






0 前言
本文主要讲述以下几点:
1.通过scikit-learn计算文本内容的tfidf并构造N*M矩阵(N个文档 M个特征词);
2.调用scikit-learn中的K-means进行文本聚类;
3.使用PAC进行降维处理,每行文本表示成两维数据;
4.最后调用Matplotlib显示聚类效果图。
文章更详细的内容参考:http://blog.csdn.net/eastmount/article/details/50473675
由于涉及到了我的毕业设计,一些更深入的内容和详细的信息,我这里就不再详细叙述了,毕竟还要查重和未发表。但其中一些算法的实现步骤是很清晰的。
最后希望文章对你有所帮助,尤其是那些正在学习文本相似度计算或文本聚类的初学者。
1 输入
文本输入是读取本地的01_All_BHSpider_Content_Result.txt文件,里面包括1000行数据,其中001~400行为景区、401~600为动物、601~800为人物明星、801~1000为国家地理文本内容(百度百科摘要信息)。
该内容可以自定义爬虫进行爬取,同时分词采用Jieba进行。
免费下载包括代码py文件和01_All_BHSpider_Content_Result.txt。
下载地址:http://download.csdn.net/detail/eastmount/9410810
2 源代码
代码如下,详见注释和后面的学习笔记推荐:
# coding=utf-8
"""
Created on 2016-01-16 @author: Eastmount
输入:打开 All_BHSpider_Result.txt 对应1000个文本
001~400 5A景区 401~600 动物 601~800 人物 801~1000 国家
输出:BHTfidf_Result.txt tfidf值 聚类图形 1000个类标
参数:weight权重 这是一个重要参数
"""
import time
import re
import os
import sys
import codecs
import shutil
import numpy as np
import matplotlib
import scipy
import matplotlib.pyplot as plt
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import HashingVectorizer
if __name__ == "__main__":
#########################################################################
# 第一步 计算TFIDF
#文档预料 空格连接
corpus = []
#读取预料 一行预料为一个文档
for line in open('01_All_BHSpider_Content_Result.txt', 'r').readlines():
#print line
corpus.append(line.strip())
#print corpus
#参考: http://blog.csdn.net/abcjennifer/article/details/23615947
#vectorizer = HashingVectorizer(n_features = 4000)
#将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer()
#该类会统计每个词语的tf-idf权值
transformer = TfidfTransformer()
#第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵
tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus))
#获取词袋模型中的所有词语
word = vectorizer.get_feature_names()
#将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重
weight = tfidf.toarray()
#打印特征向量文本内容
print 'Features length: ' + str(len(word))
resName = "BHTfidf_Result.txt"
result = codecs.open(resName, 'w', 'utf-8')
for j in range(len(word)):
result.write(word[j] + ' ')
result.write('\r\n\r\n')
#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for i in range(len(weight)):
#print u"-------这里输出第", i, u"类文本的词语tf-idf权重------"
for j in range(len(word)):
#print weight[i][j],
result.write(str(weight[i][j]) + ' ')
result.write('\r\n\r\n')
result.close()
########################################################################
# 第二步 聚类Kmeans
print 'Start Kmeans:'
from sklearn.cluster import KMeans
clf = KMeans(n_clusters=4) #景区 动物 人物 国家
s = clf.fit(weight)
print s
'''
print 'Start MiniBatchKmeans:'
from sklearn.cluster import MiniBatchKMeans
clf = MiniBatchKMeans(n_clusters=20)
s = clf.fit(weight)
print s
'''
#中心点
print(clf.cluster_centers_)
#每个样本所属的簇
label = [] #存储1000个类标 4个类
print(clf.labels_)
i = 1
while i <= len(clf.labels_):
print i, clf.labels_[i-1]
label.append(clf.labels_[i-1])
i = i + 1
#用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数 958.137281791
print(clf.inertia_)
########################################################################
# 第三步 图形输出 降维
from sklearn.decomposition import PCA
pca = PCA(n_components=2) #输出两维
newData = pca.fit_transform(weight) #载入N维
print newData
#5A景区
x1 = []
y1 = []
i=0
while i<400:
x1.append(newData[i][0])
y1.append(newData[i][1])
i += 1
#动物
x2 = []
y2 = []
i = 400
while i<600:
x2.append(newData[i][0])
y2.append(newData[i][1])
i += 1
#人物
x3 = []
y3 = []
i = 600
while i<800:
x3.append(newData[i][0])
y3.append(newData[i][1])
i += 1
#国家
x4 = []
y4 = []
i = 800
while i<1000:
x4.append(newData[i][0])
y4.append(newData[i][1])
i += 1
#四种颜色 红 绿 蓝 黑
plt.plot(x1, y1, 'or')
plt.plot(x2, y2, 'og')
plt.plot(x3, y3, 'ob')
plt.plot(x4, y4, 'ok')
plt.show()
3 输出结果
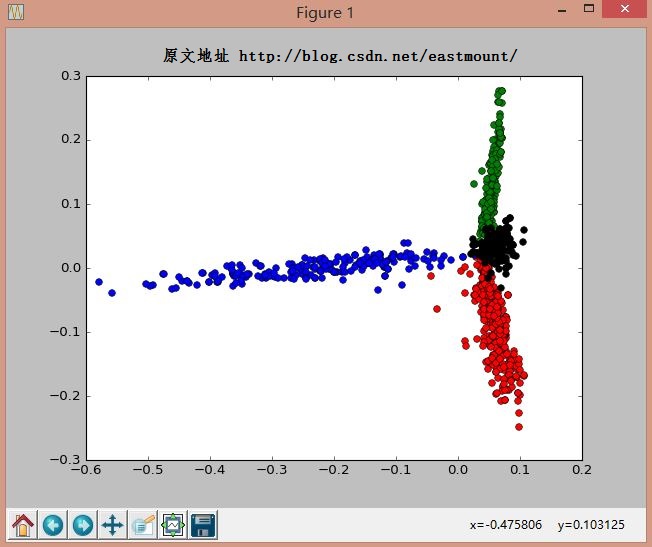
采用Kmeans中设置类簇数为4,分别表示景区、动物、明星和国家。
其中运行结果如下图所示,包括17900维tfidf特征向量:

聚类输出结果如下图所示:其中"红-景区 绿-动物 蓝-人物 黑-国家"。由于数据集比较小,文本聚类效果还是很明显的,而LDA算法是计算每个主题分布的算法,推荐你也去学习下。
4 性能评估
这里我想结合文本聚类简单叙述下最常用的评估方法:
正确率 Precision = 正确识别的个体总数 / 识别出的个体总数
召回率 Recall = 正确识别的个体总数 / 测试集中存在的个体总数
F值 F-measure = 正确率 * 召回率 * 2 / (正确率 + 召回率)
由于"clf.labels_"会返回聚类每个样本所属的簇,比如1000行数据,就会返回1000个label值。同时,clf = KMeans(n_clusters=4)设置了类簇为4,故每个值对应在0、1、2、3中的一个,统计结果如下:

其中以世界国家为例,label1数目为198,同时识别出的个体数=198(世界国家)+2(动物)=200,故:
准确率=198/200=0.990
其中动物里面有两个聚类到了世界国家中。而召回率我以人物明星为例,因为知道测试集中601~800这200个数据对应人物明星,故测试集中存在个体数为200,而正确识别数目为185个,故:
召回率=185/200=0.925
最后计算F值即可。同时可以计算宏平均聚类准确率(Macro-Prec)和宏平均召回率(Macro-Rec)。
5 总结及推荐学习资料
(1) 使用HashingVectorizer(n_features = n)设置维数,如何选择更合理的特征;
(2) 调用plt.legend([plot1, plot2, plot3, plot4], (u'景区', u'动物', u'明星', u'国家') )
报错"AttributeError: 'NoneType' object has no attribute 'tk'";
(3) sklearn其它聚类算法以及设置聚类中心点。
但是对那些刚接触Python聚类算法的同学 ,这篇文章还是有一定帮助的!同时也是我自己的在线笔记,仅仅提供了一条基础介绍,希望你能从这篇文章入门,从而实现你自己做的东西。最近总是深夜编码,生活太忙太充实,写篇博客放松下心情也不错~
最后推荐一些相关资料:
用Python开始机器学习(10:聚类算法之K均值) -lsldd大神
应用scikit-learn做文本分类(特征提取 KNN SVM 聚类) - Rachel-Zhang大神
Scikit Learn: 在python中机器学习(KNN SVMs K均) - yyliu大神 开源中国
【机器学习实验】scikit-learn的主要模块和基本使用 - JasonDing大神
Scikit-learn学习笔记 中文简介(P30-Cluster) - 百度文库
使用sklearn做kmeans聚类分析 - xiaolitnt
使用sklearn + jieba中文分词构建文本分类器 - MANYU GOU大神
sklearn学习(1) 数据集(官方数据集使用) - yuanyu5237大神
scikit-learn使用笔记与sign prediction简单小结 - xupeizhi
http://scikit-learn.org/stable/modules/clustering.html#clustering
基于K-Means的文本聚类(强推基础介绍) - freesum
Python图表绘制:matplotlib绘图库入门 - 360图书
Stanford机器学习---第十讲. 数据降维 - Rachel-Zhang大神
聚类算法初探(七)聚类分析的效果评测 - 皮果提大神
python使用matplotlib绘图 -- barChart
Python-Matplotlib安装及简单使用 (绘制柱状图)
scikit-learn中PCA的使用方法 - wphh (推荐阅读)
使用 PCA 进行降维处理——基于 sklearn 库 - Guo'Blog
(By:Eastmount 2016-01-20 深夜5点 http://blog.csdn.net//eastmount/ )















 4004
4004











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









