






前言
1:决策树原理理解
决策树(decision tree)是一个树结构(可以是二叉树或非二叉树)。
其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。
使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
总结来说:
决策树模型核心是下面几部分:
- 结点和有向边组成
- 结点有内部结点和叶结点俩种类型
- 内部结点表示一个特征,叶节点表示一个类
2:决策实例
假如我现在告诉你,我买了一个西瓜,它的特点是纹理是清晰,根蒂是硬挺的瓜,你来给我判断一下是好瓜还是坏瓜,恰好,你构建了一颗决策树,告诉他,没问题,我马上告诉你是好瓜,还是坏瓜?
判断步骤如下:
根据纹理特征,已知是清晰,那么走下面这条路,红色标记:
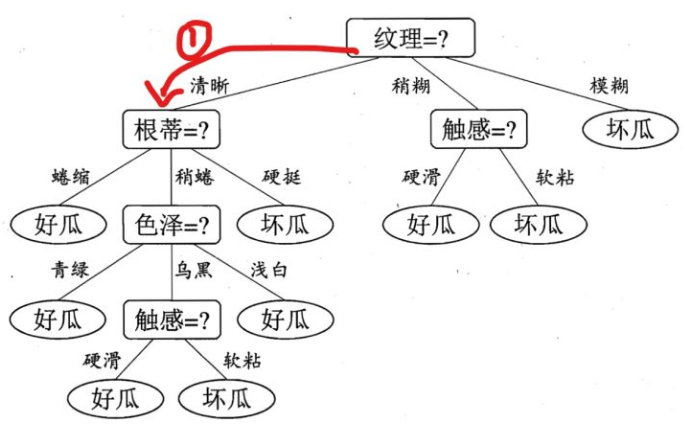
好的,现在咋们到了第二层了,这个时候,由决策树图,我们看到,我们需要知道根蒂的特征是什么了?很好,他也告诉我了,是硬挺,于是,我们继续走,如下面蓝色所示:
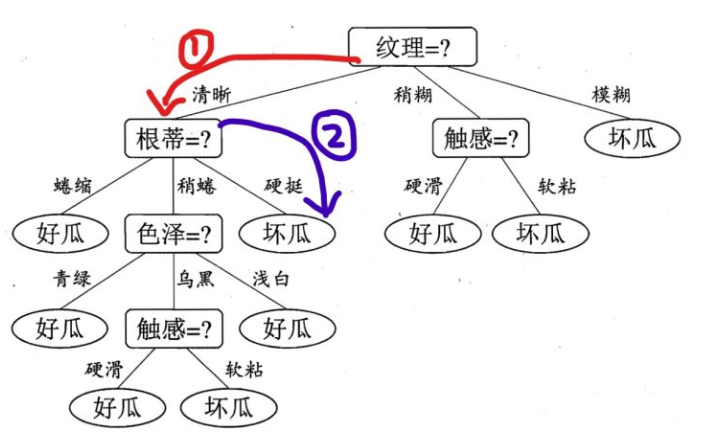
此时,我们到达叶子结点了,根据上面总结的点,可知,叶子结点代表一种类别,我们从如上决策树中,可以知道,这是一个坏瓜!
1:决策时代码使用


总结:将给的训练集特征分层特征后,进行训练后构建决策树,输入需要预测的特征数据,得出觉得分类















 1218
1218

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









