,实时执行排序任务;明天(第 T + 1 天)就能根据今天的用户行为数据来观察更新后在线模型的预测效果。
这里再补充一个数据集划分的小技巧:可以横向划分,随机或按用户或其他样本选择策略;也可以纵向划分,按照时间跨度,比如一周的数据中,周一到周四是训练集,周五周六是测试集,周日是验证集。
利用排序模型可以进行评分预测和用户行为预测,通常推荐系统利用排序模型进行用户行为预测,比如点击率(CTR)预估,进而根据点击率对物品进行排序,目前工业界常用的点击率预估模型有如下 3 种类型:
- 宽模型 + 特征⼯程 LR / MLR + 非 ID 类特征(⼈⼯离散 / GBDT / FM),可以使用 Spark 进行训练
- 宽模型 + 深模型 Wide&Deep,DeepFM,可以使用 TensorFlow 进行训练
- 深模型:DNN + 特征 Embedding,可以使用 TensorFlow 进行训练
这里的宽模型即指线性模型,线性模型的优点包括:
- 相对简单,训练和预测的计算复杂度都相对较低
- 可以集中精力发掘新的有效特征,且可以并行化工作
- 解释性较好,可以根据特征权重做解释
本文我们将采用逻辑回归作为离线模型,进行点击率预估。逻辑回归(Logistic Regression,LR)是基础的二分类模型,也是监督学习的一种,通过对有标签的训练集数据进行特征学习,进而可以对测试集(新数据)的标签进行预测。我们这里的标签就是指用户是否对文章发生了点击行为。
构造训练集
读取用户历史行为数据,将 clicked 作为训练集标签
spark.sql("use profile")user_article_basic = spark.sql("select * from user_article_basic").select(['user_id', 'article_id', 'clicked'])user_article_basic 结果如下所示
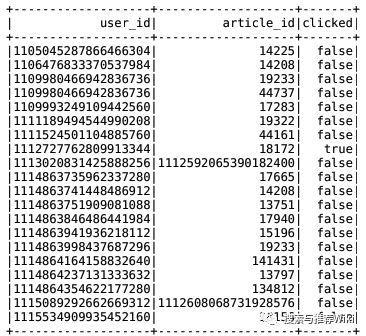
user_article_basic
之前我们已经计算好了文章特征和用户特征,并存储到了 Hbase 中。这里我们遍历用户历史行为数据,根据其中文章 ID 和用户 ID 分别获取文章特征和用户特征,再将标签转为 int 类型,这样就将一条用户行为数据构造成为了一个样本,再将所有样本加入到训练集中
train = []for user_id, article_id, clicked in user_article_basic: try: article_feature = eval(hbu.get_table_row('ctr_feature_article', '{}'.format(article_id).encode(), 'article:{}'.format(article_id).encode())) except Exception as e: article_feature = [] try: user_feature = eval(hbu.get_table_row('ctr_feature_user', '{}'.format(temp.user_id).encode(), 'channel:{}'.format(temp.channel_id).encode())) except Exception as e: user_feature = [] if not article_feature: article_feature = [0.0] * 111 if not user_feature: user_feature = [0.0] * 10 sample = [] sample.append(user_feature) sample.append(article_feature) sample.append(int(clicked)) train.append(sample)接下来,还需要利用 Spark 的 Vectors 将 array 类型的 article_feature 和 user_feature 转为 vector 类型
columns = ['article_feature', 'user_feature', 'clicked']def list_to_vector(row): from pyspark.ml.linalg import Vectors return Vectors.dense(row[0]), Vectors.dense(row[1]), row[2]train = train.rdd.map(list_to_vector).toDF(columns)再将 article_feature, user_feature 合并为统一输入到 LR 模型的特征列 features,这样就完成训练集的构建
train = VectorAssembler().setInputCols(columns[0:1]).setOutputCol('features').transform(train)模型训练
Spark 已经实现好了 LR 模型,通过指定训练集 train 的特征列 features 和标签列 clicked,即可对 LR 模型进行训练,再将训练好的模型保存到 HDFS
from pyspark.ml.feature import VectorAssemblerfrom pyspark.ml.classification import LogisticRegressionlr = LogisticRegression()model = lr.setLabelCol("clicked").setFeaturesCol("features").fit(train)model.save("hdfs://hadoop-master:9000/headlines/models/lr.obj")加载训练好的 LR 模型,调用 transform() 对训练集做出预测(实际场景应该对验证集和训练集进行预测)
from pyspark.ml.classification import LogisticRegressionModelonline_model = LogisticRegressionModel.load("hdfs://hadoop-master:9000/headlines/models/lr.obj")sort_res = online_model.transform(train)预测结果 sort_res 中包括 clicked 和 probability 列,其中 clicked 为样本标签的真实值,probability 是包含两个元素的列表,第一个元素是预测的不点击概率,第二个元素则是预测的点击概率,可以提取点击率(CTR)
def get_ctr(row): return float(row.clicked), float(row.probability[1])score_label = sort_res.select(["clicked", "probability"]).rdd.map(get_ctr)模型评估
离线模型评估指标包括:
- 评分准确度 通常是均方根误差(RMSE),用来评估预测评分的效果
- 排序能力 通常采用 AUC(Area Under the Curve),即 ROC 曲线下方的面积
- 分类准确率(Precision) 表示在 Top K 推荐列表中,用户真实点击的物品所占的比例
- 分类召回率(Recall) 表示在用户真实点击的物品中,出现在 Top K 推荐列表中所占的比例
当模型更新后,还可以根据商业指标进行评估,比例类的包括:点击率(CTR)、转化率(CVR),绝对类的包括:社交关系数量、用户停留时长、成交总额(GMV)等。
推荐系统的广度评估指标包括:
- 覆盖率 表示被有效推荐(推荐列表长度大于 c)的用户占全站用户的比例,公式如下:


我们这里主要根据 AUC 进行评估,首先利用 model.summary.roc 绘制 ROC 曲线
import matplotlib.pyplot as pltplt.figure(figsize=(5,5))plt.plot([0, 1], [0, 1], 'r--')plt.plot(model.summary.roc.select('FPR').collect(), model.summary.roc.select('TPR').collect())plt.xlabel('FPR')plt.ylabel('TPR')plt.show()ROC 曲线如下所示,曲线下面的面积即为 AUC(Area Under the Curve),AUC 值越大,排序效果越好
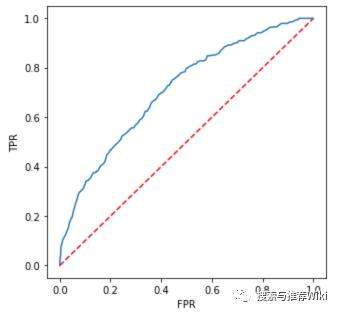
利用 Spark 的 BinaryClassificationMetrics() 计算 AUC
from pyspark.mllib.evaluation import BinaryClassificationMetricsmetrics = BinaryClassificationMetrics(score_label)metrics.areaUnderROC也可以利用 sklearn 的 roc_auc_score() 计算 AUC,accuracy_score() 计算准确率
from sklearn.metrics import accuracy_score, roc_auc_score,import numpy as nparr = np.array(score_label.collect())# AUCroc_auc_score(arr[:, 0], arr[:, 1]) # 0.719274521004087# 准确率accuracy_score(arr[:, 0], arr[:, 1].round()) # 0.9051438053097345

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









