







缓冲区引言
缓冲区在计算机世界中随处可见,内存中的多级缓冲区,io设备的缓冲区等等,还有我们经常用的内存队列,分布式队列等等。我们假设生产者和消费者的能力在某些时候不一致,则可能会发生两种问题,问题一、生产者的速度大于消费着速度,则生产者的消息都推送给消费者,它会消费不过来,要么消息会丢失,要么会导致消费者过载而导致服务故障;或者另外一种情况,消费者的处理能力非常强,远大于生产者的生产速度,那么如果消费者处于阻塞等待状态就会浪费资源,有了缓冲区之后则可以在缓冲区积压到一定量后再通知消费者来消费。所以有了缓冲区后,它可以平衡了两者能力差异带来的影响,也降低了生产者和消费者的耦合,可以解决上面提到的两个问题。
JDK的bio和nio
那么我们的网络IO中也存在同样的问题,网络通道通过网络传输消息的速度远远慢于CPU的处理速度,尤其是在网络速度不稳定的互联网环境下更为突出。我们知道JDK提供的BIO是通过输入输出流来读写消息的,而如果输入流中的数据没有准备好的情况下,我们线程就会阻塞在这里,等待输入流传输数据,而宝贵的线程资源就会浪费在这里;
后来JDK为了解决这个问题又提供了ByteBuffer来解决这个问题,通过缓冲区来平衡网络io和CPU之间的速度差异,等待缓冲区积累到一定量的数据再统一交给CPU去处理,从而提升了CPU的资源利用率。
netty的改进
我们知道netty是一个网络框架,它抽象出了一个网络操作的通用框架,不将底层的实现api暴露给使用者,因此我们可以根据需要在统一的API情况下根据使用场景自由切换不同的底层io实现,例如可以切换jdk的bio,nio,tcp和udp之间切换等等。
因此对于缓冲区,netty也抽象了一个自己的ByteBuf,相对于jdk的nio提供的ByteBuffer,它做了更多的改进。
- ?如果需要,你可以定义你自己的buffer实现类。
- 包装jdk自带的直接内存buffer类实现了透明的“零”拷贝? 。无须将系统态的数据拷贝到用户态,提升了性能。
- 容量可以按需扩展。这个特性也非常诱人。
- api更加友好,无须调用flip()切换读写模式。可同时进行读写。
- 将读写索引分开。
- 链式方法调用,api编码更简洁。
- 引用计数算法。
- 池化缓冲区,可以复用缓冲区,从而提升性能。
- 抽象出统一的字节缓冲区API,无须与具体的实现耦合。
总结起来说netty的ByteBuf和jdk的ByteBuffer都是byte字节的缓冲区,ByteBuf包含了ByteBuffer的所有功能,但是它对ByteBuffer又进行了增强,主要改进点包括:API更加简洁,性能更好,特性更丰富。
ByteBuf的原理
我们知道ByteBuf实际上就是一个字节数组,然后有两个下标,一个是写索引writerIndex,一个是读索引readerIndex,两个索引值初始化都是从0,当向ByteBuf中写入数据后,则索引下表也会增加对应的字节数,而writerIndex值也是我们读操作的上限值,readerIndex可以从0-writerIndex之间移动。
ByteBuf还有一个最大容量限制maxCapacity,若没有指定值,则它的默认值是Integer.MAX_VALUE即最允许的int类型值,设置该值的原因就是因为writerIndex是int类型的。还有一个初始化的容量值initialCapacity,该值用于控制初始化的byte数组的长度,会创建一个长度为该值的字节数组。

接下来我们动手来编写和调试代码一起看看ByteBuf内部是如何运作的。
我们写了一段简单的代码来调试它内部发生的变化。
public static void main(String[] args) throws InterruptedException {
//无参数的工厂方法,还可以,调用buffer(int initialCapacity, int maxCapacity) 来指定初始化和最大容量限制。
ByteBuf byteBuf = UnpooledByteBufAllocator.DEFAULT.buffer();//1
//写入一个byte。
byteBuf.writeByte(3);//2
//读取一个字节。
System.out.println("get value "+(byteBuf.readByte())+" from buffer");//3
try {
//再读取一个字节,超过了读取限制,则抛出异常。
System.out.println("get value " + (byteBuf.readByte()) + " from buffer");//4
}catch (Exception e){
e.printStackTrace();
}
//清空,索引值均恢复0.
byteBuf.clear(); //5
//循环写入257个字节,超过了默认初始化容量256的限制,则会触发扩容操作。
for (int i=0; i<257; i++){
byteBuf.writeByte(3);
}
System.out.println("done.");//6
我们通过单步调试看看byteBuf对象内部的属性变化。
1.创建使用无池化能力的UnpooledByteBufAllocator类分配一个默认的ByteBuffer对象。
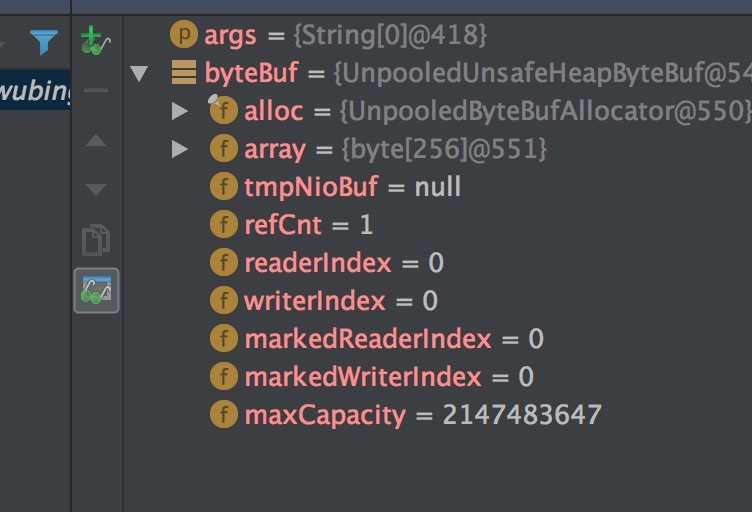
通过工厂方法创建一个ByteBuf对象,该对象的属性都处于初始化状态。
array:字节数组,使用默认的初始化容量设置256,创建一个长度是256的直接数组,所有元素的值当前都是0.
readerIndex:0,读取数据下标初始化值。当前可以读的值时从readerIndex 0 (包含)- writerIndex 0(不包含) 之间的值,中间没有可读的字节。
writerIndex:0,读取数据下标初始化值。
maxCapactiry:2147483647,是默认的最大容量限制值,该值即为int类型最大的正整数值。
refCnt:引用计数器值,涉及到引用计数的内容我们要专题讲解。
2.写入一个字节。

writerIndex的值发生了变化,从0表为1,表示写入一个字节的内容到直接数组0下标的位置上。
readerIndex的值依旧是0,未变化,则从 0 -1 之间可以读的内容是下标为0 的内容。
array字节数组的内容可以看到下标为 0 的位置上值从0 变为3.
3.读取一个字节。
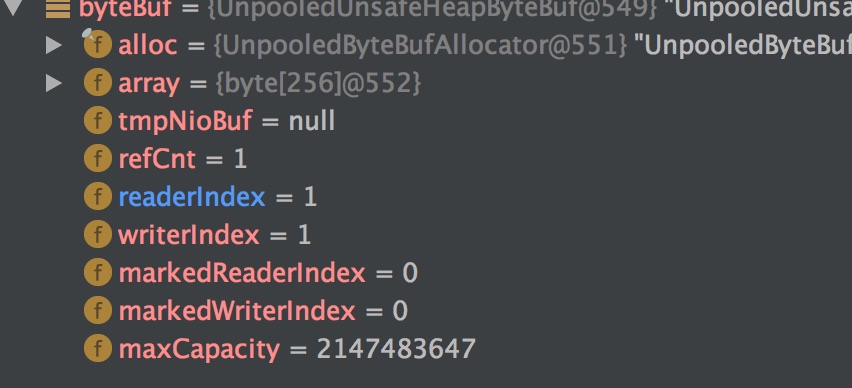
控制台输出:“get value 3 from buffer”
readerIndex的值也变为1,此时writerIndex的值也为1,当前状态下也没有可以继续读取的直接内容了。
4.超出限制再次读取字节。
由于中间无可读取的直接,则最后抛出异常,信息:
java.lang.IndexOutOfBoundsException: readerIndex(1) + length(1) exceeds writerIndex(1): UnpooledUnsafeHeapByteBuf(ridx: 1, widx: 1, cap: 256)
at io.netty.buffer.AbstractByteBuf.checkReadableBytes0(AbstractByteBuf.java:1389)
at io.netty.buffer.AbstractByteBuf.readByte(AbstractByteBuf.java:687)
at com.yangwubing.ByteBufTest.main(ByteBufTest.java:27)5.清空ByteBuff

下标值readerIndex,writerIndex的值都恢复为0了。
直接数组array中的内容并没有发生变化,直接写入的直接3还在直接数组中。
6.写入超过初始化容量的字节数。

通过写入257个字节,超过了初始化容量256,则促发了直接数组的扩容操作。
array字节数组扩容后变为了512,它扩容的容量和初始化容量一致,也是扩容了256个字节。
扩容的时候会影响性能,尤其是数据量较大的清空下,需要生成一个新的数组,并将之前的数组内容拷贝到新直接数组上。应该尽可能避免扩容。
源码分析
类图
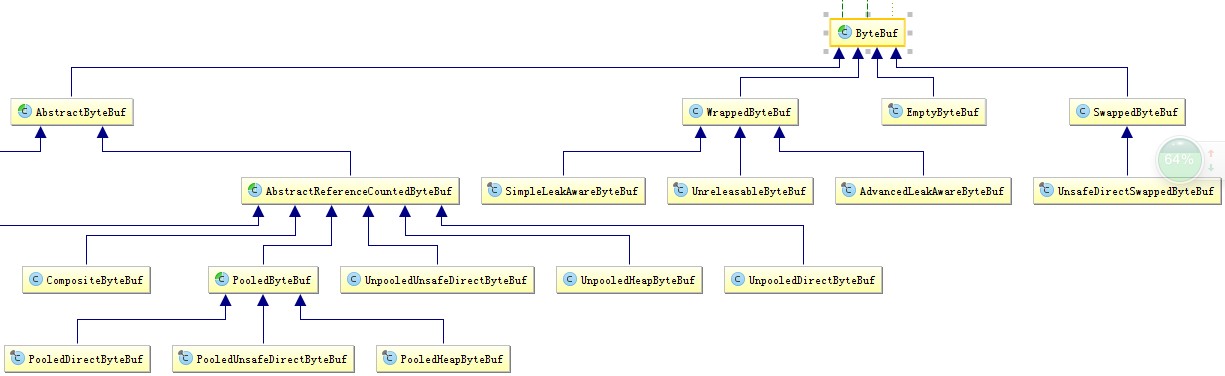
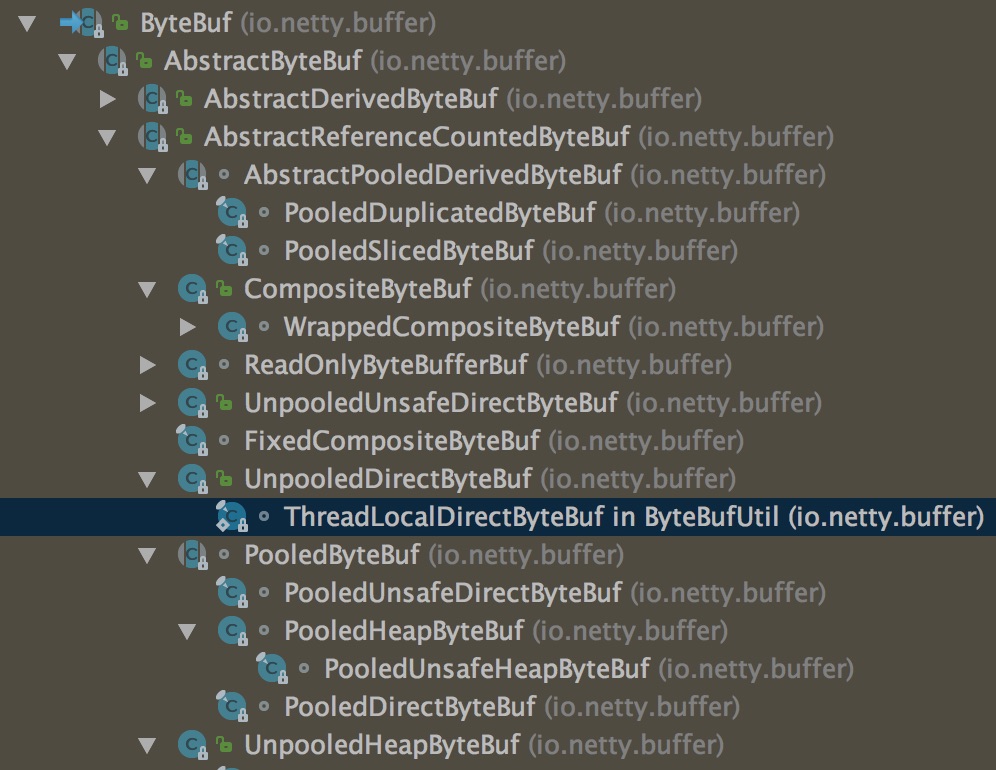
ByteBuf的类继承体系也相当庞大,我们抓住关键点,本文将重点沿着以下类继承关系来分析源码。
ByteBuf -> AbstractByteBuf -> AbstractReferenceCountedByteBuf -> UnpooledHeapByteBuf。这个类也是我们上面例子中用到的哪个实现类,该实现类是基于jvm堆的数组来实现ByteBuf,是一种比较常见的实现类。
由于我对于更加高性能的直接内存实现类UnpooledDirectByteBuf感兴趣,因此也分析一下该类的源码。
ByteBuf
字节缓冲区,本文研究的重点,在上面章节我们已经介绍了该接口以及它提供的一些常用方法。
它也继承了一些别的接口。
public abstract class ByteBuf implements ReferenceCounted, Comparable<ByteBuf> {}
继承了ReferenceCounted接口,该接口是引用计数接口,实现了引用计数的算法,该算法主要是标记一个字节缓冲区是否有被引用,如果计数为0则表示无使用,那么就可以回收到。该接口主要有下面这几个核心方法。
int refCnt();//当前被引用次数。
eferenceCounted retain(int increment);//增加引用次数值。
boolean release(int decrement);//减少引用次数值。由于ByteBuf也继承了该接口,则在它后续的实现类中就需要实现这些接口。
另外它还是实现了Comparable接口,该接口就一个方法compareTo,就是将两个ByteBuf进行比较,比较两个ByteBuf的大小。
ByteBuf就是提供了一系列的read和write方法,除了可以读写字节之外,还提供了一些列读写各种基本类型值的方法,包括short,int,long,float,double和String等。
AbstractByteBuf
AbstractByteBuf是ByteBuf的一个顶级抽闲实现类,它抽取了通用的属性和方法作为其它实现类的模版。
先看看该类中定义的一些关键属性。
int readerIndex; //当前读下标值。
int writerIndex; //当前写下标值。
private int markedReaderIndex;//标记的读下标值。
private int markedWriterIndex;//标记的写下标值。
private int maxCapacity;//字节缓冲区最大允许容量值。
这几个属性我们非常熟悉,上节内容中演示的案例我们就查看了这几个属性值。
该类中的实现方法都是围绕上述属性来实现的一些通用方法或者模版方法。
我们来看看几个重要的方法实现。
readByte
该方法是从ByteBuf中读取一个字节。
//读取一个字节的内容。
public byte readByte() {
checkReadableBytes0(1);//检查是否可以读取1个字节。
int i = readerIndex;//
byte b = _getByte(i);//获得readerIndex下标所指示的字节内容,抽象方法,留给子类实现。
readerIndex = i + 1;//readerIndex往后移一个。
return b;//返回自己内容。
}
//检查当前情况是否可以读取minimumReadableBytes个字节内容。
private void checkReadableBytes0(int minimumReadableBytes) {
ensureAccessible();//检查是否可以访问。
if (readerIndex > writerIndex - minimumReadableBytes) {//检查是否还可以读取minimumReadableBytes个字节内容。
throw new IndexOutOfBoundsException(String.format(//抛出异常。
"readerIndex(%d) + length(%d) exceeds writerIndex(%d): %s",
readerIndex, minimumReadableBytes, writerIndex, this));
}
}
protected final void ensureAccessible() {//确保ByteBuf是可以访问的。
if (checkAccessible && refCnt() == 0) {//系统变量io.netty.buffer.bytebuf.checkAccessible不允许访问或者引用计数为0.则抛出异常。
throw new IllegalReferenceCountException(0);
}
}上述代码演示了readByte模版方法的实现,它实现了该方法的骨干,但是将_getByte方法留给子类去实现。
该方法现实检查是否可以读取一个字节,如果设置了不允许访问或者引用计数不为0,则会抛出异常。
我们注意到readByte方法线程是不安全的,当被多线程读取的情况下,readIndex值可能不安全。
writeByte
该方法是写入一个字节到ByteBuf中。
public ByteBuf writeByte(int value) {
ensureAccessible();//检查是否可访问,已介绍。
ensureWritable0(1);//检查是否可以写入一个字节
_setByte(writerIndex++, value);//设置一个字节的内容,也是个抽象方法,待子类实现。
return this;//返回自己,链式编程风格。
}
//检查是否可以写一个字节内容。
private void ensureWritable0(int minWritableBytes) {
if (minWritableBytes <= writableBytes()) {//当前容量可以写入,则直接返回表示可写入。
return;
}
if (minWritableBytes > maxCapacity - writerIndex) {//写入字节数超出最大容量范围,则抛出异常。
throw new IndexOutOfBoundsException(String.format(
"writerIndex(%d) + minWritableBytes(%d) exceeds maxCapacity(%d): %s",
writerIndex, minWritableBytes, maxCapacity, this));
}
// Normalize the current capacity to the power of 2.
int newCapacity = alloc().calculateNewCapacity(writerIndex + minWritableBytes, maxCapacity);//计算出新扩展的容量数,扩展以2的倍数进扩容。
// Adjust to the new capacity.
capacity(newCapacity);//扩展新的容量。
}
public int writableBytes() {
return capacity() - writerIndex;//当前容量可允许写入的字节数。
}
写入一个自己的方法流程是先检查是否可访问,再检查容量是否充足,如果超过了最大容量限制则会抛出异常,不允许写入。
如果没有超出容量限制则可以写入,如果超出当前容量限制,则会自动进行扩容。扩容的过程中也会阻塞当前线程。
我们可以看出来writeByte方法也是一个线程不安全的方法,写入的字节内容和下标的值可能存在不一致的情况。
AbstractReferenceCountedByteBuf
抽象的引用计数ByteBuf实现类,从类名上来看,这个类主要是实现了接口ReferenceCounted的一些方法,我们看看它增强的一些关键属性和方法。
关键属性。
private volatile int refCnt = 1;该属性我们在调试的时候看到过,它就是当前的ByteBuf被引用的次数。初始值是1,一个ByteBuf被实例化的时候就会有一次引用。而且该属性还使用了volatile关键字进行了修饰,来保证多线程环境下线程栈中的缓存值和堆内存中的值保持一致。
关键方法
public int refCnt() {//获得当前的引用计数值。
return refCnt;
}
public ByteBuf retain() {//增加一次引用。
return retain0(1);
}
private ByteBuf retain0(int increment) {//增加increment次引用。
for (;;) {//循环。
int refCnt = this.refCnt;
final int nextCnt = refCnt + increment;//引用计数加1.
// Ensure we not resurrect (which means the refCnt was 0) and also that we encountered an overflow.
if (nextCnt <= increment) {
throw new IllegalReferenceCountException(refCnt, increment);
}
if (refCntUpdater.compareAndSet(this, refCnt, nextCnt)) {//通过CAS来更新数据。
break;//更新成功后退出循环。
}
}
return this;
}
refCnt()方法在上面判断是否可访问的时候用到过,如果引用计数值为0,则表示该ByteBuf是不可访问的,是可以被gc清除的,里面存储的值也是不可靠的。
retain方法是增加一次引用的方法。retain0方法才是真正的实现,使用CAS加循环的乐观锁来实现线程安全的更新refCnt的值。由于该方法非常轻,竞争也不会特别积累,因此使用了一个无限次的for循环来等待更新成功为止。而refCnt使用了volatile关键字修饰可以保证多线程环境下读取到的值是最新的。使用CAS来避免使用synchorized锁。
public boolean release() {//释放一次引用计数。
return release0(1);
}
private boolean release0(int decrement) {//释放decrement次引用计数。
for (;;) {
int refCnt = this.refCnt;
if (refCnt < decrement) {
throw new IllegalReferenceCountException(refCnt, -decrement);
}
if (refCntUpdater.compareAndSet(this, refCnt, refCnt - decrement)) {//使用CAS来更新引用计数。
if (refCnt == decrement) {//如果释放的次数等于引用计数,则表示计数全部释放完毕,引用计数更新为0.
deallocate();//重新分配空间。
return true;//全部释放。
}
return false;//释放部分。
}
}
}release方法是释放引用计数,release()方法是释放一次,release0是释放指定次数的引用计数。同样也使用了CAS乐观锁的计数来实现线程安全的更新。
区别是如果引用计数重新恢复为0则表示ByteBuf无引用,则可以被释放了,所以调用一次dealloate方法来重新分配空间,可以释放它占用的空间给其它ByteBuf使用。
UnpooledHeapByteBuf
这个类是使用jvm堆来实现的无对象池的ByteBuf实现类。
关键属性:
private final ByteBufAllocator alloc;//分配器,之前的方法中用到了它来计算扩容策略。
byte[] array;//字节数组,存放字节内容。
private ByteBuffer tmpNioBuf;//临时对象。array数组就是我们上面调试看到的哪个字节数组,字节缓冲区的内容都是存储在这里面。
构造方法
private UnpooledHeapByteBuf(
ByteBufAllocator alloc, byte[] initialArray, int readerIndex, int writerIndex, int maxCapacity) {
super(maxCapacity);
if (alloc == null) {//不能为null
throw new NullPointerException("alloc");
}
if (initialArray == null) {//初始化数组不能空。
throw new NullPointerException("initialArray");
}
if (initialArray.length > maxCapacity) {//不能超过最大容量限制。
throw new IllegalArgumentException(String.format(
"initialCapacity(%d) > maxCapacity(%d)", initialArray.length, maxCapacity));
}
this.alloc = alloc;
setArray(initialArray);//设置字节数组。
setIndex(readerIndex, writerIndex);//设置索引值。
}
private void setArray(byte[] initialArray) {
array = initialArray;//初始化数组赋值给array。
tmpNioBuf = null;
}
public ByteBuf setIndex(int readerIndex, int writerIndex) {
if (readerIndex < 0 || readerIndex > writerIndex || writerIndex > capacity()) {
throw new IndexOutOfBoundsException(String.format(
"readerIndex: %d, writerIndex: %d (expected: 0 <= readerIndex <= writerIndex <= capacity(%d))",
readerIndex, writerIndex, capacity()));
}//检查索引值的合法行。
setIndex0(readerIndex, writerIndex);//设置索引值。
return this;
}
final void setIndex0(int readerIndex, int writerIndex) {
this.readerIndex = readerIndex;
this.writerIndex = writerIndex;
}构造函数是受保护的和私有的方法,一般是通过工厂方法来创建该对象。
该方法就是对几个关键属性信息的初始化和配置。
readByte方法
抽象类AbstractByteBuf的readByte方法最终调用子类的_getBytes来获得字节内容,而这个方法的实现如下。
protected byte _getByte(int index) {
return HeapByteBufUtil.getByte(array, index);//获取字节内容,调用下面那个方法。
}
static byte getByte(byte[] memory, int index) {
return memory[index];//直接返回数组下标值的内容。
}writeByte
抽象类AbstractByteBuf的writeByte方法最终调用子类的_setBytes来获得字节内容,而这个方法的实现如下。
protected void _setByte(int index, int value) {
HeapByteBufUtil.setByte(array, index, value);//直接设置index下标的值内容。
}
static void setByte(byte[] memory, int index, int value) {
memory[index] = (byte) value;//强制将int转为byte类型设置到数组中。
}该方法将value设置到字节数组对应的下标值上,而value是一个int类型,强制转换会丢失精度,这个地方看起来有些问题。
其它的方法无非都是对array数组的内容进行操作,相对比较简单,不一一进行分析。
UnpooledDirectByteBuf
该了是一个使用jdk的java.nio.ByteBuffer类实现的一个直接内存操作的ByteBuf实现类,该类也推荐使用Unpooled#directBuffer(int)和Unpooled#wrappedBuffer(ByteBuffer)方法创建对象,而不是直接调用它的构造函数。
关键属性
private final ByteBufAllocator alloc;//分配器。
private ByteBuffer buffer;//jdk自带的ByteBuffer实现类。
private ByteBuffer tmpNioBuf;
private int capacity;//当前容量。
private boolean doNotFree;//不释放直接内存缓冲区空间。属性buffer是一个jdk自带的ByteBuffer的对象,这和UnpooledHeapByteBuf使用字节数字来存储字节内容不同。本类中该对象是实现类DirectByteBuffer的对象,它是直接内存读写的字节缓冲,相对于堆内存缓冲区,它减少了一次内存复制。因此能够提高性能。但是由于该内存不是位于jvm堆中的,无法被gc自动回收。
构造函数
protected UnpooledDirectByteBuf(ByteBufAllocator alloc, int initialCapacity, int maxCapacity) {
super(maxCapacity);
if (alloc == null) {//alloc不能为空。
throw new NullPointerException("alloc");
}
if (initialCapacity < 0) {//初始化容量要大于0
throw new IllegalArgumentException("initialCapacity: " + initialCapacity);
}
if (maxCapacity < 0) {//最大容量要大于0
throw new IllegalArgumentException("maxCapacity: " + maxCapacity);
}
if (initialCapacity > maxCapacity) {//初始化容量要小于或等于最大容量
throw new IllegalArgumentException(String.format(
"initialCapacity(%d) > maxCapacity(%d)", initialCapacity, maxCapacity));
}
this.alloc = alloc;
setByteBuffer(ByteBuffer.allocateDirect(initialCapacity));//分配一个直接内存字节缓冲区。
}
private void setByteBuffer(ByteBuffer buffer) {//设置新的直接内存缓冲区。
ByteBuffer oldBuffer = this.buffer;//更新之前的
if (oldBuffer != null) {//如果之前有,则可能需要释放。
if (doNotFree) {//不释放旧空间。
doNotFree = false;
} else {
freeDirect(oldBuffer);//释放旧的直接内存缓冲区。
}
}
this.buffer = buffer;
tmpNioBuf = null;
capacity = buffer.remaining();//当前缓冲区容量大小。
}
protected void freeDirect(ByteBuffer buffer) {
PlatformDependent.freeDirectBuffer(buffer);
}
从上面的典型构造函数来看,它调用ByteBuffer.allocateDirect(initialCapacity)方法来获得一个初始化大小的jdk自带的直接内存直接缓冲区,是一个类型DirectByteBuffer的对象,所以它是利用jdk自带的直接内存缓冲区来实现netty的直接内存缓冲区。该类是有很多本地方法代码来实现的。由于直接内存不会自动被gc释放,所以当分配了新的缓冲区,则旧的直接内容缓冲区的内存就需要手动释放,否则会存在内存泄漏的风险,所以它调用了PlatformDependent.freeDirectBuffer(buffer)来释放不再使用的直接内存缓冲区。调用buffer.remaining()来得到当前容量值。
readByte方法
抽象类AbstractByteBuf的readByte方法最终调用子类的_getBytes来获得字节内容,而这个方法的实现如下。
protected byte _getByte(int index) {
return buffer.get(index);//直接冲ByteBuffer的get方法获取字节内容。
}writeByte
抽象类AbstractByteBuf的writeByte方法最终调用子类的_setBytes来获得字节内容,而这个方法的实现如下。
protected void _setByte(int index, int value) {
buffer.put(index, (byte) value);//put自己内容到指定下标值上。
}
所以其它的一些方法也基本上都是通过调用ByteBuffer 对应的方法来一一实现,大体上相同,不再逐一介绍。
其它:PooledByteBuf、PooledHeapByteBuf是对象池化的ByteBuf实现,简单来说就是可以反复重复利用的ByteBuf,在需要多次反复使用ByteBuf的场景下能够节省初始化ByteBuf的时间,提高性能。后续章节继续分析这些对象。
参考材料
http://ifeve.com/buffers/
http://www.cnblogs.com/carl10086/p/6207223.html















 897
897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









