







一.BigTable
1.bigtable可以动态控制数据分布和格式,他提供了简单的数据模型。
2.bigtable使用了很多数据库策略,并行数据库和内存数据库,他的不同时可以动态控制数据分布式和存储。
3.用户可以把结构或半结构化的数据串行化,选择相关的数据模式,控制数据位置相关性,通过参数控制保存到内存或硬盘中。
4.bigtable的结构像一个立体空间结构。key(行,列,时间)。按行分区,每个区就是一个tablet,数据分布和均衡的最小单位。列族一般最多几百个,每个列族有很多个列关键字,而时间是列的版本。
5.时间戳信息是列的版本信息,有时是一个网络爬虫爬到的时间戳信息。
6.可以和MapReduce结合使用,MapReduce是个并行框架,可以使bigtable作为它的数据输入输出。
二.BigTable构件
1.bigtable使用GFS存储日志和数据文件。
2.bigtable内部存储数据文件是SSTable,它是个持久排序的Map结构,是一个数据块,用加载到内存的索引定位(用二分法定位数据位置)。
3.Chubby是个文件锁什么的原理没明白?
4.bigtable包括连接客户端的库,一个Master(负载和垃圾收集)多个tablet服务器,通信时候直接和tablet服务器通信,所以Master是个调配管控的作用,负载一般不会非常大。
5.Tablet位置
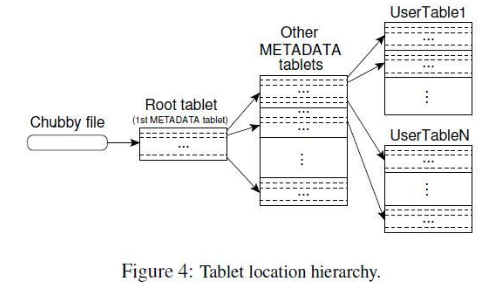
Root tablet是个行关键字(表标志&最后一行编码)。(如果每个Tablet存储128MB数据,那么一共可以存储2^61字节数据)。大约:2147483648GB。
tablet放在内存中,可以预取减少可能的开销(NameNode),还有一个次级信息用来排查错误和性能分析(SecondNameNode)。
这个地方不好理解的是,tablet服务器加入后再chubby中放一个文件作为会话的独占锁,tablet服务器退出时候会尝试释放这个独占锁,所以Master就是判断这个锁来判断tablet服务器是否还提供服务。
6.tablet分配,master会扫描现有原数据和tablelet服务已分配信息,觉得该怎么分配tablelet。
三.tablet服务
1.更新时候写日志,然后用Redo point来重建memtable,最近提交的排序缓存是memtable。读时候从sstable和memtable字典顺序合并的视图表中读取。w/r都有一个从Chubby中判断用户权限的过程。读写分割合并是可以同时进行的。
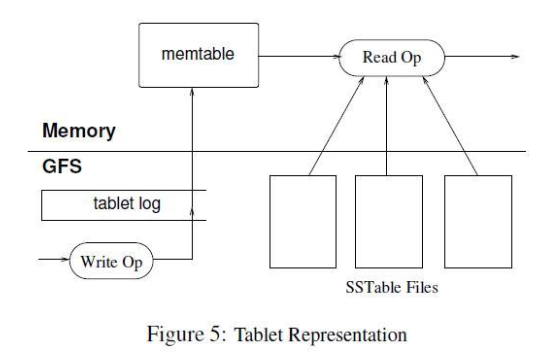
2.空间收缩
没太看明白啥过程?只不过知道有一种缓存到一定程度转SStable的过程,和合并后,删除回收数据空间的过程。
3.局部性群组
解决位置相关性列族的访问速度,将有位置关联需要或特定要求的列族划分为一个局部性群组,把频繁访问的小块数据放入内存或缓存是一种方法。
4.压缩
压缩时速率重要,同时空间比率也有较大提升,因为采用的算法选择适合的行获得了同个主机相同的数据聚簇以提高压缩比率。
5.缓存读取提高性能
缓存Key-value 和block,有位置局部性读取,能能更好。
6.bloom过滤器牺牲了一部分内存代价获得了是否访问硬盘的特性。
7.commit日志不是原来的每个tablet服务器一个,按(table,row name,log sequence number)排序,过程也是Master主导的并行排序。写日志的时候也是线程并行写的,而且有序号的唯一性,实现时就可以读时候按块连续读。
8.tablet恢复提速压缩日志并避免重新从日志中恢复。
9.SSTable缓存外的SSTable是不变的,所以我们分隔时可以不必为每个分隔出的Tablet建立SSTable集合,可以共享原来的Tablet的SSTable。
10.性能图看基本上读取次数和读取量虽不成正比,基本还是线性提升的。

11.单个tablet服务器性能提升
序列读/随机读性能要考虑到文件大小,是否放入内存/缓存中。序列写/随机写,性能相当。
12.性能提升
单个服务器可能受CPU限制,随机读取可能受网络中的Block传输限制。还有网络不均衡和移动后暂不可用造成。
13.实际应用
1个Bigtable集群运行在各种各样的服务器集群上。
14.google earth用的就是地理划分为行,列族存储地理数据原,用in-memory的列族。
15.经验教训
a,各种可能的异常,硬件,网络的,不假定只返回错误集合中的一个值。
b,tablet结构上锁问题,同步问题,METADATA访问挂起问题,GFS写入慢等操作问题都会有所监控和记录。监控集群状态,流量等信息。
c.设计简单的协议,最广泛使用的特性的协议。
16.相关工作
尝试过一些其他组件的B-tree,Key-value pair。还有oracle,IBM,db2还尝试了一个行的事物功能的完整性处理。Bigtable局部性也有以列压缩存储和读取性能的方案。bigtable也是支持每台服务器数千次操作的。
四.结论
bigtable可以随着时间的增加,通过简单的增加机器,扩展系统的承载能力。它给的存储方案带来很多优势,可以设置自己的模型,以及用到的其他google基础构件,如果出现瓶颈或效率,能比较快速的解决。















 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









