







本章主题
? 引言
? 面向对象编程
? 类
? 实例
? 绑定与方法调用
? 子类,派生和继承
? 内建函数
? 定制类
? 私有性
? 授权与包装
? 新式类的高级特性
? 相关模块
类最终解释了面向对象编程思想(OOP):
给出一个总体上的概述,涵盖了Python中使用类和OOP的所有主要方面。
其余部分针对类,类实例和方法进行详细探讨。
描述Python 中有关派生或子类及继承机理。
最后,可以在特定功能方面定制类,例如重载操作符,模拟Python 类型等。
将展示如何实现这些特殊的方法来自定义你的类,以让它们表现得更像Python 的内建类型。
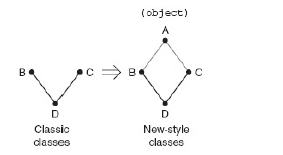
Python 社区最终统一了类型(types)和类(classes),新式类具备更多高级的OOP 特性,扮演了一个经典类(旧式类)超集的角色,后者是Python 诞生时所创造的类对象。
首先介绍两种风格的类(新式类和旧式类)中都存在的核心特性,然后讲解只有新式类才拥有的的高级特性。
13.1 介绍
在摸清OOP 和类的本质之前,我们首先讲一些高级主题,通过几个简单的例子热一热身。
若你刚学习面向对象编程,可以先跳过这部分内容,直接进入第13.2 节。
若你对有关面向对象编程已经熟悉了,想了解它在Python 中是怎样表现的,那么先看一下这部分内容,然后再进入13.3 节!
在Python 中,面向对象编程主要有两个主题,就是类和类实例(见图13-1)
类与实例
类与实例相互关联着:类是对象的定义,而实例是"真正的实物",它存放了类中所定义的对象的具体信息。
下面展示了如何创建一个类,关键字是class,紧接着是一个类名,随后是定义类的类体代码,这里通常由各种各样的定义和声明组成:
class MyNewObjectType(bases):
'define MyNewObjectType class'
class_suite #类体新式类和经典类声明的最大不同在于,所有新式类必须继承至少一个父类,参数bases可以是一个(单继承)或多个(多重继承)用于继承的父类。
object 是“所有类之母”。若你的类没有继承任何其他父类,object 将作为默认的父类。它位于所有类继承结构的最上层。如:
class MyNewObjectType:
'define MyNewObjectType classic class'
class_suite若没有指定一个父类,就是创建了一个经典类。很多Python 类都还是经典类。即使经典类已经过时了,在以后的Python 版本中,仍然可以使用它们。不过我们强烈推荐你尽可能使用新式类。
图 13-1 左边的工厂制造机器相当于类,而生产出来的玩具就是它们各个类的实例。尽管每个实例都有一个基本的结构,但各自的属性像颜色或尺寸可以改变-----这就好比实例的属性。


创建一个实例的过程称作实例化,过程如下(注意:没有使用new 关键字):
myFirstObject = MyNewObjectType()类名使用函数操作符(()),以“函数调用”的形式出现。通常会把这个新建的实例赋给一个变量。赋值在语法上不是必须的,但如果没有把这个实例保存到一个变量中,它就没用了,会被自动垃圾收集器回收,因为没有任何引用指向这个实例,这样做就是为那个实例分配了一块内存,随即又释放了它。
只要你需要,类可以很简单,也可以很复杂。最简单的情况,类仅用作名称空间(namespaces)(参见第11 章)。这意味着你把数据保存在变量中,对他们按名称空间进行分组,使得他们处于同样的关系空间中-----所谓的关系是使用标准Python 句点属性标识。比如,你有一个本身没有任何属性的类,使用它仅对数据提供一个名字空间,或者换句话说,这样的类仅作为容器对象来共享名字空间。
class MyData(object):
pass上面定义的类没有任何方法或属性。下面我们创建一个实例,它只使用类作为名称空间容器。
>>> mathObj = MyData()
>>> mathObj.x = 4
>>> mathObj.y = 5
>>> mathObj.x + mathObj.y
9
>>> mathObj.x * mathObj.y
20本例中,实例名字mathObj 将mathObj.x和mathObj.y 关联起来,mathObj.x 和 mathObj.y 是实例属性,因为它们不是类MyData 的属性,而是实例对象(mathObj)的独有属性。本章后面,我们将看到这些属性实质上是动态的:你不需要在构造器中,或其它任何地方为它们预先声明或者赋值。
方法
类的功能有一个更通俗的名字叫方法。方法定义在类定义中,但只能被实例所调用。也就是说,调用一个方法的最终途径必须是这样的:(1)定义类(和方法),(2)创建一个实例(3)最后一步,用这个实例调用方法。例如:
class MyDataWithMethod(object): # 定义类
def printFoo(self): # 定义方法
print 'You invoked printFoo()!'你注意到了self 参数,它在所有的方法声明中都存在。这个参数代表实例对象本身,当你用实例调用方法时,由解释器悄悄地传递给方法的,所以,你不需要自己传递self 进来,因为它是自动传入的。举例说明一下,假如你有一个带两参数的方法,所有你的调用只需要传递第二个参数,Python 把self 作为第一个参数传递进来,如果你犯错的话,Python 将告诉你传入的参数个数有误。
在其它语言中,self 称为“this”。可以在13.7 节的“核心笔记”中找到有关self 更多内容。一般的方法会需要这个实例(self),而静态方法或类方法不会,其中类方法需要类而不是实例。在第13.8 节中可以看到有关静态方法和类方法的更多内容。
现在我们来实例化这个类,然后调用那个方法:
>>> myObj = MyDataWithMethod() # 创建实例
>>> myObj.printFoo() # 现在调用方法
You invoked printFoo()!用一个稍复杂的例子来总结一下这部分内容,这个例子给出如何处理类(和实例),还介绍了一个特殊的方法__init__(),子类化及继承。
__init__()类似于类构造器。可以认为一个构造器仅是一个特殊的方法,它在创建一个新的对象时被调用。Python 中,__init__()实际上不是一个构造器。你没有调用“new”来创建一个新对象。(Python 根本就没有“new”关键字)。取而代之,Python 创建实例后,在实例化过程中,调用__init__()方法,当一个类被实例化时,就可以定义额外的行为,比如,设定初始值或者运行一些初步诊断代码———主要是在实例被创建后,实例化调用返回这个实例之前,去执行某些特定的任务或设置。(我们将把print 语句添加到方法中,这样我们就清楚什么时候方法被调用了。通常,我们不把输入或输出语句放入函数中,除非预期代码体具有输出的特性。)
创建一个类(类定义)
class AddrBookEntry(object): # 类定义
'address book entry class'
def __init__(self, nm, ph): # 定义构造器
self.name = nm # 设置 name
self.phone = ph # 设置 phone
print 'Created instance for:', self.name
def updatePhone(self, newph): # 定义方法
self.phone = newph
print 'Updated phone# for:', self.name可以认为实例化是对__init__()的一种隐式的调用,因为传给AddrBookEntry()的参数完全与__init__()接收到的参数是一样的(除了self,它是自动传递的)。
当方法在实例中被调用时,self参数自动由解释器传递,所以在上面的__init__()中,需要的参数是nm 和ph。__init__()在实例化时,设置这两个属性,以便,在实例从实例化调用中返回时,这两个属性对程序员是可见的了。
创建实例(实例化)
>>> john = AddrBookEntry('John Doe', '408-555-1212') #为John Doe 创建实例
>>> jane = AddrBookEntry('Jane Doe', '650-555-1212') #为Jane Doe 创建实例这就是实例化调用,它会自动调用__init__()。self 把实例对象自动传入__init__()。在上面第一个例子中,当对象john 被实例化后,它的john.name 就被设置了。
另外,如果不存在默认的参数,那么传给__init__()的两个参数在实例化时是必须的。
访问实例属性
>>> john
<__main__.AddrBookEntry instance at 80ee610>
>>> john.name
'John Doe'
>>> john.phone
'408-555-1212'
>>> jane.name
'Jane Doe'
>>> jane.phone
'650-555-1212'一旦实例被创建后,就可以证实一下,在实例化过程中,实例属性是否确实被__init__()设置了。可以通过解释器“转储”实例来查看它是什么类型的对象。(我们以后将学到如何定制类来获得想要的Python 对象字符串的输出形式,而不是现在看到的默认的Python 对象字符串(<...>))
方法调用(通过实例)
>>> john.updatePhone('415-555-1212') #更新John Doe 的电话
>>> john.phone
'415-555-1212'updatePhone()方法需要一个参数(不计self 在内):新的电话号码。
创建子类
靠继承来进行子类化是创建和定制新类类型的一种方式,新的类将保持已存在类所有的特性,而不会改动原来类的定义(指对新类的改动不会影响到原来的类)。对于新的类类型来说,这个新的子类可以定制只属于它的特定功能。除了与父类或基类的关系外,子类与通常的类没有什么区别,也像一般类一样进行实例化。注意下面,子类声明中提到了父类:
class EmplAddrBookEntry(AddrBookEntry):
'Employee Address Book Entry class'#员工地址本类
def __init__(self, nm, ph, id, em):
AddrBookEntry.__init__(self, nm, ph)
self.empid = id
self.email = em
def updateEmail(self, newem):
self.email = newem
print 'Updated e-mail address for:', self.namePython 中,当一个类被派生出来,子类继承了基类的属性,所以,在上面的类中,我们不仅定义了__init__(),updatEmail()方法,而且EmplAddrBookEntry 还从AddrBookEntry 中继承了updatePhone()方法。
如果需要,每个子类最好定义它自己的构造器,不然,基类的构造器会被调用。然而,如果子类重写基类的构造器,基类的构造器就不会被自动调用了--这样,基类的构造器就必须显式写出才会被执行,像我们上面那样。我们的子类在构造器后面几行还设置了另外两个实例属性。
注意,这里我们要显式传递self 实例对象给基类构造器,因为我们不是在其实例中调用那个方法而是在一个子类实例中调用那个方法。因为我们不是通过实例来调用它,这种未绑定的方法调用需要传递一个适当的实例(self)给方法。
本小节后面的例子,告诉我们如何创建子类的实例,访问它们的属性及调用它的方法,包括从父类继承而来的方法。
使用子类
>>> john = EmplAddrBookEntry('John Doe', '408-555-1212',42, 'john@spam.doe')
Created instance for: John Doe #给John Doe 创建实例
>>> john
<__main__.EmplAddrBookEntry object at 0x62030>
>>> john.name
'John Doe'
>>> john.phone
'408-555-1212'
>>> john.email
'john@spam.doe'
>>> john.updatePhone('415-555-1212') Updated phone# for: John Doe
>>> john.phone
'415-555-1212'
>>> john.updateEmail('john@doe.spam') Updated e-mail address for: John Doe
>>> john.email
'john@doe.spam'核心笔记:命名类、属性和方法
类名通常由大写字母打头。可以帮助你识别类,特别是在实例化过程中(有时看起来像函数调用)。
数据属性(变量或常量)听起来应当是数据值的名字,方法名应当指出对应对象或值的行为。另一种表达方式是:数据值应该使用名词作为名字,方法使用谓词(动词加对象)。数据项是操作的对象、方法应当表明程序员想要在对象进行什么操作。在上面我们定义的类中,遵循了这样的方针,数据值像“name”,“phone”和“email”,行为如“updatePhone”,“updateEmail”。这就是常说的“混合记法(mixedCase)”或“骆驼记法(camelCase)”。Python 规范推荐使用骆驼记法的下划线方式,比如,“update_phone”,“update_email”。类也要细致命名,像“AddrBookEntry”,“RepairShop”等等就是很好的名字。
我希望你已初步理解如何在Python 中进行面向对象编程了。本章其它小节将带你深入面向对象编程,Python 类及实例的方方面面。
13.2 面向对象编程
编程的发展已经从简单控制流中按步的指令序列进入到更有组织的方式中,依靠代码块可以形成命名子程序和完成既定的功能;
结构化的或过程性编程可以让我们把程序组织成逻辑块,以便重复或重用。创建程序的过程变得更具逻辑性;选出的行为要符合规范,才可以约束创建的数据;
结构化编程是“面向行为”的,因为即使没有任何行为的数据也必须“规定”逻辑性。然而,如果我们能对数据加上动作呢?如果我们所创建和编写的数据片段,是真实生活中实体的模型,内嵌数据体和动作呢?如果我们能通过一系列已定义的接口(又称存取函数集合)访问数据属性,我们就有了一个“对象”系统,从大的方面来看,每一个对象既可以与自身进行交互,也可以与其它对象进行交互;
面向对象编程增强了结构化编程,实现了数据与动作的融合:数据层和逻辑层现在由一个可用以创建这些对象的简单抽象层来描述。现实世界中的问题和实体完全暴露了本质,从中提供的一种抽象,可以用来进行相似编码,或者编入能与系统中对象进行交互的对象中。
类提供了这样一些对象的定义,实例即是这些定义的实现。二者对面向对象设计(OOD)来说都是重要的,OOD 仅意味采用面向对象方式架构来创建系统。
13.2.1 面向对象设计与面向对象编程的关系
面向对象设计(OOD)不会特别要求面向对象编程语言。事实上,OOD 可以由纯结构化语言来实现,比如C,但如果想要构造具备对象性质和特点的数据类型,就需要在程序上作更多的努力。当一门语言内建OO 特性,OO 编程开发就会更加方便高效。
另一方面,一门面向对象的语言不一定会强制你写OO 方面的程序。例如C++可以被认为“更好的C”;而Java,则要求万物皆类,此外还规定,一个源文件对应一个类定义。然而,在Python 中,类和OOP 都不是日常编程所必需的。尽管它从一开始设计就是面向对象的,并且结构上支持OOP,但Python 没有限定或要求你在你的应用中写OO 的代码。OOP 是一门强大的工具,不管你是准备进入,学习,过渡,或是转向OOP,都可以任意支配。
13.2.2 现实世界中的问题
用OOD 来工作的一个最重要的原因,在于它直接提供建模和解决现实世界问题和情形的途径。比如,模拟一台汽车维修店,可以让你停车进行维修。我们需要建两个一般实体:处在一个“系统”中并与其交互的人类,和一个修理店,它定义了物理位置,用于人类活动。因为前者有更多不同的类型,我将首先对它进行描述,然后描述后者。在此类活动中,一个名为Person的类被创建以用来表示所有的人。Person 的实例可以包括消费者(Customer),技工(Mechanic),还可能是出纳员(Cashier)。这些实例具有相似的行为,也有独一无二的行为。比如,他们能用声音进行交流,都有talk()方法,还有drive_car()方法。不同的是,技工有repair_car()方法,而出纳有ring_sale()方法。技工有一个repair_certification 属性,而所有人都有一个drivers_license属性。
最后,所有这些实例都是类RepairShop 的参与者,后者具有一个叫operating_hours 的数据属性,它通过时间函数来确定何时顾客来修车,何时职员技工和出纳员来上班。RepairShop 可能还有一个AutoBay 类,拥有SmogZone,TireBrakeZone 等实例,也许还有一个叫GeneralRepair 的实例。
RepairShop 的一个关键点是要展示类和实例加上它们的行为是如何用来对现实生活场景建模的。同样,你可以把诸如机场,其至一个邮订音乐公司想像为类,它们完全具备各自的参与者和功能性。
13.2.3*常用术语
抽象/实现
抽象指对现实世界问题和实体的本质表现、行为和特征建模,建立一个相关的子集,可以用于描绘程序结构,从而实现这种模型。抽象不仅包括这种模型的数据属性,还定义了这些数据的接口。
对某种抽象的实现就是对此数据及与之相关接口的现实化(realization)。现实化这个过程对于客户程序应当是透明而且无关的。
封装/接口
封装描述了对数据/信息进行隐藏的观念,它对数据属性提供接口和访问函数。通过任何客户端直接对数据的访问,无视接口,与封装性都是背道而驰的,除非程序员允许这些操作。作为实现的一部分,客户端根本就不需要知道在封装之后,数据属性是如何组织的。在Python 中,所有的类属性都是公开的,但名字可能被“混淆”了,以阻止未经授权的访问,但仅此而已,再没有其他预防措施了。这就需要在设计时,对数据提供相应的接口,以免客户程序通过不规范的操作来存取封装的数据属性。
合成
合成扩充了对类的描述,使得多个不同的类合成为一个大的类,来解决现实问题。合成描述了一个异常复杂的系统,比如一个类由其它类组成,更小的组件也可能是其它的类,数据属性及行为,所有这些合在一起,彼此是“有一个”的关系。比如,RepairShop“有一个”技工(应该至少有一个吧),还“有一个”顾客(至少一个)。
这些组件要么通过联合关系组在一块,意思是说,对子组件的访问是允许的(对RepairShop 来说,顾客可能请求一个SmogCheck,客户程序这时就是与RepairShop 的组件进行交互),要么是聚合在一起,封装的组件仅能通过定义好的接口来访问,对于客户程序来说是透明的。继续我的例子,客户程序可能会建立一个SmogCheck 请求来代表顾客,但不能够同RepairShop 的SmogZone 部分进行交互,因为SmogZone 是由RepairShop 内部控制的,只能通过smogCheckCar()方法调用。Python支持上述两种形式的合成。
派生/继承/继承结构
派生描述了子类的创建,新类保留已存类类型中所有需要的数据和行为,但允许修改或者其它的自定义操作,都不会修改原类的定义。继承描述了子类属性从祖先类继承这样一种方式。从前面的例子中,技工可能比顾客多个汽车技能属性,但单独的来看,每个都“是一个”人,所以,不管对谁而言调用talk()都k是合法得,因为它是人的所有实例共有的。继承结构表示多“代”派生,可以描述成一个“族谱”,连续的子类,与祖先类都有关系。
泛化/特化
泛化表示所有子类与其父类及祖先类有一样的特点,所以子类可以认为同祖先类是“是一个”的关系,因为一个派生对象(实例)是祖先类的一个“例子”。比如,技工“是一个”人,车“是一个”交通工具,等等。在上面我们间接提到的族谱图中,我们可以从子类到祖先类画一条线,表示“是一个”的关系。特化描述所有子类的自定义,也就是,什么属性让它与其祖先类不同。
多态
多态的概念指出了对象如何通过他们共同的属性和动作来操作及访问,而不需kao虑他们具体的类。多态表明了动态(又名,运行时)绑定的存在,允计重载及运行时类型确定和验证。
自省/反射
自省表示给予你,程序员,某种能力来进行像“手工类型检查”的工作,它也被称为反射。这个性质展示了某对象是如何在运行期取得自身信息的。如果传一个对象给你,你可以查出它有什么能力,这样的功能不是很好吗?这是一项强大的特性,在本章中,你会时常遇到。如果Python 不支持某种形式的自省功能,dir()和type()内建函数,将很难正常工作。请密切关注这些调用,还有那些特殊属性,像__dict__,__name__及__doc__。可能你对其中一些已经很熟悉了!
13.3 类
类是一种数据结构,可用来定义对象,后者把数据值和行为特性融合在一起。类是现实世界的抽象的实体以编程形式出现。实例是这些对象的具体化。可以类比一下,类是蓝图或者模型,用来产生真实的物体(实例)。
类声明与函数声明很相似,头一行用一个相应的关键字,接下来是一个作为它的定义的代码体:
def functionName(args):
'function documentation string' #函数文档字符串
function_suite #函数体
class ClassName(object):
'class documentation string' #类文档字符串
class_suite #类体二者都允许在他们的声明中创建函数,闭包或者内部函数(即函数内的函数)及在类中定义的方法。最大的不同在于你运行函数,而类会创建一个对象。
尽管类是对象(在Python 中,一切皆对象),但被定义时,它们还不是对象的实现。在下节中会讲到实例。现在我们集中讲解类对象。
当你创建一个类,你就实际创建了一个你自己的数据类型。
类还允许派生。你可以创建一个子类,它也是类,而且继续了父类所有的特征和属性。你也可以从内建类型中派生子类,而不是仅仅从其它类。
13.3.1 创建类
Python 类使用class 关键字来创建。简单的类的声明可以是关键字后紧跟类名:
class ClassName(bases):
'class documentation string' #'类文档字符串'
class_suite #类体本章前面的概述中提到,基类是一个或多个用于继承的父类的集合;类体由所有声明语句,类成员定义,数据属性和函数组成。类通常在一个模块的顶层进行定义,以便类实例能够在类所定义的源代码文件中的任何地方被创建。
13.3.2 声明与定义
声明与定义类没什么区别,因为他们是同时进行的,定义类体紧跟在声明(含class 关键字的头行[header line])和可选的文档字符串后面。同时,所有的方法也必须同时被定义。请注意Python 并不支持纯虚函数(像C++)或者抽象方法(如在JAVA 中),这些都强制在子类中定义方法。作为替代方法,你可以简单地在基类方法中引发NotImplementedError 异常,这样可以获得类似的效果。
13.4 类属性
属性就是属于一个对象的数据或者函,可以通过句点属性标识法来访问。比如复数有数据属性,而另外一些,像列表和字典,拥有方法(函数属性)。
当你正访问一个属性时,这个属性也是一个对象且拥有自己的属性,这导致了一个属性链。常见例子如下:
sys.stdout.write('foo')
print myModule.myClass.__doc__
myList.extend(map(upper, open('x').readlines()))类属性仅与其被定义的类相绑定,实例数据属性是你将会一直用到的主要数据属性。类数据属性仅当需要有“静态”数据类型时才变得有用,它和任何实例都无关。(如果你对静态不熟,它表示一个值,不会因为函数调用完毕而消失,它在每两个函数调用的间隙都存在。或者说,一个类中的一些数据对所有的实例来说,都是固定的。有关静态数据详细内容,见下一小节.)
接下来的一小节中,我们将简要描述,方法是如何实现及调用的。通常,Python中的所有方法都有一个限制:在调用前,需要创建一个实例。
13.4.1 类的数据属性
数据属性仅仅是所定义的类的变量。它们可以像任何其它变量一样在类创建后被使用,并且,要么是由类中的方法来更新,要么是在主程序其它什么地方被更新。
这种属性即静态变量,或者是静态数据。它们表示这些数据是与它们所属的类对象绑定的,不依赖于任何类实例。
静态成员通常仅用来跟踪与类相关的值。大多数情况下,你会用实例属性,而不是类属性。在后面,正式介绍实例时,将会对类属性及实例属性进行比较。看下面的例子,使用类数据属性(foo):
>>> class C(object):
... foo = 100
>>> print C.foo
100
>>> C.foo = C.foo + 1
>>> print C.foo
101注意,上面的代码中,看不到任何类实例的引用。
13.4.2 方法
方法,是作为类定义的一部分.(这使得方法成为类属性)。这表示myNoActionMethod 仅应用在MyClass 类型的对象(实例)上。这里,myNoActionMethod 是通过句点属性标识法与它的实例绑定的。
>>> class MyClass(object):
def myNoActionMethod(self):
pass
>>> mc = MyClass()
>>> mc.myNoActionMethod()任何像函数一样对myNoActionMethod 自身的调用都将失败:
>>> myNoActionMethod() Traceback (innermost last):
File "<stdin>", line 1, in ?
myNoActionMethod() NameError: myNoActionMethod引发了NameError 异常,因为在全局名字空间中,没有这样的函数存在。这就告诉你myNoActionMethod 是一个方法, 表示它属于一个类, 而不是全局空间中的名字。
下面展示的是,甚至由类对象调用此方法也失败了。
>>> MyClass.myNoActionMethod() Traceback (innermost last):
File "<stdin>", line 1, in ?
MyClass.myNoActionMethod()
TypeError: unbound method must be called with class
instance 1st argumentTypeError 异常初看起来很让人困惑,因为你知道这种方法是类的一个属性,为什么失败?
绑定(绑定及非绑定方法)
没有实例,方法是不能被调用的。这种限制即Python所描述的绑定概念(binding),在此,方法必须绑定(到一个实例)才能直接被调用。非绑定的方法可能可以被调用,但实例对象一定要明确给出,才能确保调用成功。然而,不管是否绑定,方法都是它所在的类的固有属性,即使它们几乎总是通过实例来调用的。在13.7 节中,我们会更深入地探索本主题。
13.4.2 决定类的属性
要知道一个类有哪些属性,有两种方法。最简单的是使用dir()内建函数。另外是通过访问类的字典属性__dict__,这是所有类都具备的特殊属性之一。看一下下面的例子:
>>> class MyClass(object):
... 'MyClass class definition' #MyClass 类定义
... myVersion = '1.1' # static data 静态数据
... def showMyVersion(self): # method 方法
... print MyClass.myVersion
...根据上面定义的类,让我们使用dir()和特殊类属性__dict__来查看一下类的属性:
>>> dir(MyClass)
['__class__', '__delattr__', '__dict__', '__doc__','__getattribute__', '__hash__', '__init__', '__module__','__new__', '__reduce__', '__reduce_ex__', '__repr__','__setattr__', '__str__', '__weakref__', 'myVersion',
'showMyVersion']
>>> MyClass.__dict__
<dictproxy object at 0x62090>
>>> print MyClass.__dict__
{'showMyVersion': <function showMyVersion at 0x59370>,'__dict__': <attribute '__dict__' of 'MyClass' objects>,'myVersion': '1.1', '__weakref__': <attribute'__weakref__' of 'MyClass' objects>, '__doc__':
'MyClass class definition'}在新式类中,还新增加了一些属性,dir()也变得更健壮。作为比较,可以看下经典类是什么样的:
>>> dir(MyClass)
['__doc__', '__module__', 'showMyVersion', 'myVersion']
>>>
>>> MyClass.__dict__
{'__doc__': None, 'myVersion': 1, 'showMyVersion':<function showMyVersion at 950ed0>, '__module__':'__main__'}从上面可以看到,dir()返回的仅是对象的属性的一个名字列表,而__dict__返回的是一个字典,它的键(keys)是属性名,键值(values)是相应的属性对象的数据值。
结果还显示了MyClass 类中两个熟悉的属性,showMyVersion 和 myVersion,以及一些新的属性。这些属性,__doc__及__module__,是所有类都具备的特殊类属性(另外还有__dict__)。。内建的vars()函数接受类对象作为参数,返回类的__dict__属性的内容。
13.4.3 特殊的类属性
对任何类C,表13.1 显示了类C的所有特殊属性:
表13.1 特殊类属性
C.__name__ 类C的名字(字符串)
C.__doc__ 类C的文档字符串
C.__bases__ 类C的所有父类构成的元组
C.__dict__ 类C的属性
C.__module__ 类C定义所在的模块
C.__class__ 实例C对应的类(仅新式类中)
根据上面定义的类MyClass,有如下结果:
>>> MyClass.__name__
'MyClass'
>>> MyClass.__doc__
'MyClass class definition'
>>> MyClass.__bases__
(<type 'object'>,)
>>> print MyClass.__dict__
{'__doc__': None, 'myVersion': 1, 'showMyVersion':<function showMyVersion at 950ed0>, '__module__': '__main__'}
>>> MyClass.__module__
'__main__'
>>> MyClass.__class__
<type 'type'>__name__是给定类的字符名字。它适用于那种只需要字符串(类对象的名字),而非类对象本身的情况。甚至一些内建的类型也有这个属性,我们将会用其中的一个来展示__name__字符串的益处。
类型对象是一个内建类型的例子,有__name__的属性,type()返回被调用对象的类型。如果仅需要一个字符串指明类型,而不需要一个对象的情况。可以使用类型对象的__name__属性来取得相应的字符串名:
>>> stype = type('What is your quest?')
>>> stype # stype is a type object stype 是一个类型对象
<type 'string'>
>>> stype.__name__ # get type as a string 得到类型名(字符串表示)
'string'
>>> type(3.14159265) # also a type object 又一个类型对象
<type 'float'>
>>> type(3.14159265).__name__ # get type as a string 得到类型名(字符串表示)
'float'__doc__是类的文档字符串,必须紧随头行(header line)后的字符串。文档字符串不能被派生类继承,也就是说派生类必须含有它们自己的文档字符串。
本章后面会讲到,__bases__用来处理继承,它包含了一个由所有父类组成的元组。
前述的__dict__属性包含一个字典,由类的数据属性组成。访问一个类属性的时候,Python 解释器将会搜索字典以得到需要的属性。如果在__dict__中没有找到,将会在基类的字典中进行搜索,采用“深度优先搜索”顺序。基类集的搜索是按顺序的,从左到右,按其在类定义时,定义父类参数时的顺序。对类的修改会仅影响到此类的字典;基类的__dict__属性不会被改动的。
Python 支持模块间的类继承。为更清晰地对类进行描述,1.5 版本中引入了__module__,这样类名就完全由模块名所限定。看一下下面的例子:
>>> class C(object):
... pass
...
>>> C
<class __main__.C at 0x53f90>
>>> C.__module__
'__main__'类C 的全名是“__main__.C”,比如,source_module.class_name。如果类C 位于一个导入的模块中,如mymod,像下面的:
>>> from mymod import C
>>> C
<class mymod.C at 0x53ea0>
>>> C.__module__
'mymod'在以前的版本中,没有特殊属性__module__,很难简单定位类的位置。
由于类型和类的统一性,当访问任何类的__class__属性时,返回一个类型对象的实例(type的实例)<type 'type'>。换句话说,一个类已是一种类型了。因为经典类并不认同这种等价性(一个经典类是一个类对象,一个类型是一个类型对象),对这些对象来说,这个属性并未定义。
13.5 实例
如果说类是一种数据结构定义类型,那么实例则声明了一个这种类型的变量。实例是那些主要用在运行期时的对象,类被实例化得到实例,该实例的类型就是这个被实例化的类。
13.5.1 初始化:通过调用类对象来创建实例
一旦定义了一个类,创建实例比调用一个函数还容易:
>>> class MyClass(object): # define class 定义类
... pass
>>> mc = MyClass() # instantiate class 初始化类调用("calling")类:MyClass(),就创建了类MyClass 的实例mc。返回的对象是你所调用类的一个实例。当使用函数记法来调用("call")一个类时,解释器就会实例化该对象,并且调用__init__(如果你定义了的话)来执行最终的定制工作,比如设置实例属性,最后将这个实例返回给你。
核心笔记:Python2.2 前后的类和实例
类和类型在2.2 版本中就统一了,任何类或者类型的实例都是这种类型的对象。比如,类MyClass 的实例mc 是类MyClass 的一个实例。同样,零是integer 类型的一个实例:
>>> mc = MyClass()
>>> type(mc)
<class '__main__.MyClass'>
>>> type(0)
<type 'int'>
但如果你仔细看,比较MyClass 和int,你将会发现二者都是类型(type):
>>> type(MyClass)
<type 'type'>
>>> type(int)
<type 'type'>
对比一下,如果在Python 早于2.2 版本时,使用经典类,此时类是类对象,实例是实例对象。
在这两个对象类型之间没有任何关系,除了实例的__class__属性引用了被实例化以得到该实例的类。
把MyClass 在Python2.1 版本中作为经典类重新定义,并运行相同的调用(注意:int()那时还不具备工厂功能...它还仅是一个通常的内建函数):
>>> type(mc)
<type 'instance'>
>>> type(0)
<type 'int'>
>>>
>>> type(MyClass)
<type 'class'>
>>> type(int)
<type 'builtin_function_or_method'>
为了避免任何混淆,你只要记住当你定义一个类时,你并没有创建一个新的类型,而是仅仅一个类对象;而对2.2 及后续版本,当你定义一个(新式的)类后,你已创建了一个新的类型。
13.5.2 __init__() "构造器"方法
当类被调用,实例化的第一步是创建实例对象。一旦对象创建了,检查是否实现了__init__()方法。默认情况下,如果没有定义(或覆盖)特殊方法__init__(),对实例不会施加任何特别的操作。任何所需的特定操作,都需要程序员实现__init__(),覆盖它的默认行为。如果__init__()没有实现,则返回它的对象,实例化过程完毕。
然而,如果__init__()已经被实现,那么它将被调用,实例对象作为第一个参数(self)被传递进去,像标准方法调用一样。调用类时,传进的任何参数都交给了__init__()。
总之,
(a)你没有通过调用new 来创建实例,你也没有定义一个构造器。是Python 为你创建了对象;
(b) __init__(),是在解释器为你创建一个实例后调用的第一个方法,在你开始使用它之前,这一步可以让你做些准备工作。
__init__()是很多为类定义的特殊方法之一。其中一些特殊方法是预定义的,缺省情况下,不进行任何操作,比如__init__(),要定制,就必须对它进行重载,还有些方法,可能要按需要去实现。本章中,我们会讲到很多这样的特殊方法。
13.5.3 __new__() “构造器”方法
与__init__()相比,__new__()方法更像一个真正的构造器。类型和类在版本2.2 就统一了,用户可以对内建类型进行派生,因此,需要一种途径来实例化不可变对象,比如,派生字符串,数字,等等。
在这种情况下,解释器则调用类的__new__()方法,一个静态方法,并且传入的参数是在类实例化操作时生成的。__new__()会调用父类的__new__()来创建对象(向上代理)。
为何我们认为__new__()比__init__()更像构造器呢?这是因为__new__()必须返回一个合法的实例,这样解释器在调用__init__()时,就可以把这个实例作为self 传给它。调用父类的__new__()来创建对象,正像其它语言中使用new 关键字一样。
__new__()和__init__()在类创建时,都传入了(相同)参数。13.11.3 节中有个例子使用了__new__()。
13.5.4 __del__() "解构器"方法
有一个特殊解构器方法名为__del__()。由于Python 具有垃圾对象回收机制(靠引用计数),这个函数要直到该实例对象所有的引用都被清除掉后才会执行。
Python 中的解构器是在实例释放前提供特殊处理功能的方法,它们通常没有被实现,因为实例很少被显式释放。
举例
在下面的例子中,我们分别创建(并覆盖)__init__()和__del__()构造及解构函数,然后,初始化类并给同样的对象分配很多别名。id()内建函数可用来确定引用同一对象的三个别名。最后一步是使用del 语句清除所有的别名,显示何时,调用了多少次解构器。
class C(P): # class declaration 类声明
def __init__(self): # "constructor" 构造器
print 'initialized'
def __del__(self): # "destructor" 解构器
P.__del__(self) # call parent destructor print 'deleted' 调用父类解构器来打印
'deleted'
>>> c1 = C()
>>> c2 = c1 # create additional alias 创建另外一个别名
>>> c3 = c1 # create a third alias 创建第三个别名
>>> id(c1), id(c2), id(c3) # all refer to same object 同一对象所有引用
(11938912, 11938912, 11938912)
>>> del c1 # remove one reference 清除一个引用
>>> del c2 # remove another reference 清除另一个引用
>>> del c3 # remove final reference deleted # destructor finally invoked 解构器最后调用注意,在上面的例子中,解构器是在类C 实例所有的引用都被清除掉后,才被调用的,比如,当引用计数已减少到0。如果你预期你的__del__()方法会被调用,却实际上没有被调用,这意味着,你的实例对象由于某些原因,其引用计数不为0,这可能有别的对它的引用,而你并不知道这些让你的对象还活着的引用所在。
要注意,解构器只能被调用一次,一旦引用计数为0,则对象就被清除了。这非常合理,因为系统中任何对象都只被分配及解构一次。
总结:
? 不要忘记首先调用父类的__del__()。
? 调用 del x 不表示调用了x.__del__() -----前面也看到,它仅仅是减少x 的引用计数。
? 如果你有一个循环引用或其它的原因,让一个实例的引用逗留不去,该对象的__del__()可能永远不会被执行。
? __del__()未捕获的异常会被忽略掉(因为一些在__del__()用到的变量或许已经被删除了)。不要在__del__()中干与实例没任何关系的事情。
? 除非你知道你正在干什么,否则不要去实现__del__()。
? 如果你定义了__del__,并且实例是某个循环的一部分,垃圾回收器将不会终止这个循环——你需要自已显式调用del。
核心笔记:跟踪实例
Python 没有提供任何内部机制来跟踪一个类有多少个实例被创建了,或者记录这些实例是些什么东西。如果需要这些功能,你可以显式加入一些代码到类定义或者__init__()和__del__()中去。
最好的方式是使用一个静态成员来记录实例的个数。靠保存它们的引用来跟踪实例对象是很危险的,因为你必须合理管理这些引用,不然,你的引用可能没办法释放(因为还有其它的引用)!看下面一个例子:
class InstCt(object):
count = 0 # count is class attr count 是一个类属性
def __init__(self): # increment count 增加count
InstCt.count += 1
def __del__(self): # decrement count 减少count
InstCt.count -= 1
def howMany(self): # return count 返回count
return InstCt.count
>>> a = InstTrack()
>>> b = InstTrack()
>>> b.howMany()
2
>>> a.howMany()
2
>>> del b
>>> a.howMany()
1
>>> del a
>>> InstTrack.count
013.6 实例属性
实例仅拥有数据属性(方法严格来说是类属性),这些值独立于其它实例或类,当一个实例被释放后,它的属性同时也被清除了。
13.6.1 “实例化”实例属性(或创建一个更好的构造器)
设置实例的属性可以在实例创建后任意时间进行。构造器__init()__是设置这些属性的关键点之一。
核心笔记:实例属性
能够在“运行时”创建实例属性,是Python 类的优秀特性之一,从C++或Java 转过来的人会被小小的震惊一下,因为C++或Java 中所有属性在使用前都必须明确定义/声明。Python 不仅是动态类型,而且在运行时,允许这些对象属性的动态创建。
一个缺陷是,属性在条件语句中创建,如果该条件语句块并未被执行,属性也就不存在,而你在后面的代码中试着去访问这些属性,就会有错误发生。这告诉我们,Python 让你体验从未用过的特性,但如果你使用它了,你还是要小心为好。
在构造器中首先设置实例属性
构造器是最早可以设置实例属性的地方,因为__init__()是实例创建后第一个被调用的方法。再没有比这更早的可以设置实例属性的机会了。一旦__init__()执行完毕,返回实例对象,即完成了实例化过程。
默认参数提供默认的实例安装
带默认参数的__init__()提供一个有效的方式来初始化实例。需要明白一点,默认参数应当是不变的对象;像列表(list)和字典(dictionary)这样的可变对象可以扮演静态数据,然后在每个方法调用中来维护它们的内容。
例13.1 描述了如何使用默认构造器行为来计算在美国一些大都市中的旅馆中寄宿时,租房总费用。
# hotel.py 代码的主要目的是来帮助某人计算出每日旅馆租房费用
class HotelRoomCalc(object):
'Hotel room rate calculator'
def __init__(self, rt, sales=0.085, rm=0.1): # 有8.5%销售税及10%的房间税,每日租房费用没有缺省
'''HotelRoomCalc default arguments:
sales tax == 8.5% and room tax == 10%'''
self.salesTax = sales
self.roomTax = rm
self.roomRate = rt
def calcTotal(self, days=1): # calcTotal()方法用来决定是计算每日总的租房费用还是计算所有天全部的租房费
'Calculate total; default to daily rate'
daily = round((self.roomRate *14 (1 + self.roomTax + self.salesTax)), 2)
return float(days) * daily内建的round()函数可以大约计算出最接近的费用(两个小数位)。下面是这个类的用法:
>>> sfo = HotelRoomCalc(299)
>>> sfo.calcTotal() # daily rate 日租金
354.32
>>> sfo.calcTotal(2) # 2-day rate 2天的租金
708.64
>>> sea = HotelRoomCalc(189, 0.086, 0.058) # new instance 新的实例
>>> sea.calcTotal()
216.22
>>> sea.calcTotal(4)
864.88
>>> wasWkDay = HotelRoomCalc(169, 0.045, 0.02) # new instance 新实例
>>> wasWkEnd = HotelRoomCalc(119, 0.045, 0.02) # new instance 新实例
>>> wasWkDay.calcTotal(5) + wasWkEnd.calcTotal() # 7-day rate 7 天的租金 停留五个工作日,外加一个周六,此时有特价,假定是星期天出发回家。
1026.69不要忘记,函数所有的灵活性。在实例化时,可变长度参数也是一个好的特性。
__init__()应当返回None
采用函数操作符调用类对象会创建一个类实例,也就是说这样一种调用过程返回的对象就是实例,下面示例可以看出:
>>> class MyClass(object):
... pass
>>> mc = MyClass()
>>> mc
<__main__.MyClass instance at 95d390>构造器不应当返回任何对象,因为实例对象是自动在实例化调用后返回的。相应地,__init__()就不应当返回任何对象(应当为None);否则,就可能出现冲突,因为只能返回实例。试着返回非None 的任何其它对象都会导致TypeError 异常:
>>> class MyClass:
... def __init__(self):
... print 'initialized'
... return 1
...
>>> mc = MyClass()
initialized
Traceback (innermost last): File "<stdin>", line 1, in ?
mc = MyClass()
TypeError: __init__() should return None13.6.2 查看实例属性
内建函数dir()可以显示类属性,同样还可以打印所有实例属性:
>>> class C(object):
... pass
>>> c = C()
>>> c.foo = 'roger'
>>> c.bar = 'shrubber'
>>> dir(c)
['__class__', '__delattr__', '__dict__', '__doc__','__getattribute__', '__hash__', '__init__', '__module__','__new__', '__reduce__', '__reduce_ex__', '__repr__','__setattr__', '__str__', '__weakref__', 'bar', 'foo']与类相似,实例也有一个__dict__特殊属性(可以调用vars()并传入一个实例来获取),它是实例属性构成的一个字典:
>>> c.__dict__
{'foo': 'roger', 'bar': 'shrubber'}13.6.3 特殊的实例属性
实例仅有两个特殊属性。对于任意对象I:
I.__class__ 实例化I 的类
I.__dict__ I 的属性
现在使用类C 及其实例C 来看看这些特殊实例属性:
>>> class C(object): # define class 定义类
... pass
...
>>> c = C() # create instance 创建实例
>>> dir(c) # instance has no attributes 实例还没有属性
[]
>>> c.__dict__ # yep, definitely no attributes 也没有属性
{}
>>> c.__class__ # class that instantiated us 实例化c 的类
<class '__main__.C'>c 还没有数据属性,添加一些再检查__dict__属性,看是否添加成功了:
>>> c.foo = 1
>>> c.bar = 'SPAM'
>>> '%d can of %s please' % (c.foo, c.bar)
'1 can of SPAM please'
>>> c.__dict__
{'foo': 1, 'bar': 'SPAM'}__dict__属性由一个字典组成,包含一个实例的所有属性。键是属性名,值是属性相应的数据值。字典中仅有实例属性,没有类属性或特殊属性。
核心风格:修改__dict__
对类和实例来说,尽管__dict__属性是可修改的,但还是建议你不要修改这些字典,除非你知道你的目的。这些修改可能会破坏你的OOP,造成不可预料的副作用。使用熟悉的句点属性标识来访问及操作属性会更易于接受。需要你直接修改__dict__属性的情况很少,其中之一是你要重载__setattr__特殊方法。实现__setattr__()本身是一个冒险的经历,满是圈套和陷阱,例如无穷递归和破坏实例对象。这个故事还是留到下次说吧。
13.6.4 内建类型属性
内建类型也是类,它们有没有像类一样的属性呢?那实例有没有呢?对内建类型也可以使用dir(),与任何其它对象一样,可以得到一个包含它属性名字的列表:
>>> x = 3+0.14j
>>> x.__class__
<type 'complex'>
>>> dir(x)
['__abs__', '__add__', '__class__', '__coerce__','__delattr__', '__div__', '__divmod__', '__doc__', '__eq__','__float__', '__floordiv__', '__ge__', '__getattribute__','__getnewargs__', '__gt__', '__hash__', '__init__',
'__int__', '__le__', '__long__', '__lt__', '__mod__','__mul__', '__ne__', '__neg__', '__new__', '__nonzero__','__pos__', '__pow__', '__radd__', '__rdiv__', '__rdivmod__','__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__',
'__rmod__', '__rmul__', '__rpow__', '__rsub__','__rtruediv__', '__setattr__', '__str__', '__sub__','__truediv__', 'conjugate', 'imag', 'real']
>>> [type(getattr(x, i)) for i in ('conjugate', 'imag','real')]
[<type 'builtin_function_or_method'>, <type 'float'>,<type 'float'>]既然我们知道了一个复数有什么样的属性,我们就可以访问它的数据属性,调用它的方法了:
>>> x.imag
2.0
>>> x.real
1.0
>>> x.conjugate()
(1-2j)试着访问__dict__会失败,因为在内建类型中,不存在这个属性:
>>> x.__dict__
Traceback (innermost last): File "<stdin>", line 1, in ?
AttributeError: __dict__13.6.5 实例属性 vs 类属性
类属性仅是与类相关的数据值,和实例属性不同,类属性和实例无关。这些值像静态成员那样被引用,即使在多次实例化中调用类,它们的值都保持不变。不管如何,静态成员不会因为实例而改变它们的值,除非实例中显式改变它们的值。类和实例都是名字空间。类是类属性的名字空间,实例则是实例属性的。关于类属性和实例属性,还有一些方面需要指出。你可采用类来访问类属性,如果实例没有同名的属性的话,你也可以用实例来访问。
访问类属性
类属性可通过类或实例来访问。下面的示例中,类C 在创建时,带一个version 属性,这样通过类对象来访问它是很自然的了。当实例c 被创建后,对实例c 而言,访问c.version 会失败,不过Python 首先会在实例中搜索名字version,然后是类,再就是继承树中的基类。本例中,version 在类中被找到了:
>>> class C(object): # define class 定义类
... version = 1.2 # static member 静态成员
...
>>> c = C() # instantiation 实例化
>>> C.version # access via class 通过类来访问
1.2
>>> c.version # access via instance 通过实例来访问
1.2
>>> C.version += 0.1 # update (only) via class 通过类(只能这样)来更新
>>> C.version # class access 类访问
1.3
>>> c.version # instance access, which 实例访问它,其值已被改变
1.3 # also reflected change我们只有当使用类引用version 时,才能更新它的值,像上面的C.version 递增语句。
如果尝试在实例中设定或更新类属性会创建一个实例属性c.version,后者会阻止对类属性C.versioin 的访问,因为第一个访问的就是c.version,这样可以对实例有效地“遮蔽”类属性C.version,直到c.version 被清除掉。
从实例中访问类属性须谨慎
任何对实例属性的赋值都会创建一个实例属性(如果不存在的话)并且对其赋值。如果类属性中存在同名的属性,副作用即产生(经典类和新式类都存在)
>>> class Foo(object):
... x = 1.5
...
>>> foo = Foo()
>>> foo.x
1.5
>>> foo.x = 1.7 # try to update class attr 试着更新类属性
>>> foo.x # looks good so far... 现在看起来还不错
1.7
>>> Foo.x # nope, just created a new inst attr 呵呵,没有变,只是创建了一个新的实例属性
1.5创建了一个名为version 的新实例属性,它覆盖了对类属性的引用。然而,类属性本身并没有受到伤害,仍然存在于类域中,还可以通过类属性来访问它。好了,那么如果把这个新的version 删除掉,会怎么样呢?
>>> del foo.x # delete instance attribute 删除实例属性
>>> foo.x # can now access class attr again 又可以访问到类属性
1.5所以,给一个与类属性同名的实例属性赋值,我们会有效地“隐藏”类属性,但一旦我们删除了这个实例属性,类属性又重见天日。现在再来试着更新类属性,我们只尝试一下增量动作:
>>> foo.x += .2 # try to increment class attr 试着增加类属性
>>> foo.x
1.7
>>> Foo.x # nope, same thing 呵呵,照旧
1.5同样创建了一个新的实例属性,类属性原封不动。(深入理解Python 相关知识:属性已存于类字典[__dict__]中。通过赋值,其被加入到实例的__dict__中了。)注意下面是一个等价的赋值方式,但它可能更加清楚些:foo.x = Foo.x + 0.2
但...在类属性可变的情况下,一切都不同了:
>>> class Foo(object):
... x = {2003: 'poe2'}
...
>>> foo = Foo()
>>> foo.x
{2003: 'poe2'}
>>> foo.x[2004] = 'valid path'
>>> foo.x
{2003: 'poe2', 2004: 'valid path'}
>>> Foo.x # it works!!! 生效了
{2003: 'poe2', 2004: 'valid path'}
>>> del foo.x # no shadow so cannot delete 没有遮蔽所以不能删除掉
Traceback (most recent call last): File "<stdin>", line 1, in ?
del foo.x
AttributeError: x
>>>类属性持久性
当一个实例在类属性被修改后才创建,那么更新的值就将生效。类属性的修改会影响到所有的实例:
>>> class C(object):
... spam = 100 # class attribute 类属性
...
>>> c1 = C()
>>> c1.spam # access class attr thru inst. 通过实例访问类属性
100
>>> C.spam += 100 # update class attribute 更新类属性
>>> C.spam # see change in attribute 查看属性值改变
200
>>> c1.spam # confirm change in attribute 在实例中验证属性值改变
200
>>> c2 = C() # create another instance 创建另一个实例
>>> c2.spam # verify class attribute 验证类属性
200
>>> del c1 # remove one instance 删除一个实例
>>> C.spam += 200 # update class attribute again 再次更新类属性
>>> c2.spam # verify that attribute changed 验证那个属性值改变
400核心提示:使用类属性来修改自身(不是实例属性)
正如上面所看到的那样,使用实例属性来试着修改类属性是很危险的。原因在于实例拥有它们自已的属性集,在Python 中没有明确的方法来指示你想要修改同名的类属性,比如,没有global关键字可以用来在一个函数中设置一个全局变量(来代替同名的局部变量)。修改类属性需要使用类名,而不是实例名。
13.7 从这里开始校对----------绑定和方法调用
再次阐述 Python 中绑定(binding)的概念,它主要与方法调用相关连。首先,方法仅仅是类内部定义的函数。(这意味着方法是类属性而不是实例属性)。
其次,方法只有在其所属的类拥有实例时,才能被调用。当存在一个实例时,方法才被认为是绑定到那个实例了。没有实例时方法就是未绑定的。
最后,任何一个方法定义中的第一个参数都是变量self,它表示调用此方法的实例对象。
核心笔记:self 是什么?
self 变量用于在类实例方法中引用方法所绑定的实例。如果你的方法中没有用到self , 那么请准备创建一个常规函数,除非你有特别的原因。毕竟,你的方法代码没有使用实例,没有与类关联其功能,这使得它看起来更像一个常规函数。
13.7.1 调用绑定方法
方法,不管绑定与否,都是由相同的代码组成的。唯一的不同在于是否存在一个实例可以调用此方法。在很多情况下,程序员调用的都是一个绑定的方法。假定现在有一个 MyClass 类和此类的一个实例 mc,而你想调用MyClass.foo()方法。因为已经有一个实例,你只需要调用mc.foo()就可以。当你还没有一个实例并且需要调用一个非绑定方法的时候你必须传递self 参数。
13.7.2 调用非绑定方法
调用非绑定方法并不经常用到。需要调用一个还没有任何实例的类中的方法的一个主要的场景是:你在派生一个子类,而且你要覆盖父类的方法,这时你需要调用那个父类中想要覆盖掉的构造方法:
class EmplAddrBookEntry(AddrBookEntry):
'Employee Address Book Entry class' # 员工地址记录条目
def __init__(self, nm, ph, em):
AddrBookEntry.__init__(self, nm, ph)
self.empid = id
self.email = em我们重载了构造器__init__()。我们想尽可能多地重用代码, 而不是去从父类构造器中剪切,粘贴代码。这正是我们想要的 --- 没有必要一行一行地复制代码。只需要能够调用父类的构造器即可,但该怎么做呢?
我们在运行时没有AddrBookEntry 的实例。我们有一个EmplAddrBookEntry的实例,它与AddrBookEntry 是那样地相似,能用它代替呢?当然可以!
当一个EmplAddrBookEntry 被实例化,并且调用 __init__() 时,其与AddrBookEntry 的实例只有很少的差别,主要是因为我们还没有机会来自定义我们的EmplAddrBookEntry 实例,以使它与AddrBookEntry 不同。
这是调用非绑定方法的最佳地方了。在子类构造器中调用父类的构造器并且明确地传递父类构造器所需要的self 参数(因为我们没有一个父类的实例)。子类中 __init__() 的第一行就是对父类__init__()的调用。我们通过父类名来调用它,并且传递给它 self 和其他所需要的参数。一旦调用返回,我们就能定义那些与父类不同的仅存在我们的(子)类中的(实例)定制。
13.8 静态方法和类方法
经典类及新式类都可以使用静态方法和类方法。一对内建函数被引入,用于将作为类定义的一部分的某一方法声明“标记”(tag),“强制类型转换”(cast)或者“转换”(convert)为这两种类型的方法之一。
静态方法和C++语言中的是一样的。它们仅是类中的函数(不需要实例)。在静态方法加入到Python 之前,用户只能在全局名字空间中创建函数,作为这种特性的替代实现 - 有时在这样的函数中使用类对象来操作类(或者是类属性)。使用模块函数比使用静态类方法更加常见。
回忆一下,通常的方法需要一个实例(self)作为第一个参数,并且对于(绑定的)方法调用来说,self 是自动传递给这个方法的。而对于类方法而言,需要类而不是实例作为第一个参数,它是由解释器传给方法。类不需要特别地命名, 类似self,不过很多人使用cls 作为变量名字。
13.8.1 staticmethod()和classmethod()内建函数
现在让我们看一下在经典类中创建静态方法和类方法的一些例子(你也可以把它们用在新式类中):
class TestStaticMethod:
def foo():
print 'calling static method foo()'
foo = staticmethod(foo)
class TestClassMethod:
def foo(cls):
print 'calling class method foo()'
print 'foo() is part of class:', cls.__name__
foo = classmethod(foo)对应的内建函数被转换成它们相应的类型,并且重新赋值给了相同的变量名。如果没有调用这两个函数,二者都会在Python 编译器中产生错误,显示需要带self 的常规方法声明。现在, 我们可以通过类或者实例调用这些函数....这没什么不同:
>>> tsm = TestStaticMethod()
>>> TestStaticMethod.foo()
calling static method foo()
>>> tsm.foo()
calling static method foo()
>>> tcm = TestClassMethod()
>>> TestClassMethod.foo()
calling class method foo()
foo() is part of class: TestClassMethod
>>> tcm.foo()
calling class method foo()
foo() is part of class: TestClassMethod13.8.2 使用函数修饰符
像foo=staticmethod(foo)这样的代码会刺激一些程序员。很多人对这样一个没意义的语法感到心烦。
在第11章“函数”的11.3.6 节中,我们了解了函数修饰符。你可以用它把一个函数应用到另个函数对象上, 而且新函数对象依然绑定在原来的变量。我们正是需要它来整理语法。通过使用decorators,我们可以避免像上面那样的重新赋值:
class TestStaticMethod:
@staticmethod
def foo():
print 'calling static method foo()'
class TestClassMethod:
@classmethod
def foo(cls):
print 'calling class method foo()'
print 'foo() is part of class:', cls.__name__13.9 组合
一个类被定义后,目标就是要把它当成一个模块来使用,并把这些对象嵌入到你的代码中去,同其它数据类型及逻辑执行流混合使用。有两种方法可以在你的代码中利用类。第一种是组合(composition)。就是让不同的类混合并加入到其它类中,来增加功能和代码重用性。你可以在一个大点的类中创建你自已的类的实例,实现一些其它属性和方法来增强对原来的类对象。另一种方法是通过派生,我们将在下一节中讨论它.
举例来说,对本章一开始创建的地址本类的加强性设计。如果在设计的过程中,为 names,addresses 等等创建了单独的类。把这些工作集成到AddrBookEntry类中去,而不是重新设计每一个需要的类。这样就节省了时间和精力,而且最后的结果是容易维护的代码 --- 一块代码中的bugs 被修正,将反映到整个应用中。
这样的类可能包含一个Name 实例,以及其它的像 StreetAddress, Phone(home, work,telefacsimile, pager, mobile, 等等),Email (home, work, 等等。),还可能需要一些Date 实例(birthday,wedding,anniversary,等等)。下面是一个简单的例子:
class NewAddrBookEntry(object): # class definition 类定义
'new address book entry class'
def __init__(self, nm, ph): # define constructor 定义构造器
self.name = Name(nm) # create Name instance 创建Name 实例
self.phone = Phone(ph) # create Phone instance 创建Phone 实例
print 'Created instance for:', self.nameNewAddrBookEntry类由它自身和其它类组合而成。这就在一个类和其它组成类之间定义了一种“has-a / 有一个”的关系。比如,我们的NewAddrBookEntry 类“有一个” Name 类实例和一个Phone实例。
创建复合对象就可以实现这些附加的功能,并且很有意义,因为这些类都不相同。每一个类管理它们自己的名字空间和行为。不过当对象之间有更接近的关系时,派生的概念可能对你的应用程序来说更有意义,特别是当你需要一些相似的对象,但却有少许不同功能的时候。
13.10 子类和派生
使用一个已经定义好的类,扩展它或者对其进行修改,而不会影响系统中使用现存类的其它代码片段。OOD 允许类特征在子孙类或子类中进行继承。这些子类从基类(或称祖先类,超类)继承它们的核心属性。而且,这些派生可能会扩展到多代。在一个层次的派生关系中的相关类(或者是在类树图中垂直相邻)是父类和子类关系。从同一个父类派生出来的这些类(或者是在类树图中水平相邻)是同胞关系。父类和所有高层类都被认为是祖先。
如果希望EmplAddrBookEntry 类中包含更多与工作有关的属性,如员工ID 和e-mail 地址?这跟PersonalAddrBookEntry 类不同,它包含更多基于家庭的信息,比如家庭地址,关系,生日等等。
两种情况下,我们都不想到从头开始设计这些类,因为这样做会重复创建通用的AddressBook类时的操作。包含AddressBook 类所有的特征和特性并加入需要的定制特性不是很好吗?这就是类派生的动机和要求。
13.10.1 创建子类
创建子类的语法看起来与普通(新式)类没有区别,一个类名,后跟一个或多个需要从其中派生的父类:
class SubClassName (ParentClass1[, ParentClass2, ...]):
'optional class documentation string'
class_suite如果你的类没有从任何祖先类派生,可以使用object 作为父类的名字。经典类的声明唯一不同之处在于其没有从祖先类派生---此时,没有圆括号:
class ClassicClassWithoutSuperclasses:
pass至此,我们已经看到了一些类和子类的例子,下面还有一个简单的例子:
class Parent(object): # define parent class 定义父类
def parentMethod(self):
print 'calling parent method'
class Child(Parent): # define child class 定义子类
def childMethod(self):
print 'calling child method'
>>> p = Parent() # instance of parent 父类的实例
>>> p.parentMethod()
calling parent method
>>> c = Child() # instance of child 子类的实例
>>> c.childMethod() # child calls its method 子类调用它的方法
calling child method
>>> c.parentMethod() # calls parent's method 调用父类的方法
calling parent method13.11 继承
继承描述了基类的属性如何“遗传”给派生类。一个子类可以继承它的基类的任何属性,不管是数据属性还是方法。
举个例子如下。P 是一个没有属性的简单类,C 从P 继承而来(因此是它的子类),也没有属性:
class P(object): # parent class 父类
pass
class C(P): # child class 子类
pass
>>> c = C() # instantiate child 实例化子类
>>> c.__class__ # child "is a" parent 子类“是一个”父类
<class '__main__.C'>
>>> C.__bases__ # child's parent class(es) 子类的父类
(<class '__main__.P'>,)因为P 没有属性,C 没有继承到什么。下面我们给P 添加一些属性:
class P: # parent class 父类
'P class'
def __init__(self):
print 'created an instance of', self.__class__.__name__
class C(P): # child class 子类
passP 有文档字符串(__doc__)和构造器:
>>> p = P() # parent instance 父类实例
created an instance of P
>>> p.__class__ # class that created us 显示p 所属的类名
<class '__main__.P'>
>>> P.__bases__ # parent's parent class(es) 父类的父类
(<type 'object'>,)
>>> P.__doc__ # parent's doc string 父类的文档字符串
'P class'我们现在来实例化C,展示 __init__()(构造)方法在执行过程中是如何继承的:
>>> c = C() # child instance 子类实例
created an instance of C
>>> c.__class__ # class that created us 显示c 所属的类名
<class '__main__.C'>
>>> C.__bases__ # child's parent class(es) 子类的父类
(<class '__main__.P'>,)
>>> C.__doc__ # child's doc string 子类的文档字符串C 继承了P 的__init__()。__bases__元组列出了其父类 P。需要注意的是文档字符串对类,函数/方法,还有模块来说都是唯一的,所以特殊属性__doc__不会从基类中继承过来。
13.11.1 __bases__类属性
__bases__类属性,对任何(子)类,它是一个包含其父类(parent)的集合的元组。注意,我们明确指出“父类”是相对所有基类(它包括了所有祖先类)而言的。那些没有父类的类,它们的__bases__属性为空。下面我们看一下如何使用__bases__的。
>>> class A(object): pass # define class A 定义类A
...
>>> class B(A): pass # subclass of A A 的子类
...
>>> class C(B): pass # subclass of B (and indirectly, A) B 的子类(A 的间接子类)
...
>>> class D(A, B): pass # subclass of A and B A,B 的子类
...
>>> A.__bases__
(<type 'object'>,)
>>> C.__bases__
(<class __main__.B at 8120c90>,)
>>> D.__bases__
(<class __main__.A at 811fc90>, <class __main__.B at 8120c90>)尽管C 是A 和B 的子类(通过B 传递继承关系),但C 的父类是B,这从它的声明中可以看出,所以,只有B 会在C.__bases__中显示出来。另一方面,D 是从两个类A 和B 中继承而来的。(多重继承参见13.11.4)
13.11.2 通过继承覆盖(Overriding)方法
我们在P 中再写一个函数,然后在其子类中对它进行覆盖。
class P(object):
def foo(self):
print 'Hi, I am P-foo()'
>>> p = P()
>>> p.foo()
Hi, I am P-foo()现在来创建子类C,从父类P 派生:
class C(P):
def foo(self):
print 'Hi, I am C-foo()'
>>> c = C()
>>> c.foo()
Hi, I am C-foo()尽管C 继承了P 的foo()方法,但因为C 定义了它自已的foo()方法,所以 P 中的 foo() 方法被覆盖。覆盖方法的原因之一是,你的子类可能需要这个方法具有特定或不同的功能。所以,你接下来的问题肯定是:“我还能否调用那个被我覆盖的基类方法呢?”肯定的,但是这时就需要你去调用一个未绑定的基类方法,明确给出子类的实例,例如下边:
>>> P.foo(c)
Hi, I am P-foo()不需要P 的实例调用P 的方法,因为已经有一个P 的子类的实例c 可用。典型情况下,你不会以这种方式调用父类方法,你会在子类的重写方法里显式地调用基类方法。
class C(P):
def foo(self):
P.foo(self)
print 'Hi, I am C-foo()'注意,在这个(未绑定)方法调用中我们显式地传递了self. 一个更好的办法是使用super()内建方法:
class C(P):
def foo(self):
super(C, self).foo()
print 'Hi, I am C-foo()'super()不但能找到基类方法,而且还为我们传进self,这样我们就不需要做这些事了。现在我们只要调用子类的方法,它会帮你完成一切:
>>> c = C()
>>> c.foo()
Hi, I am P-foo() Hi, I am C-foo()核心笔记:重写__init__不会自动调用基类的__init__
类似于上面的覆盖非特殊方法,当从一个带构造器 __init()__的类派生,如果你不去覆盖__init__(),它将会被继承并自动调用。但如果你在子类中覆盖了__init__(),子类被实例化时,基类的__init__()就不会被自动调用。这可能会让了解JAVA 的朋友感到吃惊。
class P(object):
def __init__(self):
print "calling P's constructor"
class C(P):
def __init__(self):
print "calling C's constructor"
>>> c = C()
calling C's constructor如果你还想调用基类的 __init__(),使用一个子类的实例去调用基类(未绑定)方法。相应地更新类C,会出现下面预期的执行结果:
class C(P):
def __init__(self):
P.__init__(self)
print "calling C's constructor"
>>> c = C()
calling P's constructor
calling C's constructor这是相当普遍(不是强制)的做法,用来设置初始化基类,然后可以执行子类内部的设置。这个规则之所以有意义的原因是,你希望被继承的类的对象在子类构造器运行前能够很好地被初始化或作好准备工作,因为它(子类)可能需要或设置继承属性。
对C++熟悉的朋友,可能会在派生类构造器声明时,通过在声明后面加上冒号和所要调用的所有基类构造器这种形式来调用基类构造器。而在JAVA 中,不管程序员如何处理,子类构造器都会去调用基类的的构造器。
Python 使用基类名来调用类方法,对应在JAVA 中,是用关键字super 来实现的,这就是super()内建函数引入到Python 中的原因:
class C(P):
def __init__(self):
super(C, self).__init__()
print "calling C's constructor"使用super()的重点,是你不需要明确提供父类。这意味着如果你改变了类继承关系,你只需要改一行代码(class 语句本身)而不必在大量代码中去查找所有被修改的那个类的名字。
13.11.3 从标准类型派生
介绍两个子类化Python 类型的相关例子,其中一个是可变类型,另一个是不可变类型。
不可变类型的例子
你想在金融应用中,应用一个处理浮点数的子类。每次得到一个贷币值,都需要通过四舍五入,变为带两位小数位的数值。你的类可以这样写:
class RoundFloat(float):
def __new__(cls, val):
return float.__new__(cls, round(val, 2))覆盖了__new__()特殊方法来定制我们的对象,使之和标准Python 浮点数(float)有一些区别:使用round()内建函数对原浮点数进行舍入操作,然后实例化我们的float,RoundFloat。
通过调用父类的构造器来创建真实的对象的,float.__new__()。注意,所有的__new()__方法都是类方法,我们要显式传入类传为第一个参数,这类似于常见的方法如__init__()中需要的self。
现在的例子还非常简单。通常情况下,最好是使用super()内建函数去捕获对应的父类以调用它的__new()__方法:
class RoundFloat(float):
def __new__(cls, val):
return super(RoundFloat, cls).__new__(cls, round(val, 2))这个例子还远不够完整,所以,请留意本章我们将使它有更好的表现。下面是一些样例输出:
>>> RoundFloat(1.5955)
1.6
>>> RoundFloat(1.5945)
1.59
>>> RoundFloat(-1.9955)
-2.0可变类型的例子
子类化一个可变类型与此类似,可能不需要使用__new__() (或甚至__init__()),因为通常设置不多。一般情况下,所继承到的类型的默认行为就是你想要的。下例中,我们简单地创建一个新的字典类型,它的keys()方法会自动排序结果:
class SortedKeyDict(dict):
def keys(self):
return sorted(super(SortedKeyDict, self).keys())字典(dictionary)可以由dict(),dict(mapping),dict(sequence_of_2_tuples),或者dict(**kwargs)来创建,看看下面使用新类的例子:
d = SortedKeyDict((('zheng-cai', 67), ('hui-jun', 68),('xin-yi', 2)))
print 'By iterator:'.ljust(12), [key for key in d]
print 'By keys():'.ljust(12), d.keys()把上面的代码全部加到一个脚本中,然后运行,可以得到下面的输出:
By iterator: ['zheng-cai', 'xin-yi', 'hui-jun']
By keys(): ['xin-yi', 'hui-jun', 'zheng-cai']上例中,通过keys 迭代过程是以散列顺序的形式,而使用我们(重写的)keys()方法则将keys 变为字母排序方式了。
一定要谨慎,而且要意识到你正在干什么。如果你说,“你的方法调用super()过于复杂”,取而代之的是,你更喜欢keys()简简单单(也容易理解)....,像这样:
def keys(self):
return sorted(self.keys())这是本章后面的练习13-19。
13.11.4 多重继承
Python 允许子类继承多个基类。这种特性就是多重继承。但最难的工作是,如何正确找到没有在当前(子)类定义的属性。当使用多重继承时,有两个不同的方面要记住。首先,还是要找到合适的属性。另一个就是当你重写方法时,如何调用对应父类方法以“发挥他们的作用”,同时,在子类中处理好自己的义务。我们将讨论两个方面,但侧重后者,讨论方法解析顺序。
方法解释顺序(MRO)
Python 2.2 以前的版本中,算法非常简单:深度优先,从左至右进行搜索,取得在子类中使用的属性。其它Python 算法只是覆盖被找到的名字,多重继承则取找到的第一个名字。
由于类,类型和内建类型的子类,都经过全新改造, 有了新的结构,这种算法不再可行. 这样一种新的MRO 算法被开发出来,在2.2 版本中初次登场,是一个好的尝试,但有一个缺陷(看下面的核心笔记)。这在2.3 版本中立即被修改,也就是今天还在使用的版本。
精确顺序解释很复杂,超出了本文的范畴,但你可以去阅读本节后面的书目提到的有关内容。这里提一下,新的查询方法是采用广度优先,而不是深度优先。
核心笔记:Python 2.2 使用一种唯一但不完善的MRO
2.2 版本中,算法基本思想是根据每个祖先类的继承结构,编译出一张列表,包括搜索到的类,按策略删除重复的。然而,有人指出,在维护单调性方面失败过(顺序保存),必须使用新的C3 算法替换,也就是从2.3 版开始使用的新算法。
下面的示例,展示经典类和新式类中,方法解释顺序有什么不同。
简单属性查找示例,下面这个例子将对两种类的方案不同处做一展示。脚本由一组父类,一组子类,还有一个子孙类组成。
class P1: #(object):
def foo(self):
print 'called P1-foo()'
class P2: #(object):
def foo(self):
print 'called P2-foo()'
def bar(self):
print 'called P2-bar()'
class C1(P1, P2): # child 1 der. from P1, P2 #子类1,从P1,P2 派生
pass
class C2(P1, P2): # child 2 der. from P1, P2 #子类2,从P1,P2 派生
def bar(self):
print 'called C2-bar()'
class GC(C1, C2): # define grandchild class #定义子孙类
pass # derived from C1 and C2 #从C1,C2 派生
P1 中定义了foo(),P2 定义了foo()和bar(),C2 定义了bar()。下面举例说明一下经典类和新式类的行为。
经典类
首先来使用经典类。通过在交互式解释器中执行上面的声明,我们可以验证经典类使用的解释顺序,深度优先,从左至右:
>>> gc = GC()
>>> gc.foo() # GC ==> C1 ==> P1
called P1-foo()
>>> gc.bar() # GC ==> C1 ==> P1 ==> P2
called P2-bar()当调用foo()时,它首先在当前类(GC)中查找。如果没找到,就向上查找最亲的父类,C1。查找未遂,就继续沿树上访到父类P1,foo()被找到。同样,对bar()来说,它通过搜索GC,C1,P1 然后在P2 中找到。因为使用这种解释顺序的缘故,C2.bar()根本就不会被搜索了。
现在,你可能在想,“我更愿意调用C2 的bar()方法,因为它在继承树上和我更亲近些,这样才会更合适。”在这种情况下,你必须调用它的合法的全名,采用典型的非绑定方式去调用,并且提供一个合法的实例:
>>> C2.bar(gc)
called C2-bar()新式类
取消类P1 和类P2 声明中的对(object)的注释,重新执行一下:
>>> gc = GC()
>>> gc.foo() # GC ==> C1 ==> C2 ==> P1
called P1-foo()
>>> gc.bar() # GC ==> C1 ==> C2
called C2-bar()与沿着继承树一步一步上溯不同,它首先查找同胞兄弟,采用一种广度优先的方式。当查找foo(),它检查GC,然后是C1 和C2,然后在P1 中找到。如果P1 中没有,查找将会到达P2。包括经典类和新式类都会在P1 中找到foo(),然而它们虽然是同归,但殊途!
然而,bar()的结果是不同的。它搜索GC 和C1,紧接着在C2 中找到了。这样,就不会再继续搜索到祖父P1 和P2。这种情况下,新的解释方式更适合那种要求查找GC 更亲近的bar()的方案。当然,如果你还需要调用上一级,只要按前述方法,使用非绑定的方式去做,即可。
>>> P2.bar(gc)
called P2-bar()新式类也有一个__mro__属性,告诉你查找顺序是怎样的:
>>> GC.__mro__
(<class '__main__.GC'>, <class '__main__.C1'>, <class'__main__.C2'>, <class '__main__.P1'>, <class'__main__.P2'>, <type 'object'>)菱形效应为难MRO
经典类方法解释不会带来很多问题。它很容易解释。大部分类都是单继承的,多重继承只限用在对两个完全不相关的类进行联合。这就是术语mixin 类(或者“mix-ins”)的由来。
为什么经典类MRO 会失败
在版本2.2 中,类型与类的统一,带来了一个新的“问题”,波及所有从object(所有类型的祖先类)派生出来的(根)类,一个简单的继承结构变成了一个菱形:
class B:
pass
class C:
def __init__(self):
print "the default constructor"
class D(B, C):
pass
>>> d = D()
the default constructor图13.3 为B,C 和D 的类继承结构,现在把代码改为采用新式类的方式,问题也就产生了:
class B(object):
pass
class C(object):
def __init__(self):
print "the default constructor"图13.3 继承的问题是:由于在新式类中,这样就在继承结构中形成了一个菱形。D 的实例上溯时,不应当错过C,但不能两次上溯到A(因为B 和C 都从A 派生)。
代码中仅仅是在两个类声明中加入了(object),继承结构已变成了一个菱形;真正的问题就存在于MRO 了。如果使用经典类的MRO,当实例化D 时,不再得到C.__init__()而是得到object.__init__()!这就是为什么MRO 需要修改的真正原因。
尽管我们看到了,在上面的例子中,类GC 的属性查找路径被改变了,但你不需要担心会有大量的代码崩溃。经典类将沿用老式MRO,而新式类将使用它自己的MRO。还有,如果你不需要用到新式类中的所有特性,可以继续使用经典类进行开发,不会有问题的。
总结
经典类,使用深度优先算法。因为新式类继承自object,新的菱形类继承结构出现,问题也就接着而来了,所以必须新建一个MRO。
你可以在下面的链接中读在更多有关新式类、MRO 的文章:
Guido van Rossum 的有关类型和类统一的文章:
http://www.python.org/download/releases/2.2.3/descrintro
PEP 252:使类型看起来更像类
http://www.python.org/doc/peps/pep-0252
“Python 2.2 新亮点” 文档
http://www.python.org/doc/2.2.3/whatsnew
论文:Python 2.3 方法解释顺序
http://python.org/download/releases/2.3/mro/
13.12 类、实例和其他对象的内建函数
13.12.1 issubclass()
issubclass() 布尔函数判断一个类是另一个类的子类或子孙类。它有如下语法:
issubclass(sub, sup)issubclass() 返回True 的情况:给出的子类sub 确实是父类sup 的一个子类(反之,则为False)。
这个函数也允许“不严格”的子类,意味着,一个类可视为其自身的子类,所以,这个函数如果当sub 就是sup,或者从sup 派生而来,则返回True。
从Python 2.3 开始,issubclass()的第二个参数可以是可能的父类组成的tuple(元组),这时,只要第一个参数是给定元组中任何一个候选类的子类时,就会返回True。
13.12.2 isinstance()
isinstance() 布尔函数在:判定一个对象是否是另一个给定类的实例时,它有如下语法:
isinstance(obj1, obj2)obj1 是类obj2 的一个实例,或者是obj2 的子类的一个实例时,返回True(反之,则为False),看下面的例子:
>>> class C1(object): pass
...
>>> class C2(object): pass
...
>>> c1 = C1()
>>> c2 = C2()
>>> isinstance(c1, C1) True #
>>> isinstance(c2, C1) False
>>> isinstance(c1, C2) False
>>> isinstance(c2, C2) True
>>> isinstance(C2, c2) Traceback (innermost last):
File "<stdin>", line 1, in ?
isinstance(C2, c2)
TypeError: second argument must be a class注意:第二个参数应当是类。但如果第二个参数是一个类型对象,则不会出现异常。这是允许的,因为你也可以使用isinstance()来检查一个对象obj1 是否是obj2 的类型,比如:
>>> isinstance(4, int)
True
>>> isinstance(4, str)
False
>>> isinstance('4', str)
True调用Python 的isinstance()不会有性能上的问题,主要是因为它只用来来快速搜索类族集成结构,以确定调用者是哪个类的实例,还有更重要的是,它是用C 写的!
同issubclass()一样,isinstance()也可以使用一个元组(tuple)作为第二个参数。如果第一个参数是第二个参数中给定元组的任何一个候选类型或类的实例时,就会返回True。
你还可以在595 页,第13.16.1 节中了解到更多有isinstance()的内容。
13.12.3 hasattr(), getattr(),setattr(), delattr()
*attr()系列函数可以在各种对象下工作,不限于类(class)和实例(instances)。因为在类和实例中使用极其频繁,就在这里列出来了。当使用这些函数时,传入正在处理的对象作为第一个参数,但属性名,即第二个参数,是属性的字符串名字。换句话说,就相当于调用*attr(obj,'attr'....)系列函数--下面的例子讲得很清楚。
hasattr()函数是Boolean 型的,目的就是为了判断一个对象是否有一个特定的属性,一般用于访问某属性前先作一下检查。getattr()和setattr()函数相应地取得和赋值给对象的属性,getattr()会在你试图读取一个不存在的属性时,引发AttributeError 异常,除非给出那个可选的提示语句的默认参数。setattr()将要么加入一个新的属性,要么取代一个已存在的属性。而delattr()函数会从一个对象中删除属性。eg:
>>> class myClass(object):
... def __init__(self):
... self.foo = 100
...
>>> myInst = myClass()
>>> hasattr(myInst, 'foo')
True
>>> getattr(myInst, 'foo')
100
>>> hasattr(myInst, 'bar') False
>>> getattr(myInst, 'bar') Traceback (most recent call last):
File "<stdin>", line 1, in ?
getattr(myInst, 'bar')
AttributeError: myClass instance has no attribute 'bar'
>>> getattr(c, 'bar', 'oops!')
'oops!'
>>> setattr(myInst, 'bar', 'my attr')
>>> dir(myInst)
['__doc__', '__module__', 'bar', 'foo']
>>> getattr(myInst, 'bar') # same as myInst.bar #等同于 myInst.bar
'my attr'
>>> delattr(myInst, 'foo')
>>> dir(myInst)
['__doc__', '__module__', 'bar']
>>> hasattr(myInst, 'foo')
False13.12.4 dir()
在之前的练习中,用dir()列出一个模块所有属性的信息。现在dir()还可以用在对象上。
dir()提供的信息比以前更加详尽。根据文档,“除了实例变量名和常用方法外,它还显示那些通过特殊标记来调用的方法,像__iadd__(+=),__len__(len()),__ne__(!=)。” 在Python 文档中有详细说明。
.. dir()作用在实例上(经典类或新式类)时,显示实例变量,还有在实例所在的类及所有它的基类中定义的方法和类属性。
.. dir()作用在类上(经典类或新式类)时,则显示类以及它的所有基类的__dict__中的内容。但它不会显示定义在元类(metaclass)中的类属性。
.. dir()作用在模块上时,则显示模块的__dict__的内容。(这没改动)。
.. dir()不带参数时,则显示调用者的局部变量。(也没改动)。
.. 关于更多细节:对于那些覆盖了__dict__或__class__属性的对象,就使用它们;出于向后兼容的kao虑,如果已定义了__members__和__methods__,则使用它们。
13.12.5 super()
super()这个函数的目的就是帮助程序员找出相应的父类,然后方便调用相关的属性。程序员可能仅仅采用非绑定方式调用祖先类方法。使用super()可以简化搜索一个合适祖先的任务,并且在调用它时,替你传入实例或类型对象。
在第13.11.4 节中,我们描述了文档解释顺序(MRO),用于在祖先类中查找属性。对于每个定义的类,都有一个名为__mro__的属性,它是一个元组,按照他们被搜索时的顺序,列出了被搜索的类。语法如下:
super(type[, obj])super()“返回此type 的父类”。如果你希望父类被绑定,你可以传入obj 参数(obj必须是type 类型的).否则父类不会被绑定。obj 参数也可以是一个类型,但它应当是type 的一个子类。通常,当给出obj 时:
.. 如果 obj 是一个实例,isinstance(obj,type)就必须返回True
.. 如果 obj 是一个类或类型,issubclass(obj,type)就必须返回True
事实上,super()是一个工厂函数,它创造了一个super object,为一个给定的类使用__mro__去查找相应的父类。很明显,它从当前所找到的类开始搜索MRO。更多详情,请再看一下Guido vanRossum 有关统一类型和类的文章,他甚至给出了一个super()的纯Python 实现,这样,你可以加深其印象,知道它是如何工作的!
最后想到.... super() 的主要用途, 是来查找父类的属性, 比如,super(MyClass,self).__init__()。如果你没有执行这样的查找,你可能不需要使用super()。
有很多如何使用super()的例子分散在本章中。记得阅读一下第13.11.2 节中有关super()的重要提示,尤其是那节中的核心笔记。
13.12.6 vars()
vars()内建函数与dir()相似,只是给定的对象参数都必须有一个__dict__属性。vars()返回一个字典,它包含了对象存储于其__dict__中的属性(键)及值。如果提供的对象没有这样一个属性,则会引发一个TypeError 异常。如果没有提供对象作为vars()的一个参数,它将显示一个包含本地名字空间的属性(键)及其值的字典,也就是,locals()。我们来看一下例子,使用类实例调用vars():
class C(object):
pass
>>> c = C()
>>> c.foo = 100
>>> c.bar = 'Python'
>>> c.__dict__
{'foo': 100, 'bar': 'Python'}
>>> vars(c)
{'foo': 100, 'bar': 'Python'}表13.3 概括了类和类实例的内建函数。


13.13 用特殊方法定制类
已在本章前面部分讲解了方法的两个重要方面:首先,方法必须在调用前被绑定(到它们相应类的某个实例中);其次,有两个特殊方法可以分别作为构造器和析够器的功能,分别名为__init__()和__del__()。
事实上,__init__()和__del__()只是可自定义特殊方法集中的一部分。它们中的一些有预定义的默认行为,而其它一些则没有,留到需要的时候去实现。这些特殊方法是Python 中用来扩充类的强有力的方式。它们可以实现:
.. 模拟标准类型
.. 重载操作符
特殊方法允许类通过重载标准操作符+,*, 甚至包括分段下标及映射操作操作[] 来模拟标准类型。如同其它很多保留标识符,这些方法都是以双下划线(__)开始及结尾的。表13.4 列出了所有特殊方法及其它的描述。







基本的定制和对象(值)比较特殊方法在大多数类中都可以被实现,且没有同任何特定的类型模型绑定。延后设置,也就是所谓的Rich 比较,在Python2.1 中加入。属性组帮助管理您的类的实例属性。这同样独立于模型。还有一个,__getattribute__(),它仅用在新式类中,我们将在后面的章节中对它进行描述。
特殊方法中数值类型部分可以用来模拟很多数值操作,包括那些标准(一元和二进制)操作符,类型转换,基本表示法,及压缩。也还有用来模拟序列和映射类型的特殊方法。实现这些类型的特殊方法将会重载操作符,以使它们可以处理你的类类型的实例。
另外,除操作符__*truediv__()和__*floordiv__()在Python2.2 中加入,用来支持Python 除操作符中待定的更改---可查看5.5.3 节。基本上,如果解释器启用新的除法,不管是通过一个开关来启动Python,还是通过"from __future__ import division",单斜线除操作(/)表示的将是ture除法,意思是它将总是返回一个浮点值,不管操作数是否为浮点数或者整数(复数除法保持不变)。双斜线除操作(//)将提供大家熟悉的浮点除法。同样,这些方法只能处理实现了这些方法并且启用了新的除操作的类的那些符号。
表格中,在它们的名字中,用星号通配符标注的数值二进制操作符则表示这些方法有多个版本,在名字上有些许不同。星号可代表在字符串中没有额外的字符,或者一个简单的“r”指明是一个右结合操作。没有“r”,操作则发生在对于self OP obj 的格式; “r”的出现表明格式obj OP self。比如,__add__(self,obj)是针对self+obj 的调用,而__radd__(self,obj)则针对obj+self 来调用。增量赋值,一个“i”代替星号的位置,表示左结合操作与赋值的结合,相当是在self=self OP obj。举例,__iadd__(self,obj)相当于self=self+obj的调用。
随着Python 2.2 中新式类的引入,有一些更多的方法增加了重载功能。然而,在本章开始部分提到过,我们仅关注经典类和新式类都适应的核心部分,本章的后续部分,我们介绍新式类的高级特性。
13.13.1 简单定制(RoundFloat2)
第一个例子很普通,它基于前面所看到的派生类RoundFloat。这个例子很简单。事实上,我们甚至不想去派生任何东西(当然,除object 外)...我们也不想采用与floats 有关的所有“好东西”。我们想创建一个精简的例子,这样对类定制的工作方式有一个更好的理解。这种类的前提与其它类是一样的:只要一个类来保存浮点数,四舍五入,保留两位小数位。
class RoundFloatManual(object):
def __init__(self, val):
assert isinstance(val, float), "Value must be a float!"
self.value = round(val, 2)这个类仅接收一个浮点值----它断言了传递给构造器的参数类型必须为一个浮点数----并且将其保存为实例属性值。创建这个类的一个实例:
>>> rfm = RoundFloatManual(42)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "roundFloat2.py", line 5, in __init__
assert isinstance(val, float), \ AssertionError: Value must be a float!
>>> rfm = RoundFloatManual(4.2)
>>> rfm
<roundFloat2.RoundFloatManual object at 0x63030>
>>> print rfm
<roundFloat2.RoundFloatManual object at 0x63030>当把这个对象转存在交互式解释器中时,得到一些信息,却不是我们要找的。(我们想看到数值,对吧?)调用print 语句同样没有明显的帮助。不幸的是,print(使用str())和真正的字符串对象表示(使用repr())都没能显示更多有关我们对象的信息。一个好的办法是,去实现__str__()和__repr__()二者之一,或者两者都实现,这样就能“看到”对象是个什么样子了。让我们来添加一个__str()__方法,以覆盖默认的行为:
def __str__(self):
return str(self.value)运行:
>>> rfm = RoundFloatManual(5.590464)
>>> rfm
<roundFloat2.RoundFloatManual object at 0x5eff0>
>>> print rfm
5.59
>>> rfm = RoundFloatManual(5.5964)
>>> print rfm
5.6一个问题是仅仅在解释器中转储(dump)对象时,仍然显示的是默认对象符号,但这样做也算不错。如果我们想修复它,只需要覆盖__repr__()。因为字符串表示法也是Python对象,我们可以让__repr__()和__str__()的输出一致。
为了完成这些,只要把__str__()的代码复制给__repr__()。这是一个简单的例子,所以它没有真正对我们造成负面影响,但作为程序员,你知道那不是一个最好的办法。如果__str__()中存在bug,那么我们会将bug 也复制给__repr__()了。最好的方案,在__str__()中的代码也是一个对象,同所有对象一样,引用可以指向它们,所以,我们可以仅仅让__repr__()作为__str__()的一个别名:
__repr__ = __str__在带参数5.5964 的第二个例子中,我们看到它舍入值刚好为5.6,但我们还是想显示带两位小数的数。来玩玩一个更好的妙计吧,看下面:
def __str__(self):
return '%.2f' % self.value在本章开始部分,最初的RoundFloat 例子,我们没有担心所有细致对象的显示问题;原因是__str__()和__repr__()作为float 类的一部分已经为我们定义好了。我们所要做的就是去继承它们。增强版本“手册”中需要另外的工作。你发现派生是多么的有益了吗?我们甚至不需要知道解释器在继承树上要执行多少步才能找到一个已声明的你正在使用却没有kao虑过的方法。我们将在例13.2中列出这个类的全部代码。现在开始一个稍复杂的例子。
13.13.2 数值定制(Time60)
可以想象需要创建一个简单的应用,用来操作时间,精确到小时和分。要创建的这个类可用来跟踪职员工作时间,ISP 用户在线时间,数据库总的运行时间(不包括备份及升级时的停机时间),在扑克比赛中玩家总时间,等等。
在Time60 类中,我们将整数的小时和分钟作为输入传给构造器。
class Time60(object): # ordered pair 顺序对
def __init__(self, hr, min): # constructor 构造器
self.hr = hr # assign hours 给小时赋值
self.min = min # assign minutes 给分赋值我们都习惯看小时和分,用冒号分隔开的格式:
def __str__(self):
return '%d:%d' % (self.hr, self.min)
__repr__=__str下面的例子中,我们启动一个工时表来跟踪对应构造器的计费小时数:
>>> mon = Time60(10, 30)
>>> tue = Time60(11, 15)
>>> print mon, tue
10:30 11:15下一步干什么呢?与我们的对象进行交互。比如在时间片的应用中,有必要把Time60 的实例放到一起让我们的对象执行所有有意义的操作,eg:
>>> mon + tue
21:45加法
Python 的重载操作符很简单。像加号(+),只需要重载__add__()方法,还可以用__radd__()及__iadd__()。如果我们想看到“21:45”,就必须认识到这是另一个Time60 对象,我们没有修改mon 或tue,所以,我们的方法就应当创建另一个对象并填入计算出来的总数。实现__add__()特殊方法时,首先计算出个别的总数,然后调用类构造器返回一个新的对象:
def __add__(self, other):
return self.__class__(self.hr + other.hr, self.min + other.min)和正常情况下一样,新的对象通过调用类来创建。唯一的不同点在于,在类中,你一般不直接调用类名, 而是使用self 的__class__属性,即实例化self 的那个类,并调用它。由于self.__class__与Time60 相同,所以调用self.__class__()与调用Time60()是一回事。另一个原因是,如果在创建一个新对象时,处处使用真实的类名,然后,决定将其改为别的名字,这时,就不得不非常小心地执行全局搜索并替换。如果靠使用self.__class__,就不需要做任何事情,只需要直接改为你想要的类名。好了,我们现在来使用加号重载,“增加”Time60 对象:
>>> mon = Time60(10, 30)
>>> tue = Time60(11, 15)
>>> mon + tue
<time60.Time60 object at 0x62190>
>>> print mon + tue
21:45“当我们试着在重载情况下使用一个操作符,却没有定义相对应的特殊方法时还有很多需要优化和重要改良的地方,会发生什么事呢?” 是一个TypeError 异常:
>>> mon - tue
Traceback (most recent call last): File "<stdin>", line 1, in ?
TypeError: unsupported operand type(s) for -: 'Time60'
and 'Time60'原位加法
有了增量赋值,也许还有希望覆盖“原位”操作,比如,__iadd__()。用来支持像mon += tue 这样的操作符,并把正确的结果赋给mon。重载一个__i*__()方法的唯一秘密是它必须返回self:
def __iadd__(self, other):
self.hr += other.hr
self.min += other.min
return self下面是结果输出:
>>> mon =Time60(10,30)
>>> tue =Time60(11,15)
>>> mon
10:30
>>> id(mon)
401872
>>> mon += tue
>>> id(mon)
401872
>>> mon
21:45注意,使用id()内建函数是用来确定一下,在原位加的前后,确实是修改了原来的对象,而没有创建一个新的对象。对一个具有巨大潜能的类来说,这是很好的开始。
升华
现在暂不管它了,这个类中还有很多需要优化和改良的地方。比如,如果我们不传入两个分离的参数,而传入一个2个元素的元组给构造器作为参数,是不是更好些呢?如果是像“10:30”这样的字符串的话,结果会怎样?你可以这样做且很容易做到,但不是像很多其他面向对象语言一样通过重载构造器来实现。Python 不允许用多个签名重载可调用对象。所以实现这个功能的唯一的方式是使用单一的构造器,并由isinstance()和(可能的)type()内建函数执行自省功能。能支持多种形式的输入,能够执行其它操作像减法等,可以让我们的应用更健壮,灵活。当然这些是可选的,但首先应该担心的是两个中等程度的缺点:1.当比十分钟还少时,格式并不是我们所希望的,2. 不支持60 进制(基数60)的操作:
修改这些缺陷,实现上面的改进建议可以实际性地提高你编写定制类技能。这方面的更新,更详细的描述在本章的练习13.20中。
我们希望,你现在对于操作符重载,为什么要使用操作符重载,以及如何使用特殊方法来实现它已有了一个更好的理解了。接下来为选看章节内容,让我们来了解更多复杂的类定制的情况。
13.13.3 迭代器(RandSeq 和AnyIter)
RandSeq
迭代器可以一次一个的遍历序列(或者是类似序列对象)中的项。第8 章描述了如何利用一个类中的__iter__()和next()方法,来创建一个迭代器。在此展示两个例子。
第一个例子是RandSeq,给类传入一个初始序列,然后让用户通过next()去迭代(无穷)。__iter__()仅返回self,这就是如何将一个对象声明为迭代器的方式,最后,调用next()来得到迭代器中连续的值。这个迭代器唯一的亮点是它没有终点。这个例子展示了一些可以用定制类迭代器来做的与众不同的事情。一个是无穷迭代。因为我们无损地读取一个序列,所以它是不会越界的。每次用户调用next()时,它会得到下一个迭代值,但我们的对象永远不会引发StopIteration 异常。
例13.4 随机序列迭代器(randSeq.py)
from random import choice
class RandSeq(object):
def __init__(self, seq):
self.data=seq
def __iter__(self):
return self
def next(self):
return choice(self.data)我们来运行它,将会看到下面的输出:
>>> from randseq import RandSeq
>>> for eachItem in RandSeq(... ('rock', 'paper', 'scissors')):
... print eachItem
...
scissors
scissors
rock
paper
paper
scissors例13.5 任意项的迭代器(anyIter.py)
class AnyIter(object):
def __init__(self, data, safe=False):
self.safe = safe
self.iter=iter(data)
def __iter__(self):
return self
def next(self, howmany=1):
retval=[]
for eachItem in range(howmany):
try:
retval.append(self.iter.next())
except StopIteration:
if self.safe:
break
else:
raise
return retval在第二个例子中,创建了一个迭代器对象,传给next()方法一个参数,控制返回条目的数目,而不是去一次一个地迭代每个项。它同其它迭代器一样工作,只是用户可以请求一次返回N 个迭代的项,而不仅是一个项。给出一个迭代器和一个安全标识符(safe)来创建这个对象。如果这个标识符(safe)为真(True),我们将在遍历完这个迭代器前,返回所获取的任意条目,但如果这个标识符为假(False),则在用户请求过多条目时,将会引发一个异常。在next()的最后一部分中,创建用于返回的一个列表项,并且调用sef.iter的next()方法来获得每一项条目。如果遍历完列表,得到一个StopIteration 异常,这时则检查安全标识符(safe)。如果不安全,则将异常抛还给调用者(raise);否则, 退出(break)并返回(return)已经保存过的所有项。
>>> a = AnyIter(range(10))
>>> i = iter(a)
>>> for j in range(1,5):
>>> print j, ':', i.next(j)
1 : [0]
2 : [1, 2]
3 : [3, 4, 5]
4 : [6, 7, 8, 9]我们首先试试“不安全(unsafe)”的模式,这也就是紧随其后创建我们的迭代器:
>>> i = iter(a)
>>> i.next(14)
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "anyIter.py", line 15, in next retval.append(self.iter.next())
StopIteration因为超出了项的支持量,所以出现了StopIteration 异常,并且这个异常还被重新引发回调用者。如果使用“安全(safe)”模式重建迭代器,再次运行一次同一个例子的话,就可以在项失控出现前得到迭代器所得到的元素:
>>> a = AnyIter(range(10), True)
>>> i = iter(a)
>>> i.next(14)
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]13.13.4 *多类型定制(NumStr)
现在创建另一个新类,NumStr,由一个数字(integer)-字符对组成,相应地记为n 和s。尽管这组顺序对的“合适的”记号是(n,s),但选用[n::s]来表示它。可以创建新类NumStr了,有下面的特征:
初始化类应当对数字和字符串进行初始化;如果其中一个(或两)没有初始化,则使用0 和空字符串作为默认。
加法
加法操作符是把数字加起来,把字符连在一起;要点部分是字符串要按顺序相连。比如,NumStr1=[n1::s1]且NumStr2=[n2::s2]。则NumStr1+NumStr2 表示[n1+n2::s1+s2],其中,+代表数字相加及字符相连接。
乘法
类似的, 乘法操作符的功能为, 数字相乘, 字符累积相连, 也就是,NumStr1*NumStr2=[n1*n::s1*n]。
False 值
当数字的数值为0 且字符串为空时,也就是当NumStr=[0::'']时,这个实体即有一个false 值。
比较
比较一对NumStr 对象,比如,[n1::s1] vs. [n2::s2],我们可以发现九种不同的组合(即,n1>n2and s1<s2,n1==n2 and s1>s2,等等)。对数字和字符串,一般按照标准的数值和字典顺序的进行比较,即如果obj1<obj2,普通比较cmp(obj1,obj2)的返回值是一个小于0 的整数,当obj1>obj2 时,比较的返回值大于0,当两个对象有相同的值时,比较的返回值等于0。我们的类的解决方案是把这些值相加,然后返回结果。有趣的是cmp()不会总是返回-1,0,或1。上面提到过,它是一个小于,等于或大于0 的整数。为了能够正确的比较对象,我们需要让__cmp__()在(n1>n2) 且 (s1>s2)时,返回 1,在(n1<n2)且(s1<s2)时,返回-1,而当数值和字符串都一样时,或是两个比较的结果正相反时(即(n1<n2)且(s1>s2),或相反),返回0.反之亦然。
例13.6 多类型类定制(numstr.py)
class NumStr(object):
def __init__(self, num=0, string = ""):
self.__num = num
self.__string = string
def __str__(self):
return "[%d::%r]"%(self.__num,self.__string)
__repr__=__str__
def __add__(self,other):
if isinstance(other, NumStr):
return self.__class__(self.__num+other.__num, self.__string+other.__num)
else:
raise TypeError,"Illegal argument type for built-in operation"
def __mul__(self, num):
if isinstance(num, int):
return self.__class__(self.__num * num, self.__string * num)
else:
raise TypeError,"Illegal argument type for built-in operation"
def __nonzero__(self):
return self.__num or len(self.__string)
def __norm_cval(self, cmpres):
return cmp(cmpre, 0)
def __cmp__(self, other):
return self.__norm_cval(cmp(self.__num, other.__num)) \
+ self.__norm_cval(cmp(self.__string, other.__string)根据上面的特征,我们列出numstr.py 的代码,执行一些例子:
>>> a = NumStr(3, 'foo')
>>> b = NumStr(3, 'goo')
>>> c = NumStr(2, 'foo')
>>> d = NumStr()
>>> e = NumStr(string='boo')
>>> f = NumStr(1)
>>> a
[3 :: 'foo']
>>> e
[0 :: 'boo']
>>> a < b
True
>>> b < c
False
>>> a == a
True
>>> b * 2
[6 :: 'googoo']
>>> b + e
[3 :: 'gooboo']
>>> if d: 'not false' # also bool(d)
...
>>> if e: 'not false' # also bool(e)
...
'not false'
>>> cmp(a,b)
-1
>>> cmp(a,c)
1
>>> cmp(a,a)
0命名属性时使用双下划线。这是在信息隐藏时,强加一个级别,尽管不够成熟。导入一个模块时,就不能直接访问到这些数据元素。我们正试着执行一种OO 设计中的封装特性,只有通过存取函数才能访问。你也可以从实例属性中删除所有双下划线,程序同样可以良好地运行。主要是为了防止这些属性在被外部模块导入时,由于被意外使用而造成的名字冲突。我们将名字改成含有类名的新标志符,这样做,可以确保这些属性不会被无意“访问”。更多信息,请参见13.14 节中关于私有成员的内容。
强调的是第二个元素是一个字符串,如果看到由引号标记的字符串时,会更加直观。做到这点可使用“repr()”对代码进行转换,把“%s”替换成“%r”。这相当于调用repr()或者使用单反引号来给出字符串的可求值版本--可求值版本的确要有引号:
>>> print a
[3 :: 'foo']如果在self.__string 中没有调用repr()(去掉单反引号或使用“%s”)将导致字符串引号丢失。代码中__str__()函数后的第一行是把这个函数赋给__repr__。一个可求值的字符串表示(repr)应当与可打印字符串(print)表示是一样的,而不是去定义一个完整的新函数,成为__str__()的副本,我们仅去创建一个别名,复制其引用。
Python 用于定制类的特征之一是,可以重载操作符,以使定制的这些类型更“实用”。调用一个函数,像“add(obj1,obj2)”是为“add”对象obj1 和ojb2,但如果能使用加号(+)来调用相同的操作是不是更具好呢?像这样,obj1+obj2。
重载加号,需要去为self(SELF)和其它操作数实现(OTHER)__add__().__add__()函数kao虑Self+Other 的情况,但我们不需要定义__radd__()来处理Other+Self,因为这可以由Other 的__add__()去kao虑。数值加法不像字符串那样结果受到(操作数)顺序的影响.加法操作把两个部分中的每一部分加起来,并用这个结果对形成一个新的对象----通过将结果做为参数调用self.__class__()来实例化.碰到任何类型不正确的对象时,我们会引发一个TypeError 异常.也可以重载星号[靠实现__mul__()],执行数值乘法和字符串重复,并同样通过实例化来创建一个新的对象。因为重复只允许整数在操作数的右边,因此也必执行此规则。基于同样的原因,我们在此也没有实现__rmul__()。
对标准类型而言,对象有一个false 值的情况为:它是一个类似于0 的数值,或是一个空序列,或者映射。就我们的类而言,我们选择数值必须为0,字符串要为空 作为一个实例有一个false 值的条件。覆盖__nonzero__()方法,就是为此目的。其它对象,像严格模拟序列或映射类型的对象,使用一个长度为0 作为false 值。这些情况,你需要实现__len__()方法,以实现那个功能。
__norm_cval() (“normalize cmp() value 的缩写”)不是一个特殊方法。它是一个帮助我们重载__cmp__()的助手函数:唯一的目的就是把cmp()返回的正值转为1,负值转为-1。cmp()基于比较的结果,通常返回任意的正数或负数(或0),但为了我们的目的,需要严格规定返回值为-1,0 和1。
对整数调用cmp()及与0 比较,结果即是我们所需要的,相当于如下代码片断:
def __norm_cval(self, cmpres):
if cmpres < 0:
return -1
elif cmpres > 0:
return 1
else:
return 0两个相似对象的实际比较是比较数字,比较字符串,然后返回这两个比较结果的和。
13.14 私有化
默认情况下,属性都是“public”,类所在模块和导入了类所在模块的其他模块的代码都可以访问到。很多OO 语言给数据加上一些可见性,只提供访问函数来访问其值。这就是隐藏,是对象封装中的一个关键部分。大多数OO 语言提供“访问控制符”来限定成员函数的访问。
双下划线(__)
Python 为类元素(属性和方法)的私有性提供初步的形式。由双下划线开始的属性在运行时被“混淆”,所以直接访问是不允许的。实际上,会在名字前面加上下划线和类名。以例13.6(numstr.py)中的self.__num 属性为例,被“混淆”后,用于访问这个数据值的标识就变成了self._NumStr__num。把类名加上后形成的新的“混淆”结果将可以防止在祖先类或子孙类中的同名冲突。
尽管这样做提供了某种层次上的私有化,但算法处于公共域中并且很容易被“击败”。这更多的是一种对导入源代码无法获得的模块或对同一模块中的其他代码的保护机制.
这种名字混淆的另一个目的,是为了保护__XXX 变量不与父类名字空间相冲突。如果在类中有一个__XXX 属性,它将不会被其子类中的__XXX 属性覆盖。(回忆一下,如果父类仅有一个XXX 属性,子类也定义了这个,这时,子类的XXX 就是覆盖了父类的XXX,这就是为什么你必须使用PARENT.XXX来调用父类的同名方法。) 使用__XXX,子类的代码就可以安全地使用__XXX,而不必担心它会影响到父类中的__XXX。
单下划线(_)
与我们在第十二章发现的那样,简单的模块级私有化只需要在属性名前使用一个单下划线字符。这就防止模块的属性用“from mymodule import *”来加载。这是严格基于作用域的,所以这同样适合于函数。
在Python 2.2 中引进的新式类,增加了一套全新的特征,让程序员在类及实例属性提供保护的多少上拥有大量重要的控制权。尽管Python 没有在语法上把private,protected,friend 或protected friend 等特征内建于语言中,但是可以按你的需要严格地定制访问权。我们不可能涵盖所有的内容,但会在本章后面给你一些有关新式类属性访问的建议。
13.15 *授权
13.15.1 包装
“包装”它是一个通用的名字,是对一个已存在的对象进行包装,不管它是数据类型,还是一段代码,可以是对一个已存在的对象,增加新的,删除不要的,或者修改其它已存在的功能。
在Python 2.2 版本前,从Python 标准类型子类化或派生类都是不允许的。即使你现在可以对新式类这样做,这一观念仍然很流行。你可以包装任何类型作为一个类的核心成员,以使新对象的行为模仿你想要的数据类型中已存在的行为,并且去掉你不希望存在的行为;它可能会要做一些额外的事情。这就是“包装类型”。在附录中,我们还将讨论如何扩充Python,包装的另一种形式。
包装包括定义一个类,它的实例拥有标准类型的核心行为。换句话说,它现在不仅能唱能跳,还能够像原类型一样步行,说话。图15-4 举例说明了在类中包装的类型看起像个什么样子。在图的中心为标准类型的核心行为,但它也通过新的或最新的功能,甚至可能通过访问实际数据的不同方法得到提高。
类对象(其表现像类型)
你还可以包装类,但这不会有太多的用途,因为已经有用于操作对象的机制,并且在上面已描述过,对标准类型有对其进行包装的方式。你如何操作一个已存的类,模拟你需要的行为,删除你不喜欢的,并且可能让类表现出与原类不同的行为呢?我们前面已讨论过,就是采用派生。

13.15.2 实现授权
授权是包装的一个特性,可用于简化处理有关dictating 功能,采用已存在的功能以达到最大限度的代码重用。包装一个类型通常是对已存在的类型的一些定制。这种做法可以新建,修改或删除原有产品的功能。其它的则保持原样,或者保留已存功能和行为。授权的过程,即是所有更新的功能都是由新类的某部分来处理,但已存在的功能就授权给对象的默认属性。
实现授权的关键点就是覆盖__getattr__()方法,在代码中包含一个对getattr()内建函数的调用。特别地,调用getattr()以得到默认对象属性(数据属性或者方法)并返回它以便访问或调用。
特殊方法__getattr__()的工作方式是,当搜索一个属性时,任何局部对象首先被找到(定制的对象)。如果搜索失败了,则__getattr__()会被调用,然后调用getattr()得到一个对象的默认行为。换言之,当引用一个属性时,Python 解释器将试着在局部名称空间中查找那个名字,比如一个自定义的方法或局部实例属性。如果没有在局部字典中找到,则搜索类名称空间,以防一个类属性被访问。最后,如果两类搜索都失败了,搜索则对原对象开始授权请求,此时,__getattr__()会被调用。
包装对象的简例:这个类似乎可以包装任何对象,提供基本功能,比如使用repr()和str()来处理字符串表示法。另外定制由get()方法处理,它删除包装并且返回原始对象。所以保留的功能都授权给对象的本地属性,在必要时,可由__getattr__()获得。
下面是包装类的例子:
class WrapMe(object):
def __init__(self, obj):
self.__data = obj
def get(self):
return self.__data
def __repr__(self):
return ‘self.__data‘
def __str__(self):
return str(self.__data)
def __getattr__(self, attr):
return getattr(self.__data, attr)我们用到复数,因为所有Python 数值类型,只有复数拥有属性:数据属性,及conjugate()内建方法。记住,属性可以是数据属性,还可以是函数或方法:
>>> wrappedComplex = WrapMe(3.5+4.2j)
>>> wrappedComplex # wrapped object: repr() 包装的对象:repr()
(3.5+4.2j)
>>> wrappedComplex.real # real attribute 实部属性
3.5
>>> wrappedComplex.imag # imaginary attribute 虚部属性
42.2
>>> wrappedComplex.conjugate() # conjugate() method conjugate()方法
(3.5-4.2j)
>>> wrappedComplex.get() # actual object 实际对象
(3.5+4.2j)一旦我们创建了包装的对象类型,只要由交互解释器调用repr(),就可以得到一个字符串表示。然后继续访问了复数的三种属性,类中一种都没有定义。在例子中,寻找实部,虚部及共轭复数的定义...they are not there!对这些属性的访问,是通过getattr()方法,授权给对象.最终调用get()方法没有授权,因为它是为我们的对象定义的----它返回包装的真实的数据对象。
下一个使用我们的包装类的例子用到一个列表。我们将会创建对象,然后执行多种操作,每次授权给列表方法。
>>> wrappedList = WrapMe([123, 'foo', 45.67])
>>> wrappedList.append('bar')
>>> wrappedList.append(123)
>>> wrappedList
[123, 'foo', 45.67, 'bar', 123]
>>> wrappedList.index(45.67)
2
>>> wrappedList.count(123)
2
>>> wrappedList.pop()
123
>>> wrappedList
[123, 'foo', 45.67, 'bar']尽管使用实例,它们展示的行为与它们包装的数据类型非常相似。然后,需要明白,只有已存在的属性是在此代码中授权的。
特殊行为没有在类型的方法列表中,不能被访问,因为它们不是属性。一个例子是,对列表的切片操作,它是内建于类型中的,而不是像append()方法那样作为属性存在的。从另一个角度来说,切片操作符是序列类型的一部分,并不是通过__getitem__()特殊方法来实现的。
>>> wrappedList[3]
Traceback (innermost last): File "<stdin>", line 1, in ?
File "wrapme.py", line 21, in __getattr__
return getattr(self.data, attr)
AttributeError: __getitem__AttributeError 异常出现的原因是切片操作调用了__getitem__()方法,且__getitme__()没有作为一个类实例方法进行定义,也不是列表对象的方法。回忆一下,什么时候调用getattr()呢?当在实例或类字典中的完整搜索失败后,就调用它来查找一个成功的匹配。你在上面可以看到,对getattr()的调用就是失败的那个,触发了异常。
然而,我们还有一种"作弊"的方法,访问实际对象[通过我们的get()方法]和它的切片能力.
>>> realList = wrappedList.get()
>>> realList[3]
'bar'你现在可能知道为什么我们实现get()方法了----仅仅是为了我们需要取得对原对象进行访问这种情况,我们可以从访问调用中直接访问对象的属性,而忽略局部变量(realList):
>>> wrappedList.get()[3]
'bar'get()方法返回一个对象,随后被索引以得到切片片断。
>>> f = WrapMe(open('/etc/motd'))
>>> f
<wrapMe.WrapMe object at 0x40215dac>
>>> f.get()
<open file '/etc/motd', mode 'r' at 0x40204ca0>
>>> f.readline()
'Have a lot of fun...\012'
>>> f.tell()
21
>>> f.seek(0)
>>> print f.readline(),
Have a lot of fun...
>>> f.close()
>>> f.get()
<closed file '/etc/motd', mode 'r' at 0x40204ca0>一旦你熟悉了对象的属性,你就能够开始理解一些信息片断从何而来,能够利用新得到的知识来重复功能:
>>> print "<%s file %s, mode %s at %x>" % \
... (f.closed and 'closed' or 'open', 'f.name',
'f.mode', id(f.get()))
<closed file '/etc/motd', mode 'r' at 80e95e0>我们刚接触使用类型模拟来进行类自定义。你将会发现可以进行无限多的改进,来进一步增加你的代码的用途。一种改进方法是为对象添加时间戳。
在下一小节中,我们将对我们的包装类增加另一个维度(dimension):
更新简单的包裹类
创建时间,修改时间,及访问时间是文件的几个常见属性,但没人说,你不能为对象加上这类信息。毕竟,一些应用能因有这些额外信息而受益。
若你对使用这三类时间顺序数据还不熟,我们会对它们进行解释。创建时间('ctime')是实例化的时间,修改时间('mtime')指的是核心数据升级的时间[通常会调用新的set()方法],而访问时间(或'atime')是最后一次对象的数据值被获取或者属性被访问时的时间戳。更新我们前面定义的类,可以创建一个模块twrapme.py。首先,你会发现增加了三个新方法:gettimeval(),gettimestr(),及set()。我们还增加数行代码,根据所执行的访问类型,更新相应的时间戳。
例13.7 包装标准类型(twrapme.py):类定义包装了任何内建类型,增加时间属性;get(),set(),还有字符串表示的方法;并授权所有保留的属性,访问这些标准类型。
from time import time,ctime
class TimedWrapMe(object):
def __init__(self, obj):
self.__data=obj
self.__ctime = sef.__mtime = self.__atime = time()
def get(self):
self.__atime = time()
return self.__data
def gettimeval(self, t_tye):
if not isinstance(t_type, str) or t_type[0] not in 'cma':
raise TypeError, "argument of 'c', 'm', or 'a' req'd"
return getattr(self, '_%s__%stime' % (self.__class__.__name__, t_type[0]))
def gettimestr(self, t_type):
return ctime(self.gettimeval(t_type))
def set(self, obj):
self.__data=obj
self.__mtime=self.__atime= time()
def __repr__(self):
self.__atime = time()
return `self.__data`
def __str__(self):
self.__atime = time()
return str(self.__data)
def __getattr__(self, attr):
self.__atime=time()
return getattr(self.__data, attr)
gettimeval()方法带一个简单的字符参数,“c”,“m”或“a”,相应地,对应于创建,修改或访问时间,并返回相应的时间,以一个浮点值保存。gettimestr()仅仅返回一个经time.ctime()函数格式化的打印良好的字符串形式的时间。
为新的模块作一个测试驱动。我们已看到授权是如何工作的,所以,我们将包装没有属性的对象,来突出刚加入的新的功能。在例子中,我们包装了一个整数,然后,将其改为字符串。
>>> timeWrappedObj = TimedWrapMe(932)
>>> timeWrappedObj.gettimestr('c')
‘Wed Apr 26 20:47:41 2006'
>>> timeWrappedObj.gettimestr('m')
'Wed Apr 26 20:47:41 2006'
>>> timeWrappedObj.gettimestr('a')
'Wed Apr 26 20:47:41 2006'
>>> timeWrappedObj
932
>>> timeWrappedObj.gettimestr('c')
'Wed Apr 26 20:47:41 2006'
>>> timeWrappedObj.gettimestr('m')
'Wed Apr 26 20:47:41 2006'
>>> timeWrappedObj.gettimestr('a')
'Wed Apr 26 20:48:05 2006'
你将注意到,一个对象在第一次被包装时,创建,修改,及最后一次访问时间都是一样的。一旦对象被访问,访问时间即被更新,但其它的没有动。如果使用set()来置换对象,则修改和最后一次访问时间会被更新。例子中,最后是对对象的读访问操作。
>>> timeWrappedObj.set('time is up!')
>>> timeWrappedObj.gettimestr('m')
'Wed Apr 26 20:48:35 2006'
>>> timeWrappedObj
'time is up!'
>>> timeWrappedObj.gettimestr('c')
'Wed Apr 26 20:47:41 2006'
>>> timeWrappedObj.gettimestr('m')
'Wed Apr 26 20:48:35 2006'
>>> timeWrappedObj.gettimestr('a')
'Wed Apr 26 20:48:46 2006'
改进包装一个特殊对象
下一个例子,描述了一个包装文件对象的类。我们的类与一般带一个异常的文件对象行为完全一样:在写模式中,字符串只有全部为大写时,才写入文件。
这里,我们要解决的问题是,当你正在写一个文本文件,其数据将会被一台旧电脑读取。很多老式机器在处理时,严格要求大写字母,所以,我们要实现一个文件对象,其中所有写入文件的文本会自动转化为大写,程序员就不必担心了。
事实上,唯一值得注意的不同点是并不使用open()内建函数,而是调用CapOpen 类时行初始化。
尽管,参数同open()完全一样。
例13.8 展示那段代码,文件名是capOpen.py。下面看一下例子中是如何使用这个类的:
>>> f = CapOpen('/tmp/xxx', 'w')
>>> f.write('delegation example\n')
>>> f.write('faye is good\n')
>>> f.write('at delegating\n')
>>> f.close()
>>> f
<closed file '/tmp/xxx', mode 'w' at 12c230>
例13.8 包装文件对象(capOpen.py)
这个类扩充了Python FAQs 中的一个例子,提供一个文件类对象,定制write()方法,同时,给文件对象授权其它的功能。
1 #!/usr/bin/env python
2
3 class CapOpen(object):
4 def __init__(self, fn, mode='r', buf=-1):
5 self.file = open(fn, mode, buf)
6
7 def __str__(self):
8 return str(self.file)
9
10 def __repr__(self):
11 return 'self.file'
12
13 def write(self, line):
14 self.file.write(line.upper())
15
16 def __getattr__(self, attr):
17 return getattr(self.file, attr)
可以看到,唯一不同的是第一次对CapOpen()的调用,而不是open()。如果你正与一个实际文件对象,而非行为像文件对象的类实例进行交互,那么其它所有代码与你本该做的是一样的。除了write(),所有属性都已授权给文件对象。为了确定代码是否正确,我们加载文件,并显示其内容。
(注:可以使用open()或CapOpen(),这里因在本例中用到,所以选用CapOpen()。)
>>> f = CapOpen('/tmp/xxx', 'r')
>>> for eachLine in f:
... print eachLine,
...
DELEGATION EXAMPLE FAYE IS GOOD
AT DELEGATING13.16 新式类的高级特性 (Python 2.2+)
13.16.1 新式类的通用特性
由于类型和类的统一,这些特性中最重要的是能够子类化Python 数据类型。其中一个副作用是,所有的Python 内建的 “casting” 或转换函数现在都是工厂函数。当这些函数被调用时,你实际上是对相应的类型进行实例化。
下面的内建函数,跟随Python 多日,都已“悄悄地”(也许没有)转化为工厂函数:

这些类名及工厂函数使用起来很灵活。不仅能够创建这些类型的新对象,它们还可以用来作为基类,去子类化类型,现在还可以用于isinstance()内建函数。比如,为测试一个对象是否是一个整数,旧风格中,须调用type()两次或者import 相关的模块并使用其属性;但现在只需要使用isinstance(),甚至在性能上也有所超越:
OLD (not as good):
if type(obj) == type(0)…
if type(obj) == types.IntType…
BETTER:
if type(obj) is type(0)…
EVEN BETTER:
if isinstance(obj, int)…
if isinstance(obj, (int, long))…
if type(obj) is int…记住:尽管isinstance()很灵活,但它没有执行“严格匹配”比较----如果obj 是一个给定类型的实例或其子类的实例,也会返回True。但如果想进行严格匹配,你仍然需要使用is 操作符。
请复习13.12.2 节中有关isinstance()的深入解释,还有在第4 章中介绍这些调用是如何随同Python 的变化而变化的。
13.16.2 __slots__类属性
字典位于实例的“心脏”。__dict__属性跟踪所有实例属性。举例来说,你有一个实例inst.它有一个属性foo,那使用inst.foo 来访问它与使用inst.__dict__['foo']来访问是一致的。字典会占据大量内存,如果你有一个属性数量很少的类,但有很多实例,那么正好是这种情况。为内存上的kao虑,用户现在可以使用__slots__属性来替代__dict__。基本上,__slots__是一个类变量,由一序列型对象组成,由所有合法标识构成的实例属性的集合来表示。它可以是一个列表,元组或可迭代对象。也可以是标识实例能拥有的唯一的属性的简单字符串。任何试图创建一个其名不在__slots__中的名字的实例属性都将导致AttributeError 异常:
class SlottedClass(object):
__slots__ = ('foo', 'bar')
>>> c = SlottedClass()
>>>
>>> c.foo = 42
>>> c.xxx = "don't think so" Traceback (most recent call last):
File "<stdin>", line 1, in ?
AttributeError: 'SlottedClass' object has no attribute
'xxx'这种特性的主要目的是节约内存。其副作用是某种类型的"安全",它能防止用户随心所欲的动态增加实例属性。带__slots__属性的类定义不会存在__dict__了(除非你在__slots__中增加'__dict__'元素)。更多有关__slots__的信息,请参见Python(语言)参kao手册中有关数据模型章节。
13.16.3 特殊方法__getattribute__()
Python 类有一个名为__getattr__()的特殊方法,它仅当属性不能在实例的__dict__或它的类(类的__dict__),或者祖先类(其__dict__)中找到时,才被调用。我们曾在实现授权中看到过使用__getattr__()。
很多用户碰到的问题是,他们想要一个适当的函数来执行每一个属性访问,不光是当属性不能找到的情况。这就是__getattribute__()用武之处了。它使用起来,类似__getattr__(),不同之处在于,当属性被访问时,它就一直都可以被调用,而不局限于不能找到的情况。
如果类同时定义了__getattribute__()及__getattr__()方法,除非明确从__get-attribute__()调用,或__getattribute__()引发了AttributeError 异常,否则后者不会被调用.如果你将要在此(译者注:__getattribute__()中)访问这个类或其祖先类的属性,请务必小心。如果你在__getattribute__()中不知何故再次调用了__getattribute__(),你将会进入无穷递归。为避免在使用此方法时引起无穷递归,为了安全地访问任何它所需要的属性,你总是应该调用祖先类的同名方法;比如,super(obj,self).__getattribute__(attr)。此特殊方法只在新式类中有效。
同__slots__一样,你可以参kaoPython(语言)参kao手册中数据模型章节,以得到更多有关__getattribute__()的信息。
13.16.4 描述符
描述符是Python 新式类中的关键点之一。它为对象属性提供强大的API。你可以认为描述符是表示对象属性的一个代理。当需要属性时,可根据你遇到的情况,通过描述符(如果有)或者采用常规方式(句点属性标识法)来访问它。
如你的对象有代理,并且这个代理有一个“get”属性(实际写法为__get__),当这个代理被调用时,你就可以访问这个对象了。当你试图使用描述符(set)给一个对象赋值或删除一个属性(delete)时,这同样适用。
__get__(),__set__(),__delete__()特殊方法
严格来说, 描述符实际上可以是任何( 新式) 类, 这种类至少实现了三个特殊方法__get__(),__set__()及__delete__()中的一个,这三个特殊方法充当描述符协议的作用。刚才提到过,__get__()可用于得到一个属性的值,__set__()是为一个属性进行赋值的,在采用del 语句(或其它,其引用计数递减)明确删除掉某个属性时会调__delete__()方法。三者中,后者很少被实现。
还有,也不是所有的描述符都实现了__set__()方法。它们被当作方法描述符,或更准确来说是,非数据描述符来被引用。那些同时覆盖__get__()及__set__()的类被称作数据描述符,它比非数据描述符要强大些。
The signatures for __get__(), __set__(), and __delete__() look like this:
__get__(),__set__()及__delete__()的原型,如下:
? def __get__(self, obj, typ=None) ==> value
? def __set__(self, obj, val) ==> None
? def __delete__(self, obj) ==> None
如果你想要为一个属性写个代理,必须把它作为一个类的属性,让这个代理来为我们做所有的工作。当你用这个代理来处理对一个属性的操作时,你会得到一个描述符来代理所有的函数功能。我们在前面的一节中已经讲过封装的概念。这里我们会进一步来探讨封装的问题。现在让我们来处理更加复杂的属性访问问题,而不是将所有任务都交给你所写的类中的对象们。
__getattribute__() 特殊方法(二)
使用描述符的顺序很重要,有一些描述符的级别要高于其它的。整个描述符系统的心脏是__getattribute__(),因为对每个属性的实例都会调用到这个特殊的方法。这个方法被用来查找类的属性,同时也是你的一个代理,调用它可以进行属性的访问等操作。回顾一下上面的原型,如果一个实例调用了__get__()方法,这就可能传入了一个类型或类的对象。举例来说,给定类X 和实例x, x.foo 由__getattribute__()转化成:
type(x).__dict__['foo'].__get__(x, type(x))
如果类调用了__get__()方法,那么None 将作为对象被传入(对于实例, 传入的是self):X.__dict__['foo'].__get__(None, X)
最后,如果super()被调用了,比如,给定Y 为X 的子类,然后用super(Y,obj).foo 在obj.__class__.__mro__中紧接类Y 沿着继承树来查找类X,然后调用:X.__dict__['foo'].__get__(obj, X)然后,描述符会负责返回需要的对象。
优先级别
由于__getattribute__()的实现方式很特别,我们在此对__getattribute__()方法的执行方式做一个介绍。因此了解以下优先级别的排序就非常重要了:
? 类属性
? 数据描述符
? 实例属性
? 非数据描述符
? 默认为__getattr__()
描述符是一个类属性,因此所有的类属性皆具有最高的优先级。你其实可以通过把一个描述符的引用赋给其它对象来替换这个描述符。比它们优先级别低一等的是实现了__get__()和__set__()方法的描述符。如果你实现了这个描述符,它会像一个代理那样帮助你完成所有的工作!否则,它就默认为局部对象的__dict__的值,也就是说,它可以是一个实例属性。接下来是非数据描述符。可能第一次听起来会吃惊,有人可能认为在这条“食物链”上非数据描述符应该比实例属性的优先级更高,但事实并非如此。非数据描述符的目的只是当实例属性值不存在时,提供一个值而已。这与以下情况类似: 当在一个实例的__dict__ 中找不到某个属性时, 才去调用__getattr__()。
关于__getattr__()的说明,如果没有找到非数据描述符,那么__getattribute__()将会抛出一个AttributeError 异常,接着会调用__getattr__()做为最后一步操作,否则AttributeError 会 返回给用户。
描述符举例
让我们来看一个简单的例子...用一个描述符禁止对属性进行访问或赋值的请求。事实上,以下所有示例都忽略了全部请求,但它们的功能逐步增多,我们希望你通过每个示例逐步掌握描述符的使用:
class DevNull1(object):
def __get__(self, obj, typ=None):
pass
def __set__(self, obj, val):
pass
我们建立一个类,这个类使用了这个描述符,给它赋值并显示其值:
>>> class C1(object):
... foo = DevNull1()
...
>>> c1 = C1()
>>> c1.foo = 'bar'
>>> print 'c1.foo contains:', c1.foo
c1.foo contains: None
That was not too terribly exciting … how about one where the descriptor methods at
least give some output to show what is going on?
这并没有什么有趣的 ... 让我们来看看在这个描述符中写一些输出语句会怎么样?
class DevNull2(object):
def __get__(self, obj, typ=None):
print 'Accessing attribute... ignoring'
def __set__(self, obj, val):
print 'Attempt to assign %r... ignoring' % (val)
现在我们来看看修改后的结果:
>>> class C2(object):
... foo = DevNull2()
...
>>> c2 = C2()
>>> c2.foo = 'bar'
Attempt to assign 'bar'... ignoring
>>> x = c2.foo
Accessing attribute... ignoring
>>> print 'c2.foo contains:', x
c2.foo contains: None
最后,我们在描述符所在的类中添加一个占位符,占位符包含有关于这个描述符的有用信息:
class DevNull3(object):
def __init__(self, name=None):
self.name = name
def __get__(self, obj, typ=None):
print 'Accessing [%s]... ignoring' %
self.name)
def __set__(self, obj, val):
print 'Assigning %r to [%s]... ignoring' %
val, self.name)
下面的输出结果表明我们前面提到的优先级层次结构的重要性,尤其是我们说过,一个完整的数据描述符比实例的属性具有更高的优先级:
>>> class C3(object):
... foo = DevNull3('foo')
...
>>> c3 = C3()
>>> c3.foo = 'bar'
Assigning 'bar' to [foo]... ignoring
>>> x = c3.foo
Accessing [foo]... ignoring
>>> print 'c3.foo contains:', x
c3.foo contains: None
>>> print 'Let us try to sneak it into c3 instance...'
Let us try to sneak it into c3 instance...
>>> c3.__dict__['foo'] = 'bar'
>>> x = c3.foo
Accessing [foo]... ignoring
>>> print 'c3.foo contains:', x
c3.foo contains: None
>>> print "c3.__dict__['foo'] contains: %r" % \
c3.__dict__['foo'], "... why?!?"
c3.__dict__['foo'] contains: 'bar' ... why?!?
请注意我们是如何给实例的属性赋值的。给实例属性c3.foo 赋值为一个字符串“bar”。但由于数据描述符比实例属性的优先级高,所赋的值“bar”被隐藏或覆盖了。
同样地,由于实例属性比非数据描述符的优先级高,你也可以将非数据描述符隐藏。这就和你给一个实例属性赋值,将对应类的同名属性隐藏起来是同一个道理:
>>> class FooFoo(object):
... def foo(self):
... print 'Very important foo() method.'
...
>>>
>>> bar = FooFoo()
>>> bar.foo()
Very important foo() method.
>>>
>>> bar.foo = 'It is no longer here.'
>>> bar.foo
'It is no longer here.'
>>>
>>> del bar.foo
>>> bar.foo()
Very important foo() method.
这是一个直白的示例。我们将foo 做为一个函数调用,然后又将它作为一个字符串访问,但我们也可以使用另一个函数,而且保持相同的调用机制:
>>> def barBar():
... print 'foo() hidden by barBar()'
...
>>> bar.foo = barBar
>>> bar.foo()
foo() hidden by barBar()
>>>
>>> del bar.foo
>>> bar.foo()
Very important foo() method.
要强调的是:函数是非数据描述符,实例属性有更高的优先级,我们可以遮蔽任一个非数据描述符,只需简单的把一个对象赋给实例(使用相同的名字)就可以了。
我们最后这个示例完成的功能更多一些,它尝试用文件系统保存一个属性的内容,这是个雏形版本。
第1-10 行
在引入相关模块后,我们编写一个描述符类,类中有一个类属性(saved), 它用来记录描述符访问的所有属性。描述符创建后,它将注册并且记录所有从用户处接收的属性名。
第12-26 行
在获取描述符的属性之前,我们必须确保用户给它们赋值后才能使用。如果上述条件成立,接着我们将尝试打开pickle 文件以读取其中所保存的值。如果文件打开失败,将引发一个异常。文件打开失败的原因可能有以下几种:文件已被删除了(或从未创建过),或是文件已损坏,或是由于某种原因,不能被pickle 模块反串行化。
第18-38 行
将属性保存到文件中需要经过以下几个步骤:打开用于写入的pickle 文件(可能是首次创建一个新的文件,也可能是删掉旧的文件),将对象串行化到磁盘,注册属性名,使用户可以读取这些属性值。如果对象不能被pickle{待统一命名},将引发一个异常。注意,如果你使用的是Python2.5以前的版本,你就不能合并try-except 和try-finally 语句(第30-38 行)。
例13.9 使用文件来存储属性(descr.py)
这个类是一个雏形,但它展示了描述符的一个有趣的应用--可以在一个文件系统上保存属性的内容。
1 #!/usr/bin/env python
2
3 import os
4 import pickle
5
6 class FileDescr(object):
7 saved = []
8
9 def __init__(self, name=None):
10 self.name = name
11
12 def __get__(self, obj, typ=None):
13 if self.name not in FileDescr.saved:
14 raise AttributeError, \
15 "%r used before assignment" % self.name
16
17 try:
18 f = open(self.name, 'r')
19 val = pickle.load(f)
20 f.close()
21 return val
22 except(pickle.InpicklingError, IOError,
23 EOFError, AttributeError,
24 ImportError, IndexError), e:
25 raise AttributeError, \
26 "could not read %r: %s" % self.name
27
28 def __set__(self, obj, val):
29 f = open(self.name, 'w')
30 try:
31 try:
32 pickle.dump(val, f)
33 FileDescr.saved.append(self.name)
34 except (TypeError, pickle.PicklingError), e:
35 raise AttributeError, \
36 "could not pickle %r" % self.name
37 finally:
38 f.close()
39
40 def __delete__(self, obj):
41 try:
42 os.unlink(self.name)
Edit By Vheavens
Edit By Vheavens
43 FileDescr.saved.remove(self.name)
44 except (OSError, ValueError), e:
45 pass
第40-45 行
最后,如果属性被删除了,文件会被删除,属性名字也会被注销。以下是这个类的用法示例:
>>> class MyFileVarClass(object):
...
foo = FileDescr('foo')
...
bar = FileDescr('bar')
...
>>> fvc = MyFileVarClass()
>>> print fvc.foo
Traceback (most recent call last): File "<stdin>", line 1, in ?
File "descr.py", line 14, in __get__
raise AttributeError, \
AttributeError: 'foo' used before assignment
>>>
>>> fvc.foo = 42
>>> fvc.bar = 'leanna'
>>>
>>> print fvc.foo, fvc.bar
42 leanna
>>>
>>> del fvc.foo
>>> print fvc.foo, fvc.bar
Traceback (most recent call last): File "<stdin>", line 1, in ?
File "descr.py", line 14, in __get__
raise AttributeError, \
AttributeError: 'foo' used before assignment
>>>
>>> fvc.foo = __builtins__ Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "descr.py", line 35, in __set__
raise AttributeError, \ AttributeError: could not pickle 'foo'
属性访问没有什么特别的,程序员并不能准确判断一个对象是否能被打包后存储到文件系统中
(除非如最后示例所示,将模块pickle,我们不该这样做)。我们也编写了异常处理的语句来处理文
Edit By Vheavens
Edit By Vheavens
件损坏的情况。在本例中,我们第一次在描述符中实现__delete__()方法。
请注意,在示例中,我们并没有用到obj 的实例。别把obj 和self 搞混淆,这个self 是指描
述符的实例,而不是类的实例。
描述符总结
你已经看到描述符是怎么工作的。静态方法、类方法、属性(见下面一节),甚至所有的函数都
是描述符。想一想:函数是Python 中常见的对象。有内置的函数、用户自定义的函数、类中定义的
方法、静态方法、类方法。这些都是函数的例子。 它们之间唯一的区别在于调用方式的不同。通常,
函数是非绑定的。虽然静态方法是在类中被定义的,它也是非绑定的。但方法必须绑定到一个实例
上,类方法必须绑定到一个类上,对不?一个函数对象的描述符可以处理这些问题,描述符会根据
函数的类型确定如何“封装”这个函数和函数被绑定的对象,然后返回调用对象。它的工作方式是
这样的:函数本身就是一个描述符,函数的__get__()方法用来处理调用对象,并将调用对象返回给
你。描述符具有非常棒的适用性,因此从来不会对Python 自己的工作方式产生影响。
属性和property()内建函数
属性是一种有用的特殊类型的描述符。它们是用来处理所有对实例属性的访问,其工作方式和
我们前面说过的描述符相似。“一般”情况下,当你使用点属性符号来处理一个实例属性时,其实
你是在修改这个实例的__dict__属性。
表面上来看,你使用property()访问和一般的属性访问方法没有什么不同,但实际上这种访问
的实现是不同的 - 它使用了函数(或方法)。在本章的前面,你已看到在Python 的早期版本中,我
们一般用__getattr__() 和 __setattr__() 来处理和属性相关的问题。属性的访问会涉及到以上特
殊的方法(和__getattribute__()),但是如果我们用property()来处理这些问题,你就可以写一个
和属性有关的函数来处理实例属性的获取(getting),赋值(setting),和删除(deleting)操作,而不
必再使用那些特殊的方法了(如果你要处理大量的实例属性,使用那些特殊的方法将使代码变得很臃
肿)。
property()内建函数有四个参数,它们是 :
property(fget=None, fset=None, fdel=None, doc=None)
请注意property()的一般用法是,将它写在一个类定义中,property()接受一些传进来的函数
(其实是方法)作为参数。实际上,property()是在它所在的类被创建时被调用的,这些传进来的(作
为参数的)方法是非绑定的,所以这些方法其实就是函数!
下面的一个例子:在类中建立一个只读的整数属性,用逐位异或操作符将它隐藏起来:
Edit By Vheavens
Edit By Vheavens
class ProtectAndHideX(object):
def __init__(self, x):
assert isinstance(x, int), \
'"x" must be an integer!'
self.__x = ~x
def get_x(self):
return ~self.__x
x = property(get_x)
我们来运行这个例子,会发现它只保存我们第一次给出的值,而不允许我们对它做第二次修改:
>>> inst = ProtectAndHideX('foo')
Traceback (most recent call last):
File "<stdin>", line 1, in ?
File "prop.py", line 5, in __init__
assert isinstance(x, int), \
AssertionError: "x" must be an integer!
>>> inst = ProtectAndHideX(10)
>>> print 'inst.x =', inst.x
inst.x = 10
>>> inst.x = 20
Traceback (most recent call last):
File "<stdin>", line 1, in ?
AttributeError: can't set attribute
下面是另一个关于setter 的例子:
class HideX(object):
def __init__(self, x):
self.x = x
def get_x(self):
return ~self.__x
def set_x(self, x):
assert isinstance(x, int), \
'"x" must be an integer!'
self.__x = ~x
Edit By Vheavens
Edit By Vheavens
x = property(get_x, set_x)
本示例的输出结果:
>>> inst = HideX(20)
>>> print inst.x
20
>>> inst.x = 30
>>> print inst.x
30
属性成功保存到x 中并显示出来,是因为在调用构造器给x 赋初始值前,在getter 中已经将~x
赋给了self.__x.
你还可以给自己写的属性添加一个文档字符串,参见下面这个例子:
from math import pi
def get_pi(dummy):
return pi
class PI(object):
pi = property(get_pi, doc='Constant "pi"')
为了说明这是可行的实现方法,我们在property 中使用的是一个函数而不是方法。注意在调用
函数时self 作为第一个(也是唯一的)参数被传入,所以我们必须加一个伪变量把self 丢弃。下面
是本例的输出:
>>> inst = PI()
>>> inst.pi
3.1415926535897931
>>> print PI.pi.__doc__
Constant "pi"
你明白properties 是如何把你写的函数(fget, fset 和 fdel)影射为描述符的__get__(),
__set__(), 和__delete__()方法的吗?你不必写一个描述符类,并在其中定义你要调用的这些方法。
只要把你写的函数(或方法)全部传递给property()就可以了。
在你写的类定义中创建描述符方法的一个弊端是它会搞乱类的名字空间。不仅如此,这种做法
Edit By Vheavens
Edit By Vheavens
也不会像property()那样很好地控制属性访问。如果不用property()这种控制属性访问的目的就不
可能实现。我们的第二个例子没有强制使用property(),因为它允许对属性方法的访问(由于在类定
义中包含属性方法):
>>> inst.set_x(40) # can we require inst.x = 40?
>>> print inst.x
40
APNPC(ActiveState Programmer Network Python Cookbook)
(http://aspn.activestate.com/ASPN/Cookbook/Python/Recipe/205183)上的一条精明的办
法解决了以下问题:
? “借用”一个函数的名字空间
? 编写一个用作内部函数的方法作为 property()的(关键字)参数
? (用 locals())返回一个包含所有的(函数/方法)名和对应对象的字典
? 把字典传入 property(),然后
? 去掉临时的名字空间
这样,方法就不会再把类的名字空间搞乱了,因为定义在内部函数中的这些方法属于其它的
名字空间。由于这些方法所属的名字空间已超出作用范围,用户是不能够访问这些方法的,所以通
过使用属性property()来访问属性就成为了唯一可行的办法。根据APNPC 上方法,我们来修改这个
类:
class HideX(object):
def __init__(self, x):
self.x = x
@property
def x():
def fget(self):
return ~self.__x
def fset(self, x):
assert isinstance(x, int), \
'"x" must be an integer!'
self.__x = ~x
return locals()
我们的代码工作如初,但有两点明显不同:(1) 类的名字空间更加简洁,只有 ['__doc__',
Edit By Vheavens
Edit By Vheavens
'__init__', '__module__', 'x'], (2), 用户不能再通过inst.set_x(40) 给属性赋值 ... 必须
使用init.x = 40. 我们还使用函数修饰符 (@property) 将函数中的x 赋值到一个属性对象。由于
修饰符是从Python 2.4 版本开始引入的,如果你使用的是Python 的早期版本2.2.x 或 2.3.x,请
将修饰符@property 去掉,在x()的函数声明后添加 x = property(**x())。
13.16.5 Metaclasses 和__metaclass__
元类(Metaclasses)是什么?
元类可能是添加到新风格类中最难以理解的功能了。元类让你来定义某些类是如何被创建的,
从根本上说,赋予你如何创建类的控制权。(你甚至不用去想类实例层面的东西。)早在Python1.5
的时代,人们就在谈论这些功能(当时很多人都认为不可能实现),但现在终于实现了。
从根本上说,你可以把元类想成是一个类中类,或是一个类,它的实例是其它的类。实际上,
当你创建一个新类时,你就是在使用默认的元类,它是一个类型对象。(对传统的类来说,它们的元
类是types.ClassType.)当某个类调用type()函数时,你就会看到它到底是谁的实例:
class C(object):
pass
class CC:
pass
>>> type(C)
<type 'type'>
>>>
>>> type(CC)
<type 'classobj'>
>>>
>>> import types
>>> type(CC) is types.ClassType
True
什么时候使用元类?
元类一般用于创建类。在执行类定义时,解释器必须要知道这个类的正确的元类。解释器会先
寻找类属性__metaclass__,如果此属性存在,就将这个属性赋值给此类作为它的元类。如果此属性
没有定义,它会向上查找父类中的__metaclass__. 所有新风格的类如果没有任何父类,会从对象或
类型中继承。(type (object) 当然是类型).
Edit By Vheavens
Edit By Vheavens
如果还没有发现__metaclass__属性,解释器会检查名字为__metaclass__的全局变量,如果它
存在,就使用它作为元类。否则, 这个类就是一个传统类,并用types.ClassType 作为此类的元类。
(注意:在这里你可以运用一些技巧... 如果你定义了一个传统类,并且设置它的__metaclass__ =
type,其实你是在将它升级为一个新风格的类!)
在执行类定义的时候,将检查此类正确的(一般是默认的)元类,元类(通常)传递三个参数(到构
造器):类名,从基类继承数据的元组,和(类的)属性字典。
谁在用元类?
元类这样的话题对大多数人来说属于理论化或纯面向对象思想的范畴,认为它在实际编程中没
有什么实际意义。从某种意义上讲这种想法是正确的;但最重要的请铭记在心的是,元类的最终使
用者不是用户,正是程序员自己。你通过定义一个元类来“迫使”程序员按照某种方式实现目标类,
这将既可以简化他们的工作,也可以使所编写的程序更符合特定标准。
元类何时被创建?
前面我们已提到创建的元类用于改变类的默认行为和创建方式。大多数Python 用户都无须创
建或明确地使用元类。创建一个新风格的类或传统类的通用做法是使用系统自己所提供的元类的默
认方式。
用户一般都不会觉察到元类所提供的创建类(或元类实例化)的默认模板方式。虽然一般我们并
不创建元类,还是让我们来看下面一个简单的例子。(关于更多这方面的示例请参见本节末尾的文档
列表。)
元类示例1
我们第一个关于元类的示例非常简单(希望如此)。它只是在用元类创建一个类时,显示时间标
签。(你现在该知道,这发生在类被创建的时候。)
看下面这个脚本。它包含的print 语句散落在代码各个地方,便于我们了解所发生的事情:
#!/usr/bin/env python
from time import ctime
print '*** Welcome to Metaclasses!'
print '\tMetaclass declaration first.'
Edit By Vheavens
Edit By Vheavens
class MetaC(type):
def __init__(cls, name, bases, attrd):
super(MetaC, cls).__init__(name, bases, attrd)
print '*** Created class %r at: %s' % (name, ctime())
print '\tClass "Foo" declaration next.'
class Foo(object):
__metaclass__ = MetaC
def __init__(self):
print '*** Instantiated class %r at: %s' % (
self.__class__.__name__, ctime())
print '\tClass "Foo" instantiation next.'
f = Foo()
print '\tDONE'
当我们执行此脚本时,将得到以下输出:
*** Welcome to Metaclasses! Metaclass declaration first. Class "Foo" declaration next.
*** Created class 'Foo' at: Tue May 16 14:25:53 2006
Class "Foo" instantiation next.
*** Instantiated class 'Foo' at: Tue May 16 14:25:53 2006
DONE
当你明白了一个类的定义其实是在完成某些工作的事实以后,你就容易理解这是怎么一回事情
了。
元类示例2
在第二个示例中,我们将创建一个元类,要求程序员在他们写的类中提供一个__str__()方法的
实现,这样用户就可以看到比我们在本章前面所见到的一般Python 对象字符串(<object object at
id>)更有用的信息。
如果您还没有在类中覆盖__repr__()方法,元类会(强烈)提示您这么做,但这只是个警告。如
果未实现__str__()方法,将引发一个TypeError 的异常,要求用户编写一个同名方法。以下是关于
元类的代码:
from warnings import warn
Edit By Vheavens
Edit By Vheavens
class ReqStrSugRepr(type):
def __init__(cls, name, bases, attrd):
super(ReqStrSugRepr, cls).__init__(
name, bases, attrd)
if '__str__' not in attrd:
raise TypeError("Class requires overriding of __str__()")
if '__repr__' not in attrd:
warn('Class suggests overriding of __repr__()\n', stacklevel=3)
我们编写了三个关于元类的示例,其中一个(Foo)重载了特殊方法__str__()和__repr__(),另一
个(Bar)只实现了特殊方法__str__(),还有一个(FooBar)没有实现__str__()和 __repr__(),这种
情况是错误的。完整的程序见示例13.10.
执行此脚本,我们得到如下输出:
$ python meta.py
*** Defined ReqStrSugRepr (meta)class
*** Defined Foo class
sys:1: UserWarning: Class suggests overriding of
__repr__()
*** Defined Bar class
Traceback (most recent call last): File "meta.py", line 43, in ?
class FooBar(object):
File "meta.py", line 12, in __init__
raise TypeError(
TypeError: Class requires overriding of __str__()
示例13.10 元类示例 (meta.py)
这个模块有一个元类和三个受此元类限定的类。每创建一个类,将打印一条输出语句。
1 #!/usr/bin/env python
2
3 from warnings import warn
Edit By Vheavens
Edit By Vheavens
4
5 class ReqStrSugRepr(type):
6
7 def __init__(cls, name, bases, attrd):
8 super(ReqStrSugRepr, cls).__init__(
9 name, bases, attrd)
10
11 if '__str__' not in attrd:
12 raise TypeError(
13 "Class requires overriding of __str__()")
14
15 if '__repr__' not in attrd:
16 warn(
17 'Class suggests overriding of __repr__()\n',
18 stacklevel=3)
19
20 print '*** Defined ReqStrSugRepr (meta)class\n'
21
22 class Foo(object):
23 __metaclass__ = ReqStrSugRepr
24
25 def __str__(self):
26 return 'Instance of class:', \
27 self.__class__.__name__
28
29 def __repr__(self):
30 return self.__class__.__name__
31
32 print '*** Defined Foo class\n'
33
34 class Bar(object):
35 __metaclass__ = ReqStrSugRepr
36
37 def __str__(self):
38 return 'Instance of class:', \
39 self.__class__.__name__
40
41 print '*** Defined Bar class\n'
42
43 class FooBar(object):
Edit By Vheavens
Edit By Vheavens
44 __metaclass__ = ReqStrSugRepr
45
46 print '*** Defined FooBar class\n'
注意我们是如何成功声明Foo 定义的;定义Bar 时,提示警告__repr__()未实现;FooBar 的创
建没有通过安全检查,以致程序最后没有打印出关于FooBar 的语句。另外要注意的是我们并没有创
建任何测试类的实例... 这些甚至根本不包括在我们的设计中。但别忘了这些类本身就是我们自己
的元类的实例。这个示例只显示了元类强大功能的一方面。
关于元类的在线文档众多,包括Python 文档PEPs 252 和253,《What’s New in Python 2.2》
文档,Guido van Rossum 所写的名为“Unifying Types and Classes in Python 2.2”的文章。在
Python 2.2.3 发布的主页上你也可以找到相关文档的链接地址。
13.17 相关模块和文档
我们在本章已经对核心语言做了讲述,而Python 语言中有几个扩展了核心语言功能的经典类。
这些类为Python 数据类型的子类化提供了方便。
模块好比速食品,方便即食。我们曾提到类可以有特殊的方法,如果实现了这些特殊方法,就
可以对类进行定制,这样当对一个标准类型封装时,可以给实例带来和类型一样的使用效果。
UserList 和UserDict,还有新的UserString(从Python1.6 版本开始引入)分别代表对列表、字
典、字符串对象进行封装的类定义模块。这些模块的主要用处是提供给用户所需要的功能,这样你
就不必自己动手去实现它们了,同时还可以作为基类,提供子类化和进一步定制的功能。Python 语
言已经为我们提供了大量有用的内建类型,但这种"由你自己定制"类型的附加功能使得Python 语言
更加强大。
在第四章里,我们介绍了Python 语言的标准类型和其它内建类型。types 模块是进一步学习
Python 类型方面知识的好地方,其中的一些内容已超出了本书的讨论范围。types 模块还定义了一
些可以用于进行比较操作的类型对象。(这种比较操作在Python 中很常见,因为它不支持方法的重
载 - 这简化的语言本身,同时又提供了一些工具,为貌似欠缺的地方添加功能.)
下面的代码检查传递到foo 函数的数据对象是否是一个整数或一个字符串,不允许其他类型出
现(否则会引发一个异常):
def foo(data):
if isinstance(data, int):
print 'you entered an integer'
elif isinstance(data, str):
Edit By Vheavens
Edit By Vheavens
print 'you entered a string'
else:
raise TypeError, 'only integers or strings!'
最后一个相关模块是operator 模块。这个模块提供了Python 中大多数标准操作符的函数版本。
在某些情况下,这种接口类型比标准操作符的硬编码方式更通用。
请看下边的示例。在你阅读代码时,请设想一下如果此实现中使用的是一个个操作符的话,那
会多写多少行代码啊?
>>> from operator import * # import all operators
>>> vec1 = [12, 24]
>>> vec2 = [2, 3, 4]
>>> opvec = (add, sub, mul, div) # using +, -, *, /
>>> for eachOp in opvec: # loop thru operators
... for i in vec1:
... for j in vec2:
... print '%s(%d, %d) = %d' % \
... (eachOp.__name__, i, j, eachOp(i, j))
...
add(12, 2) = 14
add(12, 3) = 15
add(12, 4) = 16
add(24, 2) = 26
add(24, 3) = 27
add(24, 4) = 28
sub(12, 2) = 10
sub(12, 3) = 9
sub(12, 4) = 8
sub(24, 2) = 22
sub(24, 3) = 21
sub(24, 4) = 20
mul(12, 2) = 24
mul(12, 3) = 36
mul(12, 4) = 48
mul(24, 2) = 48
mul(24, 3) = 72
mul(24, 4) = 96
div(12, 2) = 6
div(12, 3) = 4
Edit By Vheavens
Edit By Vheavens
div(12, 4) = 3
div(24, 2) = 12
div(24, 3) = 8
div(24, 4) = 6
上面这段代码定义了三个向量,前两个包含着操作数,最后一个代表程序员打算对两个操作数
进行的一系列操作。最外层循环遍历每个操作运算,而最内层的两个循环用每个操作数向量中的元
素组成各种可能的有序数据对。最后,print 语句打印出将当前操作符应用在给定参数上所得的运算
结果。
我们前面介绍过的模块都列在表13.5 中
表13.5 与类相关的模块
模块 说明
UserList 提供一个列表对象的封装类
UserDict 提供一个字典对象的封装类
UserString a 提供一个字符串对象的封装类;它又包括一个MutableString 子类,如果有需
要,可以提供有关功能
types 定义所有Python 对象的类型在标准Python 解释器中的名字
operator 标准操作符的函数接口
a. 新出现于Python 1.6 版本
在Python FAQ 中,有许多与类和面向对象编程有关的问题。它对Python 类库以及语言参kao手
册都是很好的补充材料。关于新风格的类,请参kaoPEPs252 和253 和Python2.2 以后的相关文档。















 2129
2129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









