







大家下午好,我是轻松筹CTO李汐,欢迎来到上海云栖大会的大数据专场。
今天我要和大家分享的是:基于数加平台,轻松筹如何开启大数据时代。
今天,主要和大家从以下三个方面来分享:

背景(Why)
轻松筹做大数据的目的是希望
真正给用户带来价值,给企业带来增长
轻松筹于2014年9月成立,经过一年的时间在2015年9月注册用户达到100万,2016年9月 经过2年时间注册用户突破1亿,并入选民政部网络募捐平台。
轻松筹,是从国外Kickstarter、Indiegogo的传统众筹模式中推陈出新,在中国演变发展为基于社交圈的全民众筹平台,并成功在中国普及了众筹这一概念。
成立至今,轻松筹经历了指数级增长,到今天,我们的手机号注册用户已经超过1.6亿,意味着每7个上网用户里就有1个人使用过轻松筹。
轻松筹每天有300GB的结构化数据产生,数据量以后还会越来越大,要应对的并发量也会越来越多。所以,一个支持PB级以上的数据库来存储这些海量数据并且能够支持及时查询,成了必需。
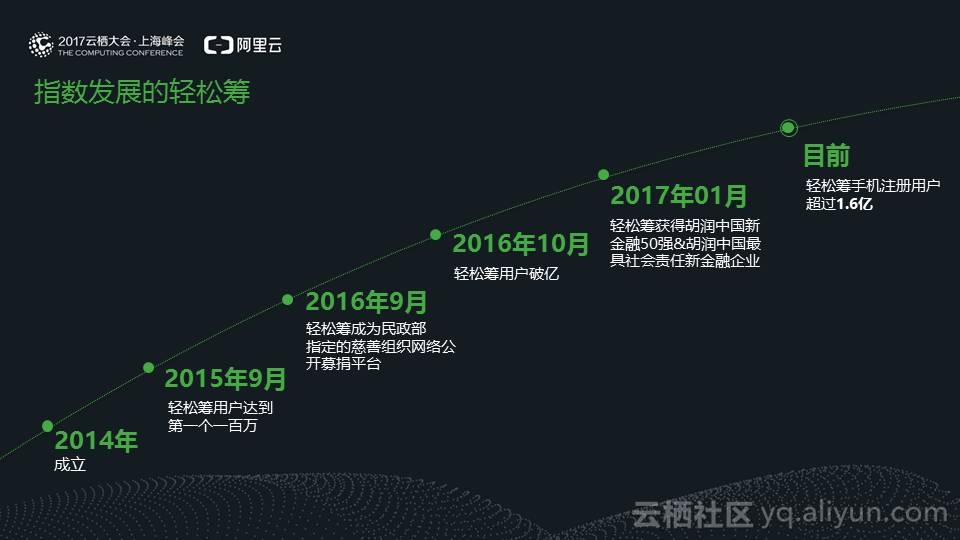
去年一年的时间,轻松筹帮助超过13.8万个大病家庭解决了燃眉之急。
数十家具有公募资格的基金会在轻松筹共筹集超过400万。
我们希望筹款能帮助每一位病人重获健康,同时我们也希望解决更多老百姓的社会保障问题,2016年4月18日我们首创了大病互助产品,每人只需3元钱就可以加入互助计划,目前我们已有735万会员加入。(大病互助产品解释:如果其中一人检查出30种大病中的一种,就可以获得30万的救助保障金,目前每人只需均摊5分钱。)
初步估算,1个月以后,轻松筹的互助行动将会有10000000会员,假设每天有20个人需要救助,那么我们每天要生成2亿行交易数据;面对如此庞大的数据存储和查询,我们需要建立一个稳定、安全,有保障的大数据中心。

有数据、但是要怎么用数据?我们有以下设想:
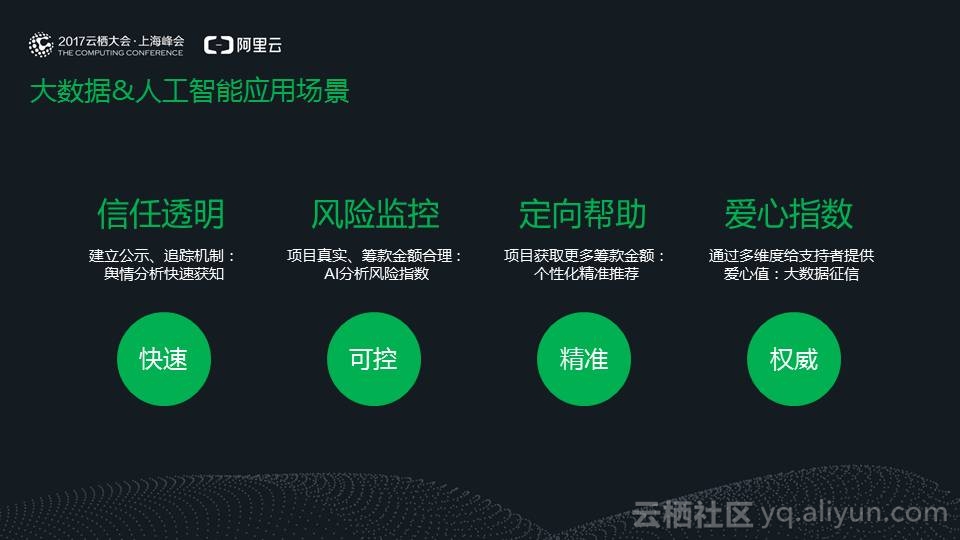
信任透明:
如何让项目(每一次救助我们结构化存储为项目)更加公开透明?我们作为平台方需要搭建好发起人和支持者良好的沟通渠道,当支持者对项目产生质疑时,我们通过项目发起人的进展、资金公示,举报数据来源,通过大数据手段实时抓取微博、微信公众号、媒体等数据源,建立公众趋势分析功能,快速获知整个项目情况,为后续追踪提供可靠的数据支撑!
风险监控:
如何保证每一个项目的真实可信,每一次筹款金额是否合理?我们建立了完整的病理库,一种大病某个分类在某个地区某个医院的医疗费用范围,其中还考虑各种其他因素,比如病人是否持续缴纳社保、病人家庭的固定资产情况。通过大数据、人工智能算法等技术计算出风险指数,给予发起人和支持者一个合理筹款的范围。
定向帮助:
如果让项目获得更多的支持金额?经典的6度人脉理论告诉我们可以通过6个人的关系联络到世界上任何一个人,经过我们的大数据分析,我们如果精准推荐给病人的三度人脉帮助其传播,能增加大概30%的筹款金额;
爱心指数:
如何满足爱心人士的存在感和荣誉感?我们创新了爱心值这个概念,通过多维度给每位支持者计算出爱心值,他们身上会被贴上“全省好人代表”或者是“联合国爱心大使”的标签,最终我们希望爱心值能类似于支付宝芝麻信用分那样实现征信的作用,可以授信借贷、租车(比如支付宝花呗借贷、共享单车租车,爱心值越高,可以借贷越高或者免费骑车)等提供给第三方使用;
为什么要做大数据?
在我看来,将数据应用到产品和业务上,给用户带来价值,给公司带来增长,才是我们做大数据的真正目的。
方案(How)
利用Hadoop自建大数据平台 VS 基于阿里云数加平台
要做大数据,但是怎么做?轻松筹面临以下几个问题:

1、缺乏大数据经验,挖坑、填坑是一个非常痛苦的事情。
业务在前面一直冲,我经历过1星期不睡觉一直擦屁股的事情。如果大家玩王者荣耀都知道每个星期的战报里那个神坑队友。
然而有了经验后则不同,它将具备先发优势,站在巨人的肩膀上,至少离成功更进一步。所以,我们需要拥有丰富的大数据项目经验的靠谱团队给我们支持。
2、用户行为埋点数据不全面。虽然市面上有百度统计、友盟、talkingdata等产品,但通过这些产品,我们只能看到局部报表数据,没法做到精准查询,而且明细数据也托管在别人手里,相当于我们的数据资产命脉在别人手里,这个是我们的痛点。
3、业务数据查询慢,传统结构数据分散有MySQL,MongoDB,日志文件等多种形式,有的业务查询需要避开业务高峰期甚至SQL查询时间要耗上1个晚上,这对于我们产品和业务的发展是非常不利的。我们需要在不影响业务正常发展的前提下,来做大数据的开发和应用。
具体该如何做?我们构想了2个计划,一是自建大数据系统;二是在成熟的产品基础上进行开发和应用;

自建系统:
即自己用开源的Hadoop等搭建一套大数据平台。首先需要招聘能做这件事的人才,初步估算需要2个月时间,实际上我们花了好几个月也没有找到负责人。去硅谷见了一圈比如Uber、LinkedIn大数据团队、国内也找了BAT做大数据的人,但是很难找到真正适合创业阶段的人。
团队建设也是非常难,如果没有核心的大数据负责人,很多技术人员来了找不到认同感,人员流动性非常大,最后会变成即使想做但还是做不了。稳定下来至少半年时间过去了。
大数据方案具体实现时间保守估计需要5个月甚至更长,因为没有底层基础,所以在这个过程中,踩坑在所难免。
1年时间下来,保守估计最终可能只完成工程以及小部分实验性产品。
但是大数据讲的不是概念,而是要用起来,还要用活;所以这个方案实际看起来更像一个理想化的工程方案,而且耗时长,对于创业公司来说,时间就是金钱,我们等不起。
所以,我们最终选择做大数据的方式如下:
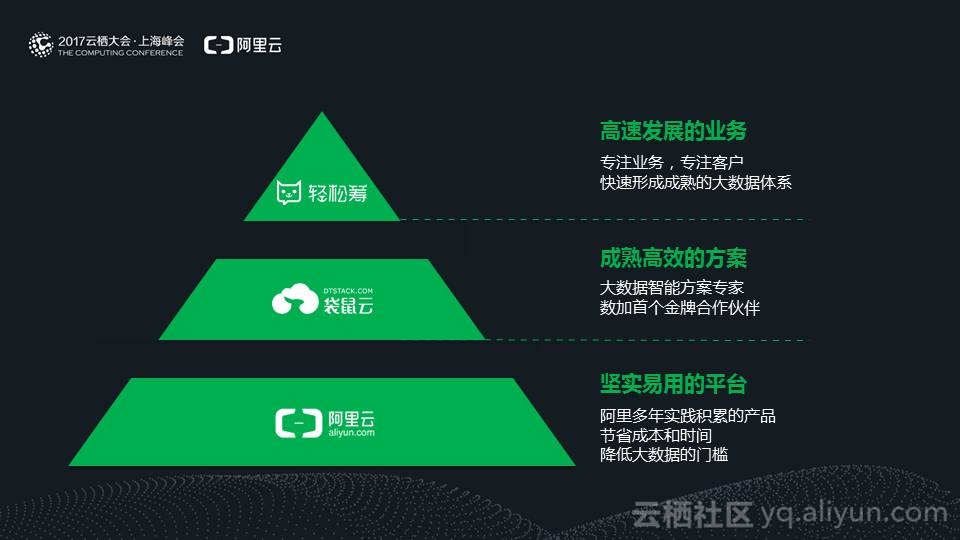
平台选择依托阿里云数加平台:数加是阿里多年实践经验沉淀的产品,成熟、稳定、开箱即用,像轻松筹这样的创业型公司,选择数加,是一个节省时间、金钱成本的明智选择。
服务商,我们选择的是袋鼠云:之所以选择袋鼠云,是因为在大数据项目之前,我们这边已经和袋鼠云有了相关合作,主要做数据库分布式架构设计,分库分表设计,袋鼠云有良好的服务态度和技术实力,对此,我们非常信任。同时袋鼠云的CTO江枫就是原来数加团队技术负责人之一,袋鼠云是数加首个金牌合作伙伴,他们有成熟的大数据解决方案,对数加平台以及数据开发和应用理解深刻。
这样一来,我们便可以快速形成成熟的大数据体系,并且能在实战中建立自己的大数据团队,互联网公司都是轻资产,轻装上阵,才能跑得更快。
我们最终采用了袋鼠云提供的大数据架构,如下图,这是一个通用的大数据架构:
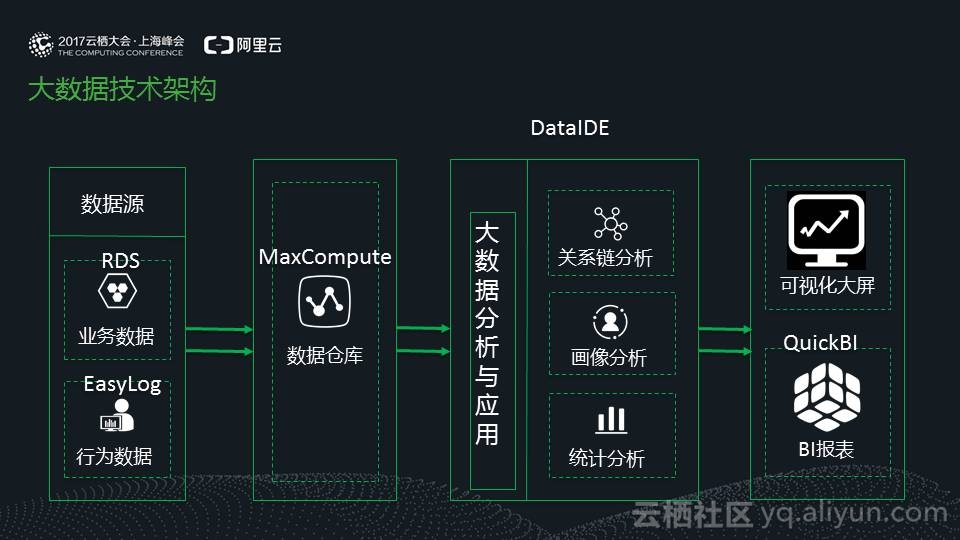
业务数据通过数据同步同步到MaxCompute中。订单类数据,每10分钟同步一次,其它的数据,每天同步一次。
行为数据,就是用户的点击、购买等行为日志数据,通过袋鼠云的云日志产品采集同步到MaxCompute中。数据的延迟在一分钟以内。
在MaxCompute中,将业务数据和行为数据打通。在此基础上,进行关系链分析、画像分析、统计分析等应用。
-
关系链分析:是想知道,筹款的传播情况。
-
画像分析:是想了解,爱心人士的捐款偏好。
-
统计分析:是生产成规报表,提出基础数据支持
最后,再将数据通过可视化大屏进行实时展现,并在QuickBI上生成BI报表。
我们期望方案能够实现数据的存、通、用,最终实现筹款者和爱心人士的更好连接。
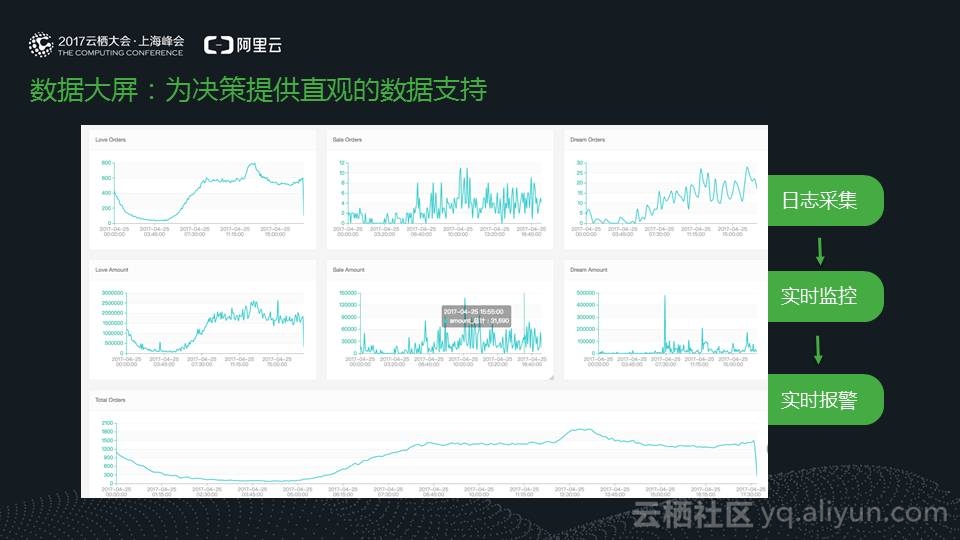
收获(What)
实时数据可视化,实现数据化运营
数据大屏
可以实时呈现业务信息,起到实时监控,支撑更快速、更敏捷的数据决策的作用。
BI报表
通过将业务数据和行为数据结合在一起,为筹款项目的精细化运营提供数据支持。
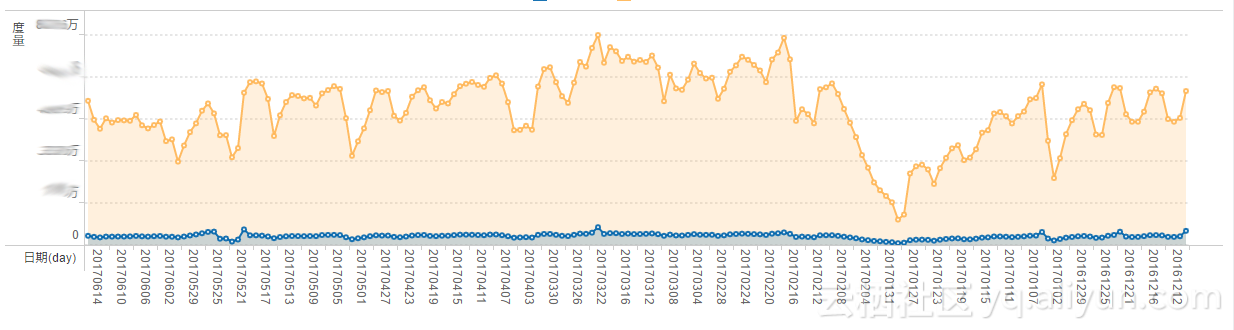
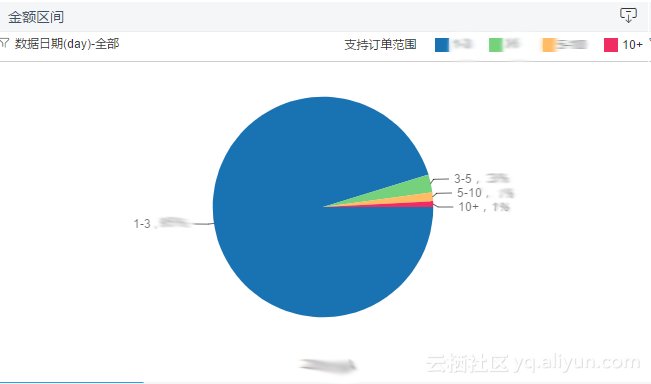
比如,可以了解某一个项目的当前的筹款状态,筹款金额趋势,筹款人数的趋势,渠道的转换率。
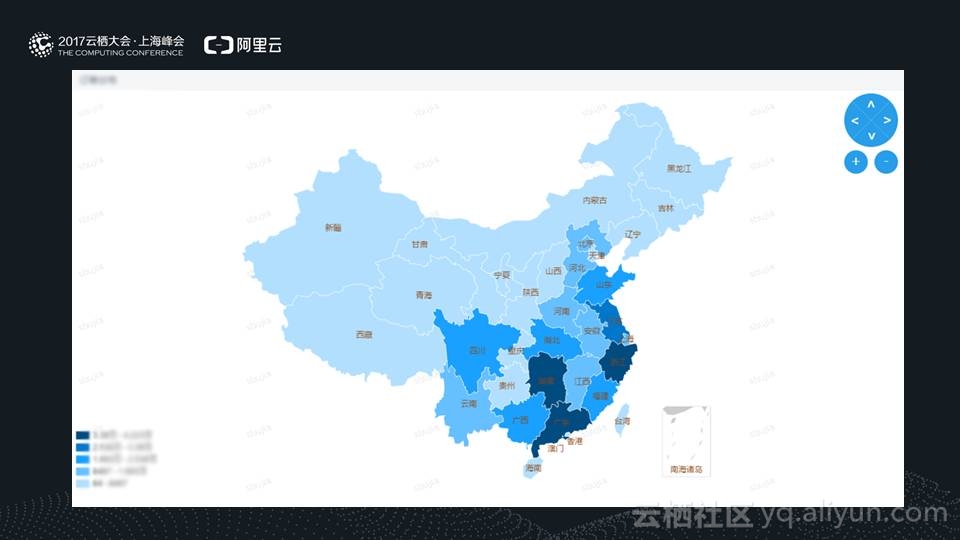
通过这些信息,我们了解到,这个项目是否需要推送到首页、工作号等渠道,让更多的人知道这个项目。
同时,我们统计各个渠道的捐款转化率,捐款占比。通过对这些分析,提出一些对产品的改善建议。
通过BI报表,让更多人使用数据,养成了对数据的使用习惯;同时,也提出了更多的报表需求;我们做决策不再是拍脑袋式的,而是根据真实数据的分析结果做更科学的决策。
这样,我们最终一步步走向数据化运营。

我们现有1.6 亿用户,每周在大数据平台生成2T的数据量。
基于阿里云平台,依靠我们的服务商袋鼠云,我们只需2个月便建成了自己的大数据中心,每月的资源花费<1万元。
通过这一系列的数据,我们认为,我们当初的选择是正确的。
最后,再升华一下,轻松筹做出的种种努力,都是为了我们最根本的愿景和使命:
解决全中国绝大多数老百姓的健康和保障问题
基于阿里云,依托合作伙伴的帮助,我们更有信心,也更容易完成我们的愿景。
-End-















 176
176











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









