






一.简介
nagiso是一个非常灵活的监控系统,可以监控常见的各种服务以及服务器的运行状态,并在监测到服务器发生故障的情况下,使用各种不同的方式通知维护人员发生了何种故障。目前nagios支持如下几种报警方式:邮件、MSN、QQ、短信、飞信。
nagios只提供了一个监控平台,实际上nagios本身并不提供任何工具来对服务器进行报警,也不提供发送报警信息的代码,所有这些功能都是由插件来实现的。nagios可以很好地整合所有的插件一起高效的工作。通过分工合作来实现一个完善的监控机制。
Nagios特征包括:
1.监控网络服务(SMTP、POP3、HTTP、SSH、mysql、NNTP、PING等);
2.监控主机资源(处理器负荷、磁盘利用率等);
3.简单地插件设计使得用户可以方便地扩展自己服务的检测方法;
4.并行服务检查机制;
5.具备定义网络分层结构的能力,用"parent"主机定义来表达网络主机间的关系,这种关系可被用来发现和明晰主机宕机或不可达状态;
6.当服务或主机问题产生与解决时将告警发送给联系人(通过EMail、短信、用户定义方式);
7.具备定义事件句柄功能,它可以在主机或服务的事件发生时获取更多问题定位;
8.自动的日志回滚;
9.可以支持并实现对主机的冗余监控;
10.可选的WEB界面用于查看当前的网络状态、通知和故障历史、日志文件等;
1.监控网络服务(SMTP、POP3、HTTP、SSH、mysql、NNTP、PING等);
2.监控主机资源(处理器负荷、磁盘利用率等);
3.简单地插件设计使得用户可以方便地扩展自己服务的检测方法;
4.并行服务检查机制;
5.具备定义网络分层结构的能力,用"parent"主机定义来表达网络主机间的关系,这种关系可被用来发现和明晰主机宕机或不可达状态;
6.当服务或主机问题产生与解决时将告警发送给联系人(通过EMail、短信、用户定义方式);
7.具备定义事件句柄功能,它可以在主机或服务的事件发生时获取更多问题定位;
8.自动的日志回滚;
9.可以支持并实现对主机的冗余监控;
10.可选的WEB界面用于查看当前的网络状态、通知和故障历史、日志文件等;
常用的nagios系统一般组成:nagios、nagios-plugs、nrpe、nsclient
一个典型的架构如下图所示:
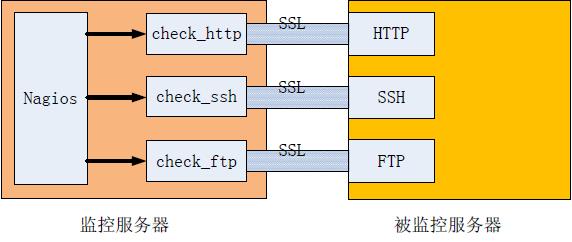
上面架构只能监控到服务器的外部服务,如HTTP、SSH、FTP,要实现对本地信息的监控可以通过在被监控服务器上安装NRPE服务,作为监控代理来实现对本地信息的监控,架构如下:

NRPE 由两个部分组成:工作在监控机一侧的check_nrpe 插件、工作在被监控机一侧的NRPE 守护进程。
Nagios 服务器执行check_nrpe 插件并告诉他检查哪个服务,check_nrpe 插件通过SSL 连接方式联系远程服务器上的NRPE 守护进程,NRPE 守护进程执行相应的插件完成指定的检查,并返回结果。
nagios相关软件下载地址 http://sourceforge.net/projects/nagios/files/
nagios汉化版下载 http://sourceforge.net/projects/nagios-cn/files/,nagios中文手册 http://nagios-cn.sourceforge.net/nagios-cn/Nagios-cn.html,感谢汉化者田朝阳
nagios相关软件下载地址 http://sourceforge.net/projects/nagios/files/
nagios汉化版下载 http://sourceforge.net/projects/nagios-cn/files/,nagios中文手册 http://nagios-cn.sourceforge.net/nagios-cn/Nagios-cn.html,感谢汉化者田朝阳
相关rpm包下载:http://rpmfind.net/linux/rpm2html/search.php
安装步骤:
1. 安装运行环境
yum install httpd php php-devel
yum install httpd php php-devel
yum install gcc glibc glibc-common
yum install gd gd-devel libpng libpng-devel libjpeg libjpeg-devel zlib zlib-devel
2.安装nagios并配置web访问
useradd nagios
usermod –G nagios apache //把apache 用户加入nagios 组,如果省略这一步会在后续的操作中产生一些问题
./configure --prefix=/usr/local/nagios --with-gd-lib=/usr/lib --with-gd-inc=/usr/include
//下面根据提示操作
make all
make install //安装nagios 主程序、CGI 和HTML 文件
make install-init //安装nagios 的启动脚本
make install-commandmode //安装外部命令使用的目录,并配置目录权限
make install-config //安装样板配置文件,位于/usr/local/nagios/etc 目录下
make install-webconf //安装apache 配置文件,以便能够通过web 页面访问nagios
htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadmin //创建web验证登录用户
service httpd restart
测试:用http://监控机IP/nagios 看能否用nagiosadmin登录
nagios 安装完毕检查/usr/local/nagios 目录下是否存在如下子目录

chkconfig --add nagios //将nagios加为系统服务
chkconfig nagios on //设置开机自启动
/usr/local/nagios/bin/nagios ‐v /usr/local/nagios/etc/nagios.cfg //验证Nagios的配置文件
如果没有报错,可以启动Nagios服务 service nagios start
3.安装插件nagios-plugin(用来实现各种监控取值的程序)
tar -zxvf nagios-plugins-1.4.15.tar.gz
./configure --prefix=/usr/local/nagios
make && make install
安装后查看/usr/local/nagios/libexec/目录,会显示安装的所有插件

4.监控机、被监控机(Linux/Unix机)上安装nrpe(如果只需要监控服务可以不装这个)
tar –zxvf nrpe-2.12.tar.gz
./configure --prefix=/usr/local/nagios --with-
make all
make install-plugin (在被监控机安装时先useradd nagios否则会出错)
make install-daemon
make install-daemon-config
make install-xinetd
//安装为xinetd服务
vim /etc/xinetd.d/nrpe
only_from = 127.0.0.1 10.1.10.23(监控机的ip地址)
vi /etc/services 增加如下一行
nrpe 5666/tcp # NRPE
chkconfig nrpe on
service xinetd restart
NRPE 测试
在被监控机上确认服务是否启动
netstat -at|grep nrpe
tcp 0 0 *:nrpe *:* LISTEN
在监控机上测试被监控机的NRPE 工作是否正常
/usr/local/nagios/libexec/check_nrpe -H
被监控机
IP
NRPE v2.12 //显示NRPE 版本信息,说明NRPE 工作正常
安装完毕接下来开始配置操作
安装完毕接下来开始配置操作
对nagios 进行配置需要了解一个概念object(对象),nagios 使用object 来对各种信息进行组织,nagios 中的包含如下obeject:


在配置前先来说明下需要修改的各配置文件的作用:
配置文件都存放在安装目录下的etc/下面
cgi.cfg 用于定义浏览器对nagios操作,比如权限控制等
nagios.cfg 用于定义控制nagios行为
nrpe.cfg nrpe配置文件
resource.cfg 资源配置文件,用于定义插件路径,一般不需修改
objects目录 监控对象配置文件存放于下面,配置文件可以自己添加,文件名可以自行定义,只要以.cfg结尾就行,但是必须在nagios.cfg加一行代码使nagios读取这个文件,例如你可以新建个linux.cfg来添加linux监控设备,nagios.cfg应该添加一行“cfg_file=/usr/local/nagios/etc/objects/linux.cfg”,一般同一类设备写到一个文件里,当然也可以对默认的文件进行修改来添加监控设备,此目录下默认有下面几个文件
commands.cfg 命令定义配置文件
contacts.cfg 定义联系人列表
timeperiods.cfg 定义时间监控模板
templates.cfg 定义各种模板,可以是主机模板、联系人模板、监控服务模板等
localhost.cfg 用于定义linux监控设备
windows.cfg 用于定义windows监控设备
switch.cfg 用于定义交换机,路由器等监控设备
printer.cfg 用于定义打印机监控设备
5.添加监控设备
(1)监控linux服务器
vi /usr/local/nagios/etc/objects/localhost.cfg 根据需要定义监控主机及监控内容
下面是个比较全的主机模板,可以在/usr/local/nagios/etc/objects/templates.cfg中找到适合的模板
use model_host //定义用的模板机
host_name host_name(*) //定义主机名,可起任意名字
alias alias(*) //定义主机别名
display_name display_name // 定义显示名字
address address(*) //主机名对应的ip 地址
parents host_names //定义父节点
hostgroups hostgroup_names //定义主机组名
check_command command_name //检查主机状态的命令
initial_state [o,d,u] //初始化状态
max_check_attempts #(*) //当检查命令返回值不是“OK”时最大重试次数
check_interval # //#分钟进行一次检查
retry_interval # //重试间隔时间
active_checks_enabled [0/1] //主动监控开关(1开0闭)
passive_checks_enabled [0/1] //被动监控开关
check_period timeperiod_name(*) //主机状态检查的时间段
obsess_over_host [0/1] //是否启用主机操作系统探测
check_freshness [0/1] // 是否启用 freshness 检查。freshness 检查是对于启用被动检查模式的主机而言的,其作用是定期检查主机报告的状态信息,如果该状态信息已经过期,freshness 将会强制做主机检查。freshness_threshold #
event_handler command_name
event_handler_enabled [0/1] //主机事件处理是否激活
low_flap_threshold #
high_flap_threshold #
flap_detection_enabled [0/1]
flap_detection_options [o,d,u]
process_perf_data [0/1]
retain_status_information [0/1]
retain_nonstatus_information [0/1]
contacts contacts(*) //发送报警通知给谁
contact_groups contact_groups(*) //发送通知给哪个报警组
notification_interval #(*) //主机状态通知功能激活
first_notification_delay #
notification_period timeperiod_name(*) //发送通知的时间段
notification_options [d,u,r,f,s] //定义那些情况下发送通知
notifications_enabled [0/1] //发送通告开关
stalking_options [o,d,u]
notes note_string
notes_url url
action_url url
icon_p_w_picpath p_w_picpath_file //定义主机图标
icon_p_w_picpath_alt alt_string
vrml_p_w_picpath p_w_picpath_file
statusmap_p_w_picpath p_w_picpath_file
2d_coords x_coord,y_coord //定义图标在网页中显示的二维坐标
3d_coords x_coord,y_coord,z_coord //定义图标在网页中显示的三维坐标
...
}
定义样例:
define host{
host_name web1
alias web1
address 192.168.1.254
parents router1
check_command check-host-alive
check_interval 5
retry_interval 1
max_check_attempts 5
check_period 24x7
process_perf_data 0
retain_nonstatus_information 0
contact_groups router-admins
notification_interval 30
notification_period 24x7
notification_options d,u,r
}
根据需要还可定义主机组
样例:
define hostgroup{ //定义主机组
hostgroup_name tianway.net ; //定义主机组的名字
alias Linux Server ;//别名
members 192.168.0.2,192.168.0.3,192.168.0.4 ; //组成员,使用逗号分隔
}
接下来根据需要定义要监控的服务和服务组,哪台设备要监控什么服务就在那个服务定义里的host_name中添加在主机定义中的主机名就行,多台设备之间用逗号隔开,下面是一些常用服务和系统状态定义
define service{ //定义监控ping
use local-service
host_name *
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service{ //定义监控根分区
use local-service
host_name web1
service_description 根分区
check_command check_local_disk!20%!10%!/
}
define service{ //定义监控登录用户数
use local-service
host_name web1
service_description 登录用户数
check_command check_local_users!20!50
}
define service{ //定义监控进程数
use local-service ;
host_name web1
service_description 进程总数
check_command check_local_procs!250!400!RSZDT
}
define service{ //定义监控系统负荷
use local-service
host_name web1
service_description 系统负荷
check_command check_local_load!5.0,4.0,3.0!10.0,6.0,4.0
}
define service{ //定义监控swap利用率
use local-service
host_name web1
service_description 交换空间利用率
check_command check_local_swap!20!10
}
define service{ //定义监控SSH服务
use local-service
host_name web1
service_description SSH
check_command check_tcp!22!1.0!10.0
notifications_enabled 1
}
define service{ //定义监控HTTP服务
use local-service
host_name web1
service_description HTTP
check_command check_http
notifications_enabled 1
}
define servicegroup{
servicegroup_name 系统负荷检查
alias 负荷检查
members web1,进程总数,web1,登录用户数,web1,根分区,web1,交换空间利用率,web1,PING
} //服务组定义members格式:主机名1,服务名,主机名2,服务名……
配置好后/usr/local/nagios/bin/nagios ‐v /usr/local/nagios/etc/nagios.cfg检查有无错误并重启nagios服务
(2)监控windows监控设备
首先在Windows机器上安装代理NSClient++构件,注意被监控机操作系统是32位还是64位,要安装对应版本的NSClient++

安装到这一步时,文档不用安装,安了也看不懂都是鸟语,下面plguins选项中,nsca选择"用时再安装",这个在分步式监控时才用到,nrpe支持就是windows版本的nrpe监控代理,你可以选择用它代理监控windows机,也可以用nsclient,两个都安装吧,到时两个都能用,如果用nrpe的话同监控linux机一样设置,这里我们用nsclient监控windows机。
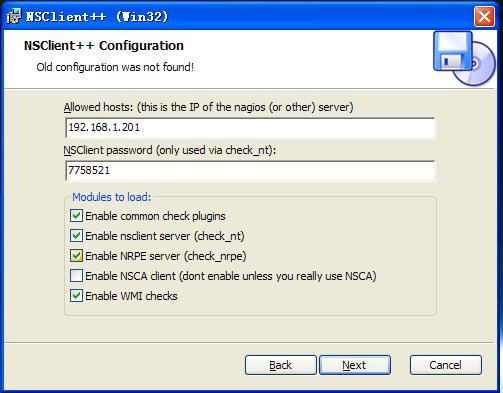
在这里要填写监控机IP,设置监控机连接时要用的密码,不设密码为空,为了更安全可以设上,但我觉得没必要设,因为你只允许监控机连接你的nsclietn++了,别的机器是拒绝连接的,除非别人知道你的监控机IP,然后伪造个相同ip来偷偷监控你的windows机器,这概率应该很小吧,设上后监控端要做相应的设置才能正常连接windows被监控机,比较麻烦。个人愚见至于加不加密码自己决定。下面的模块加载与否也是自己决定。
如果加上密码在监控机中要修改nagios安装目录下的etc/objects/commands.cfg修改chect_nt命令定义部分,加个-s 后跟连接密码,注意在这里修改的前提是每个nsclient设置的密码都是相同的,如果设置的不同则不能改这里,则需要改etc/objects/windows.cfg中的服务定义部分。
define command{
command_name check_nt
command_line $USER1$/check_nt -H $HOSTADDRESS$ -p 12489 -s 7758521 -v $ARG1$ $ARG2$
}
下面配置监控机上监控windows机的设置
vi /usr/local/nagios/etc/nagios.cfg 把下面这行最前面的#号去掉,只用第一次加windows监控机时修改
#cfg_file=/usr/local/nagios/etc/objects/windows.cfg
vi /usr/local/nagios/etc/objects/windows.cfg 定义主机及监控内容
define host{
use windows-server
host_name winserver
alias My Windows Server
address 192.168.1.2
}
下面根据需要选择性加服务定义以使Nagios监控Windows机器上的不同属性内容。如果是第一台Windows机器,可以只是修改windows.cfg里的服务对象定义。
加入下面的服务定义以监控运行于Windows机器上的NSClient++外部构件的版本。当到时间要升级Windows机器上的外部构件时这信息会很用有,因为它可以告知这台Windows机器上的NSClient++需要升级到最新版本。
define service{
use generic-service
host_name winserver
service_description NSClient++ Version
check_command check_nt!CLIENTVERSION
}
加入下面的服务定义以监控Windows机器的启动后运行时间。
define service{
use generic-service
host_name winserver
service_description Uptime
check_command check_nt!UPTIME
}
加入下面的服务定义可监控Windows机器的CPU利用率,并在5分钟CPU负荷高于90%时给出一个紧急警报或是高于80%时给出一个告警警报。
define service{
use generic-service
host_name winserver
service_description CPU Load
check_command check_nt!CPULOAD!-l 5,80,90
}
加入下面的服务定义可监控Windows机器的内存占用率,并在5分钟内存占用率高于90%时给出一个紧急警报或是高于80%时给出一个告警警报。
define service{
use generic-service
host_name winserver
service_description Memory Usage
check_command check_nt!MEMUSE!-w 80 -c 90
}
加入下面的服务定义可监控Windows机器的C:盘的磁盘利用率,并在磁盘利用率高于90%时给出一个紧急警报或是高于80%时给出一个告警警报。
define service{
use generic-service
host_name winserver
service_description C:\ Drive Space
check_command check_nt!USEDDISKSPACE!-l c -w 80 -c 90
} //把红色c换成d就是监控d盘
加入下面的服务定义可监控Windows机器上的W3SVC服务(IIS的3w网站服务)状态,并在W3SVC服务停止时给出一个紧急警报。
define service{
use generic-service
host_name winserver
service_description W3SVC
check_command check_nt!SERVICESTATE!-d SHOWALL -l W3SVC
} // W3SVC替换成别的服务名就是监控那个服务
加入下面的服务定义可监控Windows机器上的Explorer.exe进程,并在进程没有运行时给出一个紧急警报。
define service{
use generic-service
host_name winserver
service_description Explorer
check_command check_nt!PROCSTATE!-d SHOWALL -l Explorer.exe
} // Explorer.exe换成那个进程就是监控那个进程
配置好后/usr/local/nagios/bin/nagios ‐v /usr/local/nagios/etc/nagios.cfg检查有无错误并重启nagios服务
如果配置好了但监控机取不到值,可以用libexec/check_nt手动调试一下,看能否取到值
check_nt用法如下:
check_nt -H host -v variable [-p port] [-w warning] [-c critical] [-l params] [-d SHOWALL] [-u] [-t timeout]
选项:
-H 后跟被监控机主机名或IP
-p 后跟被监控nsclient端口号,默认是12489(必需有这个选项否则显示连接拒绝)
-s 后跟连接密码
-w 后跟wanring报警值
-c 后跟critical报警值
-t 后跟连接尝试次数
-h 显示帮助
-V 显示check_nt版本
-v 后跟要查看的性能值
可用的性能值有:
CLIENTVERSION 显示nsclient++版本
CPULOAD -l <minutes range>,<warning threshold>,<critical threshold>.
注意:<minute range> 不要大于 24*60.
例: -l 60,90,95,120,90,95 显示最后60分钟和120分钟waring为90%,critical为95%的平均cpuload
UPTIME 显示开机运行时间
USEDDISKSPACE 显示磁盘空间信息
例:-l c 显示当前c盘空间使用信息
-l d -w 90 -c 95 显示d盘设waring为90%,critical为95%时的空间使用信息
MEMUSE 显示内存使用情况,后可跟-w -c指定报警值,默认为5分钟内平均值
SERVICESTATE 检查一个或多个服务状态
-l <service1>,<service2>,<service3>,...
用 -d SHOWALL 可以查看正在运行有服务
PROCSTATE 检查进程状态
-l <进程名字>
COUNTER 检查一些性能计数
用法:
-l " \\<performance object>\\counter","<description>
<description> 参数用于打印输出一个需要浮点参数的命令 ,如果 <description>不包含 "%%", 它会做为一个标签
例: "Paging file usage is %%.2f %%%%"
"%%.f %%%% paging file used."
INSTANCES 检查性能对象计数
用法: check_nt -H <hostname> -p <port> -v INSTANCES -l <counter object>
<counter object> 是一个windows性能对象计数 (eg. Process),
如果它是两个词,它应该引号括起来,返回的结果将是一个逗号分隔的对象
check_nt用法举例:
check_nt -H 192.168.1.2 -p 12489 -v CPULOAD -l 60,90,95 //显示最后60分钟waring为90%,critical为95%时的平均cpuload
check_nt -H 192.168.1.2 -p 12489 -v UPTIME //显示192.168.1.2从开机到现在运行时间
check_nt -H 192.168.1.2 -p 12489 -v USEDDISKSPACE -l c //显示192.168.1.2 C盘使用情况
check_nt -H 192.168.1.2 -p 12489 -v USEDDISKSPACE -l d -w 60 -c 95 //显示192.168.1.2 D盘设waring为90%,critical为95%时的空间使用信息
check_nt -H 192.168.1.2 -p 12489 -v MEMUSE //显示192.168.1.2内存使用情况
check_nt -H 192.168.1.2 -p 12489 -v SERVICESSTATE -d SHOWALL //显示192.168.1.2所有正在运行的服务
check_nt -H 192.168.1.2 -p 12489 -v SERVICESSTATE -d SHOWALL -l W3SVC //显示192.168.1.2上IIS网站服务运行情况
check_nt -H 192.168.1.2 -p 12489 –s 7758521 –v CLIENTVERSION //查看192.168.1.2上nsclient++版本
check_nt -H 192.168.1.2 -p 12489 –s 7758521 -v INSTANCES -l Process //列举192.168.1.2上运行的进程
(3)监控路由器、交换机
vi /usr/local/nagios/etc/nagios.cfg 移除文件里下面这行的最前面的#号
#cfg_file=/usr/local/nagios/etc/objects/switch.cfg
vi /usr/local/nagios/etc/objects/switch.cfg 定义网络设备
define host{
define service{
use generic-service
host_name winserver
service_description NSClient++ Version
check_command check_nt!CLIENTVERSION
}
加入下面的服务定义以监控Windows机器的启动后运行时间。
define service{
use generic-service
host_name winserver
service_description Uptime
check_command check_nt!UPTIME
}
加入下面的服务定义可监控Windows机器的CPU利用率,并在5分钟CPU负荷高于90%时给出一个紧急警报或是高于80%时给出一个告警警报。
define service{
use generic-service
host_name winserver
service_description CPU Load
check_command check_nt!CPULOAD!-l 5,80,90
}
加入下面的服务定义可监控Windows机器的内存占用率,并在5分钟内存占用率高于90%时给出一个紧急警报或是高于80%时给出一个告警警报。
define service{
use generic-service
host_name winserver
service_description Memory Usage
check_command check_nt!MEMUSE!-w 80 -c 90
}
加入下面的服务定义可监控Windows机器的C:盘的磁盘利用率,并在磁盘利用率高于90%时给出一个紧急警报或是高于80%时给出一个告警警报。
define service{
use generic-service
host_name winserver
service_description C:\ Drive Space
check_command check_nt!USEDDISKSPACE!-l c -w 80 -c 90
} //把红色c换成d就是监控d盘
加入下面的服务定义可监控Windows机器上的W3SVC服务(IIS的3w网站服务)状态,并在W3SVC服务停止时给出一个紧急警报。
define service{
use generic-service
host_name winserver
service_description W3SVC
check_command check_nt!SERVICESTATE!-d SHOWALL -l W3SVC
} // W3SVC替换成别的服务名就是监控那个服务
加入下面的服务定义可监控Windows机器上的Explorer.exe进程,并在进程没有运行时给出一个紧急警报。
define service{
use generic-service
host_name winserver
service_description Explorer
check_command check_nt!PROCSTATE!-d SHOWALL -l Explorer.exe
} // Explorer.exe换成那个进程就是监控那个进程
配置好后/usr/local/nagios/bin/nagios ‐v /usr/local/nagios/etc/nagios.cfg检查有无错误并重启nagios服务
如果配置好了但监控机取不到值,可以用libexec/check_nt手动调试一下,看能否取到值
check_nt用法如下:
check_nt -H host -v variable [-p port] [-w warning] [-c critical] [-l params] [-d SHOWALL] [-u] [-t timeout]
选项:
-H 后跟被监控机主机名或IP
-p 后跟被监控nsclient端口号,默认是12489(必需有这个选项否则显示连接拒绝)
-s 后跟连接密码
-w 后跟wanring报警值
-c 后跟critical报警值
-t 后跟连接尝试次数
-h 显示帮助
-V 显示check_nt版本
-v 后跟要查看的性能值
可用的性能值有:
CLIENTVERSION 显示nsclient++版本
CPULOAD -l <minutes range>,<warning threshold>,<critical threshold>.
注意:<minute range> 不要大于 24*60.
例: -l 60,90,95,120,90,95 显示最后60分钟和120分钟waring为90%,critical为95%的平均cpuload
UPTIME 显示开机运行时间
USEDDISKSPACE 显示磁盘空间信息
例:-l c 显示当前c盘空间使用信息
-l d -w 90 -c 95 显示d盘设waring为90%,critical为95%时的空间使用信息
MEMUSE 显示内存使用情况,后可跟-w -c指定报警值,默认为5分钟内平均值
SERVICESTATE 检查一个或多个服务状态
-l <service1>,<service2>,<service3>,...
用 -d SHOWALL 可以查看正在运行有服务
PROCSTATE 检查进程状态
-l <进程名字>
COUNTER 检查一些性能计数
用法:
-l " \\<performance object>\\counter","<description>
<description> 参数用于打印输出一个需要浮点参数的命令 ,如果 <description>不包含 "%%", 它会做为一个标签
例: "Paging file usage is %%.2f %%%%"
"%%.f %%%% paging file used."
INSTANCES 检查性能对象计数
用法: check_nt -H <hostname> -p <port> -v INSTANCES -l <counter object>
<counter object> 是一个windows性能对象计数 (eg. Process),
如果它是两个词,它应该引号括起来,返回的结果将是一个逗号分隔的对象
check_nt用法举例:
check_nt -H 192.168.1.2 -p 12489 -v CPULOAD -l 60,90,95 //显示最后60分钟waring为90%,critical为95%时的平均cpuload
check_nt -H 192.168.1.2 -p 12489 -v UPTIME //显示192.168.1.2从开机到现在运行时间
check_nt -H 192.168.1.2 -p 12489 -v USEDDISKSPACE -l c //显示192.168.1.2 C盘使用情况
check_nt -H 192.168.1.2 -p 12489 -v USEDDISKSPACE -l d -w 60 -c 95 //显示192.168.1.2 D盘设waring为90%,critical为95%时的空间使用信息
check_nt -H 192.168.1.2 -p 12489 -v MEMUSE //显示192.168.1.2内存使用情况
check_nt -H 192.168.1.2 -p 12489 -v SERVICESSTATE -d SHOWALL //显示192.168.1.2所有正在运行的服务
check_nt -H 192.168.1.2 -p 12489 -v SERVICESSTATE -d SHOWALL -l W3SVC //显示192.168.1.2上IIS网站服务运行情况
check_nt -H 192.168.1.2 -p 12489 –s 7758521 –v CLIENTVERSION //查看192.168.1.2上nsclient++版本
check_nt -H 192.168.1.2 -p 12489 –s 7758521 -v INSTANCES -l Process //列举192.168.1.2上运行的进程
(3)监控路由器、交换机
vi /usr/local/nagios/etc/nagios.cfg 移除文件里下面这行的最前面的#号
#cfg_file=/usr/local/nagios/etc/objects/switch.cfg
vi /usr/local/nagios/etc/objects/switch.cfg 定义网络设备
define host{
use generic-switch
host_name linksys-srw224p
alias Linksys SRW224P Switch
address 192.168.1.253
hostgroups allhosts,switches
}
//监控丢包率和RTA
增加如下的服务定义以监控自Nagios监控主机到交换机的丢包率和平均回包周期RTA,在一般情况下每5分钟检测一次。
define service{
use generic-service
host_name linksys-srw224p
service_description PING
check_command check_ping!200.0,20%!600.0,60%
normal_check_interval 5
retry_check_interval 1
}
解释:这个服务的状态将会处于:
紧急(CRITICAL)-条件是RTA大于600ms或丢包率大于等于60%;
告警(WARNING)-条件是RTA大于200ms或是丢包率大于等于20%;
正常(OK)-条件是RTA小于200ms或丢包率小于20%
//监控SNMP状态信息
如果交换机与路由器支持SNMP接口,可以用check_snmp插件来监控更丰富的信息。
define service{
use generic-service
host_name linksys-srw224p
service_description Uptime
check_command check_snmp!-C public -o sysUpTime.0
}
在上述服务定义中的check_command域里,用"-C public"来指定SNMP共同体名称为"public",用"-o sysUpTime.0"指明要检测的OID(译者注-MIB节点值)。
如果要确保交换机上某个指定端口或接口的状态处于运行状态,可以在对象定义里加入一段定义:
define service{
use generic-service
host_name linksys-srw224p
service_description Port 1 Link Status
check_command check_snmp!-C public -o ifOperStatus.1 -r 1 -m RFC1213-MIB
}
在上例中,"-o ifOperStatus.1"指出取出交换机的端口编号为1的OID状态。"-r 1"选项是让check_snmp插件检查返回一个正常(OK)状态,如果是在SNMP查询结果中存在"1"(1说明交换机端口处于运行状态)如果没找到1就是紧急(CRITICAL)状态。"-m RFC1213-MIB"是可选的,它告诉check_snmp插件只加载"RFC1213-MIB"库而不是加载每个在系统里的MIB库,这可以加快插件运行速度。
有成百上千种信息可以通过SNMP来监控,这完全取决于你需要做什么和如果来做监控。通常可以用如下命令来寻找你想用于监控的OID节点(用你的交换机IP替换192.168.1.253):snmpwalk -v1 -c public 192.168.1.253 -m ALL .1
在H3C系列的交换机中配置snmp
# 设置团体、群组和用户。
<H3C> system-view
[H3C] snmp-agent
[H3C] snmp-agent sys-info version all
[H3C] snmp-agent community write public
[H3C] snmp-agent mib-view include internet 1.3.6.1
[H3C] snmp-agent group v3 managev3group write-view internet
[H3C] snmp-agent usm-user v3 managev3user managev3group
# 允许向网管工作站192.168.1.1发送Trap报文,使用的团体名为public。
[H3C] snmp-agent trap enable standard authentication
[H3C] snmp-agent trap enable standard coldstart
[H3C] snmp-agent trap enable standard linkup
[H3C] snmp-agent trap enable standard linkdown
[H3C] snmp-agent target-host trap address udp-domain 192.168.1.1 udp-port 5000 params securityname publi
//监控带宽和流量
可以监控交换机或路由器的带宽利用率,用
MRTG
绘图并让Nagios在流量超出指定门限时报警。check_mrtgtraf插件可以实现。需要让check_mrtgtraf插件知道如何来保存MRTG数据并存入文件,以及门限等。在例子中,监控了一个Linksys交换机。MRTG日志保存于/var/lib/mrtg/192.168.1.253_1.log文件中。这就是我用于监控的服务定义,它可以用于监控带宽数据到日志文件之中...
define service{
use generic-service
host_name linksys-srw224p
service_description Port 1 Bandwidth Usage
check_command check_local_mrtgtraf!/var/lib/mrtg/192.168.1.253_1.log!AVG!1000000,2000000!5000000,5000000!10
}
在上例中,"/var/lib/mrtg/192.168.1.253_1.log"参数传给check_local_mrtgtraf命令意思是插件的MRTG日志文件在这个文件里读写,"AVG"参数的意思是取带宽的统计平均值,"1000000,200000"参数是指流入的告警门限(以字节为单位),"5000000,5000000"是输出流量紧急状态门限(以字节为单位),"10"是指如果MRTG日志如果超过10分钟没有数据返回一个紧急状态(应该每5分钟更新一次)。
配置好后/usr/local/nagios/bin/nagios ‐v /usr/local/nagios/etc/nagios.cfg检查有无错误并重启nagios服务
6.报警设置
nagios 常见的报警方式有邮件报警、短信报警、飞信报警、QQ 报警、MSN 报警等。
1) 邮件报警
1) 邮件报警
邮件报警是一种广为使用的报警方式,具有成本低廉,性能稳定等优势,默认采用系统自带的mail程序来发送邮件。
# echo test |mail –s "nagios报警"
crazyrhce@126.com //发送测试邮件
如果能正常收到测试邮件,就进行下一步邮件报警配置
需要修改两个地方,一个是contacts.cfg文件,一个是主机定义中的contacts选项
在contacts.cfg添加联系人对象,例如:
在contacts.cfg添加联系人对象,例如:
define contact{
contact_name nagiosadmin
use generic-contact
alias Nagios Admin
email llq @163.com ; crazyrhce@126.com } //多个联系人用分号隔开
contact_name nagiosadmin
use generic-contact
alias Nagios Admin
email llq @163.com ; crazyrhce@126.com } //多个联系人用分号隔开
最后在需要邮件报警的主机定义文件中加上contacets nagiosadmin
配置文件修改完成后重启nagios 服务,如果设置正常,发生故障时nagios 就会发送邮件给指定的E-mail 信箱。
2) 飞信报警
发生故障时nagios 发送邮件到指定的信箱是一个可行的通知办法,但是对于关键的业务服务而言,这样的报警方式显然不能满足需要。对于关键业务的运行情况,我们需要在发生故障后的第一时间获取到相关信息,甚至希望能够在故障发生前就进行处理。例如对磁盘空间的监控可以在磁盘被占满之前发出预警,是我们有足够的时间进行处理。综合各种情况,最合适的关键业务报警方式无非是短信、电话两种方式。短信及时性好、花费低廉对终端要求低等各种优势,往往成为最佳的选择。对于大企业用户而言,可以使用短信网关来发送短信,对于小型企业可以购买短信猫来实现相同的功能,对于不原意花钱又想用短信报警的用户,飞信就成为最好的选择。
用飞信报警可以通过装飞信客户端或者装飞信机器人实现。
用飞信机器人实现方法:
到
http://bbs.it-adv.net/viewthread.php?tid=1081&extra=page%3D1&page=1下载需要的库文件和飞信绿色安装文件,cp库文件到/usr/lib
自己给自己发个飞信测试一下:
fetion --mobile=15012345678 --pwd=xxxxx --to=15012345678 --msg-utf8="测试飞信" //pwd指飞信登录密码
现在飞信第一次发信时要有图形码验证(在和fetion同目录下生成),你可以把图形弄到桌面环境读取或者弄到windows机读取后再输入
修改commands.cfg 文件,为nagios 增加两个报警命令
[root@nagios objects]# vi commands.cfg
//增加以下内容
define command{
command_name notify-service-by-fetion
command_line /usr/bin/fetion --mobile=15012345678 --pwd=xxxxx --to=$CONTACTPAGER$
--msg-utf8="$HOSTNAME$ $SERVICEDESC$ is $SERVICESTATE$ on $TIME$ result is $SERVICEOUTPUT$" //飞信内容可自行定义,但一些变量必不可少
}
define command{
command_name notify-host-by-fetion
command_line /usr/bin/fetion --mobile=15012345678 --pwd=xxxxx --to=$CONTACTPAGER$
--msg-utf8="$NOTIFICATIONTYPE$ Host Alert: $HOSTNAME$ is $HOSTSTATE$ "
}
修改contacts.cfg,增加飞信报警方式
define contact{
contact_name sa
alias system admin
host_notification_period 24x7
service_notification_period 24x7
host_notification_options d,r,
service_notification_options c,w,r
service_notification_commands notify-service-by-fetion //这里报警命令名字与上面对应
host_notification_commands notify-host-by-fetion
pager 15012345678
}
配置文件修改完成后重启nagios 服务,使配置文件生效就可以使用飞信报警了
最后在需要飞信报警的主机定义文件中加上contacets sa
本文出自 “
老林的技术笔记” 博客,请务必保留此出处
http://lilinqing.blog.51cto.com/1122687/483604
转载于:https://blog.51cto.com/kwokchivu/736273















 158
158

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









