



 本文介绍了流程图的重要性和规范化,强调了流程图在项目沟通中的作用。文章详细阐述了流程图的统一形状、命名规则、操作描述、起点与终点设定、流程线方向等规范,并列举了几款常用的流程图制作工具。同时,讲解了流程图的顺序结构、选择结构和循环结构,通过实例展示了这些结构在流程图中的应用。最后,提供了一个订单支付流程的流程图样例。
本文介绍了流程图的重要性和规范化,强调了流程图在项目沟通中的作用。文章详细阐述了流程图的统一形状、命名规则、操作描述、起点与终点设定、流程线方向等规范,并列举了几款常用的流程图制作工具。同时,讲解了流程图的顺序结构、选择结构和循环结构,通过实例展示了这些结构在流程图中的应用。最后,提供了一个订单支付流程的流程图样例。
一开始,小编对于流程图可以说也是一脸懵逼的。但是呢对于不了解的东西总是有一种执念想要去“追究到底”的,从搜索流程这个词开始了解它的标准意思。再进一步去搜索不少流程图,就觉得其实还是很有意思的,把自己脑海里的一个过程通过制作流程图展现出来。那种自己的思路瞬间清晰表达出来的感觉简直妙极了。其实小编也发现别人流程图的画法和规范等都不太一样,处于好奇也查阅过一些资料,发现其实流程图是有那么一套明确并且通用的规范。下面,小编根据我学习得到的关于流程图的知识,整理出这篇文章,分享给大家。
一、前言
1、规范化流程图的意义: 流程图可以简单地描述一个过程,是对过程、算法、流程的一种图像表示。规范的流程图帮助项目组成员统一认识,便于项目的沟通和讨论,有助于项目的顺利推进。
2、目前一个项目的流程图是为了技术人员开发和自测时与测试人员测试时更好的理解项目。
3、画流程图工具:
二、规范
1、流程图形状统一。流程图是由点和线组成的面。要画出规范的路程图,最基本的就是流程图的形状要统一。
http://processon.com/ (在线制作流程图)
Xmind (涵盖pcMacIOS安卓)
亿图 (国产不错的流程图软件)
Microsoft Visio (微软老牌制作流程图软件)
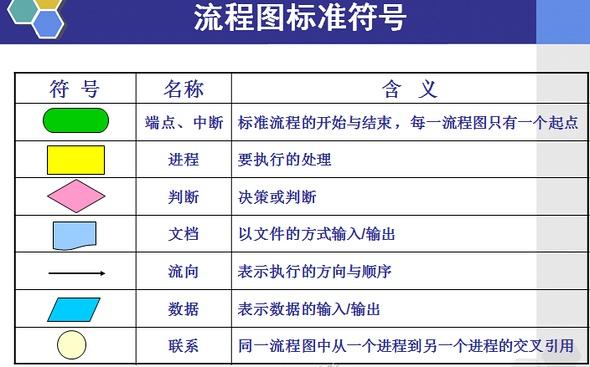
2、流程图的命名要使用主谓结构,如“设备购买流程”。
3、操作描述用动宾结构,语言要简洁清晰,如“编制招聘计划”。
4、起点必须有且只有一个,而终点可以省略不画或有多个。
5、流程图的形状大小一致,统一字号。
6、流程线是从下往上或从右向左时,必须带箭头;除此以外,都可以不画箭头;流程线的走向默认都是从上向下或从左向右。
7、判断框和选择框上下端连接“yes”线,左右端“no”流入流出。
8、流程图从左到右、从上至下排列。
9、流程处理关系为并行关系的,需要将流程放在同一高度。
10、连接线不要交叉。
三、流程图的三大结构
流程图由三大结构构成,这三大结构分别为顺序结构、选择结构和循环结构,这三个结构构成了流程执行的全过程。
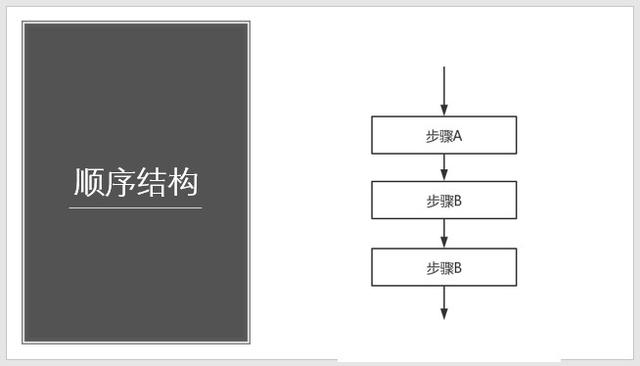
(一)、顺序结构
1、在顺序结构中,各个步骤是按先后顺序执行的,这是一种最简单的基本结构。如图,A、B、C是三个连续的步骤,它们是按顺序执行的,即完成上一个框中指定的操作才能再执行下一个动作。
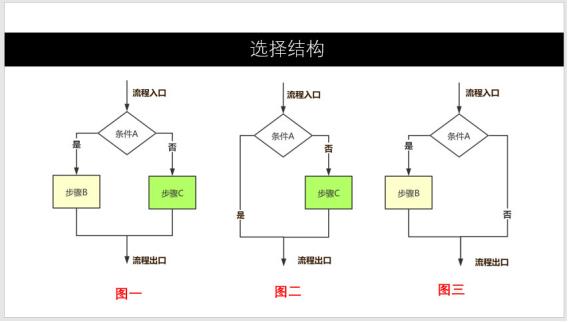
(二)、选择结构
1、选择结构又称分支结构,选择结构用于判断给定的条件,根据判断的结果判断某些条件,根据判断的结果来控制程序的流程。在实际运用中,某一判定结果可以为空操作(如图二、图三)。
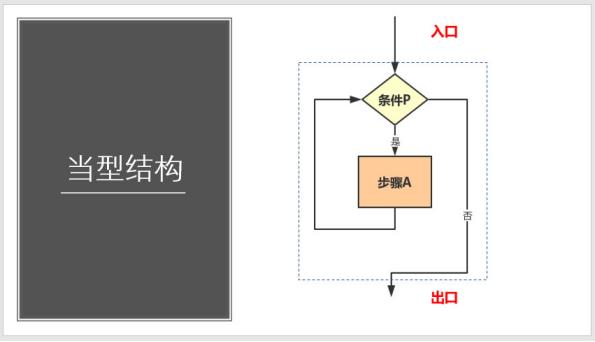
1、循环结构又称为重复结构,就是流程在一定的条件下,反复执行某一操作的流程结构。循环结构下又可以分为当型结构和直到型结构。
2、循环结构可以看成是一个条件判断条件和一个向回转向条件的组合,循环结构的包括三个要素:循环变量、循环体和循环终止条件。在流程图的表示中,判断框内写上条件,两个出口分别对应着条件成立和条件不成立时所执行的不同指令,其中一个要指向循环体,然后再从循环体回到判断框的入口处。
3、当型结构:先判断所给条件p是否成立,若P成立,则执行A(步骤);再判断条件p是否成立;若P成立,则又执行A,若此反复,直到某一次条件p不成立时为止
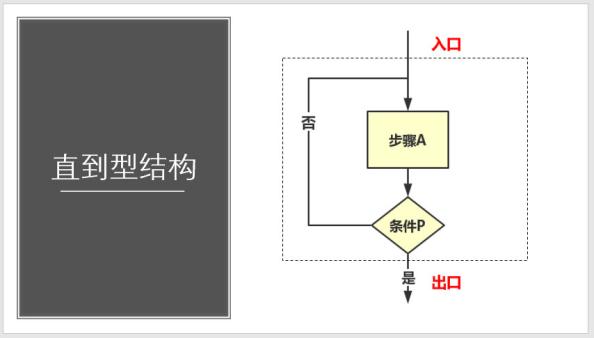
4、直到型结构:先执行A,再判断所给条件P是否成立,若p不成立,则再执行A,如此反复,直到P成立,该循环过程结束
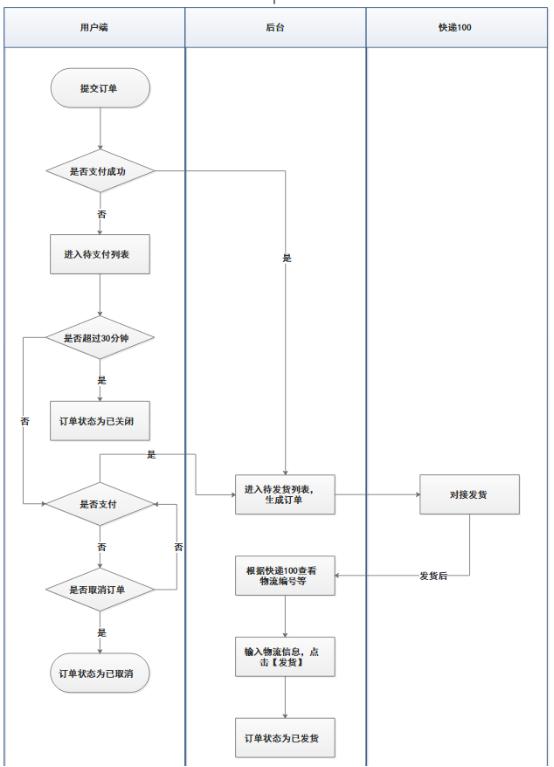
四、样例
话不多说,来一张图片消化消化。如下图描述的是一个订单从待支付变为已支付一直到待发货的流程
以上就是小编总结出来流程图的规范以及结构,可能不是很全面也不是很专业,仅代表个人观点。求广大网友们来交换一下个人的观念和看法。


















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









